
本页内容
GreptimeDB v1.0 为 Prometheus Remote Write[1] 路径引入了 Pending Rows Batcher。在 16 Region 的物理表上,同样的写入负载下,吞吐从 120 万点/秒提升到 217 万点/秒,Datanode 的 CPU 反而下降约 20%。
代价是 Frontend 的 CPU 占用上升约一倍。我们把原本压在 Datanode 关键路径上的计算开销挪到了 Frontend,让批量数据以列式格式直通到存储层。本文介绍这条新写入路径的设计和它解决的问题。
Prometheus 写入对时序数据库为什么不友好
可观测性场景下,Prometheus 通过 Remote Write 协议把时序数据推送到远端存储。一次写入请求通常只携带几十到几百个数据点,但请求频率极高。数据库需要持续处理大量碎片化的小写入。
原有的逐行写入路径上,每个请求都会独立触发一组固定动作:
- 表结构解析
- Schema 对齐(缺列时需要 ALTER TABLE,缺表时需要 CREATE TABLE)
- 行格式编码、gRPC 传输
- Datanode 侧逐行解码、主键编码、写入 Memtable、WAL
这些动作中很多是重复的固定开销。同一张表的连续写入会反复触发同样的 Schema 检查和格式转换。当 TPS 升高,这些重复开销会主导整体吞吐。
真正的瓶颈:Region Worker 的 Critical Section
固定开销只是问题的一面,更深一层的瓶颈在 Datanode 内部。
GreptimeDB 中,每个 Region 的写入由一个专属的 Region Worker 串行处理。为了保证数据的定序一致性,Worker 在处理一次写入时需要持有 Region 的 &mut 引用,这构成一个 Critical Section。临界区内,Region 不能被其他任务并发访问。
逐行写入路径下,Critical Section 内需要完成的工作包括:
- 行数据的解码和校验
- 主键编码和排序
- Schema 对齐和列转换
- 写入 Memtable
- WAL 写入
其中编码和排序是计算密集型的,会显著拉长持锁时间。高 TPS 下,Region Worker 成为瓶颈,后续请求必须排队等待前一个请求完成整个 Critical Section。
降低固定开销、缩短 Critical Section,这是 Pending Rows Batcher 要解决的问题。
解决方案:三步流水线
Pending Rows Batcher 在 Frontend 侧将多个请求的行数据攒在一起,统一完成 Schema 对齐和行转列,再通过 BulkInsert RPC 把列式批次直接写入 Datanode。整条路径由三部分组成:

- Frontend 侧的 Batcher 负责攒批和行转列
- BulkInsert 写入路径负责传输列式批次
- Datanode 侧的 BulkMemtable[2] 负责以列式结构承接这些数据
三个阶段依次是:在入口处完成提交与 Schema 对齐,按物理表维度累积批次,最后通过列式批量写入送入 Datanode。

整体思路是把原本压在 Datanode Critical Section 内的重计算(解码、编码、排序、Schema 对齐)前移到 Frontend,让 Region Worker 只负责消费已经编码好的 RecordBatch。
写入路径的几个关键点
提交与 Schema 对齐
Prometheus Remote Write 请求到达后,Batcher 首先把它转换为 Arrow RecordBatch[3],同时完成 Schema 对齐:
- 对已有的逻辑表,自动识别并补齐缺失的 Tag 列(批量 ALTER TABLE)
- 对新发现的指标表,自动批量创建(批量 CREATE TABLE)
- 所有 DDL 操作按物理表分组批量执行,避免逐条请求触发 DDL 的开销
这样一来,Schema 变更的开销被分摊到了整个批次上,不再是每个请求都承担一次。
逻辑表与物理表的映射
这里需要先解释 Metric Engine 的一层抽象。
Prometheus 写入场景下,每个 metric 通常以一张逻辑表(Logical Table)的形式暴露给用户,不同的指标名对应不同的逻辑表。但在底层存储中,多个逻辑表可以映射到同一张物理表(Physical Table),由这张物理表统一承接实际的数据写入、分区和 Region 管理。

因此 Batcher 不是简单地按"每个 metric 一批"来攒批。它先根据逻辑表完成 Schema 对齐,再按所属的物理表归并。落到同一张物理表的多个指标可以共享同一个 Worker 和刷新节奏,最终合并成更大的列式批次写入 Datanode。
这也是后文反复出现"按物理表分片"的原因:逻辑表决定用户看到的指标表和 Schema,物理表决定底层批量写入时如何组织和调度数据。
Worker 攒批的双触发条件
每个物理表都有一个专属的后台 Worker 任务。提交后的 RecordBatch 被发送到对应 Worker 进行累积,由两个条件触发刷新:累积行数达到 max_batch_rows(默认 10 万行)时立即刷新,或者距离上次刷新超过 pending_rows_flush_interval 时定时刷新。此外,Worker 空闲超过 3 倍 flush_interval 时会自动关闭以释放资源。
定时刷新兜住延迟下限,满批刷新最大化批次大小,两者结合在低延迟和大批次之间做了平衡。
列式批量写入
刷新时,Batcher 把同一批次内所有逻辑表的 RecordBatch 合并并编码为 Arrow IPC 格式,通过 BulkInsert RPC 一次性写入目标 Region。相比原有的逐行 Insert,这种方式减少了网络往返次数,Datanode 侧可以直接处理列式数据,省去了行转列的开销;同时支持按分区规则自动拆分,各 Region 的写入可以并发执行。
Critical Section 是怎么被缩短的
对照前面 Critical Section 瓶颈的分析,整条路径的分工是这样的:
- Frontend 侧(Critical Section 外):行转列、Schema 自动对齐、主键编码、按分区规则拆分。这些计算密集型操作在 Batcher 中异步完成,不占用 Datanode 的 Region Worker。
- Datanode 侧(Critical Section 内):Region Worker 收到 BulkInsert 请求后,只需将已经编码好的 Arrow IPC RecordBatch 直接 push 到 Region 中。没有解码、没有排序、没有逐行处理。
Critical Section 内的工作量从「解码 + 主键编码 + 排序 + 写入 Memtable + WAL」缩减为「导入一个已经编码好的 RecordBatch」。持锁时间大幅缩短,Region Worker 的吞吐能力也随之提升。
全程列式:BulkMemtable 的角色
Frontend 把数据从行格式转成 Arrow RecordBatch 后,下一个问题是这些列式数据到了 Datanode 之后会发生什么。
如果 Datanode 仍然使用原有的行式 Memtable(TimeSeriesMemtable),列式批次会被拆解成逐行的 Mutation,再逐行编码主键、逐行插入。Batcher 攒批的收益等于被抹掉了,批量化只换来了网络层面的节省,存储层面又退回到逐行处理。

GreptimeDB v1.0 中引入的 BulkMemtable 解决了这个问题。它专为列式批量写入设计,只接受 RecordBatch 输入,内部以列式结构存储,扫描时也直接输出 RecordBatch 迭代器。
结合 BulkMemtable,整条写入路径变成:
Prometheus Remote Write → Batcher(行转列 + 攒批)→ BulkInsert RPC(Arrow IPC)→ BulkMemtable(列式存储)→ 刷盘(列式 Parquet)→ 查询(列式扫描)
数据在 Batcher 中完成一次"行 → 列"转换后,就再也不会回到行格式。这带来三个层面的收益:
- 零格式转换开销:BulkMemtable 直接接收 RecordBatch,无需拆回逐行结构
- 零拷贝刷盘:内存中已经按 Parquet 格式编码的数据可以直接写入 SST 文件
- 向量化查询:扫描输出的 RecordBatch 可以直接被 DataFusion 消费
BulkMemtable 的内部设计(Part 分层、合并策略、内存 Parquet 编码)相对独立,我们在另一篇博客《高基数场景下的时序数据库优化:GreptimeDB Flat 格式设计》中做了详细介绍。本文只需要记住一点:Pending Rows Batcher 和 BulkMemtable 配合,构成了一条从入口到存储的全链路列式流水线。
性能表现
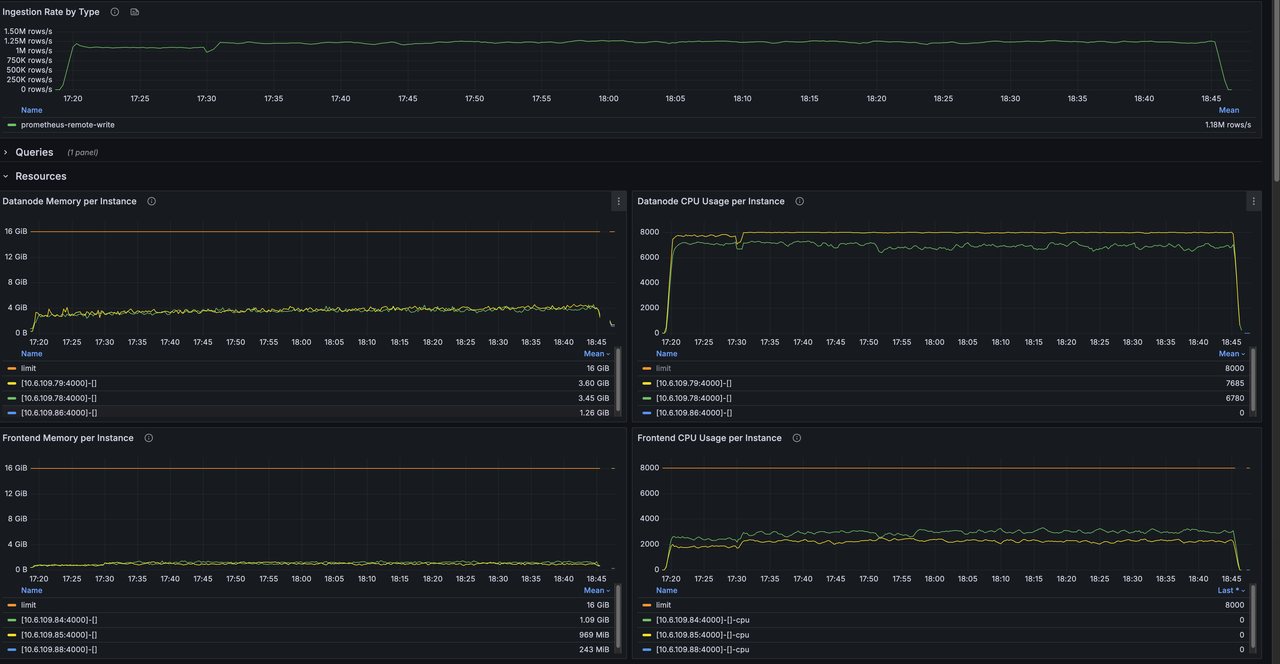
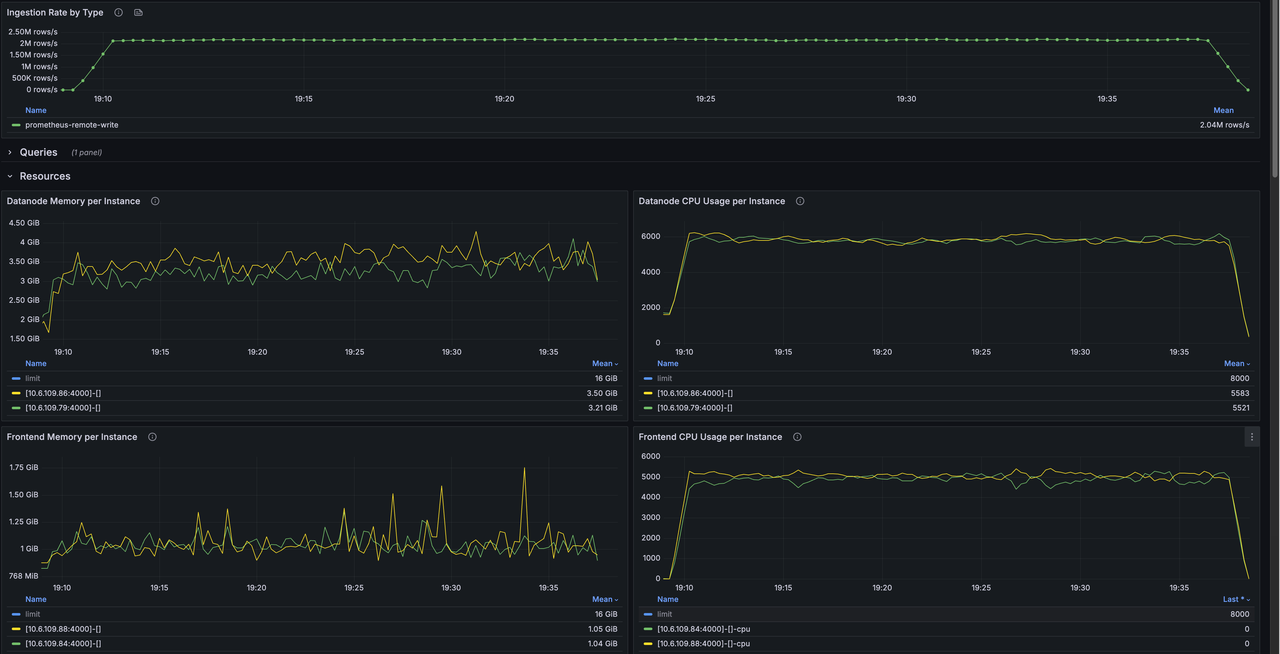
测试基于 16 个 Region 的物理表,在相同的 Prometheus Remote Write 负载下,分别测量默认模式和 Pending Rows Batcher 模式的写入吞吐与资源消耗。
写入吞吐

启用 Pending Rows Batcher 后,写入吞吐从 120 万点/秒提升到 217 万点/秒,提升约 81%。
资源占用对比
| 指标 | 默认模式 | Batcher 模式 | 变化 |
|---|---|---|---|
| 写入吞吐 | 120 万点/秒 | 217 万点/秒 | +81% |
| Datanode CPU | 14.9 核 | 11.95 核 | -20% |
| Datanode 内存 | 7.14 GB | 6.36 GB | -11% |
| Frontend CPU | 5.2 核 | 10.15 核 | +95% |
| Frontend 内存 | 2.09 GB | 2.04 GB | 持平 |
Frontend CPU 上升是预期内的,因为 Schema 对齐、行转列、主键编码这些计算被前移到了 Frontend。整体看,这是用 Frontend 的计算资源换取了更高的写入吞吐和更低的 Datanode 负载。在大多数部署中 Datanode 是更稀缺的资源,它直接关联存储、刷盘和查询性能;Frontend 是无状态的,水平扩展更容易。这个取舍在生产环境中是划算的。
原始监控数据
下面两张是测试期间 Grafana 监控面板的截图,可以作为上述数据的原始参考。
如何启用
批量写入模式需要配置在 Frontend 侧。如果写入负载以高 TPS、小批量的 Prometheus Remote Write 请求为主,可以在 Frontend 配置文件中启用 Metric Engine 并设置 Pending Rows Batcher 参数:
toml
[prom_store]
enable = true
with_metric_engine = true
pending_rows_flush_interval = "5s"
max_batch_rows = 20000
max_concurrent_flushes = 256
worker_channel_capacity = 65526
max_inflight_requests = 3000关键参数说明:
enable:启用 Prometheus Remote Write 存储入口。with_metric_engine:使用 Metric Engine 存储 Prometheus 指标数据,这是启用逻辑表/物理表映射和批量写入路径的前提。pending_rows_flush_interval:攒批时间窗口。设为 0 则禁用 Batcher;示例中配置为 5 秒。max_batch_rows:单批次最大行数,达到后立即刷新。示例中配置为 20,000 行。max_concurrent_flushes:最大并发刷新数,用于限制同时执行的 flush 任务数量。worker_channel_capacity:每个 Worker 接收待写入批次的通道容量,用于缓冲提交到该物理表 Worker 的请求。max_inflight_requests:最大在途请求数,用于反压控制,避免 Frontend 侧堆积过多未完成写入。
总结
Pending Rows Batcher 通过"Schema 自动对齐 → 攒批 → 列式批量写入"的三段式流水线,把 Prometheus Remote Write 的写入吞吐提升了 80% 以上,同时降低了 Datanode 的资源消耗。
它做的事情可以归结为重新划分 Frontend 和 Datanode 之间的计算分工:让 Frontend 承担更多的预处理(攒批、Schema 对齐、行转列、主键编码),让 Datanode 的 Region Worker 只做最关键的临界区操作。配合 BulkMemtable 的列式直通,整条写入路径不再有行列格式之间的反复转换。
高基数、高 TPS 的可观测性场景下,只要 Frontend 改几行配置就能拿到这条新路径。

