
本页内容
“可观测性 2.0”是由 Honeycomb 的 CTO Charity Majors 提出的概念,虽然这种版本号式的命名方式存在争议,甚至后来还引发了关于“可观测性 3.0”/“4.0”的讨论。但“2.0”所代表的,其实是对传统可观测性“三大支柱”(指标、日志、追踪)的一次演进与突破。
这三大支柱在过去近十年主导了运维监控领域的主流实践,而“可观测性 2.0”则主张以“宽事件”(wide events)作为统一的数据基础,强调使用高基数、宽结构的数据集(high-cardinality, wide-event datasets),代替传统的孤立监控信号,以更好地应对当代系统架构日益增长的复杂性。
什么是“可观测性 2.0”和宽事件
多年以来,可观测性的实践一直建立在指标、日志和追踪的基础上,衍生出了无数的编程库、工具和标准,还催生了 OpenTelemetry 这一成功的 CNCF 项目,完全基于这三种数据类型设定。
随着开发者对可观测性提出了更多要求,传统的方式逐渐体现出一些局限性:
传统可观测性的问题
- 数据孤岛:指标、日志和追踪三种数据来自不同的数据源,分散采集、独立存储,数据之间难以实现关联,甚至会因为无法对齐颗粒度而导致数据质量问题;
- 预聚合的代价:预聚合指标(如计数器、摘要、直方图)最初通过牺牲数据粒度来降低存储成本和提升性能。这种设计的本意是“以简驭繁”,却牺牲了数据的上下文信息。为了弥补这一点,团队常常不得不创建数百万条时间序列来捕捉细节,讽刺的是,这反而带来了指数级增长的存储和计算成本,与最初的节省目标完全背道而驰;
- 非结构化日志的困境:虽然现代日志系统鼓励结构化,但现实中大量日志仍以非结构化文本形式存在。要从中提取有价值的信息,通常需要复杂的解析、索引和处理流程,资源消耗巨大;
- 静态插桩的局限:工具依赖预定义的查询和阈值,仅能检测“已知的已知问题”(known knowns)。若需新增日志或指标,必须同步修改代码,最终不得不拖累软件开发周期;
- 数据冗余:相同的上下文信息在指标、日志和追踪中重复存储,既浪费存储空间,又增加了管理开销。
“可观测性 2.0”的方案
“可观测性 2.0”通过采用宽事件(wide events)作为基础数据结构来解决上述问题。它不再预先计算指标或结构化日志,而是将原始的、高保真的事件数据保留为单一事实来源(single source of truth)。这使得团队能够对历史数据进行探索性分析,并直接从原始数据集中动态生成指标、日志和追踪。
Cloudflare 的 Boris Tane 在其文章《可观测性宽事件 101》中将宽事件定义为一种上下文丰富(context-rich)、高维度(high-dimensional)且高基数(high-cardinality)的记录。
例如,一个宽事件可能包含以下类型的信息:
json
{
"method": "POST",
"path": "/articles",
"service": "articles",
"outcome": "ok",
"status_code": 201,
"duration": 268,
"requestId": "8bfdf7ecdd485694",
"timestamp":"2024-09-08 06:14:05.680",
"message": "Article created",
"commit_hash": "690de31f245eb4f2160643e0dbb5304179a1cdd3",
"user": {
"id": "fdc4ddd4-8b30-4ee9-83aa-abd2e59e9603",
"activated": true,
"subscription": {
"id": "1aeb233c-1572-4f54-bd10-837c7d34b2d3",
"trial": true,
"plan": "free",
"expiration": "2024-09-16 14:16:37.980",
"created": "2024-08-16 14:16:37.980",
"updated": "2024-08-16 14:16:37.980"
},
"created": "2024-08-16 14:16:37.980",
"updated": "2024-08-16 14:16:37.980"
},
"article": {
"id": "f8d4d21c-f1fd-48b9-a4ce-285c263170cc",
"title": "Test Blog Post",
"ownerId": "fdc4ddd4-8b30-4ee9-83aa-abd2e59e9603",
"published": false,
"created": "2024-09-08 06:14:05.460",
"updated": "2024-09-08 06:14:05.460"
},
"db": {
"query": "INSERT INTO articles (id, title, content, owner_id, published, created, updated) VALUES ($1, $2, $3, $4, $5, $6, $7);",
"parameters": {
"$1": "f8d4d21c-f1fd-48b9-a4ce-285c263170cc",
"$2": "Test Blog Post",
"$3": "******",
"$4": "fdc4ddd4-8b30-4ee9-83aa-abd2e59e9603",
"$5": false,
"$6": "2024-09-08 06:14:05.460",
"$7": "2024-09-08 06:14:05.460"
}
},
"cache": {
"operation": "write",
"key": "f8d4d21c-f1fd-48b9-a4ce-285c263170cc",
"value": "{\"article\":{\"id\":\"f8d4d21c-f1fd-48b9-a4ce-285c263170cc\",\"title\":\"Test Blog Post\"..."
},
"headers": {
"accept-encoding": "gzip, br",
"cf-connecting-ip": "*****",
"connection": "Keep-Alive",
"content-length": "1963",
"content-type": "application/json",
"host": "website.com",
"url": "https://website.com/articles",
"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36",
"Authorization": "********",
"x-forwarded-proto": "https",
"x-real-ip": "******"
}
}宽事件(wide events)包含的上下文信息量远多于传统的结构化日志,足以捕获完整的应用程序状态细节。这些事件作为原始数据集存储在可观测性数据仓库中,团队可从中计算出任何传统指标。
例如:
- 特定 API 路径的 QPS(每秒请求数);
- 按 HTTP 状态码分类的响应时延分布;
- 基于用户地域或设备类型筛选的错误率。
此过程无需代码变更——指标直接通过查询原始事件数据动态生成,从而彻底消除了预聚合(pre-aggregation)和预先插桩(prior instrumentation)的需求。
具体实践方案可参考:
“可观测性 2.0”的落地挑战
传统指标和日志的设计以资源效率为核心:优先最小化计算与存储成本。
例如,Prometheus 采用一种类似键值对的数据模型进行时序存储,这与早期 NoSQL 时代的思路相似,开发者将一部分计数器、集合和列表等数据结构从关系型数据库迁移到 Redis,这么做快速、简单,可观测性工具也通过预聚合指标来降低开销。
然而,正如软件工程逐步演进至大数据驱动的范式,从“三大支柱”到宽事件的转变,反映了行业对原始细粒度数据(而非预计算摘要)需求的增加。
这一转型将面临以下关键挑战:
- 事件生成:缺乏成熟框架对应用进行插桩(instrumentation),以生成标准化、上下文丰富的宽事件;
- 数据传输:如何高效流式传输高吞吐量事件数据,避免瓶颈或延迟;
- 经济性存储:在保证查询性能的前提下,低成本存储 TB 级原始高基数数据;
- 查询灵活性:支持跨任意维度(如用户属性、请求路径)的按需分析,无需预定义模式;
- 工具链集成:通过从存储的事件中动态生成指标和日志(而非在应用层预生成),复用现有工具(如仪表盘、告警系统)。
什么是“可观测性 2.0”的原生数据库
如 Charity Majors 在她的博客文章里指出,可观测性正逐步走向数据湖模式。虽然宽事件作为单一数据源简化了数据建模,但现在也需要基础设施能够系统性地解决前文所述的挑战。
采用“可观测性 2.0”的目标是最大化原始数据的价值,同时避免过度复杂的架构。
尽管从技术层面可以通过以下组件拼凑方案来解决现有问题:
- 使用 OLAP 数据库存储原始事件;
- 构建预处理管道生成衍生指标/追踪;
- 独立指标存储支持仪表盘;
- 专用追踪存储对接分布式追踪 API;
- 冷数据备份系统;
- ……
但这种碎片化的架构违背了“可观测性 2.0”的初衷,同时让可观测体系更加难以维护。
这就要求我们针对这种使用场景设计一个优化的“可观测性 2.0 原生数据库”。
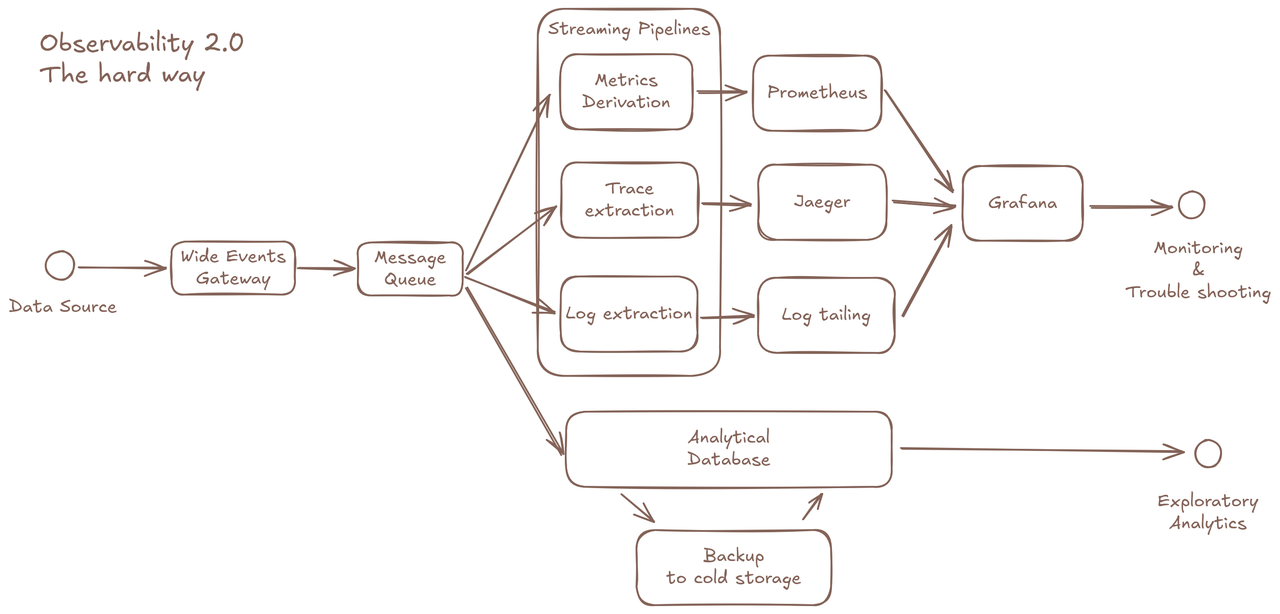
以下是我们总结的“可观测性 2.0 数据库”的关键要求👇
高效利用通用存储资源与数据格式
- 存算分离架构与云对象存储
- 列式数据格式支持压缩与性能优化
如 Boris Tane 所示,单个未压缩的宽事件可能超过 2KB。对于高吞吐的微服务应用,这将导致巨大的存储膨胀,尤其是在需要长期保留数据以支持持续分析(例如训练 AI 模型或审计历史趋势)的场景。
因此,数据库必须优先利用云对象存储(如 AWS S3、Google Cloud Storage)来实现成本效益和可扩展性。
理想情况下,它具备以下能力:
- 支持冷热数据自动分层,在本地缓存与云存储间智能调度;
- 实现存算分离架构,计算节点按需弹性扩展,避免资源浪费;
- 具备极低的管理开销,适合云原生部署。
与此同时,列式数据格式(如 Apache Parquet、Arrow)成为宽事件存储的默认选择。相比行式样格式:
- 按字段顺序存储数据值,支持定制编码(如字典编码、游程编码)以压缩数据,极大降低存储开销;
- 更适合分析型查询,尤其在只读取少量字段时,可实现高效的聚合计算。
实时性、可扩展性与弹性
- 低延迟查询与数据可见性;
- 数据写入量可随业务流量弹性扩展。
传统指标因其预聚合特性,数据量仅和部署规模呈线性关系,这使得指标存储的容量规划相对简单。然而,当宽事件作为单一事实来源时,可观测性数据会按流量生成,这意味着**“可观测性 2.0”基础设施必须与应用程序具备同等的弹性扩展能力**。
为适应现代云环境,数据库设计需谨慎:
- 将状态管理限制在最小范围;
- 明确各类型节点的职责分离。
数据必须实现实时写入和可查询,以满足仪表盘和告警等实时场景的需求。
灵活查询能力
- 支持“可观测性 1.0”查询与分析型查询;
- 指标需直接从宽事件动态生成。
“可观测性 2.0”数据库需支持两类查询:
- 常规查询(用于仪表盘和告警);
- 探索性查询(用于按需分析)。
虽然指标不再作为原始数据,但这并不意味着我们不需要指标数据,而是此聚合事件将产生指标的任务从应用层转移至数据库。用户仍需通过仪表盘或告警快速访问已知的关键信息(如错误率、延迟阈值),这要求数据库高效处理常规查询。数据库必须支持灵活索引策略、预处理能力、增量计算(例如无需全量重处理即可更新聚合结果)等基础能力。
此外,数据库需支持探索性分析——通过离线长期分析发现未知的未知。这类查询通常不可预测,涉及大规模数据集和长时段范围。理想情况下,数据库应在不影响常规查询或数据写入性能的前提下执行此类操作。传统的方式是把数据复制并导入到 OLAP 数据库里,复制导致的延迟和额外成本将破坏“可观测性 2.0” 统一实时洞察的核心目标。
对 “可观测性 1.0”的兼容
现有“可观测性 1.0”的仪表盘、可视化工具和告警规则已非常成熟,向宽事件过渡并不意味着抛弃这些工具或从头构建新的工作流。
相较于 SQL,PromQL 等语言,专为时序指标设计的 DSL 仍最适合时序仪表盘。得益于常规查询(为仪表盘/告警优化)与探索性分析的明确分离,通常情况下不需要复杂的 PromQL 查询,高基数也不再成为可观测性数据库的系统性限制。
追踪视图和日志排查等功能也必须在新的数据后端保持可用。所有“可观测性 1.0”的最佳实践(如告警阈值设定、仪表盘规范、追踪分析流程)都应被保留并增强,而非废弃。
GreptimeDB 对“可观测性 2.0”的支持
GreptimeDB 是专为宽事件(wide events)和“可观测性 2.0”(Observability 2.0)实践打造的开源分析型可观测性数据库。我们将其设计为与现代云基础设施无缝协同,为用户提供高效、一站式的可观测性数据管理体验。

所有“可观测性 2.0”需要的关键能力都可以在 GreptimeDB 中原生实现,用户不需要额外部署任何组件:
- 原生支持 OpenTelemetry 格式数据接入,统一处理 metrics、logs 和 traces;
- 内置转换引擎(transform engine)实现数据预处理;
- 高吞吐实时数据写入(data ingestion),适应大规模的数据场景;
- 实时查询 API,支持低延迟指标/日志/追踪查询;
- 物化视图(materialized view)支持数据衍生计算;
- 只读副本(read-replicas)隔离分析型查询负载;
- 内置规则引擎与触发机制实现推送式告警通知;
- 云对象存储(object storage)保障数据持久化。
基于原始数据的下一代可观测基础设施
在可观测性 2.0 时代,原始数据不再是“中间产物”,而是核心资产。我们相信,围绕原始宽事件构建的统一数据平台,将彻底改变开发者、运维人员和数据团队使用可观测数据的方式。
GreptimeDB 作为这一基础设施的核心组件,帮助用户以渐进式方式完成过渡——从指标为主的旧范式,走向以原始事件为核心的新一代可观测体系。
关于 Greptime
Greptime 格睿科技专注于打造新一代可观测性数据库,服务开发者与企业用户,覆盖从从边缘设备到云端企业级部署的多样化需求。
- GreptimeDB 开源版:开源、云原生,统一处理指标、日志和追踪数据,适合中小规模 IoT,个人项目与可观测性场景;
- GreptimeDB 企业版:面向关键业务,提供更高性能、高安全性、高可用性和智能化运维服务;
- GreptimeCloud 云服务:全托管云服务,零运维体验“企业级”可观测性数据库,弹性扩展,按需付费。
欢迎加入开源社区参与贡献与交流!推荐从带有 good first issue 标签的任务入手,一起共建可观测未来。
⭐ Star us on GitHub | 📚 官网 | 📖 文档

