
本页内容
本文由理想汽车车辆数据团队和格睿科技联合写作。
车辆故障发生时,我们能看到的只是前后几十秒的数据片段。如果问题早在几天前就已埋下,怎么办?
在理想汽车,软件研发里"可观测"的理念被搬到了车上——在研发和售后阶段,通过采集车辆数据来预警风险、分析故障,甚至洞察整车真实的运行状态。这对迭代飞快的智能电动车来说,尤其关键。
如今,数据从车端采集、压缩上传,再到云端清洗入库,整套流程并不陌生。但在实际运维里,这条链路往往采样有限、精度不足,真出了问题,还是容易"看不清、摸不透"。
于是我们开始思考:能不能拿到车辆各系统的原始数据,并且高效地用起来?
为什么需要原始数据?
原始数据能最大程度还原现场。就像在软件开发里,我们用日志和 Trace 追踪每个请求的来龙去脉;在车上,毫秒甚至微秒级的细节,往往就藏在那些被常规采样"平滑"掉的波动里。
最早,行业普遍采用**"车端黑匣子"**的思路:持续监听车内信号,一旦触发预设规则(比如某个故障码),就把事发前后的数据打包保存,找机会上传。这个做法很务实:
- 只在事件发生时存数据,减少了存储压力,也保护了车载闪存寿命;
- 只传片段数据,流量和云端处理成本都比较低;
- 车端只负责录制,对系统性能影响小。
但为了极致控制成本和性能,可观测能力其实做了很大妥协:
- 数据只在故障前后捕获,无法反映车辆日常状态;
- 规则驱动,意味着我们只能看到已知问题,难以发现"未知的未知";
- 本质上,它还只是一种事后诊断工具,更像"监控",而非真正的"可观测"。
要实现可观测,就意味着我们需要常态化、低成本地采集原始数据。随之而来的,是一系列新挑战:
- 采原始报文还是解析后的信号?
- 数据怎么存——结构化还是非结构化?
- 上传链路怎么设计?云端又该如何管理使用?
这背后,其实是数据价值、采集性能与成本之间的持续博弈。尤其在原始数据场景下,压力来自各个环节:车端采集解析的资源消耗、云端处理的算力成本、查询延迟,还有谁都绕不开的流量费用。
理想的选择:把时序数据库"搬上车"
综合考虑后,我们决定将采集程序、解码器和时序数据库整体部署到车端。核心思路很明确:
- 减少车云传输的数据量,降低流量成本;
- 合理利用车端算力,把部分处理工作前置,减轻云端负担。
具体来说,我们在采集程序里直接对原始报文进行解码,把传统上在云端完成的 ETL 流程提前到车端。这样一来,后续环节处理的直接就是结构化的、有业务意义的数据。
结构化之后,数据压缩效率大幅提升。通过 Delta 编码、游程编码等列式存储专用方法,再配合通用压缩算法,最终文件体积可以比"原始报文 + 通用压缩"再小 30% 以上。
也因为数据变成了按块组织的文件,再加上数据量远大于传统降采样模式,我们不再适合用传统的 TCP/MQTT 流式上传——那样容易阻塞链路,影响车辆与控制中心的实时通信。最终,我们改用 HTTP 协议直连 OSS 对象存储,以文件为单位上传。
车端时序数据库:性能与成本的平衡术
方案定了,接下来就是找一个能跑在高通平台 Android 系统上的时序数据库。它需要胜任几件事:
- 高性能写入和高压缩率;
- 生成的文件能在云端低成本导入;
- 未来甚至能把查询和计算能力进一步下放到车端。
经过多轮对比,GreptimeDB 在几个关键维度上胜出:
| 能力项 | 为什么重要 | GreptimeDB | 竞品 A | 竞品 B |
|---|---|---|---|---|
| 时序数据模型 | 车辆信号天然是时序数据,专用模型才能高效存储和查询 | ✅ | ✅ | ✅ |
| 运行在 ARM / Android 平台 | 车机芯片均为 ARM 架构,跑不起来等于零 | ✅ | ❌ | ✅ |
| 单进程、低资源消耗 | 车机资源有限,数据库不能抢占导航、座舱等核心功能的算力 | ✅ | ❌ | ❌ |
| 列式数据组织 | 传感器信号重复性高,列式存储可大幅提升压缩率,直接降低流量成本 | ✅ | ❌ | ❌ |
| 闪存读写友好 | 车载存储介质为闪存,频繁小写会加速磨损,影响硬件寿命 | ✅ | ❌ | ❌ |
| 车云同构 | 车端文件可直接加载到云端,省去 ETL 转换,节省大量云端算力 | ✅ | ❌ | ❌ |
选型只是第一步,真正考验的是实车适配。在理想的车机环境里,CPU 占用是条硬红线,数据服务必须足够轻量,不能影响车上其他功能。
我们做了大量针对性优化。例如在写入接口上,为了减少跨进程通信(IPC)的开销,我们没有直接用现成的 gRPC 接口,而是为车机专门设计了一套基于 RingBuffer 和 Arrow IPC 的机制。通过共享内存和高效的序列化协议,显著降低了 CPU 占用。
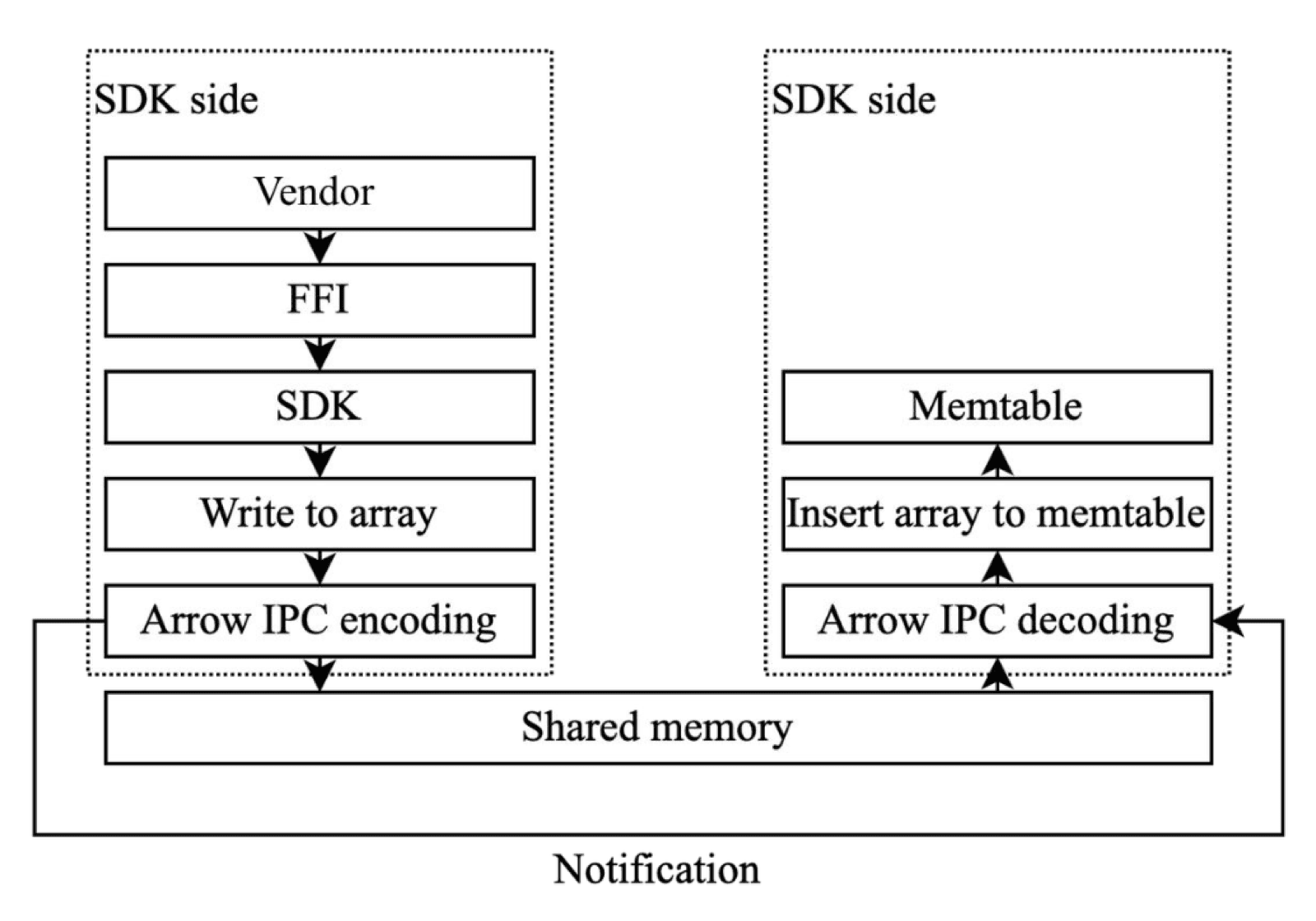
基于共享内存的 RingBuffer 高效写入实现
数据落盘也要"精打细算"。如果来一条就写一条,不仅压缩率低,还会产生大量小文件,加剧闪存磨损。因此,我们在 I/O 路径上做了深度优化:
- 针对车载传感器数据特征,优化列式存储编码,显著减少原始数据量;
- 在此基础上叠加 zstd 压缩,并创新性地引入预训练字典——字典基于历史数据离线生成,部署后无需实时计算,就能提升小批量数据的压缩率;
- 为了解决小文件写放大问题,我们在存储引擎层实现了单文件顺序追加写入,将数据批量写入统一文件,减轻对闪存的压力。
这一系列优化,在保证低 CPU 开销的同时,大幅降低了闪存写入量和写放大效应。
内存占用也被严格管控。我们为批量写入设计了紧凑的内存缓冲区结构,基于 Arrow IPC 的列式布局,比传统的 BTree 或 SkipList 实现更省内存。实测中,内存占用从 1.4GB 降至 300MB 左右。
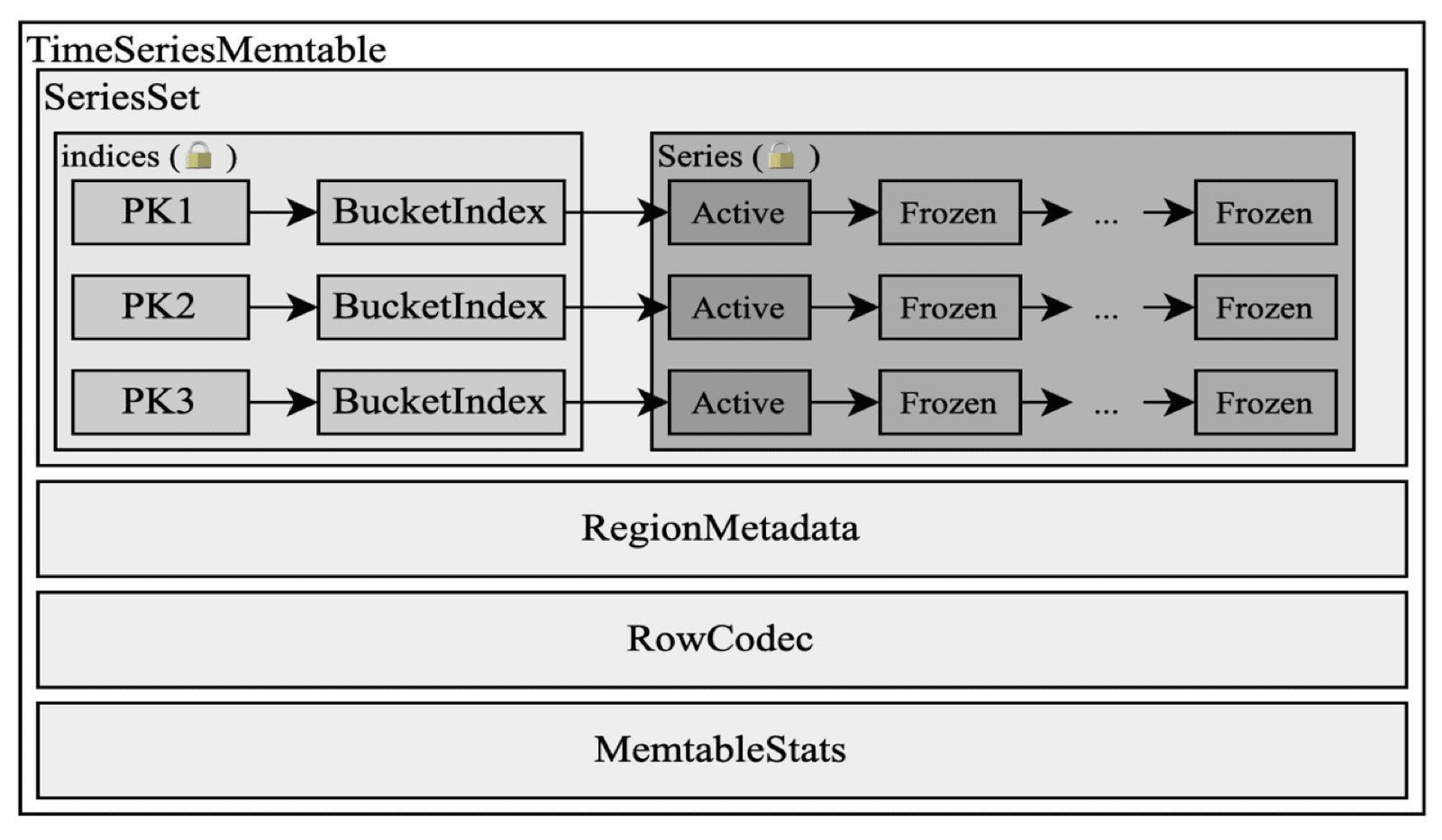
紧凑的内存结构降低内存占用
车云一体:数据流动的自然延伸
因为车端和云端用了同一套数据架构(车云同构),车端生成的数据文件上传后,无需转换或重新处理,可以直接加载到云端数据库。随着理想车辆保有量增长,这种模式节省的云端算力是非常可观的。
数据量暴涨也对存储提出了挑战。得益于存算分离架构,我们可以将海量数据放在成本更低的对象存储中,成本比传统数仓的本地盘方案降低了一个数量级。存储和计算资源都可以按需弹性伸缩,真正做到用多少付多少。
从宏观视角看,所有车端数据库与云端数据库共同构成了一个逻辑上的统一集群。车端负责写入分片数据,通过车云链路同步到云端,云端则承担复杂的分析查询任务。
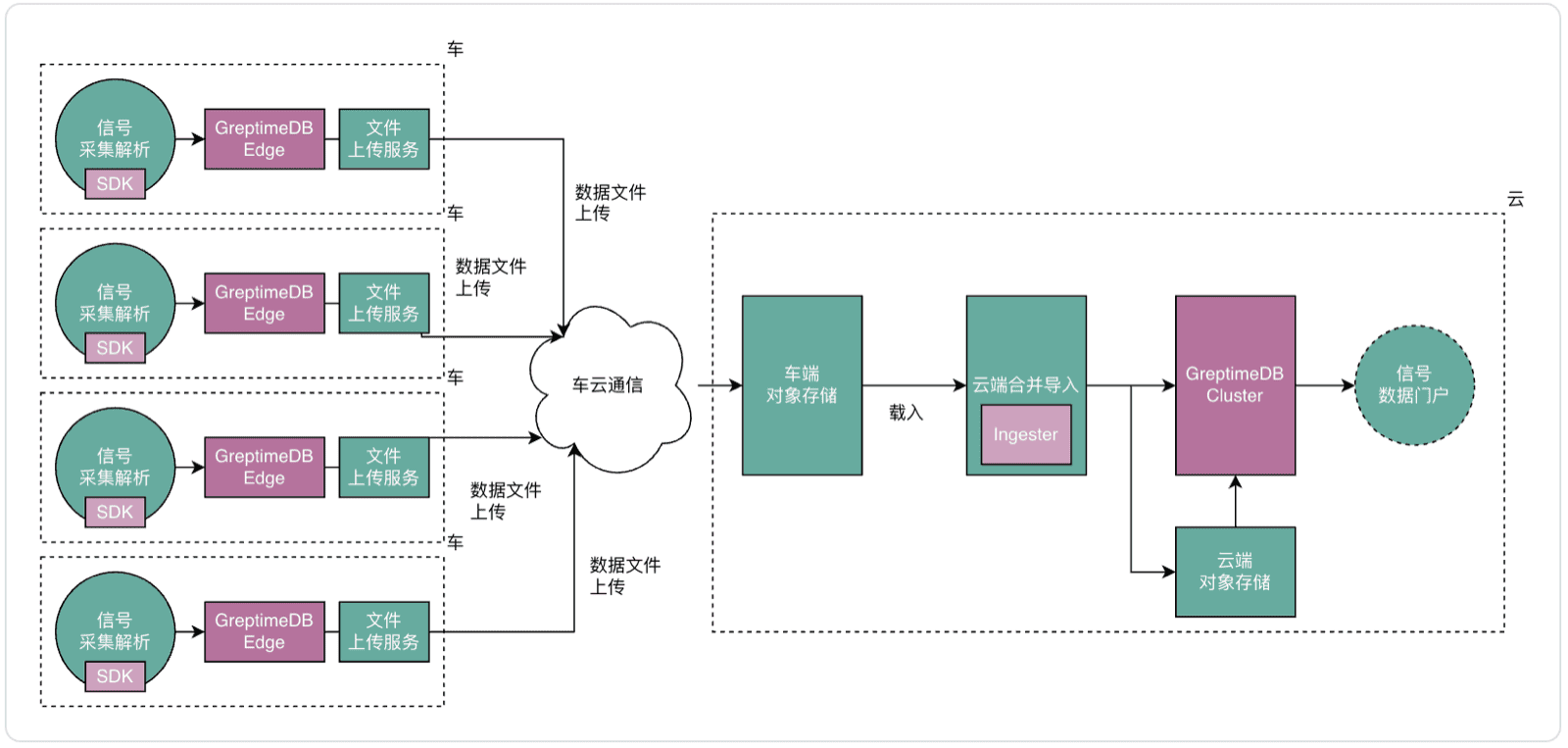
车云无缝协同
走向"车载可观测大数据":车端时序数据库如何驱动高级诊断升级
把时序数据库搬上车,最初的动念是"存得下、传得起"。但随着架构逐渐成熟,我们发现在车端拥有一个完整的、可查询的数据库,带来的想象空间远不止于此——它正在重新定义车辆的高级诊断与分析能力。
数据基石:从"片段"到"全量档案"
传统黑匣子模式只能存下故障前后几十秒的数据,像是一个只有"案发现场"的报告。而在车端部署时序数据库后,理想可以存储全量结构化的信号与日志,形成每辆车完整的运行数据档案。
这意味着当用户反馈"我的车最近感觉有点怪,但说不清哪里不对"时,售后团队不再只能碰运气——他们可以回溯过去几天甚至更长时间内的毫秒级信号,看看那些细微的波动背后,是不是藏着什么端倪。
诊断深度:看见"看不见的问题"
有些故障,不是亮个故障码就能说清楚的。比如三电系统的偶发性性能衰减、某些场景下的 NVH 异常,它们往往是多个信号在时间轴上交叉作用的产物,靠单点阈值告警根本抓不住。
有了车端时序数据库,可以在车端或云端对这些长周期、高频率的数据做复杂计算:把电压、电流、温度、转速等信号对齐到同一时间轴,分析它们之间的时序关系和联动模式。那些传统诊断手段无法触及的复杂特征故障,终于变得**"可见、可分析、可预测"**。
诊断模式升级:从"被动应答"到"主动预警"
更关键的是,数据库下沉到车端,让诊断逻辑本身也可以下沉。将售后团队积累的诊断策略,以算法或查询任务的形式下发到车上,让车端具备执行高级自诊断的能力。
想象一下这样的场景:车辆不再等故障发生后再上传数据"喊救命",而是在日常行驶中,基于本地存储的全量数据,持续扫描异常特征。当它发现某些信号组合接近历史故障的前兆模式时,可以主动预警、提前干预,甚至在用户感知到问题之前,就安排进店检查。
从"车坏了,查原因"到"车感觉要坏了,先看看"——这背后,正是车端时序数据库带来的诊断范式迁移。
结语
通过 GreptimeDB 构建的车云一体数据架构,理想构建了新一代的原始数据可观测平台。它既全面提升了数据的可见性与可用性,又通过技术优化,在性能和成本之间找到了优雅的平衡。更重要的是,它为高级诊断、主动预警等前瞻能力,铺好了数据层面的地基。
这套方案为理想汽车节省了千万级的流量与云端资源费用,也印证了一件事:真正的可观测能力,未必需要以高昂的成本和性能妥协为代价。数据,作为智能汽车的"血液",正持续驱动着产品的进化与体验的保障。
了解更多 Greptime 车云一体方案,请访问 Greptime 车云一体方案页面。

