
本页内容
AI agent 不再只是聊天机器人。越来越多的 agent 开始直接操作基础设施:检查数据库 schema,生成 SQL,执行查询,再根据结果决定下一步。从提问到拿到答案,整个过程几秒就完成了。数据库多了一类新用户。
对 GreptimeDB 来说,这件事有两面。一面是让 agent 能连上来查数据、做操作。另一面可能更有意思:作为可观测性数据库 (Observability Database),GreptimeDB 本身就是存放 agent 行为数据的地方。LLM 调用的 trace、token 消耗指标、对话日志,这些都是可观测性数据。
这篇文章梳理我们在这个方向上做的几件事。
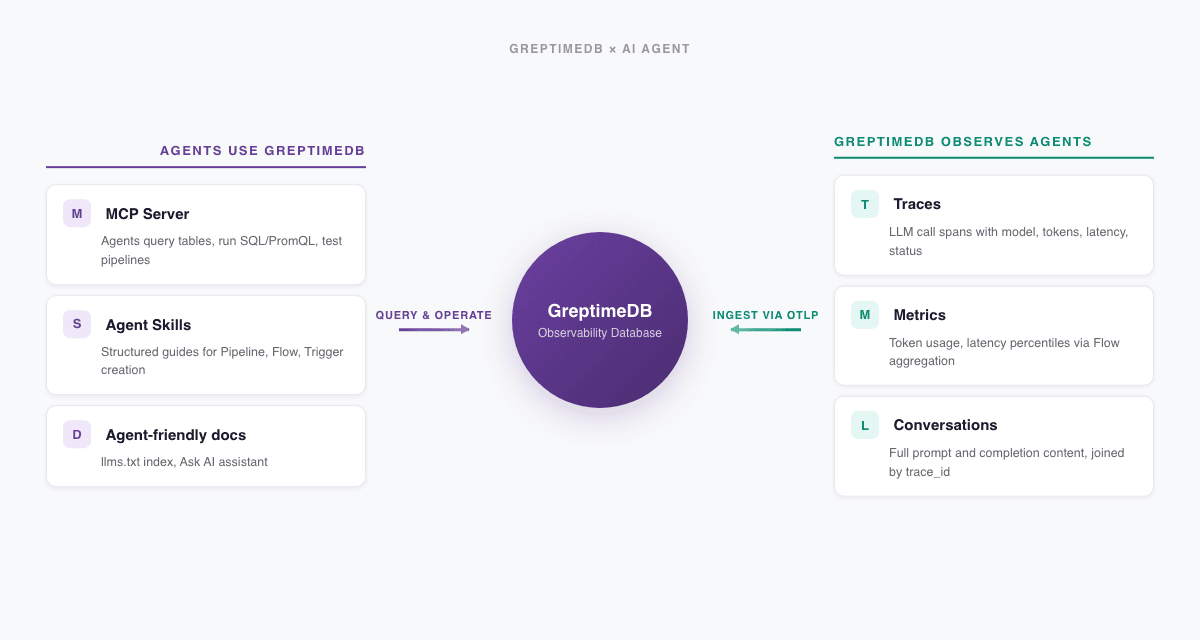
MCP Server:让 agent 查询可观测性数据
Model Context Protocol (MCP) 是 Anthropic 发起的开放协议,给 LLM 提供了连接外部工具和数据源的标准接口。我们开源了 GreptimeDB MCP Server,让 AI agent 通过 MCP 直接查询和分析 GreptimeDB 中的数据。
安装一行命令:
bash
pip install greptimedb-mcp-server配置到 Claude Desktop 或其他 MCP 客户端后,agent 就能列出数据库中的表、读取数据、执行 SQL/TQL(PromQL 兼容)/RANGE 查询。
内置的场景化模板
很多数据库的 MCP server 做到"能执行 SQL"就停了。GreptimeDB 的 MCP Server 往前走了一步,内置了 7 个场景化的 prompt 模板:
metrics_analysis— 指标分析,包含异常检测和聚合查询的 SQL 示例trace_analysis— 链路追踪分析,涵盖 span 查询、错误率计算、延迟分位数promql_analysis— PromQL 查询分析iot_monitoring— IoT 设备监控pipeline_creator— 日志管道创建,包含处理器语法、索引选择指南、日志格式模板log_pipeline— 日志管道管理table_operation— 表操作
拿 pipeline_creator 来说,它包含了 GreptimeDB Pipeline 的完整语法参考——dissect、regex、date、epoch 等处理器怎么写,三种索引类型分别适合什么场景(inverted 适合低基数字段过滤,fulltext 适合全文搜索,skipping 适合高基数 ID),以及日志表设计时该注意什么。agent 加载这个模板后,可以直接从一条 nginx 日志样本生成可用的 Pipeline 配置。
面向生产环境
MCP Server 在安全性和生产可用性上做了几件事:
- 数据脱敏:
GREPTIMEDB_MASK_ENABLED=true开启后,敏感数据在返回给 LLM 前被替换为****** - 只读强制:DDL/DML 操作被安全门拦截,agent 只能查询
- Pipeline 管理工具:
create_pipeline和dryrun_pipeline让 agent 可以创建和测试日志处理管道 - 多种传输模式:stdio 用于开发,SSE 用于兼容,Streamable HTTP 推荐生产使用
更多详情见 MCP Server 介绍博客和 v0.3 发布博客。
Agent Skills:教 agent 操作 GreptimeDB
MCP Server 给了 agent 工具,但光有工具不够。agent 还需要知道怎么把这些工具组合起来完成一件事。这就是 Agent Skills 解决的问题。
Agent Skills 是一个开放标准,目前 Claude Code、OpenAI Codex CLI、GitHub Copilot、Cursor 等 AI 编码助手都已支持。一个 Skill 就是一个 SKILL.md 文件,包含结构化的指令,agent 遇到相关任务时自动加载。
我们在 GreptimeDB 文档仓库发布了三个 Skills:
greptimedb-pipeline
教 agent 创建日志处理管道 (Pipeline)。工作流分四步:
- 学习:agent 加载 Pipeline 官方文档,理解处理器和 transform 语法
- 创建:根据用户给的日志样本,生成 Pipeline YAML 和对应的表定义
- 验证:如果 MCP Server 可用,用
dryrun_pipeline测试配置是否正确 - 优化:根据用户的额外需求调整,比如数据分发规则、索引类型、表选项
greptimedb-flow
教 agent 创建 Flow 任务(持续聚合)。agent 理解用户想要的时间窗口和聚合规则后,生成 CREATE FLOW 和对应 sink 表的 DDL,再通过 MCP Server 的 execute_sql 工具执行和验证。
greptimedb-trigger
教 agent 创建告警规则 (Trigger)。如果用户有现成的 Prometheus 告警规则 YAML,agent 可以把它转成 GreptimeDB 的 CREATE TRIGGER 语句。
安装方式:
bash
npx skills add https://github.com/GreptimeTeam/docs/tree/main/skills/greptimedb-pipeline
npx skills add https://github.com/GreptimeTeam/docs/tree/main/skills/greptimedb-flow
npx skills add https://github.com/GreptimeTeam/docs/tree/main/skills/greptimedb-triggerSkills 和 MCP Server 的配合
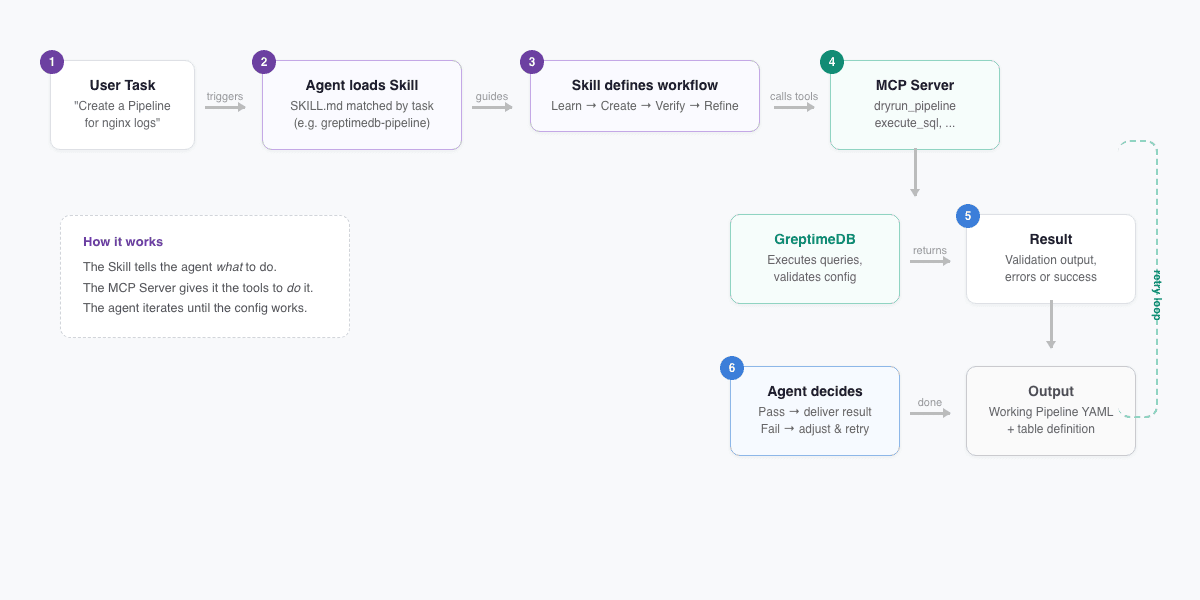
这里有个细节值得说一下。Skills 和 MCP Server 是配合使用的——Skill 教 agent 该做什么,MCP Server 给 agent 动手的工具。比如 greptimedb-pipeline Skill 里明确写了:
如果 greptimedb-mcp-server 可用,用
dryrun_pipeline工具测试配置。
所以 agent 不是生成配置文件就完事了,它会自己跑测试、看结果、调整,直到配置能用。
目前这三个 Skills 都是任务导向的,教 agent 从头到尾完成一件具体的事。后续我们会加入 best practices 类的规则——schema 设计、查询优化、写入调优——让 agent 写 GreptimeDB 相关代码时也有章可循。
GenAI Observability:观测 agent 本身
前面两部分讲的是 agent 怎么用 GreptimeDB。这部分反过来:用 GreptimeDB 观测 agent 和 LLM 应用。
GreptimeDB 的 Observability 2.0 架构把 metrics、logs、traces 统一为宽事件 (Wide Events),存在同一个引擎里。LLM 应用的调用 trace、token 指标、对话日志,本质上也是这三种信号。不需要再引入一套专门的 LLM 可观测性工具,用 GreptimeDB 就够了。
问题:三套系统,一个问题查三遍
LLM 应用出问题时,工程师通常要回答这类问题:
- 这个请求为什么慢?是模型响应慢,还是应用逻辑的问题?
- Token 用量上周涨了三倍。哪个用户?哪个 prompt?
- 用户投诉"AI 回答得不对",能找到那次对话吗?
如果用传统方案,数据散在三个地方:Jaeger 存 trace,Prometheus 存 token 指标,Elasticsearch 存对话内容。回答一个问题,要在三个 UI 之间来回切。
方案:一个数据库,三种信号
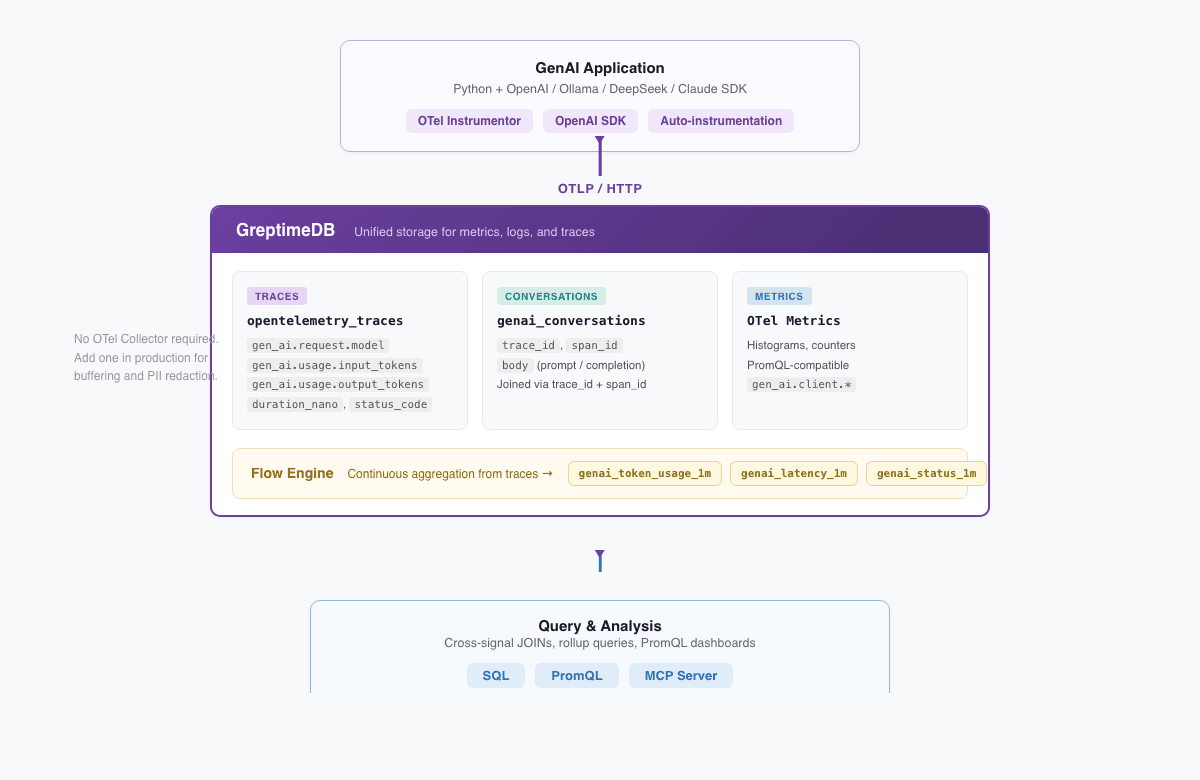
我们基于 OpenTelemetry GenAI Semantic Conventions(gen_ai.* 属性规范)做了一个完整的 demo,展示 GreptimeDB 如何同时存储 trace、metrics 和对话内容。
架构如下:
GenAI App (Python + OpenAI SDK + OTel Instrumentor)
│
│ OTLP/HTTP
▼
GreptimeDB
├── opentelemetry_traces ← span 属性展平成可查询的列
├── genai_conversations ← prompt 和 completion 的完整内容
├── OTel metrics ← histogram,兼容 PromQL
└── Flow 聚合表 ← 持续聚合的 token/延迟/状态汇总OTLP 数据直连 GreptimeDB,不需要中间的 OTel Collector(生产环境建议加上,用于缓冲和 PII 脱敏)。instrument 代码只有一行:
python
from opentelemetry.instrumentation.openai_v2 import OpenAIInstrumentor
OpenAIInstrumentor().instrument()demo 支持四种后端:OpenAI、Ollama(本地免费)、DeepSeek、Claude。一键启动:
bash
docker compose --profile load up -d跨信号 JOIN:一条 SQL 关联 trace 和对话
三种信号在同一个数据库里,最直接的好处是可以 JOIN。比如找出 token 消耗最高的用户提问,同时看对应的模型和 token 数:
sql
SELECT
t.trace_id,
t."span_attributes.gen_ai.request.model" AS model,
t."span_attributes.gen_ai.usage.input_tokens" AS input_tokens,
t."span_attributes.gen_ai.usage.output_tokens" AS output_tokens,
json_get_string(parse_json(c.body), 'content') AS user_message
FROM opentelemetry_traces t
JOIN genai_conversations c
ON t.trace_id = c.trace_id AND t.span_id = c.span_id
WHERE t."span_attributes.gen_ai.system" IS NOT NULL
AND json_get_string(parse_json(c.body), 'message.role') IS NULL
ORDER BY input_tokens DESC
LIMIT 10;如果 trace 和对话日志分别在不同系统,这种关联得在应用层拼接,写起来费劲,跑起来也慢。
Flow Engine:从 trace 直接派生 metrics
GreptimeDB 的 Flow Engine 做持续聚合,类似会自动刷新的物化视图。每个 LLM 调用的 span 本身就是一个宽事件——模型名、token 数、延迟、状态码都在里面。用 Flow 直接从 trace 派生 metrics,应用端不需要写两份数据:
sql
CREATE FLOW IF NOT EXISTS genai_token_usage_flow
SINK TO genai_token_usage_1m
EXPIRE AFTER '24h'
AS
SELECT
"span_attributes.gen_ai.request.model" AS model,
COUNT("span_attributes.gen_ai.request.model") AS request_count,
SUM(CAST("span_attributes.gen_ai.usage.input_tokens" AS DOUBLE)) AS total_input_tokens,
SUM(CAST("span_attributes.gen_ai.usage.output_tokens" AS DOUBLE)) AS total_output_tokens,
date_bin('1 minute'::INTERVAL, "timestamp") AS time_window
FROM opentelemetry_traces
WHERE "span_attributes.gen_ai.system" IS NOT NULL
GROUP BY "span_attributes.gen_ai.request.model", time_window;demo 中定义了三个 Flow:token 用量、延迟分布(用 uddsketch 做分位数计算)、按模型和状态码的请求计数。查 p95 延迟不用扫全量 trace,查聚合表就行:
sql
SELECT model,
ROUND(uddsketch_calc(0.50, duration_sketch) / 1000000, 1) AS p50_ms,
ROUND(uddsketch_calc(0.95, duration_sketch) / 1000000, 1) AS p95_ms
FROM genai_latency_1m
ORDER BY time_window DESC LIMIT 20;完整方案见这篇博客:One Database for LLM Observability: Traces, Metrics, and Conversations。
Agent-Friendly 的文档和 AI 助手
工具和数据库能力之外,我们也在让文档对 agent 更友好。
文档站发布了 llms.txt,遵循 llmstxt.org 标准。这是文档的结构化索引,agent 读了这个文件就知道该去哪找需要的内容,不用遍历整个站点。
文档站和官网还集成了 Ask AI 助手,用自然语言提问就能拿到基于官方文档的回答。对刚上手的开发者来说,比自己翻目录快不少。
为什么是 GreptimeDB
上面讲的是具体的工具和产品。回到架构层面说几句。
GreptimeDB 把 metrics、logs、traces 统一为带时间戳的宽事件 (Wide Events),存在同一个列式引擎里。GenAI 的 trace、token 指标、对话日志不需要三套基础设施,一个数据库搞定,一条 SQL 就能关联。这是 Observability 2.0 的核心思路。
查询语言上,SQL 和 PromQL 都支持。Agent 生成 SQL 是自然的事;已有的 Prometheus 监控用 PromQL 也能继续跑。两种语言查同一份数据。
存储上,主存储是 S3、GCS、Azure Blob 这类对象存储,计算和存储分离。LLM 应用的可观测性数据量增长快,对话日志尤其占空间,对象存储的成本优势在这个场景下很明显。
协议上,原生支持 OTLP、Prometheus Remote Write、InfluxDB Line Protocol。LLM 应用用 OTel 做 instrumentation 后,数据直连 GreptimeDB,不需要额外的适配。
GreptimeDB 还能跑在 ARM 边缘设备上。如果 agent 部署在边缘(IoT 场景比较常见),本地就能存储和查询可观测性数据。
试试看
- 安装 MCP Server:
pip install greptimedb-mcp-server - 安装 Agent Skills:
npx skills add https://github.com/GreptimeTeam/docs/tree/main/skills/greptimedb-pipeline - 跑一遍 GenAI Observability demo:
docker compose --profile load up -d - 在 docs.greptime.cn 试试 Ask AI
后续我们会继续补充 Agent Skills(包括 best practices 规则),完善文档的 Markdown 化,在 MCP Server 中增加更多分析场景的支持。

