本页内容
4 月 25 日,Greptime、AutoMQ、DeepFlow(云杉网络)联合主办的「当可观测性遇上 AI:下一代数据栈的工程实践」Meetup 在上海顺利举办。OceanBase 公有云的工程师也到场,分享了 GreptimeDB 在多云日志存储中的落地经验。
AI Agent 进入生产环境之后,可观测性面对的已经不只是"日志太多"——数据类型在爆炸,行为路径不可预测,传统 APM 的埋点逻辑开始不够用。与此同时,ELK 等上一代技术栈也在撞墙:高基数指标处理吃力,日志和 Metrics、Traces 各存各的,基础设施成本一路涨。问题不在某个环节,从采集、传输到存储,整条管道都得重新想。
这次 Meetup,三个团队分别从 eBPF 零侵扰采集、云原生 Diskless 消息队列、Metrics/Logs/Traces 统一存储三个层面切入,聊各自在工程上的选择和取舍。现场还有一场 15 分钟的 Lightning Talk,把三者串成一条完整管道,跑了一遍基于 LLM 的智能取数和异常检测。

议题回顾
01 谁来监管你的 AI Agent?——从口供、行车记录仪到电子眼
向阳|云杉网络总裁,清华大学博士,曾在 ACM SIGCOMM 发表可观测性方向论文。

AI Agent 能自主决策、调用工具,行为路径带有随机性。向阳用三个比喻切入主题:日志像"口供",靠智能体自己打印;APM 像"行车记录仪",需要提前安装,覆盖面有限;而智能体治理真正需要的是"电子眼"——从操作系统层独立观测,不依赖任何插桩,逻辑上无法被绕过。
企业落地 AI Agent 面临四个挑战:影子智能体不可见、行为不可预测、禁止操作无法查证、责任链难以追溯。向阳认为治理思路应该是"边发展、边审计、边治理"——先用电子眼把行为记录下来,出了问题再追溯并生成规范,而不是一刀切地限制使用。
DeepFlow 用 eBPF 从操作系统内核层采集进程行为:网络通信、文件操作、权限变化、命令执行。一旦发现某个进程是智能体(比如调用了大模型或向量数据库),就自动记录其所有行为,包括子进程和孙进程的完整调用链。DeepFlow 还在智能体流量的源发端给流量"盖戳",让防火墙和服务端都能识别"这是智能体的流量",实现流量层面的差异化治理。

向阳还提到 IETF 正在推进 AI Agent 数字身份管理和企业网络通信方面的标准化草案,行业已经开始为智能体世界的治理搭建基础设施。
Q&A 精选:有观众问 eBPF 采集的局限性。向阳回应说,eBPF 能采集所有经过内核的操作,语言无关且无需插桩;唯一的边界情况是使用 DPDK 等用户态通信的场景,需要通过 uProbe 间接采集。被问到相比插桩式方案有什么劣势,向阳笑着说:"劣势就是难以实现——所以你可以用开源的 DeepFlow。"
02 AutoMQ:基于共享存储架构的新一代 Diskless Kafka
万凯明|AutoMQ 解决方案架构总监

数据采集完了怎么传输?当 Logs、Metrics、Traces 汇聚成统一数据流,Kafka 正在变成基础设施里成本最高、弹性最差的那个瓶颈。凯明从 Kafka 的架构演进讲起,解释了这个"瓶颈"是怎么来的。
传统 Kafka 诞生于 2011 年的物理机房时代,Shared-Nothing 架构,依赖本地磁盘,靠多副本保障持久性。搬到云上之后,架构错配的问题暴露无遗:云盘贵、计算存储耦合导致扩缩容困难、分区数据迁移动辄数小时且影响业务、跨可用区流量费每月轻松过万美元。凯明举了个直观的例子——京东之前用 CubeFS 做对象存储,本身有三副本,Kafka 上面又搞三副本,三乘三等于九副本,大量资源就这么浪费了。
AutoMQ 的做法是从底层重新设计:fork Kafka 代码,将存储层替换为自研的流存储引擎 S3 Stream,100% 兼容 Kafka 协议。所有数据存在对象存储上,Broker 完全无状态。 带来的变化很直接——不需要多副本复制了,跨 AZ 流量费消除了,分区迁移只移动 metadata 而不搬数据,秒级完成。集群内置 controller 实时监控负载,自动做 partition 的流量均衡,运维不用再半夜爬起来手动 rebalance。
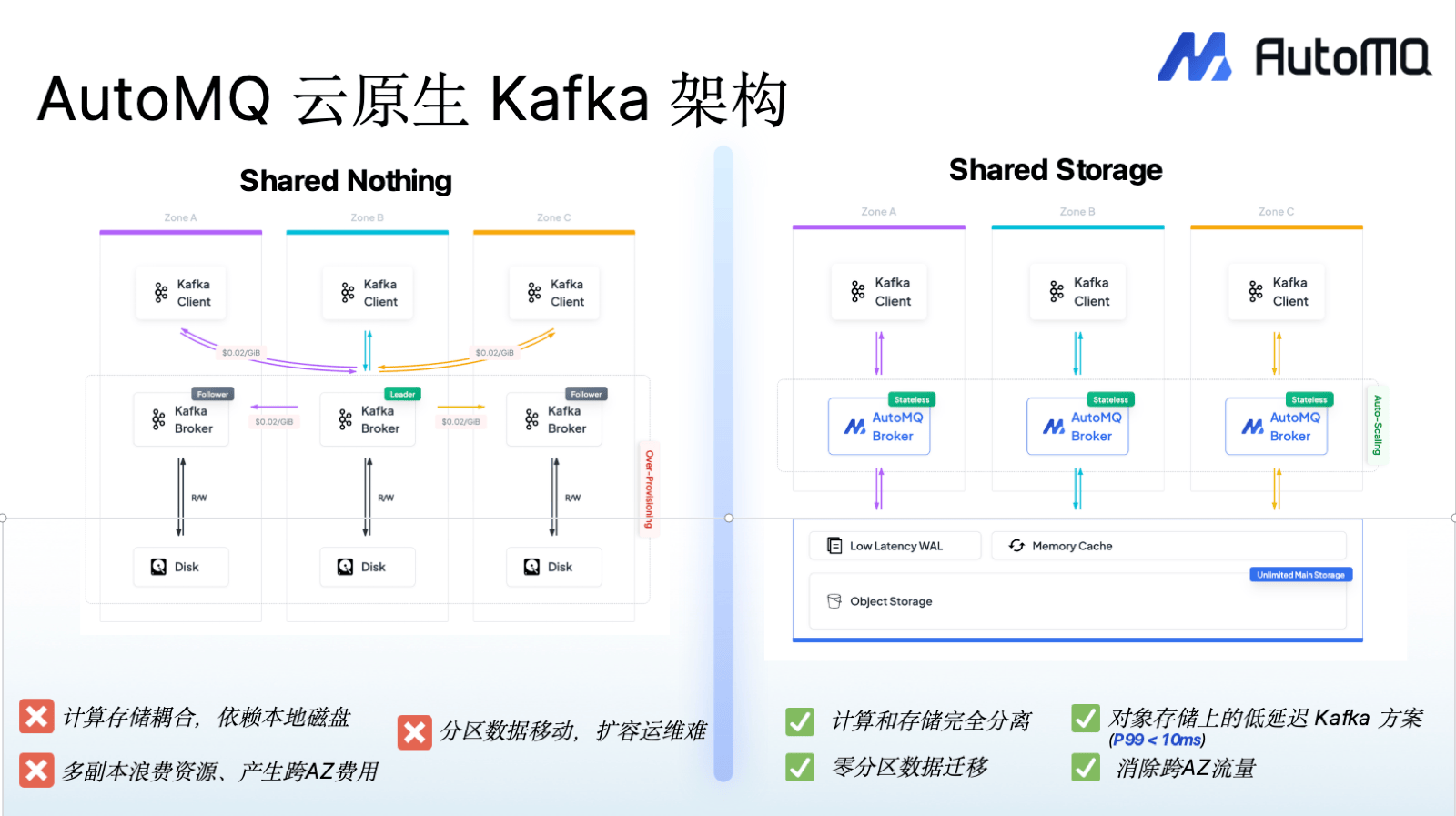
对象存储有个已知的短板:写入延迟高,典型 P99 在百毫秒级。AutoMQ 引入了 WAL Storage 抽象层来解决这个问题——数据先同步写入低延迟的 WAL 存储(EBS、S3 Express 或 NFS 都可以),持久化后返回 ACK,再异步上传到对象存储。整体 P99 延迟控制在 10ms 以内,用户可以在延迟和成本之间自己权衡。
凯明分享了四个落地案例。米哈游:游戏发版带来流量洪峰,原来扩了就回不去,集群长期处于过量预留状态,切到 AutoMQ 后单集群峰值 350K+ QPS,资源利用率提升了一个数量级。爱奇艺:大规模 Kafka 集群弹性升级,弹性效率提升 10 倍,成本降低 70% 以上。吉利汽车:车联网场景,稳定运行近三年,零故障,400+ TB 数据存储不再担心容量上限。得物:可观测性数据管道,多集群合计 40+ GiB/s 峰值吞吐,成本降低 50% 以上。
AutoMQ 还提供了一个零停机迁移工具,支持从 Kafka 到 AutoMQ 的在线迁移——所有数据和 offset byte-to-byte 保留,生产和消费端滚动重启即可,不需要停机,也不需要梳理 topic 和业务关系。
Q&A 精选:有观众追问自平衡的策略细节。凯明介绍说 AutoMQ 提供 QPS 均衡、Traffic 均衡、Partition 均衡等多种策略以及组合策略,controller 实时监控集群水位线,自动移动 partition 达到均衡目标。因为 partition 不含数据,迁移是秒级的。还有观众问冷热数据的读取路径——热数据从内存 Hot Cache 直接读,冷数据从对象存储加载到 Cold Cache,冷热分离,不会污染 Page Cache,也就不会出现传统 Kafka 冷读拖垮集群的问题。
Lightning Talk|从 eBPF 到 LLM:一条 Diskless 可观测性管道的现场演示
庄晓丹|Greptime CEO
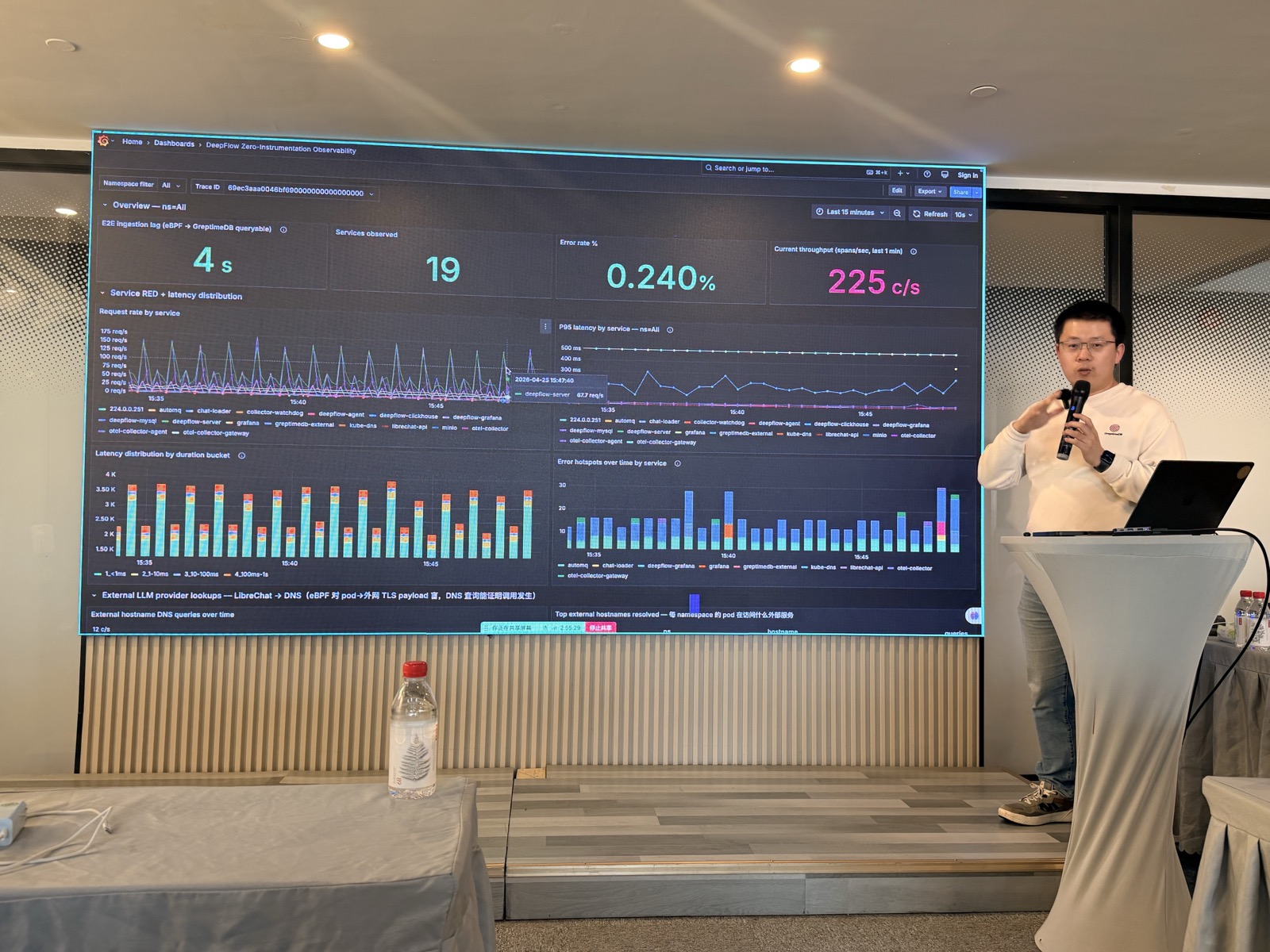
15 分钟,一场端到端的现场 Demo。晓丹把前面两位嘉宾讲的技术串成了一条完整管道:DeepFlow 零侵扰采集 → AutoMQ 传输 → GreptimeDB 统一存储 → MCP + LLM 智能分析。全程 Diskless,所有数据在对象存储上(本地用 MinIO 模拟)。
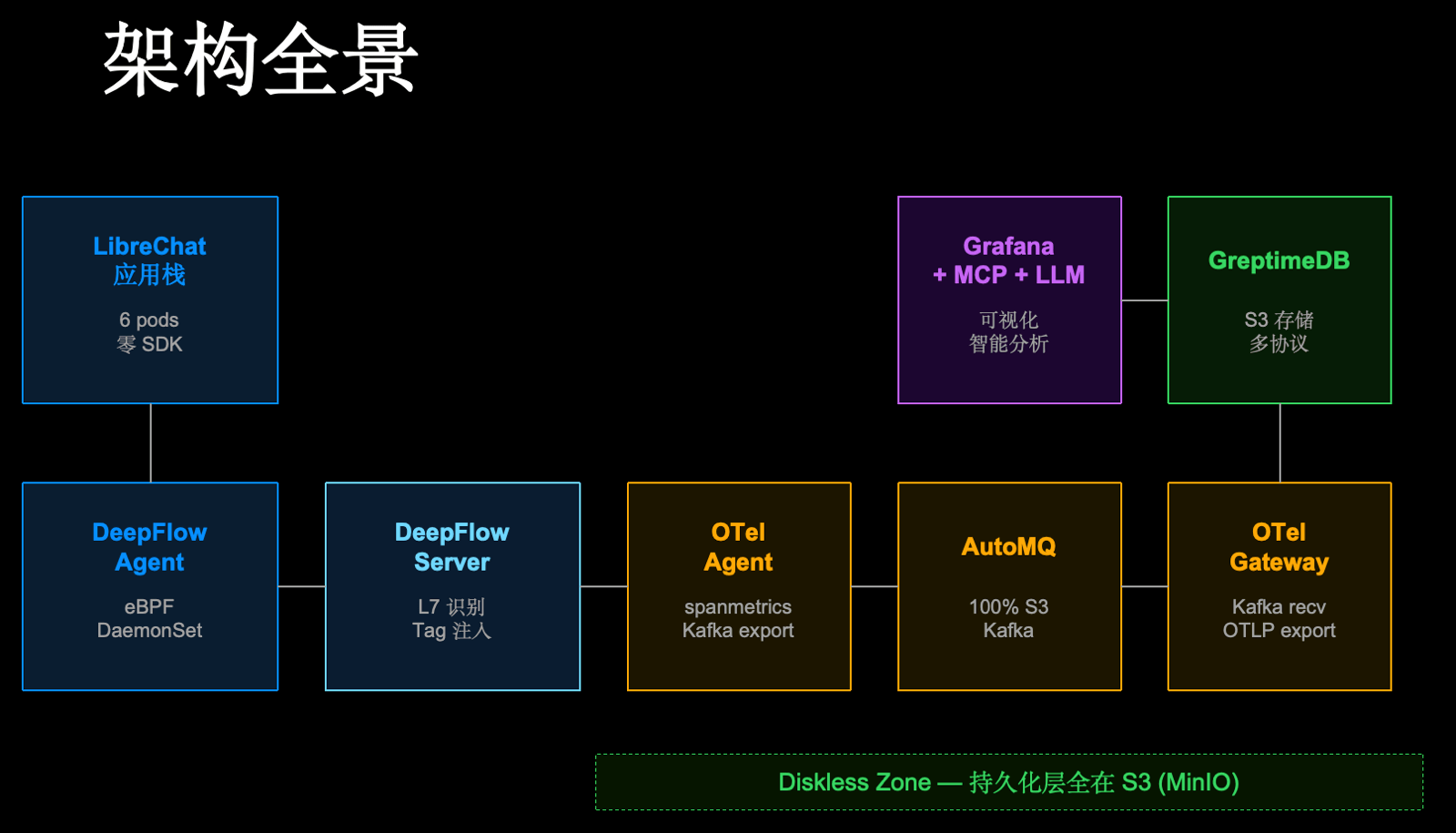
演示跑在本机的一套完整 Kubernetes 集群上,20 个 Pod、5 个 Namespace。DeepFlow 通过 eBPF 抓取所有容器的网络流量,零埋点;数据经 AutoMQ 传输写入 GreptimeDB;Grafana 大盘实时展示。北极星指标:端到端延迟约 5 秒,错误率 0.24%,吞吐 200+ span/秒,累计采集超 140 万条 Span。
最抓眼球的环节是自然语言查询。晓丹通过 GreptimeDB 的 MCP Server 接入大模型,现场用自然语言问:"过去 5 分钟对 GreptimeDB 发起了多少请求?分别用什么协议?延迟多少?"模型自动将问题转化为 SQL,查询 GreptimeDB 里统一存储的 Metrics、Logs、Traces 数据,几秒钟返回结果——和 Grafana 大盘上的数据完全对得上。
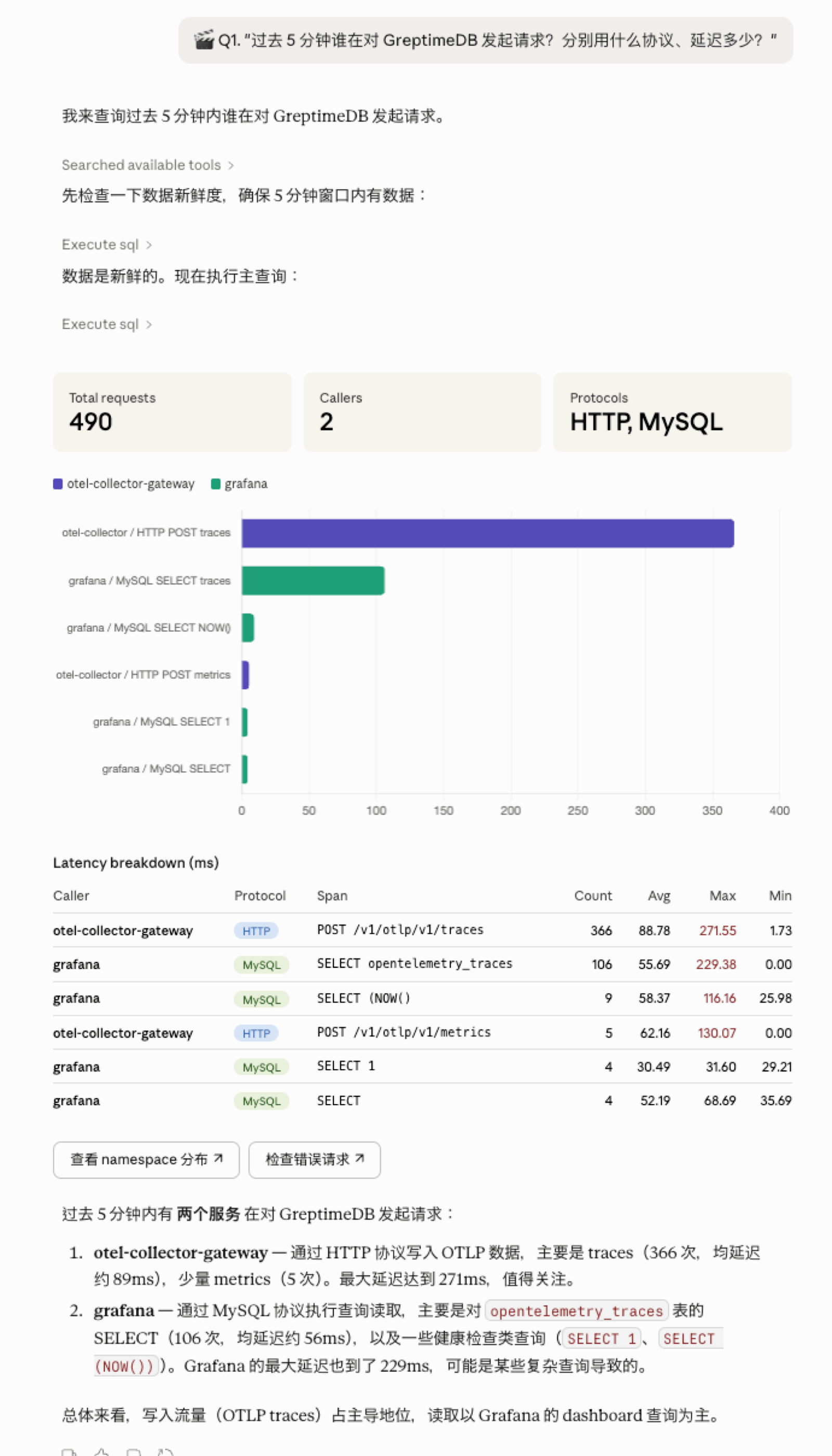
这之所以能行得通,是因为 GreptimeDB 用统一的表模型存储所有可观测性数据。Prometheus Metrics、OpenTelemetry Traces、日志,全部以表的形式存在,通过 SQL 和 PromQL 查询。大模型只要了解表结构和字段含义,就能自己编排查询。这比以前 Metrics 用 Prometheus、Logs 用 Loki、Traces 用 Tempo 三套系统分开查然后人肉关联,体验完全不同。
一个有趣的细节:晓丹用 LibreChat 搭了一个 DeepSeek V4 助手来问问题,DeepFlow 实时抓到了对 api.deepseek.com 的调用链路,包括 HTTP 请求和响应——恰好印证了前面向阳讲的"AI Agent 可观测性"。
晓丹也坦率提到这套架构目前还有改进空间:DeepFlow Agent 目前只吐私有 gRPC 协议,必须经过 DeepFlow Server 才能转成 OTLP,未来如果 Agent 直接支持 OTLP 输出会更简洁;GreptimeDB 的 WAL 目前仍在本地 PVC,虽然可以配置 Kafka 作为 WAL 但会引入额外依赖,理论上未来也可以全部放到 S3 上。但整体方向已经很清晰:零侵扰、Diskless、AI 驱动分析。
03 GreptimeDB 在 OB Cloud 多云的大规模日志存储实践
闫树松|OceanBase 公有云高级研发专家,负责云上 OB 数据库运维管控和多云架构演进。

树松带来了一个真实的生产案例:OceanBase 公有云(OB Cloud)怎么选择并落地 GreptimeDB 作为多云中立的日志存储服务。
先说背景。OB Cloud 覆盖七大主流公有云厂商,是全球唯一做到这个覆盖度的一体化云数据库。做多云扩展时,日志存储遇到了两个核心问题。
第一是开发运维成本。 各云厂商的日志服务查询语法割裂——国内厂商大多用类 Lucene 语法,AWS CloudWatch 和 Azure Logs 各有各的自定义语法,GCP 甚至需要用 BigQuery 查日志。API 抽象难度大,采集标准也不统一,每增加一个云就要重新适配一套日志体系。
第二是成本。 阿里云 SLS 索引流量费用高昂,CloudWatch 按扫描量收费且查询性能到分钟级,Azure 存储费用也不便宜。
OB Cloud 团队先后探索了几个方案:ES 运维复杂且成本甚至比 SLS 还高;ClickHouse 当时还不支持全文索引;Loki 只对标签建索引,写入成本低但查询体验很差——数据量大时查询频繁超时,范围只能缩到数分钟,问题排查效率很低。
了解到 GreptimeDB 后,团队从 0.12 版本开始做 POC,在华为云、腾讯云、AWS 上分别部署验证。效果明显:大数据量查询从 Loki 的频繁超时提升到亚秒到秒级响应;多云部署体验一致;对象存储加高效压缩带来更低的存储成本。Pipeline 功能特别实用——日志采集端 Fluent Bit 不需要做解析处理,原始日志直接写入 Pipeline,在 GreptimeDB 内部完成解析和字段提取。
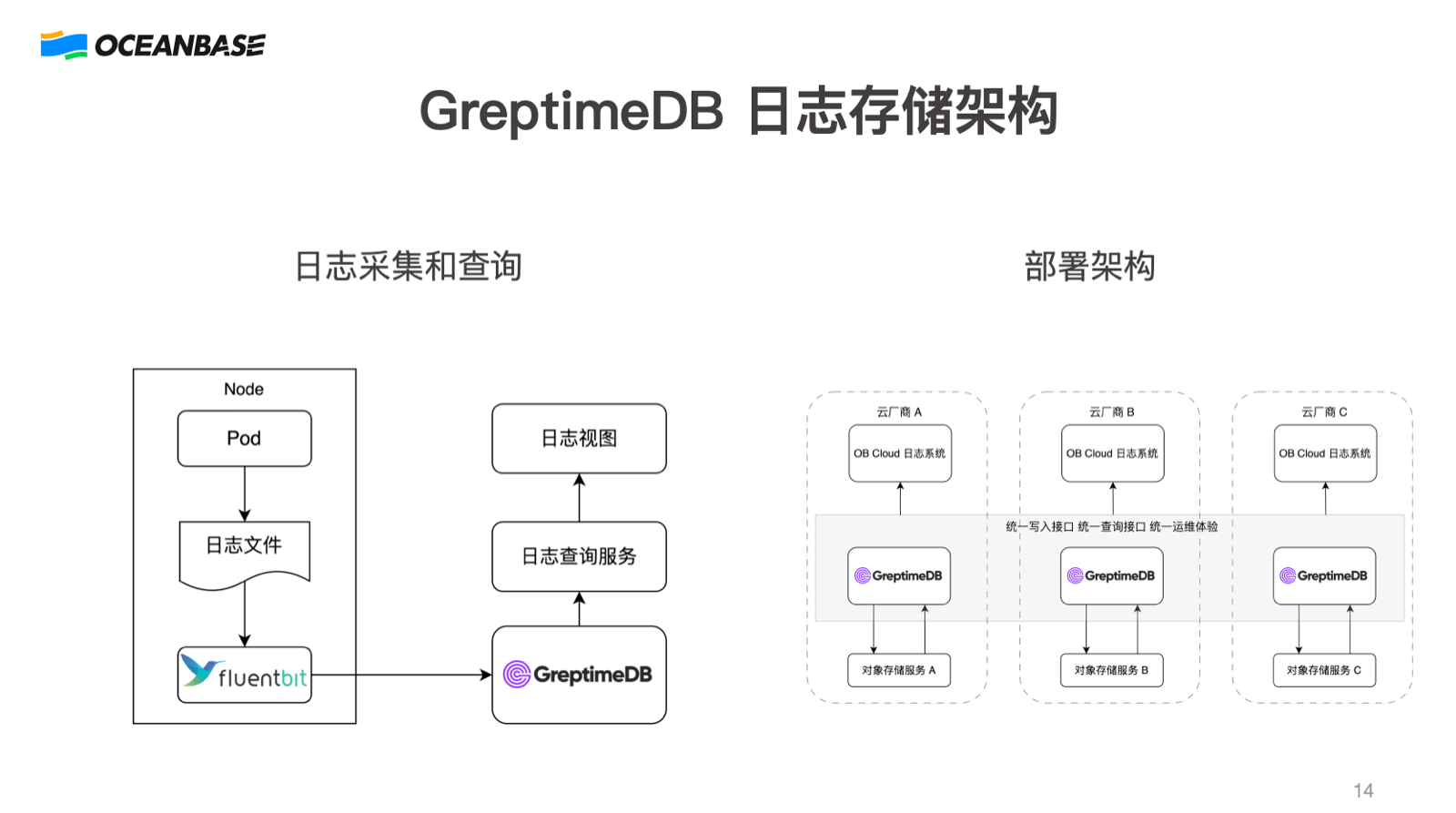
树松也坦诚提到了迭代过程中遇到的问题:早期 Pipeline 不支持条件过滤(比如只想采集 WARN 和 ERROR 级别的日志)、0.12 版本的匹配函数(matches)比较复杂使用不友好、大写入量下 Compaction 导致 OOM 需要人工干预调参。0.13 版本提供了新的全文索引实现和查询语法函数,0.15 版本优化了 Compaction 文件合并策略,降低了峰值内存占用。升级到 0.15 企业版后线上没再出现过 OOM。元数据存储也从 etcd 切换到了 RDS,MetaSrv 全面兼容 RDS 后省去了额外维护 etcd 的成本。
目前 OB Cloud 的日志存储已全部切换到 GreptimeDB 企业版:80+ 套集群,300 TB 数据(7 天保留),最大单集群超 50 TB,平均写入流量超 1 GB/s。日志存储成本降低了 60%,并且同步下调了对客 SQL 审计服务的定价,帮助用户节省 60% 以上的 SQL 审计成本。
树松还介绍了 GreptimeDB 在 OB Cloud 智能诊断 Agent 中的应用。OB Cloud 搭建了一套 Multi-Agent 智能诊断系统,其中可观测 Agent 通过 GreptimeDB 的 MCP Server 查日志和 SQL 审计数据,通过 OB Server MCP Server 查内部表,配合 PromQL 查指标。开发同学甚至在自己的 Code Agent 上配了 MCP Server,AI 直接拉错误日志,结合代码上下文定位 bug——用树松的话说,这也是当初选择 GreptimeDB 之后带来的"技术红利"。
资源获取
添加 Greptime 小助手(微信号:greptime)备注"上海 meetup",可获取本次活动所有讲师 PPT。

本次活动的直播回放已在视频号发布,欢迎未能到场的朋友扫码观看回放。

关于主办方
Greptime 格睿科技 — GreptimeDB 开源时序数据库,Metrics 和 Logs 统一存储引擎。
AutoMQ — 基于共享存储的云原生 Diskless Kafka。
DeepFlow — 基于 eBPF 的零侵扰全栈可观测性平台。

