
本页内容
ORDER BY ... LIMIT 10 看起来只返回几行,但执行起来不一定便宜。表一大、排序键又不是时间索引(Time Index),数据库往往得读完很多行,才能确定该返回哪 10 行。
GreptimeDB v1.0 在这条路径上做了一件事:把 TopK 在执行过程中形成的边界尽早交还给扫描侧。后面的数据如果已经不可能进入结果,就不必再读。在一组真实 traces 数据上,ORDER BY end_time DESC LIMIT 10 因此从将近半分钟降到了亚秒级。
具体实现分两步:GreptimeDB #7545 引入了动态过滤主体——把 DataFusion 上游在 TopK 上做的运行时过滤能力,完整接到 GreptimeDB 自己的 Mito 扫描层;#7912 又把时间索引 TopK 也并入了这条路径。本文详解背后的原理和最终的效果。
慢在哪里
sql
SELECT start_time, end_time, run_type, status
FROM langchain_traces
ORDER BY end_time DESC
LIMIT 10;旧路径下,扫描节点完全看不到 TopK 算子的中间状态。即使最终只返回 10 行,它也得老老实实读到查询结束——等查询跑完才发现,中间扫的那一大堆数据其实根本用不上。
这里还有个背景需要交代:start_time 是这张表的时间索引列,end_time 不是。GreptimeDB 早先针对时间索引的 TopK 有一套叫 windowed sort(内部由 PartSortExec 承担局部排序)的优化,它依赖时间索引的数据分布,逻辑也偏复杂。一旦排序键换成 end_time 这种普通列,过去并没有等价的剪枝手段。PR #7545 补的就是这一块。
PR #7912 又往前推了一步。实测发现:对 TopK 而言,普通 SortExec: TopK + 动态过滤 比 WindowedSortExec + PartSortExec 还要更快。于是 GreptimeDB 干脆在有 LIMIT k 时关掉 windowed sort 重写规则,让时间索引和非时间索引的 TopK 走同一条统一路径。windowed sort 只保留给真正的 full sort(没有 LIMIT)。
让 TopK 把边界告诉扫描
新路径的想法很直接:让 TopK 把当前持有的边界,作为运行时条件回推给扫描节点。
- 查询刚开始时,过滤条件几乎放过所有数据。
- 随着候选行不断进来,当前 K 个里最差的那一行就成了新边界,而且会越收越紧。
- 边界被包成一个
DynamicFilterPhysicalExpr,通过 DataFusion 的 filter pushdown 机制下推给扫描节点。 - 扫描侧拿到这个动态条件后,结合 SST 文件和 row group 的 min/max 统计,把已经不可能命中的数据直接跳过。
对 ORDER BY end_time DESC LIMIT 10 来说,收益主要不是来自结果变小——本来就只要 10 行——而是来自扫描范围被提前收窄。
下面这张图把新旧两条路径放在一起对照:上半是旧路径,扫描层不知道 TopK 阈值,8 个 row group 全得读;下半是新路径,阈值作为动态条件下推到扫描层,扫描器结合 row group 的 max 统计,直接整个跳过那些不可能进入 Top 10 的 row group。
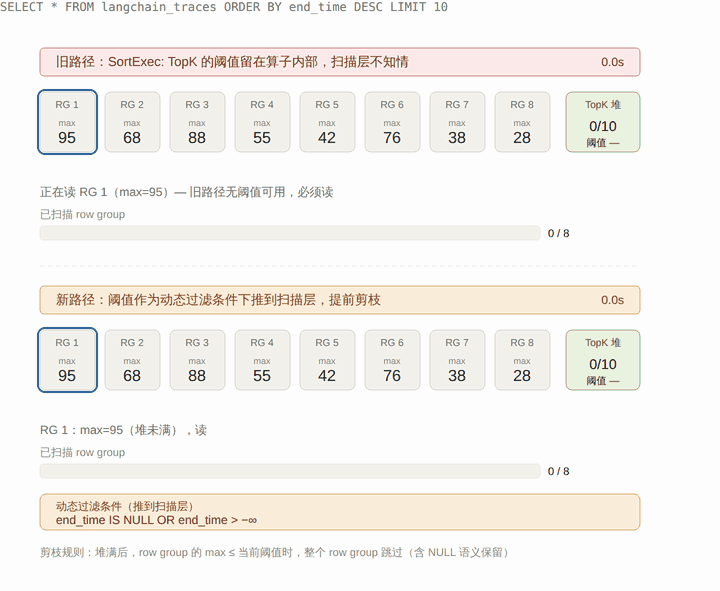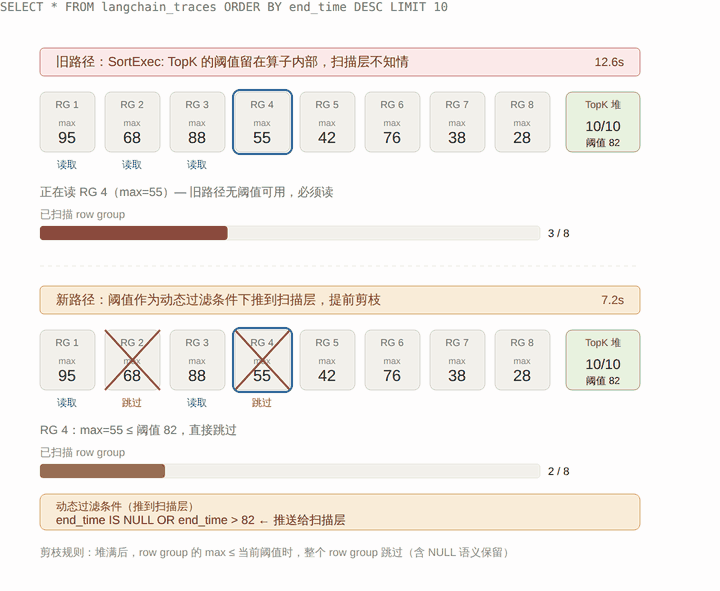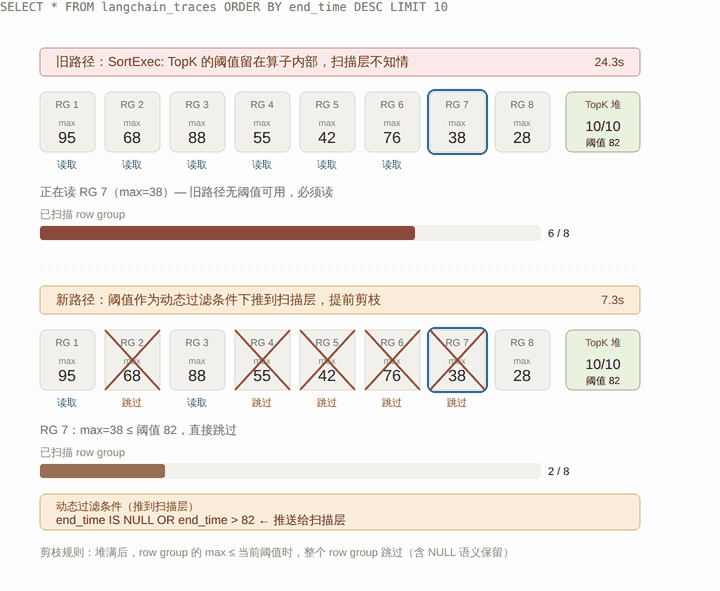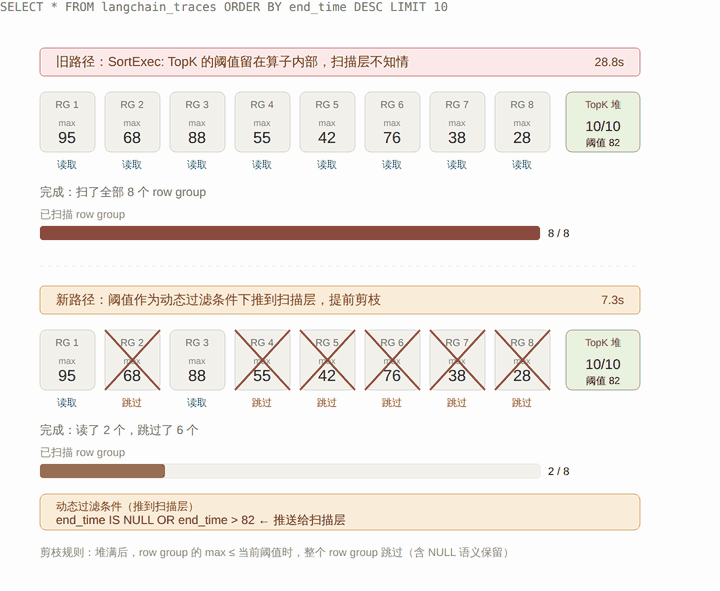
整个机制对应到执行流程上是这样的:
┌────────────────────────────────┐
│ TopK 持续更新当前边界 │
└──────────────┬─────────────────┘
│
▼
┌────────────────────────────────┐
│ 动态过滤条件逐步收紧 │
└──────────────┬─────────────────┘
│
▼
┌────────────────────────────────┐
│ 扫描侧用 row group stats │
│ 重新评估后续文件 / row group │
└──────────────┬─────────────────┘
│
▼
┌────────────────────────────────┐
│ 已经不可能命中的数据被跳过 │
└────────────────────────────────┘边界长什么样
TopK 一旦形成了有意义的边界,GreptimeDB 会把它包成一个保留空值语义的谓词,大致是这样:
text
end_time IS NULL OR end_time > 1753660799999000000带上 IS NULL 是因为在 ORDER BY ... DESC NULLS FIRST 语义下,NULL 排在最前面,不能被剪掉。
扫描侧并不需要把所有行先读出来才能用上这个条件。只要 row group 的统计信息表明它的取值范围不可能满足新条件,GreptimeDB 在真正读取之前就能把整个 row group 跳过。
代码里的几个关键点
这条链路落到代码里,主要涉及下面几处:
RegionScannertrait(src/store-api/src/region_engine.rs)新增了一个方法:rustfn add_dyn_filter_to_predicate( &mut self, filter_exprs: Vec<Arc<dyn PhysicalExpr>>, ) -> Vec<bool>;返回值告诉 DataFusion 哪些 filter 被真正采纳了(用于剪枝 row group),没被采纳的仍由上层评估。
RegionScanExec::handle_child_pushdown_result(src/table/src/table/scan.rs)是 DataFusion 与 GreptimeDB 扫描层的接入点。它把父算子(TopK 或 Hash Join)下推的parent_filters交给 scanner,再把支持情况回传给FilterPushdownPropagation。Predicate(src/table/src/predicate.rs)把动态过滤条件存成一个可热更新的结构:rustdyn_filters: Arc<ArcSwap<Vec<Arc<DynamicFilterPhysicalExpr>>>>,靠
ArcSwap,扫描过程中可以无锁刷新边界。正在进行中的读最多看到一个旧快照,不会阻塞,也不会破坏一致性。Mito 三个扫描路径——
seq_scan.rs、series_scan.rs、unordered_scan.rs——都会把接到的过滤器转发到ScanInput里的PredicateGroup::add_dyn_filters,同时落到predicate_all和predicate_without_region两个 Predicate 上。真正做剪枝的地方在
FileRange::in_dynamic_filter_range(src/mito2/src/sst/parquet/file_range.rs):每个 row group 读取之前,用最新的dyn_filters配合RowGroupPruningStats做一次prune_with_stats,命中就跳过整个 row group。
整条链路的关键在于:每个 row group 都拿当前最新的边界来评估,而不是用查询开始时的快照。
怎么确认它真的生效了
EXPLAIN ANALYZE VERBOSE 可以直接验证。
TopK 节点会显示当前的运行时过滤条件:
text
SortExec: TopK(fetch=10), expr=[end_time@1 DESC], preserve_partitioning=[true],
filter=[end_time@1 IS NULL OR end_time@1 > 1753660799999000000]扫描节点则会显示这个条件已经被传下去了:
text
SeqScan: region=..., {"projection": [...],
"dyn_filters": ["DynamicFilter [ end_time@1 IS NULL OR end_time@1 > 1753660799999000000 ]"],
"files": [...]}两个信号要一起看:SortExec: TopK 里有 filter=[...],说明 TopK 已经形成了运行时阈值;扫描节点里有 dyn_filters,说明扫描侧确实收到了这个阈值并据此剪枝。如果两个都在,动态过滤通常就是走通了。仓库里也有对应的 sqlness 测试,参见 tests/cases/standalone/common/filter/topk_dyn_filter.sql。
实测收益
测试数据是一组 langchain traces。最有代表性的还是开头那个查询:
sql
SELECT *
FROM langchain_traces
ORDER BY end_time DESC
LIMIT 10;端到端耗时
| Query | 旧路径 | dyn filter 路径 | 说明 |
|---|---|---|---|
ORDER BY end_time DESC LIMIT 10 | ~28.9s | ~0.21s | end_time 不是时间索引列,旧路径基本会把表扫完;切到动态过滤后,扫描可以更早被剪掉 |
ORDER BY start_time DESC LIMIT 10 | ~0.33s(windowed sort) | ~0.23–0.24s(dyn filter) | start_time 是时间索引列,原本由 windowed sort 处理。PR #7912 实测发现 windowed sort 反而更慢,TopK 改走统一的 dyn filter 路径 |
分解到算子
| 指标 | main | dyn_filter | 加速 |
|---|---|---|---|
| Total Query Time (User Time) | 28.70 s | 0.20 s | ~143x |
| Scan Node Cost (Total) | 28.81 s | 0.20 s | ~144x |
| Sort Exec Compute Time | 6.55 s | 0.009 s | ~720x |
| Scan Rows before Filter | High (Full Scan) | Near 0 (Pruned) | Significant |
end_time 这条之前慢,本质就是旧路径会扫描全表。换到动态过滤后,TopK 边界可以直接拿来提前剪掉后续扫描——SortExec 自身的耗时从 6.55s 跌到 9ms,也是因为它根本不需要再为大量行做比较了。
start_time 这条则是另一种情况。它原本走的是 windowed sort(WindowedSortExec + 内部 PartSortExec),依靠 partition range + 原生 SST time-range 元数据剪枝。在 PR #7545 阶段,这条路径不接 dyn filter,性能也算可以(~0.33s);PR #7912 再做了一轮对照后,决定让它也切到 dyn filter,p50 进一步压到了 ~0.23s。
需要说清楚的一点:这项优化改变的是扫描量,不是算子复杂度。具体能快多少,仍然取决于数据分布、row group 统计的选择性,以及 LIMIT 的大小。
时间索引 TopK 为什么也改走 dyn filter
PR #7545 最初的取舍是:对时间索引 TopK,刻意不开 dyn filter pushdown。当时实测 PartSortExec + dyn filter 比单独走任一条都慢,所以默认把这条路径让给了 windowed sort。
PR #7912 重新审视了这件事,主要做了两件:
第一,修了 PartSortExec::with_new_children 的一个生命周期 bug。 早先 with_new_children 走的是 try_new,会重建一个全新的 PartSortExec,但这样会丢掉外面已经接好的动态过滤 handle,相当于 dyn filter 永远拿不到 TopK 当前的边界。修完之后,with_new_children 直接 clone 自己、只换 input,保留活的 dyn filter 引用:
rust
// before: 用 try_new 重建,dyn filter 是新的,没人 update 它
// after: 保留 self 的 dyn filter,只更新 input
let mut new_exec = self.as_ref().clone();
new_exec.input = new_input.clone();
new_exec.properties = new_input.properties().clone();第二,修完之后重新跑了一轮 benchmark。 让 PartSortExec + dyn filter 真正生效后,对 ORDER BY start_time DESC LIMIT k:
| LIMIT | p50 |
|---|---|
| 5 | 0.586s |
| 10 | 0.587s |
| 100 | 0.569s |
| 1000 | 0.584s |
而完全跳过 windowed sort、回退到普通 SortExec: TopK + dyn filter 的版本是 0.23–0.24s 区间。也就是说:哪怕把 PartSortExec 的 dyn filter 接通,也还是比普通 TopK + dyn filter 慢一倍以上。
最终代码改动只有一行(外加注释):
rust
// src/query/src/optimizer/windowed_sort.rs
if /* ... matches the windowed-sort pattern ... */
&& sort_exec.fetch().is_none()
// skip if there is a limit, as dyn filter alone is good enough in this case
{
// do the rewrite
} else {
return Ok(Transformed::no(plan));
}行为变成:
SortExec没有fetch(也就是 full sort、没有LIMIT)——继续走 windowed sort 重写,partition range 剪枝照常使用;SortExec有fetch(也就是 TopK)——保留SortExec: TopK原状,让 dyn filter pushdown 接管。时间索引和非时间索引共用同一条路径。
至此,#7545 阶段为兼容 PartSortExec 而保留的开关也成了历史:今天的执行计划里,TopK 不会再出现 PartSortExec。
什么样的查询收益最大
收益最明显的场景,通常下面这些条件同时成立:
k比较小,边界能很快变紧;- row group 的 min/max 有足够的选择性;
- 数据分布使 TopK 边界能比较早变得有意义。
排序键是不是时间索引列,如今已经不再是分水岭——TopK 都走同一条 dyn filter 路径。区别只是:时间索引列天然有序,边界收敛得更快一些。
反过来,这些情况下收益就有限:
- 查询本来就高效,比如时间索引 + 小窗口;
- 过滤条件在执行的大部分时间里都接近
true; - row group 的 min/max 太宽,剪不掉多少;
LIMIT太大,边界收得太慢。
简单来说,只要查询本身受扫描成本主导,数据形态也合适,这条路径就有机会显著改变查询的代价。
现状与下一步
PR #7545 加上 #7912 落地的动态过滤,目前覆盖:
- 本地 TopK(
SortExec: TopK)的运行时过滤下推——已生效,且不再区分时间索引和非时间索引; - 本地 Hash Join(同一 datanode 内的
HashJoin)的 dyn filter——已通过hash_join_dyn_filter/hash_join_topk_dyn_filter等 sqlness 用例覆盖; - 跨节点 Hash Join(frontend 上的 join 把 dyn filter 推到 datanode 上的扫描节点)——尚未支持。
跨节点的版本需要一种 "remote dyn filter" 机制,把上游算子在执行中产生的运行时条件通过 RPC 推回到数据节点的 scan operator。相关 RFC 见 #7931,基础设施见 #7979,目前仍在演进中。
排查清单
如果你手头有 ORDER BY ... LIMIT k 的查询仍然偏慢,可以按下面这条顺序看:
- 执行计划里 TopK 节点带
filter=[...]了吗?- 没有:查询可能根本不是 TopK 形态(被规划成 full sort,或者被分拆到聚合之后再 limit);也可能 GreptimeDB 版本早于 #7912,时间索引列还在被规划成
WindowedSortExec。
- 没有:查询可能根本不是 TopK 形态(被规划成 full sort,或者被分拆到聚合之后再 limit);也可能 GreptimeDB 版本早于 #7912,时间索引列还在被规划成
- 扫描节点里带
dyn_filters: [...]了吗?- 没有:dyn filter 没传下来。检查排序列、投影,以及中间是否有阻断算子(复杂表达式、UNION 等)。
- row group stats 的选择性够吗?
- 边界传下来了但还是扫了不少,通常是 row group min/max 太宽,或者写入时没有按相关列做聚簇。
- 执行计划里出现
WindowedSortExec/PartSortExec了吗?- 出现了:如果是 full sort(没有
LIMIT),按设计就该走 windowed sort,不接 dyn filter;如果明明是 TopK 却仍然出现,说明sort_exec.fetch().is_none()这个分支被误判了,需要排查规则。
- 出现了:如果是 full sort(没有
对这类 TopK 查询而言,真正关键的不是结果只返回几行,而是后面的扫描能不能更早停下来。

