
本页内容
三个系统,定位一个问题
LLM 应用上线之后,工程师通常会遇到这几个问题:
- 这个请求为什么这么慢?是模型响应慢,还是业务逻辑的问题?
- 上周 token 用量突然涨了 3 倍,是哪个用户?哪个 prompt?
- 用户反馈"AI 回答得一塌糊涂",能找到那条对话记录吗?
- 同一个场景,换个模型,p95 延迟和成本差多少?
这些问题本身不复杂,但如果你用的是传统可观测性方案——Prometheus 存 metrics、Elasticsearch 存日志、Jaeger 存 traces——三个系统之间的数据根本关联不起来。一次 LLM 调用的 trace_id 在 Jaeger 里,token 用量在 Prometheus 里,对话内容在 Elasticsearch 里,定位一个问题要跨三个界面来回跳。
LLM 可观测性的难点不是数据采不到——而是 traces、metrics 和对话记录分散在三个互不相通的库里。
本文以一个基于 OpenTelemetry GenAI 语义规范 的 demo 为例,展示如何用 GreptimeDB 作为统一后端,解决上面这些问题。
OTel GenAI 语义规范:LLM 可观测性的统一语言
OpenTelemetry(OTel)在微服务可观测性领域已经是事实标准。2024 年起,OTel 社区开始为 GenAI 工作负载制定专用的语义规范(Semantic Conventions),定义了一套 gen_ai.* 命名空间下的标准属性体系,把 LLM 调用的遥测数据格式统一了下来。
三类信号
OTel GenAI 规范覆盖三类可观测性信号:
Traces(链路追踪)——每次 LLM 调用产生一个 Span,携带结构化属性:
| 属性 | 含义 | 示例值 |
|---|---|---|
gen_ai.system | 提供商 | openai |
gen_ai.request.model | 请求模型 | gpt-4o-mini |
gen_ai.response.model | 实际使用模型 | gpt-4o-mini-2024-07-18 |
gen_ai.usage.input_tokens | 输入 token 数 | 142 |
gen_ai.usage.output_tokens | 输出 token 数 | 87 |
gen_ai.response.finish_reasons | 停止原因(JSON 数组) | ["stop"]、["tool_calls"] |
Metrics(指标)——SDK 自动生成两个直方图 metric(OTel 规范中的 instrument 名):
gen_ai.client.operation.duration:每次调用的端到端延迟(单位s)gen_ai.client.token.usage:每次调用的 token 消耗(无单位)
两个 metric 写入 GreptimeDB 后,表名规则有所不同:
gen_ai.client.operation.duration— 有时间单位(s),Prometheus 惯例追加_seconds后缀。表名:gen_ai_client_operation_duration_seconds_bucket/count/sum。gen_ai.client.token.usage— 无量纲单位({token}),后缀被省略。表名:gen_ai_client_token_usage_bucket/count/sum。
Logs/Events(日志/事件)——可选开启的会话内容捕获,记录完整的 prompt 和 completion。默认关闭(避免误采集敏感数据),通过 OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=true 开启。demo 的 docker-compose.yml 里已默认开启,跑起来后三类信号全部激活。
一行代码接入
python
from opentelemetry.instrumentation.openai_v2 import OpenAIInstrumentor
OpenAIInstrumentor().instrument()
# 之后所有 OpenAI SDK 调用自动产生 gen_ai.* 遥测数据
client.chat.completions.create(model="gpt-4o-mini", messages=[...])opentelemetry-instrumentation-openai-v2 自动 patch 了 OpenAI SDK,每次调用都会生成符合规范的 Span 和 Metric,无需修改业务代码。日志捕获默认关闭,需要通过上面的环境变量开启。除了 OpenAI,规范还覆盖 Anthropic、Azure AI Inference、AWS Bedrock 等主流提供商。
Demo 架构:OTLP 直送 GreptimeDB
GenAI 应用(Python)
│ OpenAI SDK + OTel GenAI Instrumentor
│ 自动产生 traces + metrics + logs
│
│ OTLP/HTTP
▼
GreptimeDB
├── opentelemetry_traces ← traces,gen_ai.* 属性展开为可查询列
├── genai_conversations ← logs,完整 prompt/completion 内容
├── OTel metrics ← histograms,支持 PromQL 查询
└── Flow 聚合表 ← 实时预聚合的 token/延迟/状态统计
│
Grafana
├── SQL 面板(traces、logs、Flow 表)
├── PromQL 面板(OTel histogram metrics)
└── Trace 瀑布图(GreptimeDB Grafana 插件)三类 OTel 信号通过不同的端点写入 GreptimeDB(详见 GreptimeDB OpenTelemetry 接入文档):
python
# Traces:通过内置 pipeline 将 span attributes 展平为可查询列
OTLPSpanExporter(
endpoint="http://greptimedb:4000/v1/otlp/v1/traces",
headers={"x-greptime-pipeline-name": "greptime_trace_v1"},
)
# Metrics:标准 OTLP,histogram 自动支持 PromQL
OTLPMetricExporter(endpoint="http://greptimedb:4000/v1/otlp/v1/metrics")
# Logs:通过自定义 header 路由到指定表
OTLPLogExporter(
endpoint="http://greptimedb:4000/v1/otlp/v1/logs",
headers={"X-Greptime-Log-Table-Name": "genai_conversations"},
)整个链路没有 OTel Collector——数据从应用直接写入 GreptimeDB,适合 demo 和小规模部署。生产环境通常会在中间加 Collector 处理 buffer/retry、采样和 PII 脱敏,但架构核心不变。
跑起来之后,Grafana dashboard 长这样——请求数、token 用量、成本、错误率一屏呈现,往下是 token 趋势、延迟分位数、model comparison:
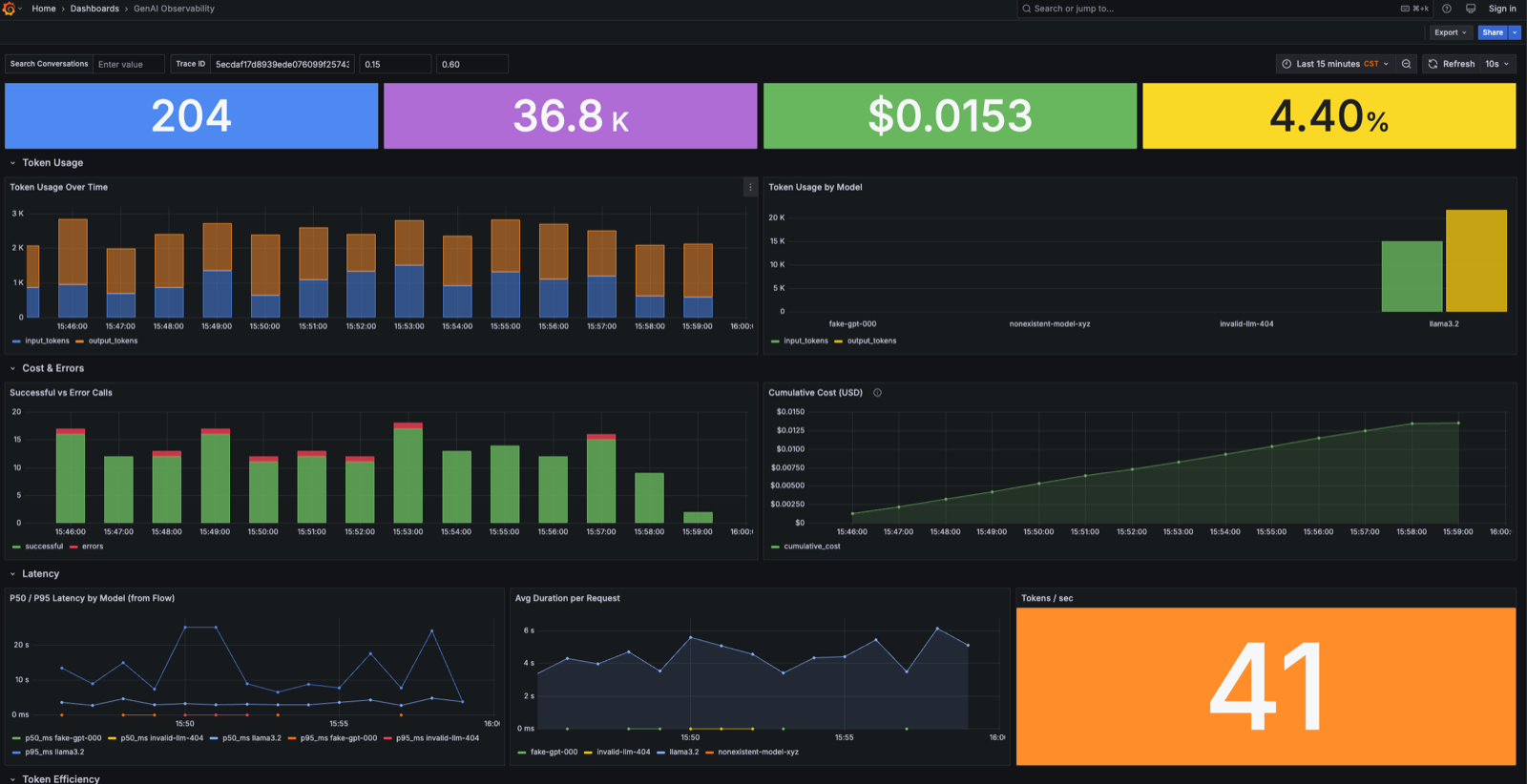
GreptimeDB 的三个核心优势
1. 三类信号同库,跨信号关联查询
传统方案里,traces、metrics、logs 分散在三个系统,"从 trace 找到对应对话"往往要在界面之间手动传递 trace_id,无法用一条查询完成。
GreptimeDB 把三类信号存在同一个库里,traces 和对话记录可以直接 JOIN——不用切换任何界面。
opentelemetry_traces 表和 genai_conversations 表都有 trace_id 和 span_id 列。注意:opentelemetry_traces 的列名包含点号(如 span_attributes.gen_ai.request.model),在 SQL 中需用双引号包裹,下文所有示例统一使用双引号:
sql
-- 找到 token 用量最高的用户 prompt,直接关联查看内容
SELECT
t.trace_id,
t."span_attributes.gen_ai.request.model" AS model,
t."span_attributes.gen_ai.usage.input_tokens" AS input_tokens,
t."span_attributes.gen_ai.usage.output_tokens" AS output_tokens,
json_get_string(parse_json(c.body), 'content') AS user_message
FROM opentelemetry_traces t
JOIN genai_conversations c ON t.trace_id = c.trace_id AND t.span_id = c.span_id
WHERE t."span_attributes.gen_ai.system" IS NOT NULL
AND json_get_string(parse_json(c.body), 'message.role') IS NULL
ORDER BY input_tokens DESC
LIMIT 10;Prometheus + Elasticsearch 的组合里这类查询几乎无法实现——两个系统没有共享的存储引擎,trace_id 关联只能在应用层手动拼接。
2. 从原始 Span 衍生 Metrics,不用双写
GreptimeDB 的流处理引擎(Flow)提供持续聚合能力,类似 SQL 里的物化视图,但实时驱动。
每个 LLM 调用的 Span 本身就是一个宽事件(Wide Event),携带了所有需要聚合的字段:model、token counts、duration、status code。有了 Flow,直接从 traces 里聚合出指标——应用层不需要再额外上报一套 metrics。
sql
-- token 用量:每分钟每模型的消耗
CREATE FLOW genai_token_usage_flow
SINK TO genai_token_usage_1m
EXPIRE AFTER '24h'
AS
SELECT
"span_attributes.gen_ai.request.model" AS model,
COUNT("span_attributes.gen_ai.request.model") AS request_count,
SUM(CAST("span_attributes.gen_ai.usage.input_tokens" AS DOUBLE)) AS total_input_tokens,
SUM(CAST("span_attributes.gen_ai.usage.output_tokens" AS DOUBLE)) AS total_output_tokens,
date_bin('1 minute'::INTERVAL, "timestamp") AS time_window
FROM opentelemetry_traces
WHERE "span_attributes.gen_ai.system" IS NOT NULL
GROUP BY "span_attributes.gen_ai.request.model", time_window;
-- 延迟分布:用 uddsketch 保存分位数草图,支持 p50/p95/p99 查询
CREATE FLOW genai_latency_flow
SINK TO genai_latency_1m
EXPIRE AFTER '24h'
AS
SELECT
"span_attributes.gen_ai.request.model" AS model,
COUNT("span_attributes.gen_ai.request.model") AS request_count,
uddsketch_state(128, 0.01, duration_nano) AS duration_sketch,
date_bin('1 minute'::INTERVAL, "timestamp") AS time_window
FROM opentelemetry_traces
WHERE "span_attributes.gen_ai.system" IS NOT NULL
GROUP BY "span_attributes.gen_ai.request.model", time_window;Demo 还定义了第三个 Flow 用于状态聚合(按 model 和 status code 统计请求数)——完整定义见 flows.sql。
uddsketch_state(buckets, error_rate, value) 是 GreptimeDB 1.0 RC1 中的分位数聚合函数,三个参数依次是:分桶数(128)、误差率(0.01,即 1%)、待聚合的值列。p50/p95/p99 直接从聚合表读取,不用扫全量原始 traces:
sql
SELECT
model,
ROUND(uddsketch_calc(0.50, duration_sketch) / 1000000, 1) AS p50_ms,
ROUND(uddsketch_calc(0.95, duration_sketch) / 1000000, 1) AS p95_ms,
ROUND(uddsketch_calc(0.99, duration_sketch) / 1000000, 1) AS p99_ms,
time_window
FROM genai_latency_1m
ORDER BY time_window DESC
LIMIT 20;3. 原始对话可搜索,点击直达 Trace
OTel GenAI 规范支持将完整的 prompt 和 completion 内容作为 Log Events 发送。开启 OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=true 后,每条用户输入和模型输出都作为一条 log 记录写入 genai_conversations 表。GreptimeDB 接收 OTLP 日志时会自动创建该表,并对 body 列启用全文索引,无需手动建表。
输入关键词,找到匹配的对话,点 trace_id 直接跳到瀑布图。 matches_term() 利用全文索引做检索:
sql
-- 搜索所有提到 "GreptimeDB" 的对话
SELECT
timestamp,
trace_id,
CASE WHEN json_get_string(parse_json(body), 'message.role') IS NOT NULL
THEN json_get_string(parse_json(body), 'message.role')
ELSE 'user' END AS role,
COALESCE(
json_get_string(parse_json(body), 'message.content'),
json_get_string(parse_json(body), 'content')
) AS content
FROM genai_conversations
WHERE matches_term(body, 'GreptimeDB')
ORDER BY timestamp DESC
LIMIT 20;genai_conversations 表里每条 log 的 body 结构因角色不同而有所差异:用户消息是 {"content": "..."} 顶层结构,助手回复是 {"message": {"role": "assistant", "content": "..."}} 嵌套结构,用 COALESCE 同时兼容两种格式。
Grafana dashboard 里的 "Search Conversations" 输入框就是这条查询的前端。

下图展示了从 Recent Conversations 到 Recent Traces,再到 Trace Detail 瀑布图的完整视图——三类信号在同一界面里通过 trace_id 串联:
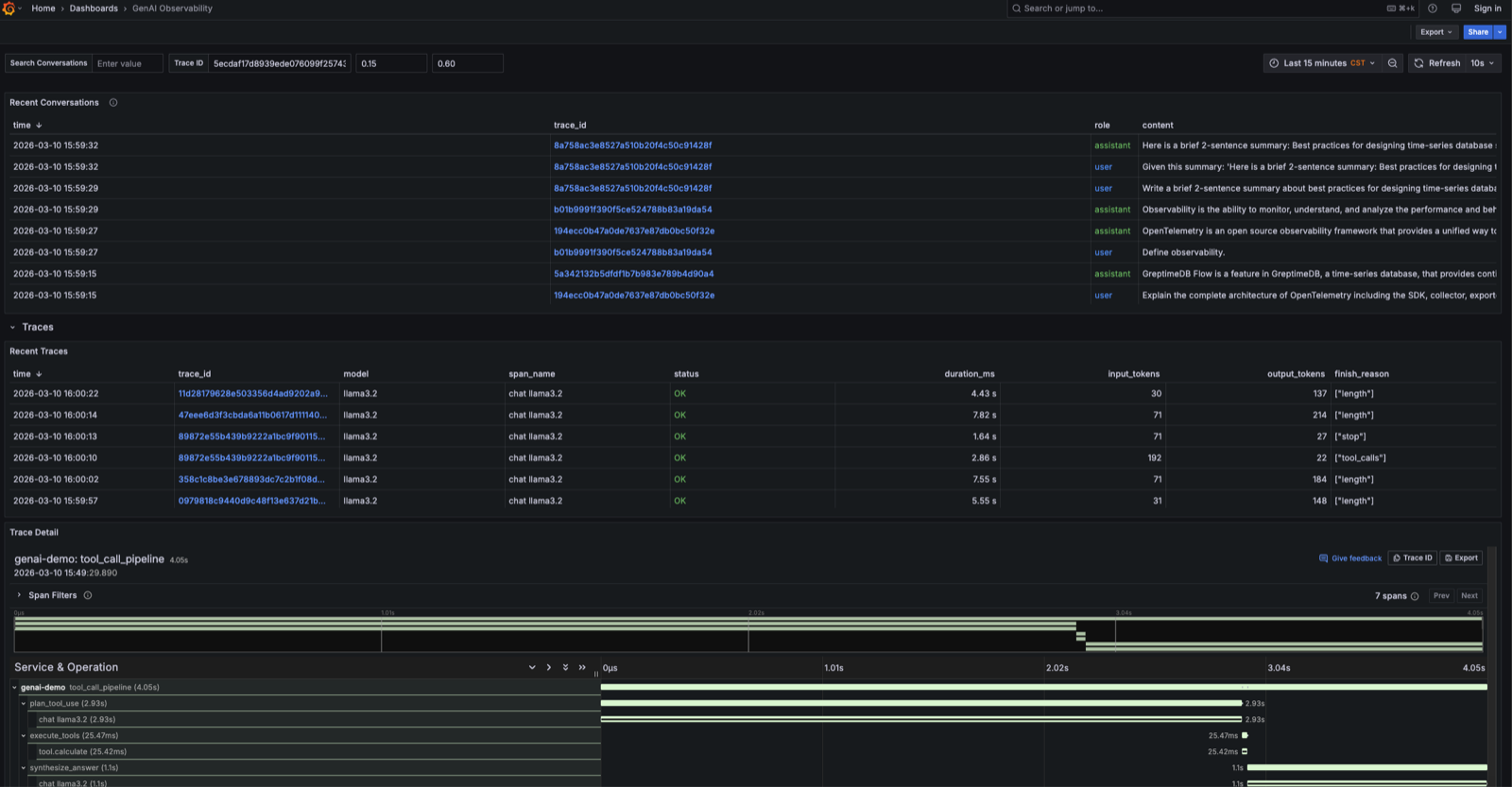
对于 tool calling、RAG pipeline、multi-agent 这类复杂场景,trace 结构会形成嵌套的 span 树。demo 里 tool calling 场景的完整 trace:
tool_call_pipeline (4.01s)
├── plan_tool_use (2.62s)
│ └── chat llama3.2 (2.62s) ← 模型判断需要调用工具
├── execute_tools (59.31ms)
│ └── tool.calculate (59.23ms) ← 模拟工具执行
└── synthesize_answer (1.33s)
└── chat llama3.2 (1.33s) ← 携带工具结果再次调用模型
这些嵌套结构完整保存在 GreptimeDB 中,通过 GreptimeDB Grafana 插件渲染成标准瀑布图,也可以直接用 SQL 查询特定 trace_id 的所有 span。
你能从数据里看到什么
成本估算:按模型实际用量,估算任意时间段的费用(以下以 gpt-4o-mini 定价为例,实际费率以 OpenAI 官网为准)——
sql
SELECT
"span_attributes.gen_ai.request.model" AS model,
SUM("span_attributes.gen_ai.usage.input_tokens") AS input_tokens,
SUM("span_attributes.gen_ai.usage.output_tokens") AS output_tokens,
ROUND(
SUM("span_attributes.gen_ai.usage.input_tokens") * 0.15 / 1000000
+ SUM("span_attributes.gen_ai.usage.output_tokens") * 0.60 / 1000000,
4
) AS estimated_cost_usd
FROM opentelemetry_traces
WHERE "span_attributes.gen_ai.system" IS NOT NULL
AND timestamp > NOW() - '1 hour'::INTERVAL
GROUP BY model
ORDER BY estimated_cost_usd DESC;各模型错误率:哪个模型最不稳定——
sql
SELECT
"span_attributes.gen_ai.request.model" AS model,
COUNT(*) AS total,
COUNT(CASE WHEN span_status_code = 'STATUS_CODE_ERROR' THEN 1 END) AS errors,
ROUND(
COUNT(CASE WHEN span_status_code = 'STATUS_CODE_ERROR' THEN 1 END) * 100.0
/ COUNT(*),
1
) AS error_rate_pct
FROM opentelemetry_traces
WHERE "span_attributes.gen_ai.system" IS NOT NULL
AND timestamp > NOW() - '1 hour'::INTERVAL
GROUP BY model
ORDER BY error_rate_pct DESC;PromQL 查询:OTel SDK 生成的 histogram metrics 同样支持 PromQL。两个 metric 的实际表名已在前文说明,PromQL 中直接使用:
promql
# token 消耗的 p95 分布
histogram_quantile(0.95,
sum(rate(gen_ai_client_token_usage_bucket[5m])) by (le, gen_ai_token_type)
)
# 各模型请求速率
sum(rate(gen_ai_client_operation_duration_seconds_count[5m])) by (gen_ai_request_model)GreptimeDB 同时支持 SQL 和 PromQL,Grafana dashboard 里两种查询方式并列,共用同一套数据。下图展示了 Token Efficiency、Model Comparison 和 Metrics(PromQL)三个区块:
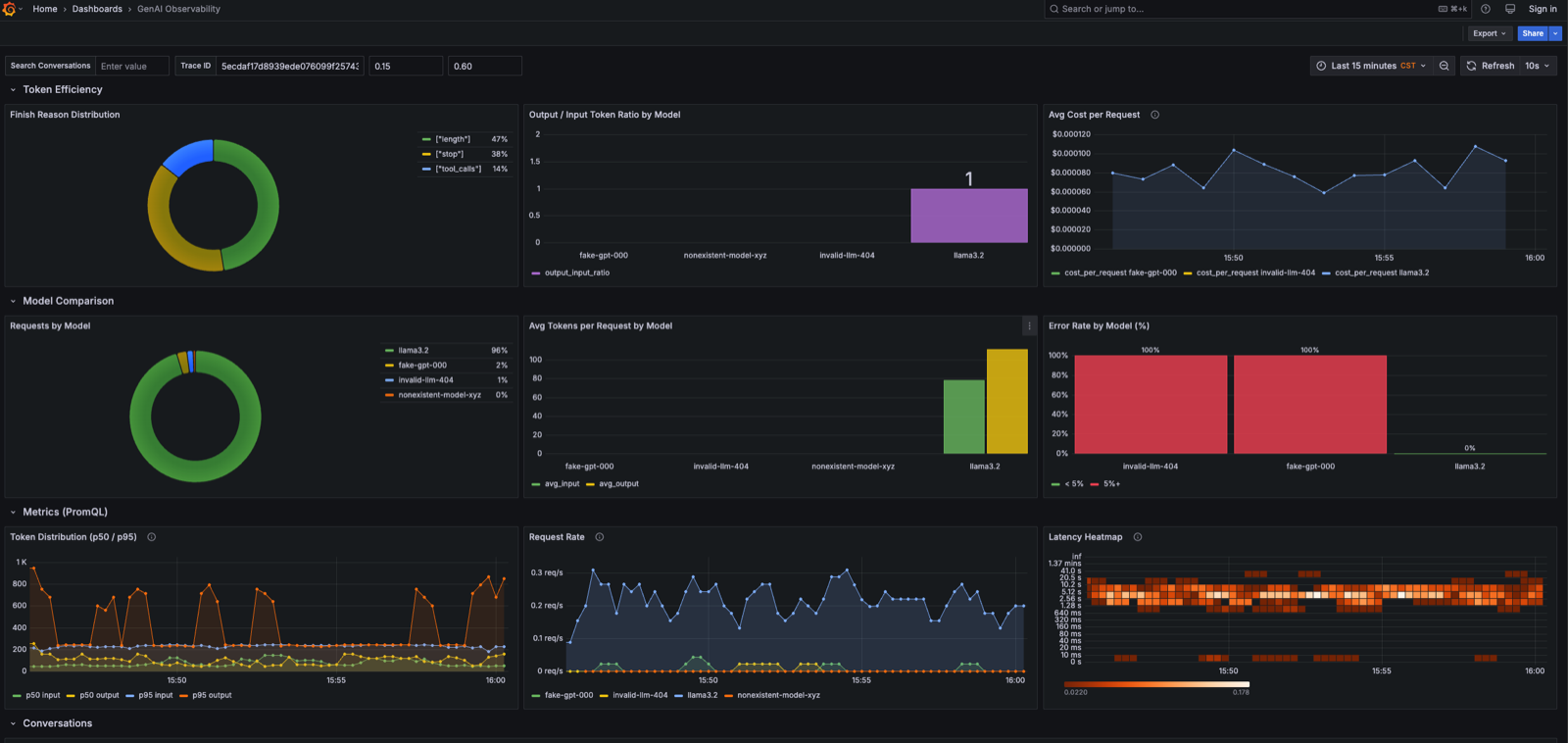
快速上手
项目开源在 GreptimeTeam/demo-scene,三步跑起来:
bash
# 0. 克隆仓库
git clone https://github.com/GreptimeTeam/demo-scene.git
cd demo-scene/genai-observability
# 1. 设置 OpenAI API Key
export OPENAI_API_KEY="sk-..."
# 2. 启动全部服务(GreptimeDB + Grafana + load generator + Flow 聚合)
docker compose --profile load up -d
# 3. 打开 Grafana:http://localhost:3000(admin / admin)
# 打开 "GenAI Observability" dashboard也支持本地 Ollama,不需要 OpenAI API Key:
bash
docker compose --profile local up -d
docker compose --profile local exec ollama ollama pull llama3.2
OPENAI_BASE_URL=http://ollama:11434/v1 MODEL_NAME=llama3.2 \
docker compose --profile load up -d小结
OTel GenAI 规范统一了 LLM 遥测数据的格式,但它只管数据怎么产出,不管数据存在哪、怎么查。这篇文章展示的是后半段:用 GreptimeDB 把 traces、metrics、logs 放在同一个库里,通过 Flow 从原始 span 直接聚合出指标,用 matches_term() 搜索历史对话,点 trace_id 跳到完整链路。SQL 和 PromQL 都支持,现有的 Grafana 工作流不用改。
如果你跑起来了,欢迎告诉我们你的 p95 延迟和 token 分布长什么样——尤其是同时跑多个模型的时候。

