
本页内容
本文基于对 D6 创始人之一 Jacson 的采访,由 D6 与 Greptime 团队共同撰写。
Jacson 拥有超过 10 年的软件开发经验。D6 是一支来自巴西的团队,他们正在构建一个工业物联网 (Industrial IoT) 平台,目标是把云基础设施中那套成熟的可观测性 (Observability) 体系搬到工厂车间。他们的产品监测工业设备的能耗和生产信号,为制造工厂和矿业企业提供设备运行状况的实时与历史数据分析能力。这篇文章记录了他们从 VictoriaMetrics 迁移到 GreptimeDB 的过程、系统架构,以及实践中踩过的坑。
目标:像监控云服务一样监控工厂设备
D6 想做的事情很直接——把你在云系统中习以为常的指标、监控、仪表盘,带到工厂车间的机器上。他们的目标是帮助企业理解设备的运行方式,从而提升工厂效率,无论是实时状态还是长期趋势。
他们的平台在工业设备上安装传感器,通过部署在现场的边缘网关 (Edge Gateway) 采集电气和运行数据,再将数据流式传输到云端进行集中分析。
采集的数据包括:
- 电气参数:电压、电流、功率
- 从设备运行中提取的生产指标
- 通过传感器行为推断的运行状态
目前的部署覆盖约 20 台工业设备、10 个边缘网关、30 个传感器,累计存储了超过 12 亿条数据。他们的目标是保留长达 10 年的历史数据——工业能耗的长期趋势才是真正有价值的部分。
VictoriaMetrics 为什么不够用
在使用 GreptimeDB 之前,D6 用的是 VictoriaMetrics。在指标写入和存储方面,VictoriaMetrics 确实高效,PromQL 查询也能满足日常的仪表盘需求。
问题出在他们需要更灵活地访问底层数据的时候。有一个具体的场景:他们需要导出历史数据并重新组织结构做进一步分析,但发现用 VictoriaMetrics 实现这件事并不容易。
这促使他们开始寻找一个既能高效处理时序写入、又具备分析能力的数据库。TimescaleDB 进入了候选名单,SQL 的灵活性正是他们想要的,但在他们的工作负载下,TimescaleDB 需要的基础设施资源太多,成本不可接受。
他们真正需要的是:高效的时序数据写入 + SQL 分析能力,同时不大幅增加运维复杂度。
为什么选择 GreptimeDB
D6 在调研开源时序数据库时发现了 GreptimeDB。最吸引他们的是同一个系统中同时支持 SQL 和 PromQL。
这种组合直接对应了他们的工作流:
- PromQL 用来构建仪表盘和指标监控
- SQL 用来做更深入的历史数据分析和数据变换
运维简单也是一个重要因素。GreptimeDB 的单机模式 (Standalone) 让他们能保持简单的基础设施,控制早期阶段的成本。
GreptimeDB 的 gRPC 写入接口让云端的数据写入管道可以直接将数据送入数据库,不需要额外的适配层。而 GreptimeDB 的分布式架构让他们有信心,随着客户和设备数量增长,系统可以平滑扩展,不必迁移到另一个数据库。
架构
D6 的架构围绕"边缘采集 + 云端分析"展开:
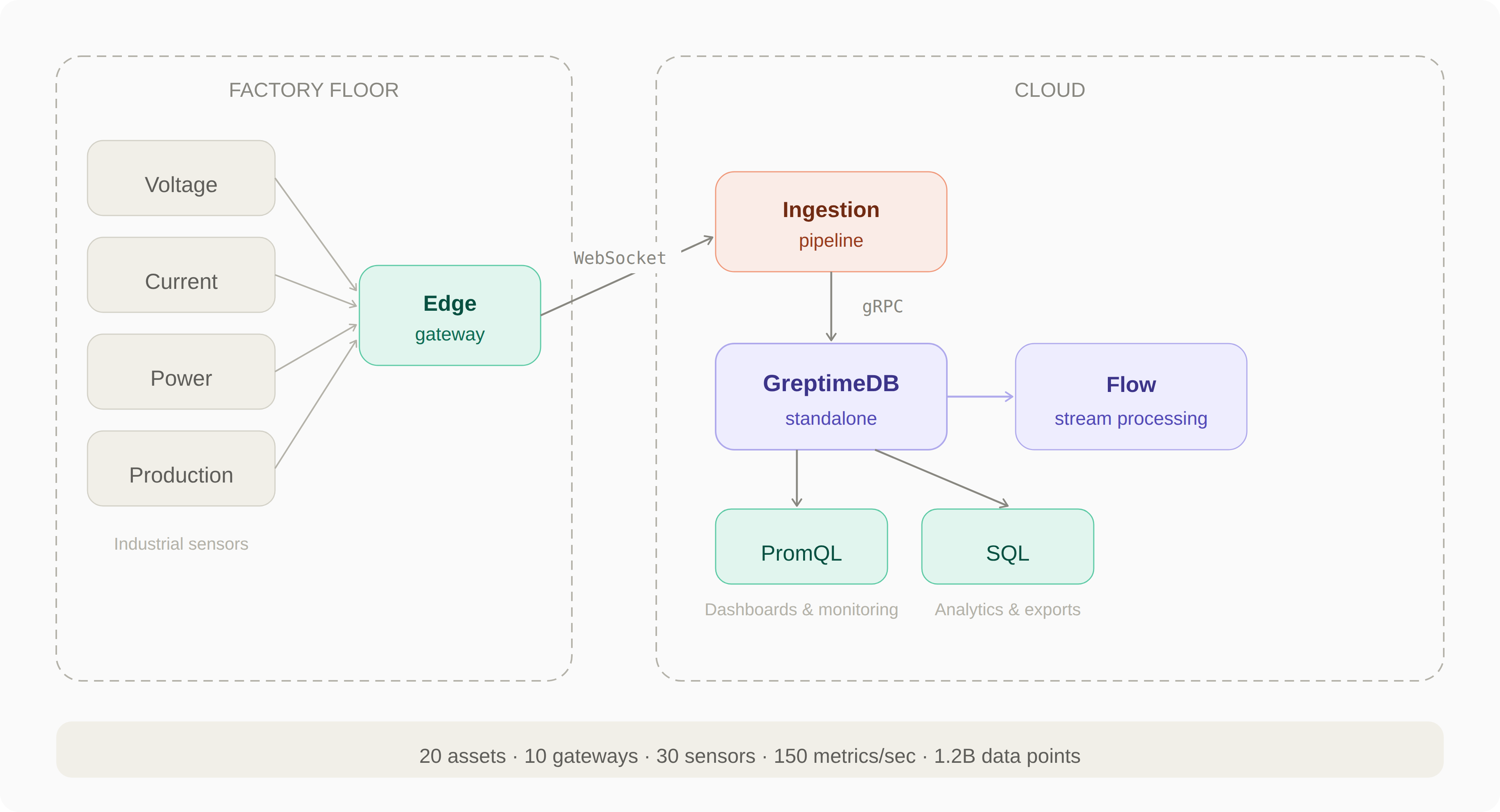
传感器直接从设备上采集电气和运行参数。部署在每个客户现场的边缘网关汇聚数据,通过 WebSocket 长连接把数据推送到云端的数据写入管道。数据写入管道再通过 gRPC 将数据写入 GreptimeDB。上层的仪表盘和分析系统通过 SQL 和 PromQL 查询数据。
目前是一个 GreptimeDB 单机节点持续写入,稳定管理着超过 12 亿条数据。
从原始信号到运营洞察
采用 GreptimeDB 之后最大的改善,是能够将 SQL 查询与 Flow(GreptimeDB 内置的流处理引擎)结合,从原始传感器数据中提取更高层次的业务指标。
用 VictoriaMetrics 的时候,D6 基本只能用 PromQL 做监控。换成 GreptimeDB 后,他们可以用 SQL 查询历史数据,同时用 Flow 对实时写入的数据做预处理,生成衍生指标。
举个实际的例子。工业设备会产生详细的电气信号。通过分析一台设备的能耗特征随时间的变化,D6 可以推断出:
- 设备是在运行还是空闲
- 运行周期的边界
- 某些情况下,甚至可以根据能耗模式判断正在生产的产品类型
直接在数据库内完成时序数据的处理和加工,简化了他们的数据管道。不需要额外的流处理系统,随着数据积累,他们可以持续优化这些衍生指标。
实践经验
查询性能:非毫秒时间索引的过滤下推问题
D6 发现部分 PromQL 查询随着时间推移越来越慢。通过 TQL ANALYZE 排查后,他们找到了原因:系统扫描了远超必要的数据量。
编者注:GreptimeDB 的 PromQL 实现允许通过分析查询计划和执行情况来定位性能问题。详见
TQL ANALYZE文档。
问题的本质是:D6 的数据使用微秒精度的时间索引,而 PromQL 引擎工作在毫秒精度。当查询计划器处理时间过滤条件时,它会先在时间索引上加一层 cast projection 把时间戳转换成毫秒,再把过滤条件放在这个 projection 之上。结果是:时间过滤条件无法下推到存储层的 TableScan,SST 文件的时间范围剪枝失效,原本只需要读一个小时间窗口的查询退化成了全表扫描。
实际生成的计划大致是这样:
Filter: timestamp >= TimestampMillisecond(...) AND timestamp <= TimestampMillisecond(...)
Projection: CAST(metrics.timestamp AS Timestamp(ms)) AS timestamp
TableScan: metrics [timestamp:Timestamp(ns)]过滤条件落在了 Projection 之上,ScanRequest.filters 就拿不到时间范围谓词,存储层只能退回到全范围扫描。
GreptimeDB 团队已经确认这是一个 bug 并正在修复,跟踪 issue 是 #7913。如果你的工作负载涉及非毫秒时间索引,可以订阅这个 issue 跟进进度。
兼容性:最后一公里很关键
从 D6 的角度看,GreptimeDB 在兼容性方面已经做了很大的改进。他们的核心反馈是:继续打磨与 PostgreSQL、MySQL 和 PromQL 生态的兼容性。
"把最后那些细节和边界情况处理好,会让 GreptimeDB 更容易接入现有的工作流和工具链。"
对于一个依赖现成工具和标准客户端的小团队来说,每个兼容性边界问题都意味着额外的 workaround。每修复一个边界情况,就少一个需要维护的补丁。
总结
D6 的案例展示了当工业设备获得和云基础设施同等的可观测性待遇时会发生什么。工厂设备一直在产生信号——电气模式、运行周期、生产数据。差的不是数据本身,而是像监控服务器和容器那样去采集、存储和分析这些数据的工具。
GreptimeDB 让 D6 用一套系统同时满足了实时监控(PromQL)和分析需求(SQL + Flow),不需要搭建复杂的多系统组合。
架构本身是可扩展的。GreptimeDB 的分布式模式随时可以启用,他们构建的数据模型——通过 Flow 将原始传感器信号加工成运营指标——每接入一台新设备都会变得更有价值。
正如 Jacson 所说:"整体来说,做得真的很好。我们很期待继续在这上面构建。"
D6 是一支来自巴西的工业物联网团队,为工厂设备构建可观测性平台。了解更多关于 GreptimeDB 的信息,请访问 greptime.com 或查阅文档。

