
本页内容
背景
OceanBase 始创于 2010 年,是 100% 根自研的原生分布式数据库。OceanBase 基于单机分布式一体化架构,高度兼容 Oracle 和 MySQL,支持事务处理(TP)和实时分析处理(AP)等多工作负载,原生支持向量检索与多模数据混合检索,助力客户构建面向 AI 的一体化数据底座。已广泛应用于金融、运营商、零售、互联网及公共服务等行业,助力 4000+ 客户实现关键业务系统升级。
2022 年,OceanBase 正式推出云数据库 OB Cloud,通过一体化云数据库服务助力客户构建现代数据架构,简化技术栈。目前,OB Cloud 已覆盖全球 16 个国家和地区、60+ 区域、240+ 可用区,是全球唯一覆盖 7 大主流公有云的一体化云数据库,基于阿里云、华为云、腾讯云、百度智能云、AWS、Azure 和 Google Cloud 等提供全球范围内一致体验,并支持跨地域、跨云双活容灾,满足客户多样的业务增长需求。
从 Grafana Loki 切换到 GreptimeDB 一年之后,OB Cloud 已经在 GreptimeDB 上沉淀了 80+ 集群、300TB 日志和 SQL 审计数据,整体存储成本下降 60% 以上。
OB Cloud 都存什么日志
OB Cloud 日常需要存储、检索和保留四类日志:
| 日志类型 | 说明 | 特点 |
|---|---|---|
| 应用日志 | OB Cloud 平台自身的服务日志 | 量大、结构复杂;用于排查定位平台服务问题 |
| OBServer 日志 | OceanBase 数据库内核日志 | 量大;用于排查定位内核问题 |
| OBProxy 日志 | OceanBase 数据库代理日志 | 量大;用于排查定位数据访问链路问题 |
| SQL Audit | SQL 执行审计记录 | 量大、高频写入、字段统一、SQL 字段结构复杂、查询分析需求强 |
这些日志有一个共同特征:排查和分析问题时不可或缺,但 95% 的时间不会被查询。出问题的时候必须立刻可用,平时则放着不动。这决定了存储层的优先级——首先要以低单位成本承接持续高吞吐的写入,同时在工程师真正需要时仍能快速回应关键字检索和结构化查询。
多云日志方案的选型路径
起点:阿里云 SLS
OB Cloud 最早选用阿里云 SLS 来存日志。SLS 与阿里云生态深度集成,全文索引带来毫秒级查询响应,自动扩容免去容量管理。但有两个缺点对 OB Cloud 是硬伤:全量索引带来明显的存储膨胀,整体成本偏高;并且只能跑在阿里云上。
各云原生日志服务的现实
每家云厂商都有自己的日志方案。OB Cloud 团队逐一调研了一遍:
| 云厂商 | 日志采集 | 日志读取 |
|---|---|---|
| 阿里云 SLS | Logtail (LoongCollector) | Lucene + 标准 SQL |
| 华为云 LTS | ICAgent | 类 Lucene 语法 |
| 腾讯云 CLS | LogListener | 类 Lucene 语法 |
| 百度云 BLS | LogAgent | 类 Lucene 语法 + 标准 SQL |
| AWS CloudWatch Logs | Unified CloudWatch Agent | Logs Insights 语法 |
| Azure Monitor Logs | Azure Monitor Agent (AMA) | KQL |
| GCP Logging | Ops Agent / Fluent Bit | Logging Query Language |
七套日志栈在两个维度上同时拉高成本:
- 开发运维:每接入一朵云就要重做一次适配——查询语法不同、采集端不同、解析规则不同、白名单和配置也无法对齐。在七种语法之上抽象出一个统一的查询接口很难维护。
- 延迟和价格:CloudWatch Logs 实时性差(10 秒到分钟级延迟)、按扫描日志量收费;SLS 索引流量贵;Azure 存储贵。
多云中立方案的探索
接下来 OB Cloud 评估的是多云中立的存储方案:
- Elasticsearch:方案成熟,但运维复杂、存储成本高。
- ClickHouse:有使用案例,运维复杂、存储成本高,选型时还没有生产可用的全文索引。
- Grafana Loki:有使用案例,标签索引,支持对象存储,存储成本低。
Loki 灵感来源于 Prometheus,只索引标签不索引日志正文,支持 S3 / OSS / GCS,通过 LogQL 查询,K8s 原生部署。OB Cloud 最终选择 Loki 作为第一代方案。
第一代架构:基于 Loki
基于 Loki 的日志存储架构如下:
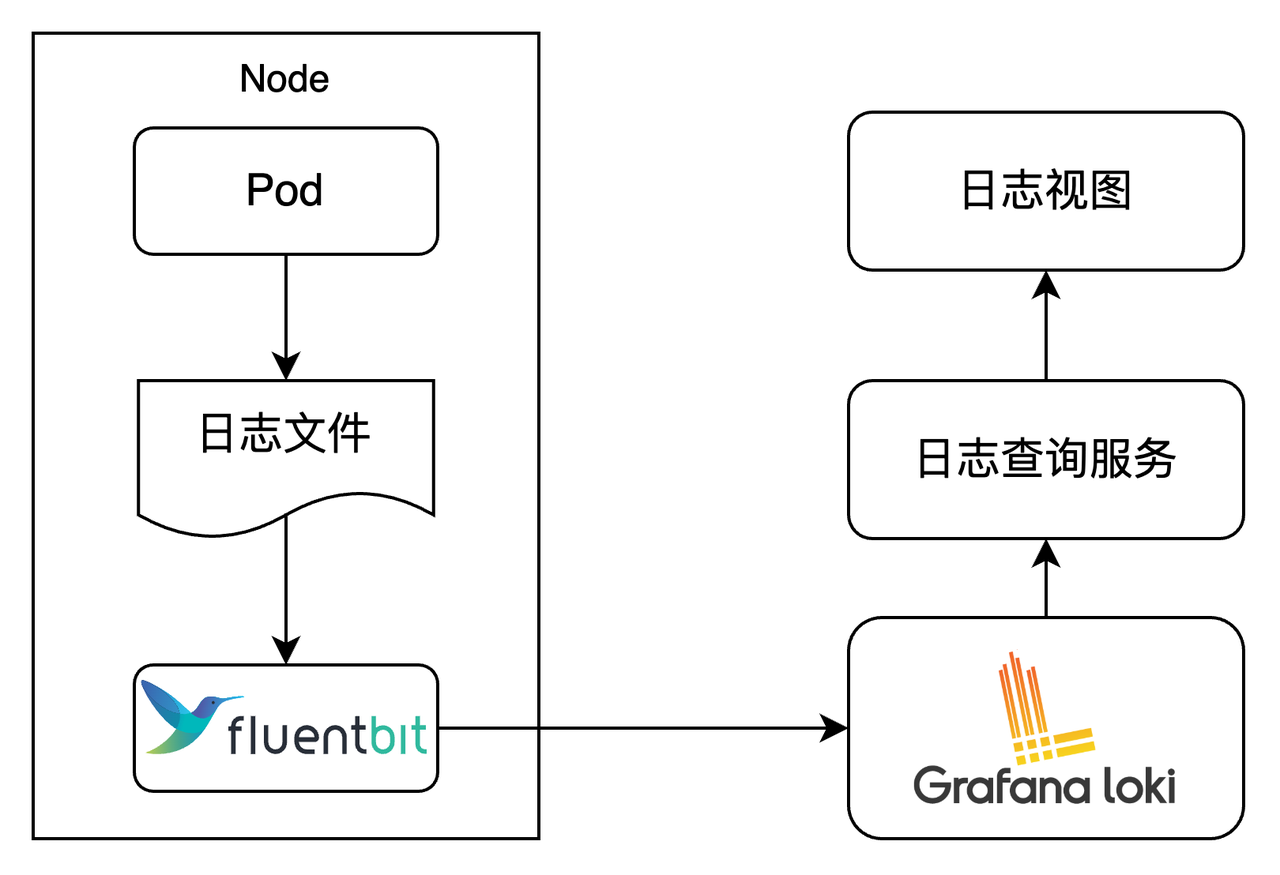
每个节点上的 Fluent Bit 采集所在节点上各应用 Pod 的日志,写入 Loki。日志视图调用日志查询服务获取结果,查询服务把检索条件翻译成 LogQL,再调用 Loki 的 API。
随着业务增长,三个限制逐渐凸显:
- 索引能力弱:只索引标签,对日志正文的关键字检索只能暴力扫全量。
- 大数据量查询超时:查询时间范围只能限制到分钟级,否则容易超时。
- 瓶颈随业务增长加剧,研发排障效率明显下降。
切换到 GreptimeDB
在 v0.12 版本上做 POC 时,GreptimeDB 满足了 OB Cloud 关心的几条:
- 云原生:存算分离、K8s 原生部署和运维。
- 对象存储:原生支持 S3 / OSS / GCS / ABS。
- 高压缩:列式存储 + 高效压缩,存储成本低。
- 统一接口:SQL 查询 + 统一写入协议,跨云一致体验。
- 丰富索引:全文索引 + 倒排索引,关键字检索不再只能暴力扫描。
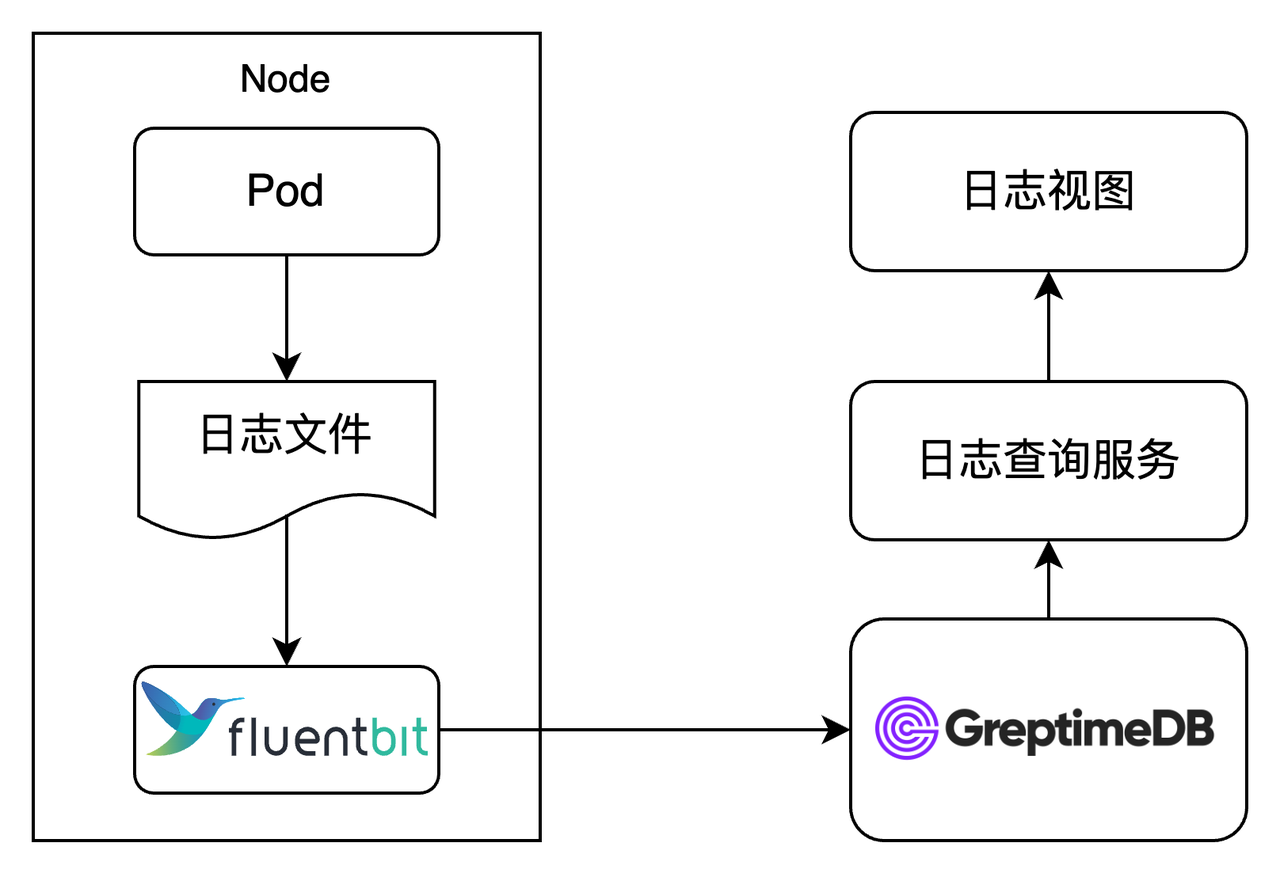
POC 通过后整体切换:Fluent Bit 直接写 GreptimeDB,日志查询服务通过 SQL 查询。原本在 Loki 上动辄超时的查询,在 GreptimeDB 上稳定在亚秒到秒级,日志视图的默认时间范围也从分钟扩到了小时甚至天。
多云部署架构
OB Cloud 在不同的云上各自部署 GreptimeDB 集群,对接对应云厂商的对象存储:
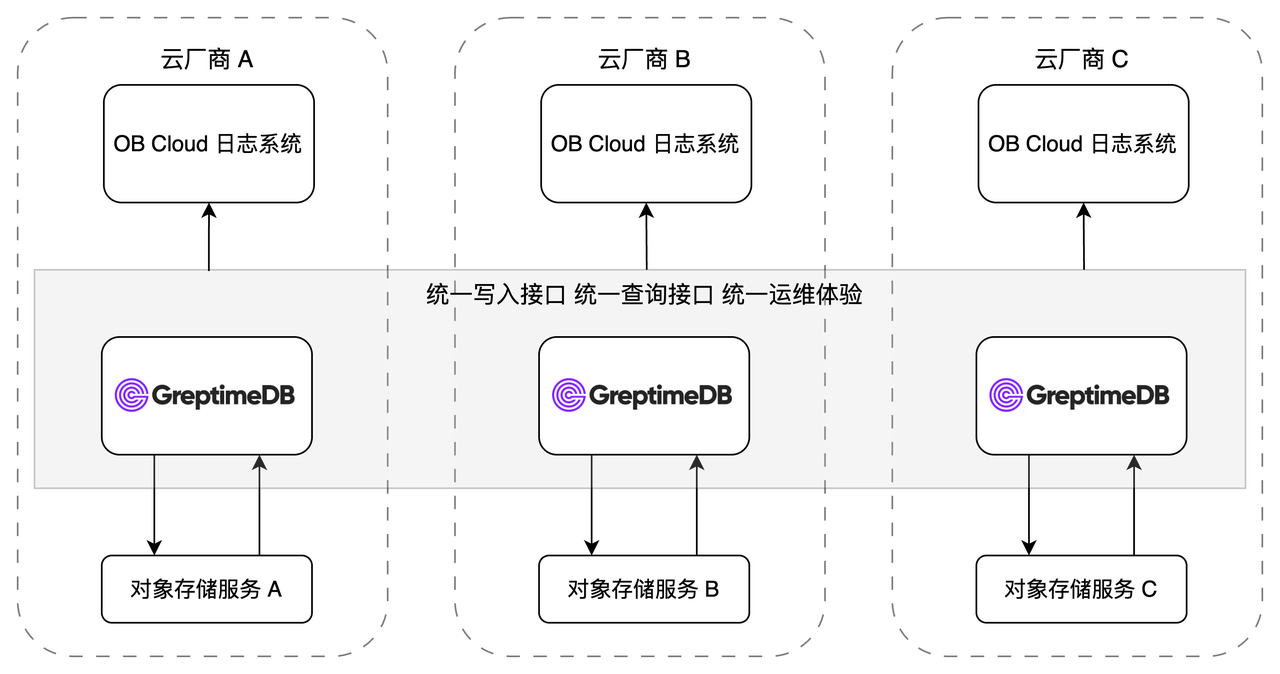
每朵云上跑的都是同一套写入协议、SQL 查询接口和运维体验。不论底层是哪朵云,上层日志系统都是一致的。
实践细节
Pipeline 解析与字段提取
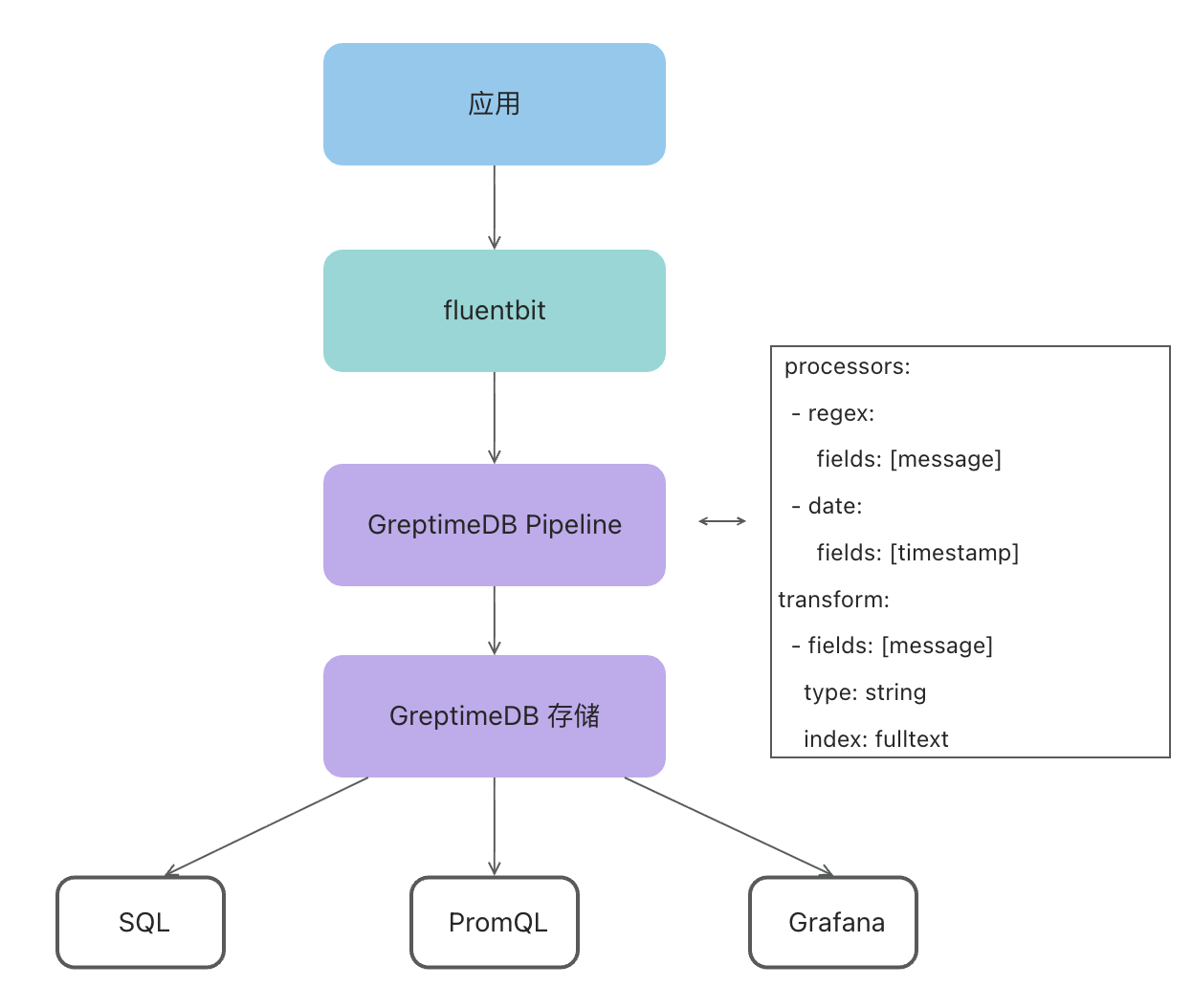
Fluent Bit 写入 GreptimeDB 的是 JSON 格式数据,由 GreptimeDB 的 Pipeline 解析 JSON、提取字段后写入日志表。主机名、文件路径等字段会单独存到对应的列上,方便查询时直接按这些字段过滤。
OB Cloud 部分应用的日志会包含多个换行,dissect 处理器无法干净地切分。这类日志 OB Cloud 改用 regex 处理器:
yaml
processors:
- regex:
fields:
- message
patterns:
- '^(?P<timestamp>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}(\.\d+)?)[ ,](?P<message>(?s:.*))$'
ignore_missing: true
- date:
fields:
- message_timestamp
formats:
- '%Y-%m-%d %H:%M:%S%.3f'
- '%Y-%m-%d %H:%M:%S%.6f'
- '%Y-%m-%d %H:%M:%S%.9f'
- '%Y-%m-%d %H:%M:%S%.f'
- '%Y-%m-%d %H:%M:%S%'
timezone: 'Asia/Shanghai'
ignore_missing: true
transform:
- fields:
- message
type: string
- fields:
- file
- host
type: string
index: tag
- fields:
- message_timestamp,timestamp
type: epoch, ns
index: timestamp整条流水线如下:
表设计
一个典型的日志表设计如下:
sql
CREATE TABLE IF NOT EXISTS "xx_log" (
"timestamp" TIMESTAMP(9) NOT NULL DEFAULT current_timestamp(),
"file" STRING NULL,
"host" STRING NULL,
"ip" STRING NULL,
"request_id" STRING NULL SKIPPING INDEX,
"message" STRING NULL FULLTEXT,
TIME INDEX ("timestamp"),
PRIMARY KEY ("file", "host", "ip")
)
ENGINE = mito
WITH (
append_mode = 'true',
'compaction.twcs.time_window' = '2h',
'compaction.type' = 'twcs',
ttl = '15days'
);几点设计说明:
append_mode = 'true'适合只追加的日志场景,省掉对从不更新的行做版本管理的开销。- TWCS 时间窗 2 小时 + 15 天 TTL 与"95% 不查"的访问模式匹配:数据按时间分组、过期窗口干净下线、Compaction 工作量有界。
- 索引选择按字段实际用途:
request_id用 SKIPPING INDEX 应对高基数点查;message用 FULLTEXT 处理关键字检索;其余字段不加索引,控制存储成本。
Fluent Bit 调参
流量高峰期 Fluent Bit 日志中出现 mem buf overlimit,提示存在反压。但 GreptimeDB 服务端的写入耗时和负载指标都正常,Fluent Bit 自身资源占用也并不高。问题出在 Fluent Bit 的缓冲机制配置上:
- Fluent Bit 内部用一个内存缓冲区(
mem_buf)存放采集到的日志,写满之后会暂停采集。 mem_buf_limit决定缓冲区大小,也间接决定了 Fluent Bit 的内存占用上限。flush控制缓冲区数据下发的间隔。mem_buf_limit偏小、flush偏大时,发送速度跟不上业务高峰期的产生速度。- 日志轮转时 Fluent Bit 默认每 60 秒扫一次文件列表(
Refresh_Interval),新切出来的文件采集存在延迟。
把 flush、mem_buf_limit、Refresh_Interval 一起调整后,高峰期的延迟和反压基本消除。
一年后再看 Loki vs GreptimeDB
| 维度 | Loki | GreptimeDB |
|---|---|---|
| 查询性能 | 大数据量超时 | 一天日志亚秒级 ~ 秒级 |
| 索引能力 | 仅标签索引 | 全文索引 + Skipping/倒排索引 |
| 多云部署 | 可部署但体验一般 | 原生多云、统一接口 |
| 存储成本 | 对象存储,较低 | 对象存储 + 高压缩,更低 |
| 查询范围 | 分钟级 | 小时级甚至天级 |
| 运维复杂度 | 中等 | K8s 原生,运维简单 |
使用过程中遇到的问题与版本迭代
平时跑得很顺,但生产规模总会暴露出新问题。这些问题也驱动了 GreptimeDB 一路的版本迭代:
- 0.15 之前 Pipeline 不支持条件过滤。部分业务场景只需要采集特定级别或包含某些关键字的日志,没有过滤就只能全量采。0.15 给 Pipeline 增加了过滤功能,能在写入前丢掉不需要的日志,直接降低存储成本。
- 0.12 的
matches函数比较复杂、使用不友好。0.13 提供了新的全文索引实现和查询语法函数,简化了查询写法,性能也同步提升。 - 大写入量下 datanode compaction 阶段会内存膨胀甚至 OOM。OB Cloud 团队一度需要人工调整合并参数和扩容 datanode 来稳定集群。0.15 优化了 compaction 文件合并策略,把 compaction 的峰值内存降下来,datanode 整体运行内存稳定。
- 早期版本 meta server 对 RDS 支持不完善,需要单独搭一套 etcd 存元数据,多了一层运维成本。0.15 meta server 全面兼容 RDS,并提供了元数据迁移工具。OB Cloud 就是用这个工具完成了向 GreptimeDB 0.15 企业版的升级。
升级到 GreptimeDB 企业版
到 80+ 集群、单集群最大 50TB 的时候,运维面已经足够大,OB Cloud 决定升级到 GreptimeDB 企业版。企业版补齐了三类能力:
- 性能与扩展性:更高的写入性能、只读副本、智能分层缓存。
- 智能自动操控:自动扩缩容、自动分区、自动负载均衡、自动备份、智能流控、远程压缩与索引。
- 运维与管理:企业管理控制台、性能诊断、一对一专家 7×24 服务响应、定制化服务。
当前规模与收益
- 存储覆盖:日志和 SQL Audit 全部存储到 GreptimeDB。
- 集群规模:80+ GreptimeDB 集群在产;保留 7 天的数据量达到 300TB;最大单集群 50TB;平均写入流量约 1GB/s。
- 成本:整体日志存储成本下降 60% 以上。
- 客户侧收益:对客的 SQL 审计定价同步下调,把 60%+ 的 SQL 审计成本节省传递给最终用户。
下一站:智能诊断 Agent
这种规模下要保障生产稳定性,靠三件事配合:经验丰富的 SRE 团队、系统化的能力底座(巡检、监控告警、根因分析和预案),以及一个 7×24 在线的 AI Agent。
OB Cloud 智能诊断 Agent 把这几样组合起来:
- LLM 作为推理大脑。
- Skills 沉淀专家经验和技能。
- MCP 作为数据通道和上下文数据源。
- 知识库接入技术文档、工单和历史故障。
- Scheduled 负责定时巡检调度。
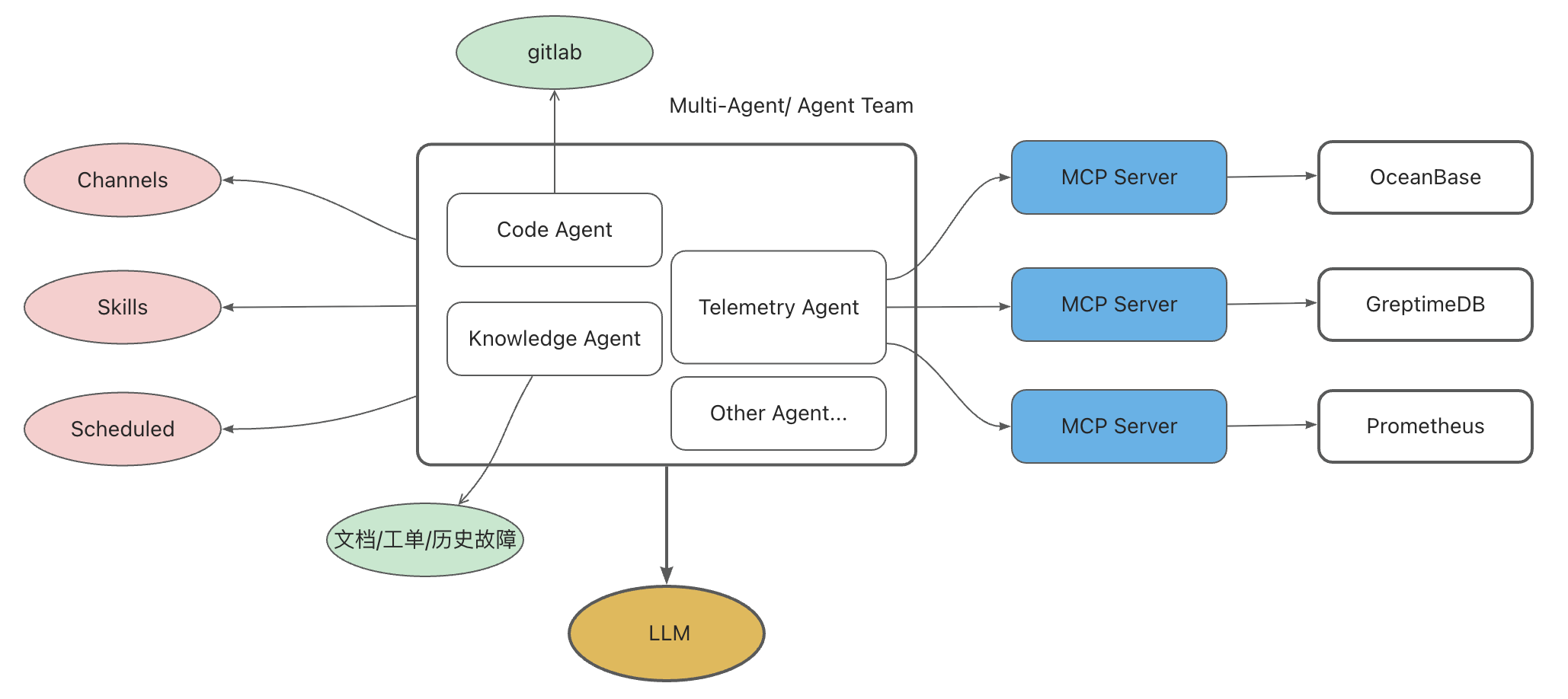
GreptimeDB 在这里是一等公民数据源。Telemetry Agent 通过 GreptimeDB MCP Server 直接从 SQL Audit 表里取 Top SQL,请求最终落到的 SQL 大致长这样:
sql
SELECT *
FROM sql_audit_<cluster>
WHERE request_timestamp >= NOW() - INTERVAL '10 MINUTES'
AND tenant_name = '<tenant>'
ORDER BY affected_rows DESC
LIMIT 20;SRE 平时复盘要用的数据,现在直接成为 LLM 在线诊断时的上下文。
总结
一年的实际运行印证了当时的判断:在 OB Cloud 的规模下,多云中立 + 列式存储 + 全文索引 + 对象存储 + 统一 SQL 接口,能稳定支撑 80+ 集群、300TB 日志的存储与查询。下一阶段的方向是让更多可观测数据进入同一套底座,并把诊断 Agent 接得更深。

