
本页内容
GreptimeDB 企业版简介
GreptimeDB 企业版是 GreptimeDB 的商业版本,专注于服务企业级用户在以下方面的核心需求:
- 大规模数据的存储与处理
- 高性能、高并发的查询管理
- 可靠性保障
- 与现有企业系统的集成能力
本篇文章将详细介绍 GreptimeDB 企业版 25.05 版本中的关键新增特性。
Elasticsearch/Kibana 兼容性支持
我们注意到,大量使用日志功能的用户来自 Elasticsearch 生态。相比于 Elasticsearch,GreptimeDB 在日志场景下具备更高效的数据存储结构、更强的扩展能力,以及更优的写入与查询性能。
但在实际迁移过程中,现有系统中大量依赖 Kibana 的 UI 和旧接口,往往成为阻碍切换的重要因素。为此,最新版的 GreptimeDB 企业版中引入了 Elasticsearch 兼容层,支持将 GreptimeDB 企业版作为 Kibana 的后端,实现对日志的搜索、聚合及仪表盘展示。
支持的 Elasticsearch 查询语句包括:
matchmatch_allmulti_matchtermtermsprefixwildcardregexprangeexistsbool
支持只读副本,提升分析查询能力
在 GreptimeDB 开源版中,写入和读取通常由同一类数据节点处理。这种设计适用于典型的实时场景,例如高频率写入、仪表盘读取和告警数据的读取。但对于分析类查询,尤其是跨时间段、跨维度的深度分析,这种混合拓扑架构存在资源竞争的问题,影响查询效率。
我们在企业版中引入了只读副本机制,充分利用 GreptimeDB 的 存算分离架构,将查询压力从写入节点中剥离出来:
- 只读副本是专门处理查询任务的数据节点;
- 数据统一存储在对象存储中,不需要在节点间复制;
- 用户可以通过 SQL 查询中的 hint(提示参数)控制是否使用只读副本。
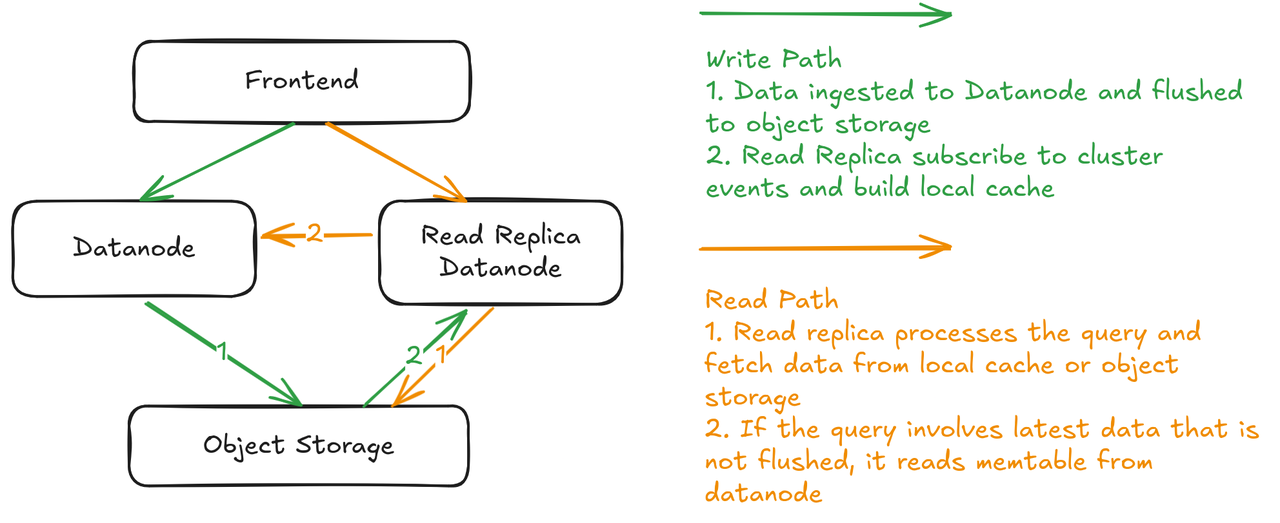
此外,只读副本还支持:
- 常驻“热”节点:提前订阅集群事件并构建查询缓存;
- 弹性“冷”节点(计划下个版本支持):可根据查询请求动态创建,灵活应对资源需求波动。
Trigger(触发器)机制:内置事件响应能力
不少用户希望在数据满足某些条件时,GreptimeDB 能够主动触发通知或执行操作。为此,我们在该版本中引入了内建的 Trigger 框架。
Trigger 允许用户:
- 定义规则(如 CPU > 1);
- 配置执行频率(如每 5 分钟);
- 设置告警等级和摘要信息;
- 对接通知方式(如 Prometheus AlertManager)。
示例:定义一个监控 CPU 占用率的触发器
sql
CREATE TRIGGER IF NOT EXISTS cpu_monitor
ON (SELECT host AS host_label, cpu, memory FROM machine_monitor WHERE cpu > 1)
EVERY '5 minute'::INTERVAL
LABELS (severity = 'warning')
ANNOTATIONS (summary = 'CPU utilization is too high', link = 'http://...')
NOTIFY(
WEBHOOK alert_manager URL 'http://127.0.0.1:9093' WITH (timeout="1m")
);该机制与 Prometheus AlertManager 高度集成,是轻量可观测性建设中的重要组件。
Flow 引擎增强:支持任务迁移,提升流式处理稳定性
GreptimeDB 内置的轻量级流式计算引擎 Flow,也在本次更新中获得了可靠性能力的增强。我们新增了任务迁移(Task Migration)功能,支持在多个 Flow 节点间动态迁移任务,以实现负载均衡、故障隔离和系统容错。
企业可视化控制台不断迭代中
除了底层引擎的持续增强,我们的企业版可视化控制台也在不断迭代中,为企业用户提供更直观的数据管理与监控体验。
发布节奏与企业支持服务
GreptimeDB 企业版的大版本每 6 个月发布一次,企业用户还可根据需求获取定制功能更新与问题修复支持。
如需获取完整的功能列表、企业部署支持和 SLA 服务,请通过官方渠道与我们联系(小助手:15310923206;售前支持:18210326473)。
如果您是企业用户,希望使用 GreptimeDB 构建下一代可观测平台,欢迎随时与我们沟通合作。

