本页内容
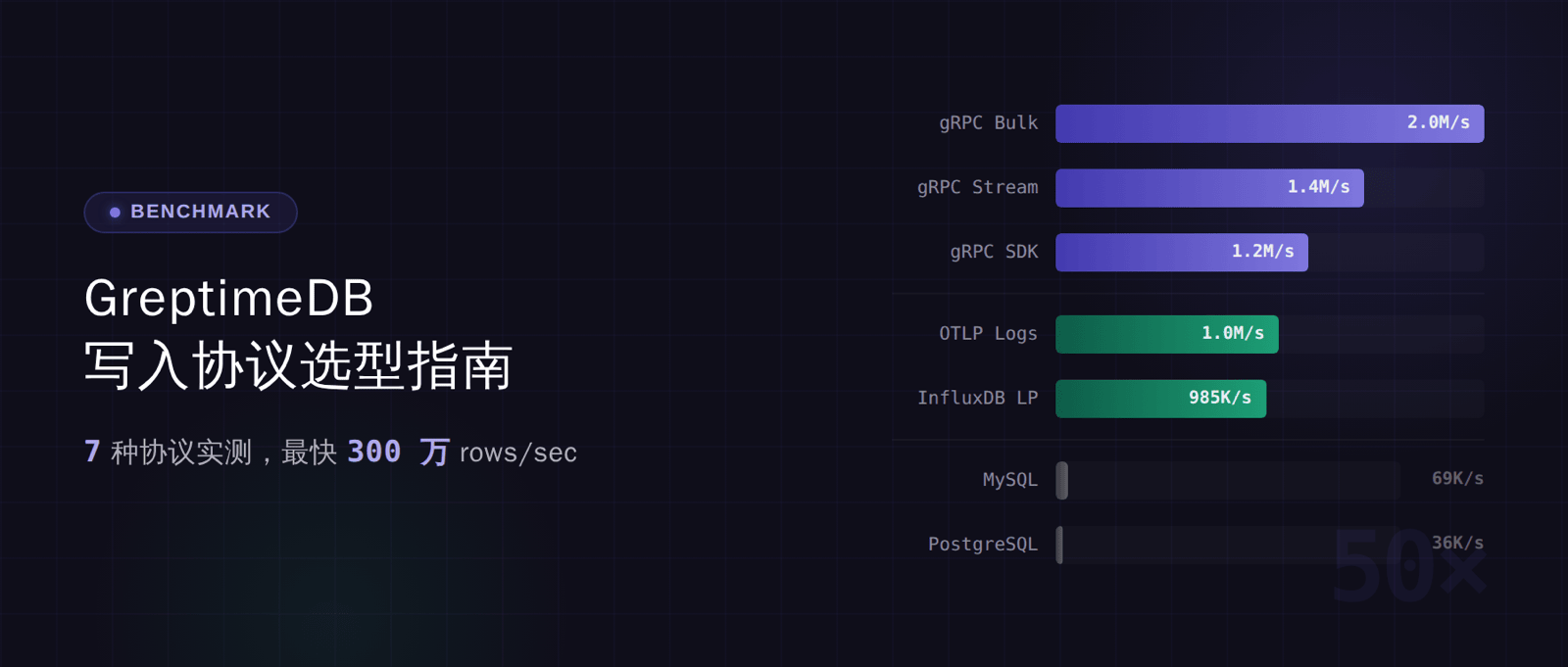
不同写入协议的性能差距可达 37 倍。这篇文章用 benchmark 数据帮你选对。
2026-04-21 更新:下文数据基于 GreptimeDB v1.0 GA 重新测试。和第一版相比有几处变化。OTLP 路径启用了
greptime_identitypipeline,attributes 被展开为独立列,存储布局与其他协议一致。v1.0 将 Flat SST / BulkMemtable 设为默认格式后,Bulk 路径对 Arrow schema 的严格校验暴露了 Go ingester 在 timestamp 类型上的不匹配,已在greptimedb-ingester-gov0.7.2 修复。PostgreSQL 启用了 prepared statement cache。版本背景见 v1.0 GA 发布博客。
GreptimeDB 支持十几种写入协议,社区里被问得最多的问题就是:该用哪个?
能找到的零散数据不少,但测试条件各不相同,没法直接对比。所以我做了一个开源 benchmark 工具 greptimedb-ingestion-benchmark,把几种最常用的协议放在完全相同的条件下跑了一遍。这篇文章分享结果和选型建议。
测了哪些协议
从众多写入方式中挑了三类:
GreptimeDB gRPC 协议,通过官方 SDK 使用,有三种写入模式:
| 写入模式 | 说明 |
|---|---|
| gRPC SDK (Unary) | 每批次一次 RPC 调用,最简单 |
| gRPC Stream | 双向流复用连接,适合高频、持续高吞吐 |
| gRPC Bulk (Arrow) | Arrow Flight DoPut 列式传输,吞吐最高 |
开放标准协议:InfluxDB Line Protocol(HTTP 文本格式)和 OTLP Logs(HTTP + Protobuf)。
SQL 协议:MySQL INSERT 和 PostgreSQL INSERT。
这里 OTLP 测的是 Logs 而不是 Metrics。原因是 GreptimeDB 的 OTLP 数据模型中,Metrics 会把每个 metric name 映射为独立的表。本次 benchmark 有 5 个指标字段,Metrics 模型会拆成 5 张表,没法和其他协议公平对比。Logs 模型把所有字段写入同一张表,测试条件一致。本轮 OTLP Logs 路径启用了 greptime_identity pipeline,将 log attributes 展开为独立列,而不是统一写入单个 JSON 列,存储布局与其他协议一致。
关于 Schemaless(自动建表):gRPC SDK、gRPC Stream、InfluxDB LP、OTLP 都支持写入时自动建表[1],新字段直接写,GreptimeDB 自动加列。SQL INSERT 和 gRPC Bulk (Arrow) 需要提前建表。SQL 是因为 INSERT INTO 依赖已有表结构,Arrow Bulk 是因为 DoPut 接口需要目标表已存在来做列映射。数据结构不固定的场景(IoT 设备字段变化、LLM 对话数据等),优先选支持 Schemaless 的协议。
测试条件
1000 万行,100 万个时间序列(1000 台主机 × 5 region × 10 datacenter × 20 service),每行 5 个 float64 指标字段,固定随机种子(seed=42)。每种协议写入独立表,5 并发 worker,SDK 全部默认配置。
测试环境:MacBook Pro 14-inch(M4 Max, 48 GB),GreptimeDB v1.0 GA standalone 模式,greptimedb-ingester-go v0.7.2。这是单机测试,目的是比较协议间的相对差异,不是测绝对吞吐上限。生产环境分布式集群的绝对数值会更高,但协议间的排序一致。完整方法论见仓库 README。
结果
batch=1000,100 万 series
100 万时间序列接近真实生产环境的基数,batch=1000 是大多数场景的合理默认值。
| 协议 | 吞吐 (rows/sec) | 耗时 | P50 延迟 | P99 延迟 |
|---|---|---|---|---|
| gRPC Bulk (Arrow) | 2,678,839 | 3.7 秒 | 1.54 ms | 8.80 ms |
| gRPC Stream | 1,562,134 | 6.4 秒 | 2.88 ms | 10.77 ms |
| gRPC SDK | 1,174,221 | 8.5 秒 | 4.15 ms | 10.80 ms |
| InfluxDB LP | 889,051 | 11.3 秒 | 5.42 ms | 13.06 ms |
| OTLP Logs (HTTP) | 621,367 | 16.1 秒 | 7.79 ms | 16.38 ms |
| PostgreSQL INSERT | 73,760 | 135.6 秒 | 66.58 ms | 101.58 ms |
| MySQL INSERT | 72,103 | 138.7 秒 | 67.65 ms | 119.37 ms |
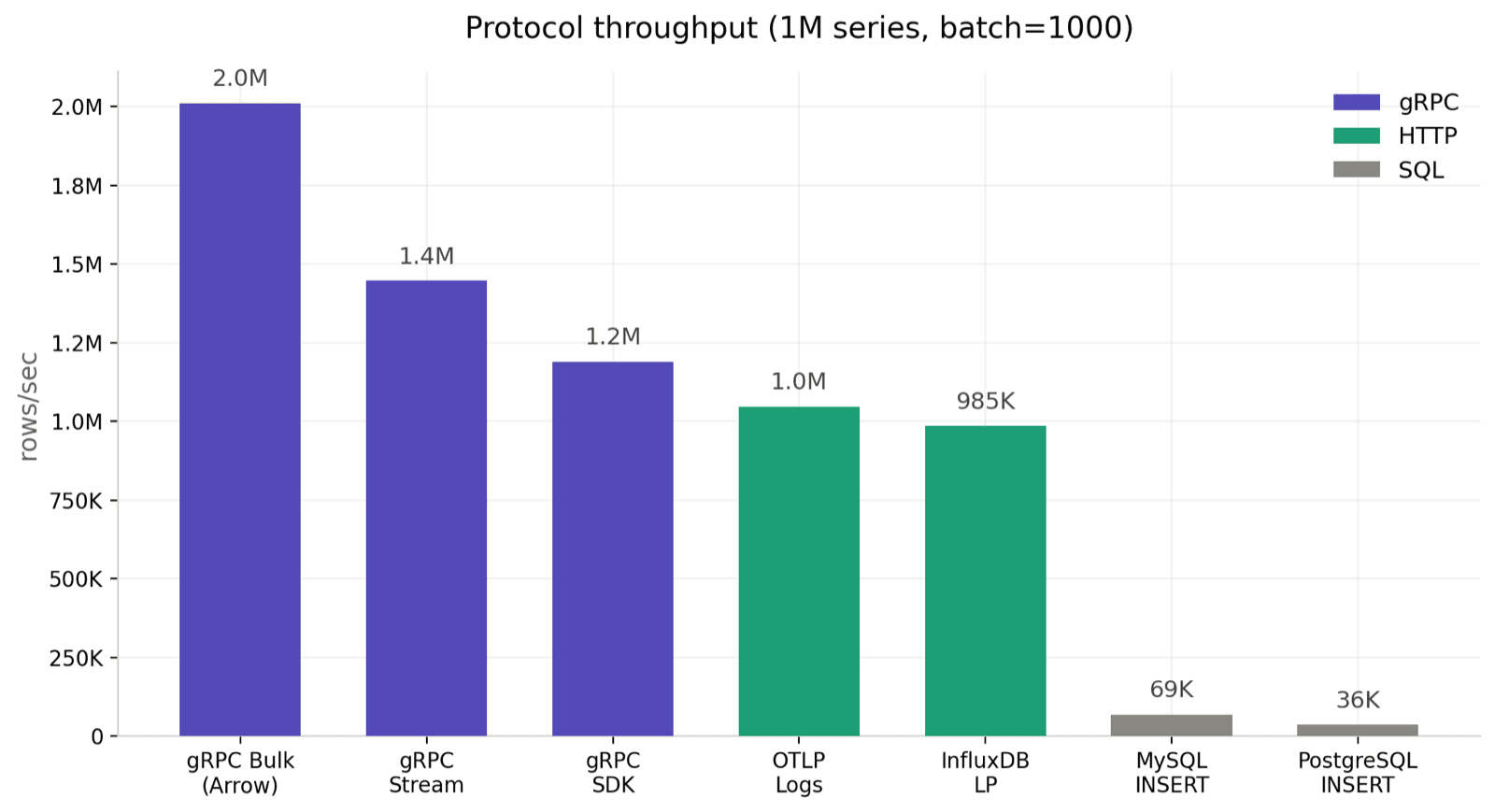
gRPC 三种模式在 117-268 万/秒这个区间。HTTP 协议里 InfluxDB LP 约 89 万/秒,OTLP Logs 约 62 万/秒,掉一档。SQL 在 7.2-7.4 万/秒。最快和最慢差了大约 37 倍。
OTLP 吞吐 62 万落在 InfluxDB LP 之下,这符合预期:两者同样走 HTTP,每批次一次完整的请求-响应,但 OTLP 路径还需要在服务端执行 greptime_identity pipeline,把 attributes 展开为独立列,这部分 CPU 开销是它落后的主要原因。代价换来的是与其他协议一致的存储布局;下面"时间序列基数的影响"一节还会看到,这条路径对 cardinality 几乎不敏感。
SQL 的结果需要多说一句:本次测试的连接池大小和并发数都只有 5,这是 benchmark 统一的配置。实际使用中,通过增大连接池和并发数可以提升 SQL 写入吞吐,但这不在本次测试的覆盖范围内。这里的数据反映的是相同并发条件下各协议的相对表现。
低基数参考:batch=1000,10 万 series
时间序列较少的场景(几百台主机的监控之类),大多数协议基本持平,但有一个例外:
| 协议 | 吞吐 (rows/sec) | P50 延迟 | P99 延迟 |
|---|---|---|---|
| gRPC Bulk (Arrow) | 1,950,517 | 1.37 ms | 12.92 ms |
| gRPC Stream | 1,653,225 | 2.64 ms | 11.47 ms |
| gRPC SDK | 1,228,298 | 3.96 ms | 9.87 ms |
| InfluxDB LP | 945,912 | 4.99 ms | 15.26 ms |
| OTLP Logs (HTTP) | 616,848 | 7.46 ms | 18.16 ms |
| PostgreSQL INSERT | 74,218 | 65.90 ms | 106.31 ms |
| MySQL INSERT | 73,813 | 66.12 ms | 107.61 ms |
gRPC Bulk 在 10 万 series 下反而比 100 万 series 更慢,与其他协议趋势相反,并非笔误。原因在下面"时间序列基数的影响"一节展开。
批次大小的影响
4 种批次大小(50 / 200 / 1000 / 2000),100 万 series:
| 协议 | batch=50 | batch=200 | batch=1000 | batch=2000 |
|---|---|---|---|---|
| gRPC Bulk (Arrow) | 806,495 | 1,524,316 | 2,678,839 | 3,335,918 |
| gRPC Stream | 641,485 | 1,076,555 | 1,562,134 | 1,759,202 |
| gRPC SDK | 552,341 | 950,197 | 1,174,221 | 1,415,292 |
| InfluxDB LP | 507,072 | 761,088 | 889,051 | 1,082,739 |
| OTLP Logs (HTTP) | 425,849 | 564,228 | 621,367 | 683,222 |
| MySQL INSERT | 66,788 | 67,692 | 72,103 | 73,534 |
| PostgreSQL INSERT | 66,490 | 68,176 | 73,760 | 73,617 |
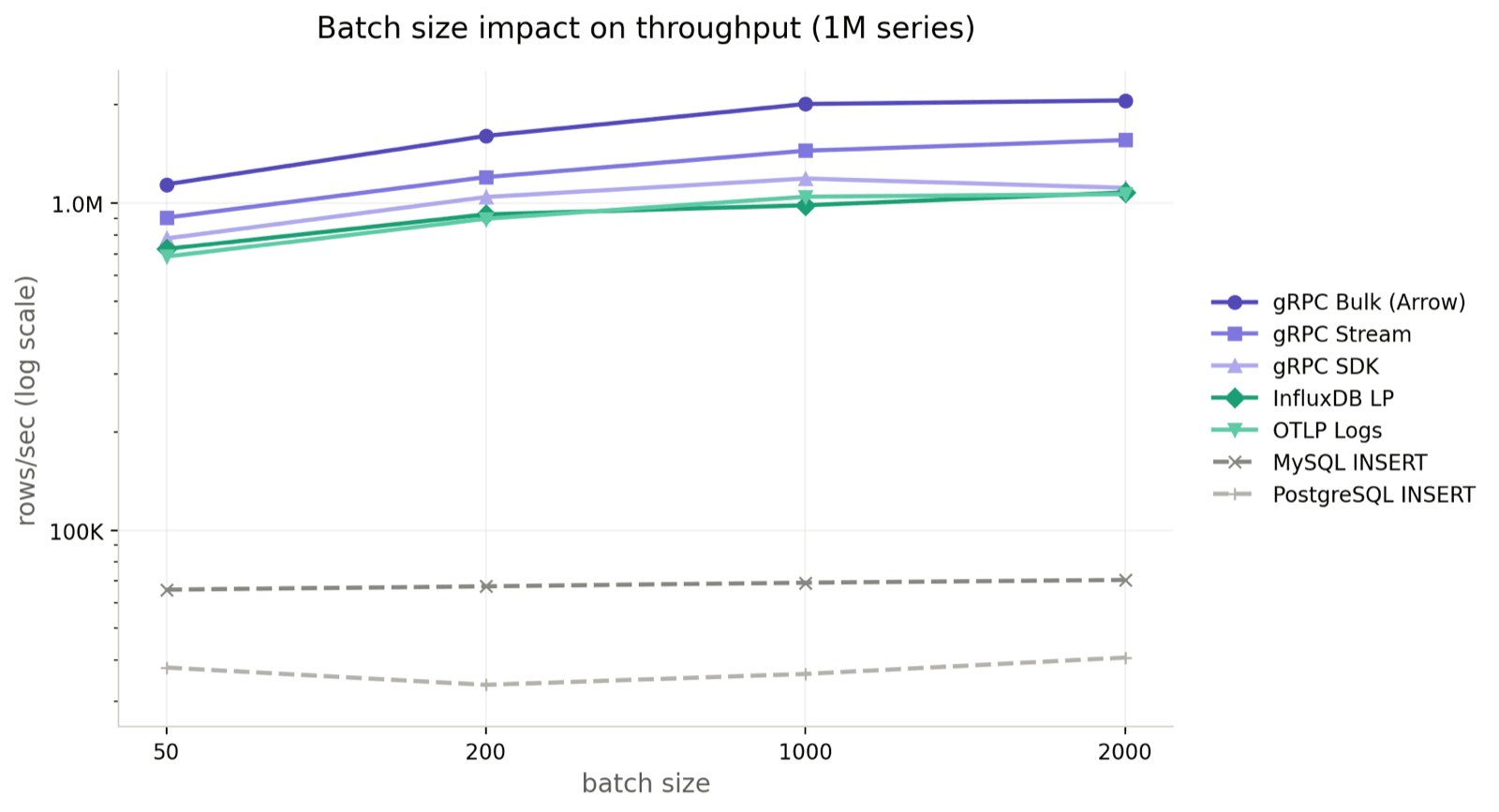
gRPC 系列持续受益于更大的批次。Bulk 从 batch=50 的 80.6 万一路涨到 batch=2000 的 334 万,超过 4 倍。Stream 约 2.7 倍(64 万 → 176 万),SDK 2.6 倍。延迟代价也在可接受范围 —— 即使 batch=2000,gRPC Bulk P99 也只在十几毫秒(13.78 ms)。
InfluxDB LP 的批次收益优于 OTLP(50.7 万 → 108 万 vs 42.6 万 → 68.3 万)。OTLP 走 protobuf 再加 pipeline 处理,比 InfluxDB 纯文本 line protocol 路径重。
SQL 几乎没变。MySQL 从 6.7 万到 7.4 万,PostgreSQL 从 6.6 万到 7.4 万。吞吐被 INSERT ... VALUES (...) 的逐行执行模型卡住了,batch 再大也只是把延迟摊到一条语句里(P99 从 7 ms 飙到 200 ms+)。
时间序列基数的影响
先交代一个 v1.0 的前提,本节观察都建立在这之上:v1.0 起,Flat SST / BulkMemtable 是默认存储格式(详见 v1.0 GA 发布博客)。benchmark 中所有协议的写入都经过新的 BulkMemtable,下面的 cardinality 对比能直接反映出这个变化的影响。
10 万 vs 100 万 series,batch=1000:
| 协议 | 10 万 series | 100 万 series | 差异 |
|---|---|---|---|
| gRPC Bulk (Arrow) | 1,950,517 | 2,678,839 | +37.3% |
| gRPC Stream | 1,653,225 | 1,562,134 | −5.5% |
| gRPC SDK | 1,228,298 | 1,174,221 | −4.4% |
| InfluxDB LP | 945,912 | 889,051 | −6.0% |
| OTLP Logs (HTTP) | 616,848 | 621,367 | +0.7% |
| PostgreSQL INSERT | 74,218 | 73,760 | −0.6% |
| MySQL INSERT | 73,813 | 72,103 | −2.3% |
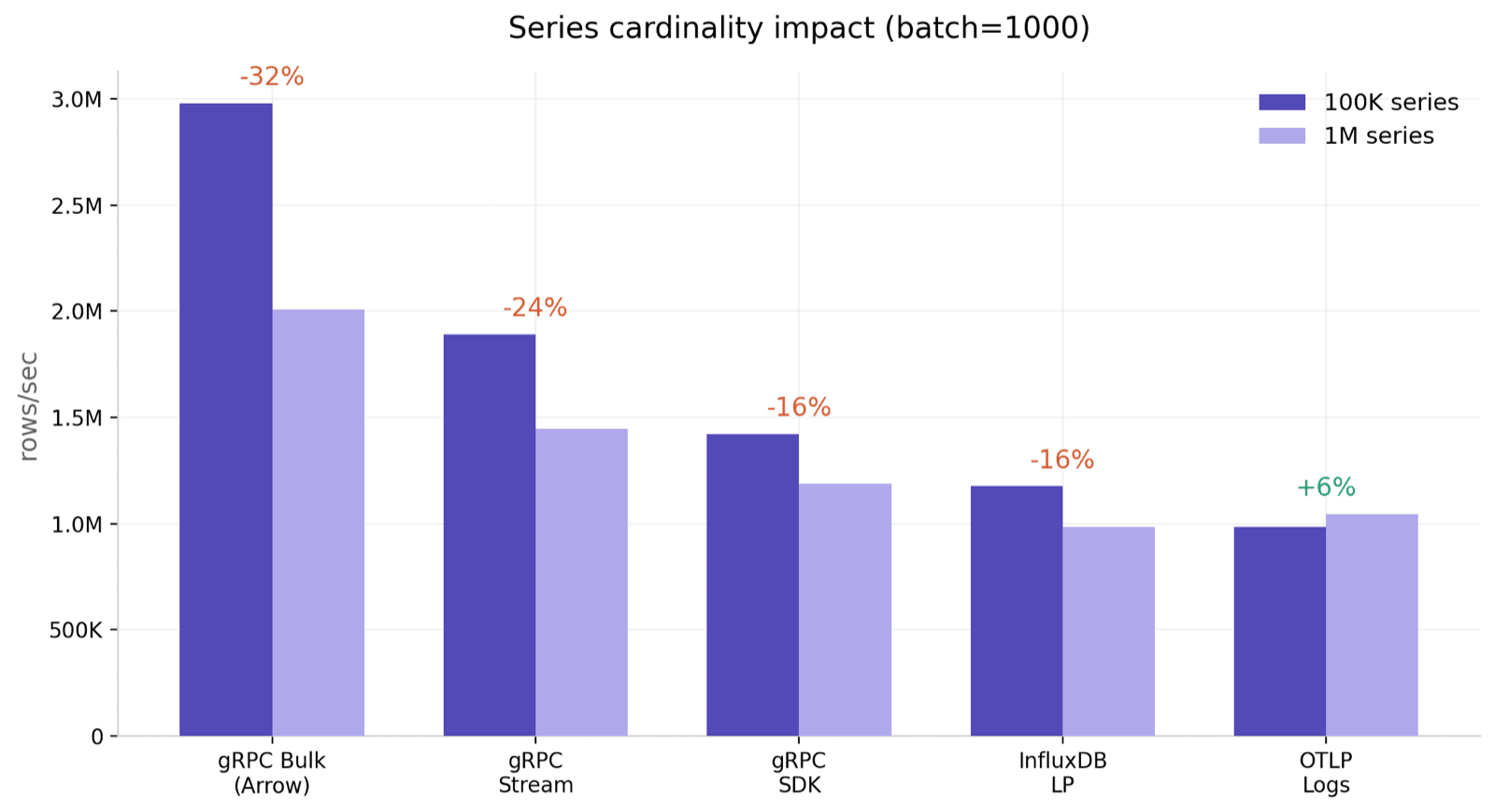
两点值得关注。其一,除 gRPC Bulk 外,其他协议基本持平,差异都在 ±6% 以内;其二,gRPC Bulk 不仅不持平,方向还反了——100 万 series 比 10 万 series 快 37.3%。多次重复运行结果稳定,不是单次偶然。
差距真正在哪
10M rows、batch=2000 下 dump information_schema.region_statistics 和 mito flush metrics,结果相当清楚:
| 指标 | 10 万 series | 100 万 series |
|---|---|---|
| 吞吐 rows/sec | 2,159K | 2,933K(+36%) |
| wall clock | 4.63 s | 3.41 s(Δ = −1.22 s) |
| region 数 | 1 | 1 |
flush 次数(reason="EngineFull") | 3 | 3 |
| SST 输出大小 | 491 MB | 493 MB |
flush_elapsed_sum{type="total"} | 2.31 s | 1.02 s |
flush_memtables sum | 2.28 s | 0.99 s |
write_batch(parquet IO)sum | 2.23 s | 2.01 s |
几个事实可以直接从上面的表格中读出。两次运行的 region 数、flush 次数、SST 输出大小均相同,差距不来自触发更多 flush 或写入更多字节。write_batch(parquet IO 阶段)两者也基本持平,瓶颈同样不在 IO。真正有显著差异的只有 flush_memtables:10 万的耗时是 100 万的 2.3 倍,1.29 s 的差值基本对应 1.22 s 的 wall clock 差距。cardinality 的反转,本质上是 BulkMemtable 单次 flush 耗时的反转。
对照实验:没有 flush 就没有差距
如果 flush 是差距的来源,那把总写入量缩到不会触发 flush,差距应该消失。实测也确实如此:
| 场景 | 10 万 | 100 万 | flush 次数 |
|---|---|---|---|
| total=1M rows(不触发 flush) | 5,138K / 4,981K rows/sec | 5,425K / 3,537K rows/sec | 0 |
| total=10M rows(触发 3 次 flush) | 2,186K rows/sec | 2,929K rows/sec | 3 |
没有 flush 时,两种 cardinality 分不出高低(其中一次 10 万 series 还略领先)。一旦 flush 开始触发,差距就出现了。
5000 万行规模:同样的模式
为了确认这不是 1000 万行规模下的 artifact,我们在同一台机器、同一配置下,把数据量放到 5000 万行又跑了一遍:
| batch | 10 万 rows/sec | 100 万 rows/sec | 100 万 领先 | 10 万 flush 次数 / 总耗时 | 100 万 flush 次数 / 总耗时 | 单次 flush 比值 |
|---|---|---|---|---|---|---|
| 1000 | 1,604K | 2,235K | +39% | 12 / 5.80 s | 12 / 3.85 s | 1.5× |
| 10000 | 3,171K | 4,090K | +29% | 12 / 14.86 s | 12 / 10.22 s | 1.45× |
两种 cardinality 下 flush 次数相同(12 次),整体形状一致,差距依然集中在单次 flush 的耗时上,10 万的 flush 比 100 万慢 ~50%。差距从 +39%(batch=1000)收窄到 +29%(batch=10000),但没有消失。1000 万和 5000 万两个规模的结论一致,不是小数据量下的噪声。
为什么只有 gRPC Bulk 看到
其他协议在写入侧都有 per-row 开销:partition 路由、行转列、schema 校验,这部分成本随 cardinality 线性增长。它大致抵消了 memtable flush 侧在高 cardinality 下的加速,所以 Stream、SDK、InfluxDB、OTLP、SQL 的波动都只在几个百分点。Bulk 把 per-row 开销压到接近零(整批 Arrow RecordBatch 直接 append 成 part),flush 侧的 cardinality 效应才显露出来。在这个量级下,它恰好对用户有利。
为什么差距这么大
gRPC 快在编码效率。Protocol Buffers 二进制格式,体积小,解析快。三种模式的区别在于连接模型:SDK 每批次独立 RPC;Stream 用双向流复用连接,省掉连接协商开销,吞吐比 Unary 高约 20-30%;Bulk 走 Arrow Flight 协议[2]做列式传输,GreptimeDB 内部也用 Arrow 做内存格式,写入接近 zero-copy,所以能到 268 万/秒(batch=2000 下到 334 万/秒)。代价是需要提前建表。
InfluxDB LP 和 OTLP 都走 HTTP,每个批次一个完整的请求-响应周期,这是它们的天花板。InfluxDB LP 虽然是文本格式,但路径本身比较薄;OTLP 还要多跑一道 greptime_identity pipeline,所以即使两者都是 HTTP + 批量模式,OTLP 这次还是落在 InfluxDB LP 下面。
SQL 慢有两层原因。第一是处理路径长:客户端拼 INSERT INTO ... VALUES (...) 文本,服务端解析 SQL,逐行做类型转换,再写入,每一步都有开销,文本体积也远大于二进制格式。第二是并发模型的限制:MySQL 和 PostgreSQL 协议都是同步连接模型,一个连接同一时间只能处理一条语句,并发能力受连接数限制,跟 gRPC 的异步流式模型差距很大。这不是 GreptimeDB 特有的问题,任何通过 SQL 协议写入的时序数据库 (Time Series Database) 都面临同样的开销。
怎么选
大多数场景用 gRPC SDK。 约 117 万 rows/sec,代码简单,支持 Schemaless,我们的官方 SDK 覆盖 Go、Java、Rust、Erlang、.NET。没有特殊需求的话,这是最稳妥的起点。如果技术栈是 JS/TS(目前没有 gRPC 的 JS 客户端),用 InfluxDB LP 或 OTLP 替代,它们有成熟的 JS 库,性能也在几十万到百万级。
批量导入用 gRPC Bulk。 数据迁移、历史回填、ETL 场景。batch=1000 时约 268 万 rows/sec,batch=2000 时超过 334 万 rows/sec,1000 万行 4 秒以内写完。需要提前建好表。Erlang SDK 暂不支持这个模式。
高频或持续高吞吐用 gRPC Stream。 IoT 网关、监控采集器这种长时间不间断写入的场景,或者写入频率很高、每次数据量不大但频次密集的场景。双向流复用连接避免了反复建连的开销,吞吐约 156 万 rows/sec,支持 Schemaless。
已有 InfluxDB 生态就用 InfluxDB Line Protocol。 在跑 Telegraf,或者应用已经输出 Line Protocol?直接接 GreptimeDB 的兼容接口,约 89 万 rows/sec,迁移成本接近零。
已有 OTel 生态就用 OTLP。 在用 OpenTelemetry Collector 或 OTel SDK?OTLP 约 62 万 rows/sec,支持 Schemaless。吞吐低于 InfluxDB LP 是因为服务端要跑 greptime_identity pipeline 把 attributes 展开成独立列 —— 这个代价换来的是与其他协议一致的存储布局。Metrics 和 Logs 的数据模型不同[3]:Metrics 按 metric name 分表,适合 Prometheus 式监控;Logs 写入统一的日志表,适合结构灵活的数据。根据实际数据模型选。
开发调试用 MySQL / PostgreSQL。 写入吞吐低(MySQL/PG 都在 7.2 万 rows/sec 左右),但 mysql、psql 命令行、DBeaver、各种 ORM 和语言驱动都能直接连。不支持 Schemaless,需先建表。写入慢不代表查询慢,MySQL/PG 协议是 GreptimeDB 查询的主要接口。
速查表
| gRPC SDK | gRPC Stream | gRPC Bulk | InfluxDB LP | OTLP | MySQL/PG | |
|---|---|---|---|---|---|---|
| 吞吐 | 117 万/s | 156 万/s | 268 万/s | 89 万/s | 62 万/s | ~7.2 万/s |
| Schemaless | ✅ | ✅ | ❌ 需建表 | ✅ | ✅ | ❌ 需建表 |
| 传输格式 | Protobuf | Protobuf | Arrow IPC | 文本 | Protobuf | SQL 文本 |
| SDK 覆盖 | Go/Java/Rust/Erlang/.NET | 同左 | 同左(Erlang 除外) | 各语言 | 各语言 | 各语言 |
| 场景 | 通用默认 | 高频/持续写入 | 批量导入 | InfluxDB 迁移 | OTel 生态 | 查询和调试 |
一句话总结:性能敏感选 gRPC(SDK 起步,需要更高吞吐再上 Stream 或 Bulk),已有生态选对应的兼容协议(InfluxDB LP / OTLP),SQL 用来查询和调试。
自己跑一遍
bash
git clone https://github.com/killme2008/greptimedb-ingestion-benchmark.git
cd greptimedb-ingestion-benchmark
bin/run.sh脚本自动下载 GreptimeDB、启动、跑完全部协议、输出结果。支持自定义:
bash
bin/run.sh -protocols grpc,grpc_bulk,influxdb -batch-size 500,1000,2000
bin/run.sh -host 10.0.0.1 # 连接远程实例测试结果和这里的有差异?或者在特定场景下有不同发现?欢迎到 GitHub Discussion 或 Slack 聊聊。

