本页内容
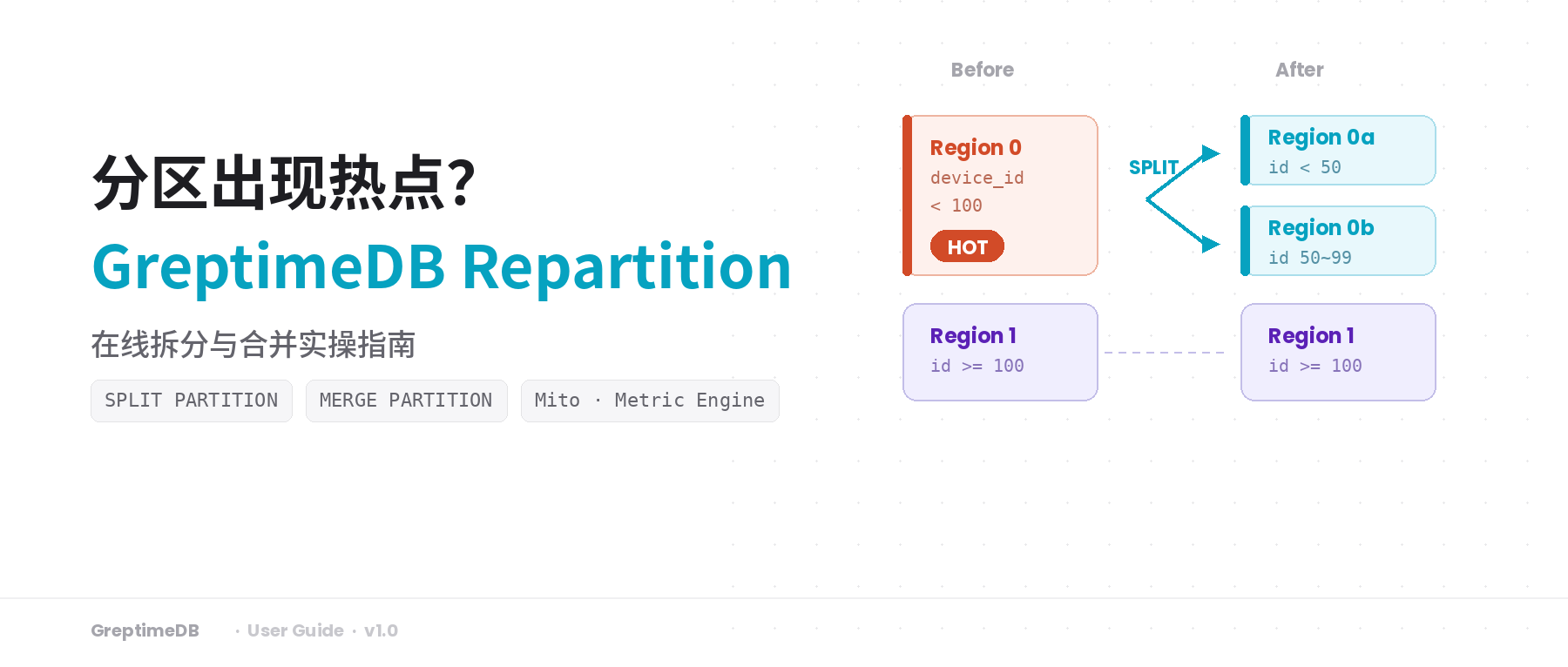
分区表跑久了,常见的麻烦不是"写不进去",而是负载分布逐渐跑偏。一种情况是热点:某些 Region(区域)的写入量远高于其他分区,读写时延被拉开。另一种是碎片化:业务变迁之后,一些 Region 变得又冷又小,占着资源却几乎没有负载。
如果你用过 HBase,会觉得这很眼熟——就是 Region Split 和 Region Merge 要解决的问题。GreptimeDB 通过 SPLIT PARTITION 和 MERGE PARTITION 在线调整分区边界,让规则重新贴合当前的数据分布。
这篇指南会说清楚三件事:
- 怎么判断一张表是否需要做 Repartition(重分区);
- Mito 引擎和指标引擎两种场景下的完整操作示例;
- 执行前后的检查清单和常见踩坑点。
一句话理解 Repartition:本质上是分区规则和 Region 路由的在线调整。不涉及数据文件的物理迁移,而是通过调整 Region 的 manifest 文件引用关系完成规则切换。
版本说明:Repartition(
SPLIT PARTITION/MERGE PARTITION)从 GreptimeDB v1.0-rc.1 开始引入。请确保使用最新版本进行测试。
背景:GreptimeDB 的分区机制
在进入操作之前,先快速过一下 GreptimeDB 分布式模式下分区表的基本结构。
GreptimeDB 分布式集群有三个核心组件:
- Frontend(前端节点):无状态的接入层,接收客户端请求,按分区规则把写入和查询路由到正确的 Datanode;
- Metasrv(元数据服务):集群的"大脑",存储表结构、分区规则和 Region 在 Datanode 上的分布信息;
- Datanode(数据节点):实际存储和处理数据的节点,每个 Datanode 可以承载多个 Region。
一张表在创建时可以通过 PARTITION ON COLUMNS 指定分区列和分区规则。每条分区规则对应一个 Region,Region 是 GreptimeDB 数据管理和调度的最小单位。Metasrv 负责把这些 Region 分配到不同的 Datanode 上,Frontend 根据 Metasrv 提供的路由信息把请求发到对应节点。

举个例子,假设按 device_id 分了三段,Metasrv 可能把三个 Region 分别分配给不同的 Datanode,也可能把其中两个放在同一个节点上——取决于集群当前的资源状况。
一个 Region 有相对固定的吞吐上限。表的 Region 越多,总吞吐容量越大;但 Region 数量增加也意味着更多的元数据开销和调度复杂度。所以关键不是"越多越好",而是让每个 Region 的负载尽量均匀。
当负载不再均匀——某些 Region 变成热点,或者某些 Region 冷到没有存在的必要——就轮到 Repartition 出场了。
更多细节可以参考官方文档:表分片。
什么时候该做 Repartition?
不需要先搭一套监控面板。出现下面这些信号,就值得评估了。
需要 Split(拆分)——热点:
- 某些分区长期写入量或查询时延明显高于其他分区;
- 同一张表不同 Region 的查询或写入时延差距在拉大;
- 业务维度变了,原有分区边界不再适合当前流量模式。
需要 Merge(合并)——碎片化:
- 历史上拆分过多次,部分 Region 数据量很小、几乎没有写入;
- Region 数量过多,元数据开销和调度压力增大;
- 相邻分区的流量都很低,合并后能减少资源占用、提高查询效率。
有了初步判断后,别急着改规则——先确认问题落在哪条规则上。
定位目标分区
把热点 Region 映射到分区规则
下面这条 SQL 把 Region 级别的写入统计和分区规则关联起来,直接看到哪条规则对应的 Region 压力最大:
sql
SELECT
t.table_name,
r.region_id,
r.region_number,
p.partition_name,
p.partition_description,
r.region_role,
r.written_bytes_since_open,
r.region_rows
FROM information_schema.region_statistics r
JOIN information_schema.tables t
ON r.table_id = t.table_id
JOIN information_schema.partitions p
ON p.table_schema = t.table_schema
AND p.table_name = t.table_name
AND p.greptime_partition_id = r.region_id
WHERE t.table_schema = 'public'
AND t.table_name = 'your_table'
ORDER BY r.written_bytes_since_open DESC
LIMIT 10;参考输出:
table_name | region_id | region_number | partition_name | partition_description | region_role | written_bytes_since_open | region_rows
demo_hotspot_map | 19524921327616 | 0 | p0 | device_id < 100 | Leader | 110 | 2
demo_hotspot_map | 19524921327617 | 1 | p1 | device_id >= 100 | Leader | 64 | 1written_bytes_since_open 长期偏高的规则,优先考虑拆分;相邻分区数值都很低的,考虑合并。
排除节点异常
有时候"看起来像热点"只是节点异常导致的局部抖动,跑一下这条查询先排除:
sql
SELECT
p.region_id,
p.peer_addr,
p.status,
p.down_seconds
FROM information_schema.region_peers p
WHERE p.table_schema = 'public'
AND p.table_name = 'your_table'
ORDER BY p.region_id, p.peer_addr;节点状态正常、热点或碎片化信号持续存在,就可以着手设计 Repartition 方案了。
information_schema.region_statistics是近似值,适合看相对差异和趋势。最好连续观察一段时间,避免把短时波动当成长期问题。
Repartition 执行时,系统内部发生了什么?
在生产环境操作之前,先了解一下执行过程。整个流程大致分 5 步:
- Frontend 校验新规则,Metasrv 计算新旧规则差异并生成执行计划;
- 系统按计划分组执行,期间会出现短暂的写入暂停窗口,完成元数据切换;
- Datanode 更新 Region 规则后,携带旧规则版本的写入会被拒绝,新版本写入进入暂存 (staged) 状态;
- 系统基于旧 manifest 和新旧规则的映射关系,计算并提交新 manifest;提交完成后,暂存变更对查询可见;
- 操作结束,compaction 恢复执行,相关缓存逐步 reload。

所以 Repartition 不是一个"完全无感"的操作——变更窗口内写入可能短暂失败,随后恢复。
写入侧一定要做重试
规则切换过程中有一个短暂的"写入敏感窗口":写入暂停、旧版本请求被拒绝、缓存刷新需要时间。客户端如果把这类失败直接当成最终失败,业务侧就会感知到异常;但只要写入侧有退避重试,这个窗口通常能平滑跨过去。
具体来说:
- 用指数退避 + 抖动 (exponential backoff with jitter);
- 关注"最终成功"而不是"每次都一次成功";
- 变更窗口内盯重试后的成功率,别只看瞬时失败数。
语法速览
SPLIT PARTITION
把一个分区拆成两个:
sql
ALTER TABLE table_name SPLIT PARTITION (
source_partition_expr
) INTO (
target_partition_expr_1,
target_partition_expr_2
);MERGE PARTITION
把两个分区合并成一个:
sql
ALTER TABLE table_name MERGE PARTITION (
partition_expr_1,
partition_expr_2
);DDL 选项
可以在语句末尾附加执行控制选项:
sql
ALTER TABLE table_name SPLIT PARTITION (
source_partition_expr
) INTO (
target_partition_expr_1,
target_partition_expr_2
) WITH (
TIMEOUT = '5m',
WAIT = false
);WAIT = false:立即返回procedure_id,适合异步跟踪;TIMEOUT:控制操作超时时间。
当前限制(开源版):只支持 1 拆 2、2 合 1,不支持一次拆分或合并更多 Region。这些语句只能在分布式集群中执行,要求共享对象存储和 GC 已正确启用。
场景一:Mito Engine 表的 Repartition
这个例子刻意保持简短:先按 device_id 分两段,再把热点分区拆细,最后合并回去。
建表
sql
CREATE TABLE demo_repart_mito (
ts TIMESTAMP TIME INDEX,
device_id INT,
host STRING,
method_name STRING,
latency DOUBLE,
PRIMARY KEY(device_id, host, method_name)
)
PARTITION ON COLUMNS (device_id) (
device_id < 100,
device_id >= 100
);写入样例数据
sql
INSERT INTO demo_repart_mito (ts, device_id, host, method_name, latency) VALUES
('2026-03-10 10:00:00', 10, 'host1', 'GetUser', 103.0),
('2026-03-10 10:00:01', 60, 'host1', 'CreateOrder', 180.0),
('2026-03-10 10:00:02', 120, 'host2', 'GetUser', 96.0);拆分热点分区
假设观察到 device_id < 100 对应的 Region 是热点,把它拆成两段:
sql
ALTER TABLE demo_repart_mito SPLIT PARTITION (
device_id < 100
) INTO (
device_id < 50,
device_id >= 50 AND device_id < 100
);验证
拆完之后,从规则和数据两个角度看一下:
sql
-- 分区规则
SELECT partition_name, partition_description
FROM information_schema.partitions
WHERE table_name = 'demo_repart_mito'
ORDER BY partition_name;
-- 数据完整性
SELECT count(*) AS row_count_after_repartition FROM demo_repart_mito;预期输出:
partition_name | partition_description
p0 | device_id < 50
p1 | device_id >= 100
p2 | device_id >= 50 AND device_id < 100
row_count_after_repartition
3三条规则,数据量没变。
合并碎片分区
后续如果这两个 Region 流量都回落了,变成冷小碎片,合并回去:
sql
ALTER TABLE demo_repart_mito MERGE PARTITION (
device_id < 50,
device_id >= 50 AND device_id < 100
);合并完同样跑一下验证:
sql
SELECT partition_name, partition_description
FROM information_schema.partitions
WHERE table_name = 'demo_repart_mito'
ORDER BY partition_name;
SELECT count(*) AS row_count_after_merge FROM demo_repart_mito;场景二:Metric Engine 表的 Repartition
指标引擎 (Metric Engine) 场景和 Mito 引擎最大的区别不在语法,而在操作对象。
指标引擎的逻辑表依赖物理表,所以分区调整要在物理表上做。在逻辑表上跑 Split 或 Merge,方向从一开始就错了。
建物理表和逻辑表
sql
-- 物理表
CREATE TABLE demo_metric_physical (
ts TIMESTAMP TIME INDEX,
host STRING,
method_name STRING,
latency DOUBLE,
PRIMARY KEY(host, method_name)
)
PARTITION ON COLUMNS (host) (
host < 'm',
host >= 'm'
)
ENGINE = metric
WITH (physical_metric_table = 'true');
-- 逻辑表
CREATE TABLE demo_metric_logical (
ts TIMESTAMP TIME INDEX,
host STRING,
method_name STRING,
latency DOUBLE,
PRIMARY KEY(host, method_name)
)
ENGINE = metric
WITH (on_physical_table = 'demo_metric_physical');写入样例数据
sql
INSERT INTO demo_metric_logical (host, latency, ts, method_name) VALUES
('a01', 100.0, '2026-03-10 10:10:00', 'GetUser'),
('h01', 220.0, '2026-03-10 10:10:01', 'CreateOrder'),
('m01', 130.0, '2026-03-10 10:10:02', 'GetUser');在物理表上拆分
sql
ALTER TABLE demo_metric_physical SPLIT PARTITION (
host < 'm'
) INTO (
host < 'h',
host >= 'h' AND host < 'm'
);验证
sql
-- 物理表分区规则
SELECT partition_name, partition_description
FROM information_schema.partitions
WHERE table_name = 'demo_metric_physical'
ORDER BY partition_name;
-- 通过逻辑表确认数据完整
SELECT count(*) AS row_count_after_split FROM demo_metric_logical;预期输出:
partition_name | partition_description
p0 | host < h
p1 | host >= m
p2 | host >= h AND host < m
row_count_after_split
3字符串边界的排序陷阱
指标引擎的分区边界按字符串字典序比较,有个容易踩的坑:'host10' < 'host2' 是成立的,因为逐字符比较时 '1' 小于 '2'。设计字符串类型的分区边界时要注意这一点。
合并碎片分区
流量回落后,把拆开的 Region 合并回去:
sql
ALTER TABLE demo_metric_physical MERGE PARTITION (
host < 'h',
host >= 'h' AND host < 'm'
);执行后的检查清单
跑完 Repartition 不代表结束,下面几项应该作为固定流程:
- 用
SHOW CREATE TABLE确认最终规则和预期一致; - 查
information_schema.partitions确认分区边界和数量正确; - 观察业务写入,确认重试后最终成功率稳定;
- 再跑一次前面的热点 SQL,和变更前的 TopN 对比——Split 场景看热度是否更均衡,Merge 场景看 Region 数量是否减少。
开源版 vs. 企业版
开源版提供了完整的 SPLIT PARTITION 和 MERGE PARTITION 能力,每次操作支持 1 拆 2 和 2 合 1。拆分或合并后,通常需要手动将 Region 迁移到更合适的节点。企业版在此基础上支持单次操作拆分或合并更多 Region,并自动完成 Region 负载均衡。
常见问题
规则不完整:新规则有空洞,部分数据不命中任何分区。拆分时确保新的两条规则完整覆盖原规则范围。
规则重叠:多个分区覆盖同一范围,导致数据路由冲突。
操作对象搞错了:在指标引擎的逻辑表上做 Split 或 Merge。分区调整只能在物理表上执行。
短暂写入失败:Repartition 期间的正常现象,写入侧有重试机制就行。
小结
分区表跑久了,出现热点或碎片化很正常。SPLIT PARTITION 拆热点,MERGE PARTITION 收碎片——配合着用,让分区规则跟上业务负载的变化。上生产之前先完整演练一遍,把写入重试和变更前后的热点对比纳入固定检查项。建议将监控配置上,随时注意有没有热点分区信号等出现。

