
本页内容
如何把应用从 InfluxDB 切换到 GreptimeDB?这篇文章把整个过程走一遍。
如果你还在从性能角度评估这次迁移,可以先看 GreptimeDB vs. InfluxDB 性能测试报告,它基于 TSBS 的 CPU 监控负载,对比了读写吞吐。
InfluxDB 用户迁移到 GreptimeDB 时,最容易先看到的是协议兼容:GreptimeDB 支持 InfluxDB line protocol,很多写入链路只需要改 URL、鉴权和数据库名。但真正决定迁移质量的,通常是后两步:历史数据如何平滑导入,以及已有 InfluxQL 查询如何改写成 GreptimeDB SQL。
本文按四个阶段完成迁移。其中第 1 步使用 TSBS 的 IoT use case 构造一组接近真实车联网场景的数据,仅用于方便演示后续步骤;如果你已经有自己的 InfluxDB 数据和查询,可以直接跳过第 1 步,从写入迁移或历史数据迁移开始。
准备演示数据(可选):用 TSBS IoT 数据集写入 InfluxDB。
迁移写请求:把在线写入从 InfluxDB 切到 GreptimeDB。
迁移历史数据:把 InfluxDB 中已有的 line protocol 数据导入 GreptimeDB。
迁移 InfluxQL:把 TSBS IoT 查询改写为 GreptimeDB SQL,并在适合的地方使用 GreptimeDB 的 range query。
GreptimeDB 官方文档中也有更通用的 InfluxDB 迁移指南 和 range query 语法说明。本文会把这些能力放到一个端到端迁移场景中展开。
迁移前先确认数据模型
InfluxDB 的 point 由 measurement、tag set、field set 和 timestamp 组成。通过 InfluxDB line protocol 写入 GreptimeDB 后,GreptimeDB 会把它映射成时序表:
measurement 对应表名,例如
readings、diagnostics。tag 对应主键列,例如 TSBS IoT 中的
name、driver、fleet、model。field 对应普通字段列,例如
latitude、longitude、velocity、fuel_state、current_load。timestamp 对应
greptime_timestamp,类型为TimestampNanosecond,也是时间索引列。
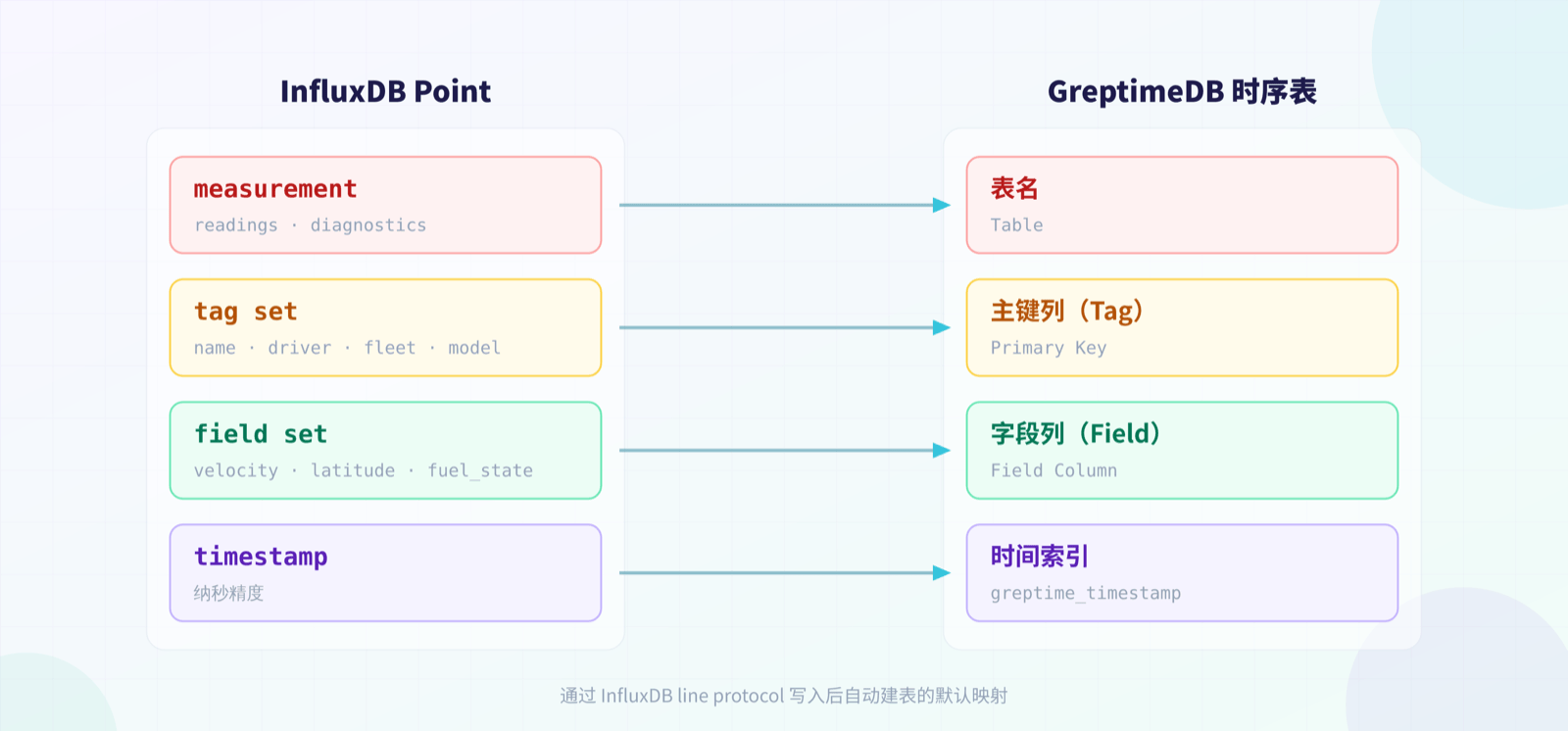
这意味着迁移查询时,不需要再把 InfluxDB 的 measurement/tag/field 当作特殊概念处理;它们已经是普通 SQL 表和列。迁移完成后建议先执行:
sql
DESC TABLE readings;
DESC TABLE diagnostics;
SHOW CREATE TABLE readings;
SHOW CREATE TABLE diagnostics;如果你在迁移前已经手动建表,也可以把时间列命名为 ts 或其他名字。本文后面的 SQL 以 line protocol 自动建表后的默认时间列 greptime_timestamp 为例。
1. 准备演示数据(可选)
这一步只是为了让后面的写入迁移、历史数据迁移和查询改写有一套可复现的数据。如果你已经有自己的 InfluxDB 实例、line protocol 数据或真实业务查询,可以跳过本节,直接进入第 2 节。
先启动一个本地 InfluxDB 1.8 实例。本文使用 InfluxDB 1.x 的数据库模型,便于用 TSBS 生成的 InfluxDB line protocol 数据和 InfluxQL 查询做迁移演示。
shell
docker run --rm --name influxdb-1-8 \
-p 8086:8086 \
influxdb:1.8安装 TSBS。TSBS 仓库提供多个命令,其中本文需要 tsbs_generate_data 生成数据,也可以用 tsbs_generate_queries 生成 InfluxQL 查询样例。
shell
git clone https://github.com/timescale/tsbs.git
cd tsbs
make生成 IoT use case 的 InfluxDB line protocol 数据。下面的规模适合本地演示;生产压测时可以把 --scale 和时间范围调大。
shell
./bin/tsbs_generate_data \
--use-case="iot" \
--seed=123 \
--scale=100 \
--timestamp-start="2026-01-01T00:00:00Z" \
--timestamp-end="2026-01-02T00:00:00Z" \
--log-interval="10s" \
--format="influx" \
| gzip > tsbs-iot-influx.gz创建 InfluxDB 数据库并写入数据。TSBS 生成的是 line protocol,可以直接写入 InfluxDB 的 /write API。为了避免单次请求过大,下面先按行切分。
shell
curl -sS -XPOST "http://localhost:8086/query" \
--data-urlencode "q=CREATE DATABASE benchmark"
mkdir -p tsbs-iot-parts
gunzip -c tsbs-iot-influx.gz \
| split -l 5000 - ./tsbs-iot-parts/data.
for file in ./tsbs-iot-parts/data.*; do
curl -sS -XPOST "http://localhost:8086/write?db=benchmark&precision=ns" \
--data-binary @"${file}"
done简单验证:
shell
curl -G "http://localhost:8086/query" \
--data-urlencode "db=benchmark" \
--data-urlencode "q=SHOW MEASUREMENTS"
curl -G "http://localhost:8086/query" \
--data-urlencode "db=benchmark" \
--data-urlencode "q=SELECT count(*) FROM readings"TSBS IoT 通常会生成两类核心 measurement:
readings:车辆位置、速度、油耗等运行读数。diagnostics:车辆状态、油量、载重等诊断数据。
2. 迁移写请求
在线写入迁移的核心是把 InfluxDB 写入端点切到 GreptimeDB。GreptimeDB 支持 InfluxDB line protocol v1 和 v2 两种常见写入方式。
首先启动 GreptimeDB。下面用 Docker 运行一个单机版 GreptimeDB,用于演示本文的迁移流程:
shell
docker run -p 0.0.0.0:4000-4003:4000-4003 \
-v "$(pwd)/greptimedb_data:/greptimedb_data" \
--name greptime --rm \
greptime/greptimedb:v1.0.2 standalone start \
--http-addr 0.0.0.0:4000 \
--rpc-bind-addr 0.0.0.0:4001 \
--mysql-addr 0.0.0.0:4002 \
--postgres-addr 0.0.0.0:4003GreptimeDB 更多安装方式见官方文档:https://docs.greptime.cn/getting-started/installation/overview/
如果原应用使用 InfluxDB v1 write API:
shell
curl -XPOST "http://127.0.0.1:4000/v1/influxdb/write?db=public&precision=ns" \
--data-binary \
'readings,name=truck_0,fleet=South,driver=driver_0 latitude=37.7749,longitude=-122.4194,velocity=42.0 1451606400000000000'如果原应用使用 InfluxDB v2 write API:
shell
curl -XPOST "http://127.0.0.1:4000/v1/influxdb/api/v2/write?db=public&precision=ns" \
--data-binary \
'readings,name=truck_0,fleet=South,driver=driver_0 latitude=37.7749,longitude=-122.4194,velocity=42.0 1451606400000000000'这一步有两个细节值得提前确认。
第一,db 对应 GreptimeDB 的数据库名。InfluxDB v2 中的 bucket 在 GreptimeDB 这里也通过 db 参数承载;如果使用官方 InfluxDB 客户端,通常把 bucket 设置为 GreptimeDB 数据库名,organization 留空。注意 GreptimeDB 不会自动创建数据库:当 db 参数不是预创建的 public 时,需要先用 CREATE DATABASE 语句手动创建目标数据库。
第二,precision 要和原始 timestamp 精度一致。GreptimeDB 的 InfluxDB line protocol API 默认按纳秒解释 timestamp;如果原请求写的是毫秒、微秒或秒,需要显式传 precision=ms、precision=us 或 precision=s。
在线迁移建议采用双写或灰度切流:先让新写入同时进入 InfluxDB 和 GreptimeDB,对比 count(*)、时间范围、关键聚合查询结果,再逐步把读流量切到 GreptimeDB。确认无误后,再停止写入 InfluxDB。

3. 迁移历史数据
历史数据迁移最直接的路线是继续使用 InfluxDB line protocol。只要能把历史数据导出为 line protocol,就可以通过 GreptimeDB 的 InfluxDB write API 导入。
在本文的 TSBS 演示里,tsbs-iot-influx.gz 本身就是历史数据文件。导入 GreptimeDB 可以复用 GreptimeDB 官方迁移文档中的 shell 模式:
shell
export GREPTIME_HOST="localhost"
export GREPTIME_DB="public"
for file in ./tsbs-iot-parts/data.*; do
curl -i --retry 3 \
-X POST "http://${GREPTIME_HOST}:4000/v1/influxdb/write?db=${GREPTIME_DB}&precision=ns" \
--data-binary @"${file}"
sleep 1
done如果历史数据来自真实 InfluxDB 实例,而不是 TSBS 生成文件,可以按下面的原则处理:
数据量不大时,可以通过应用侧或脚本把数据按 line protocol 格式重新导出,再用 GreptimeDB write API 导入。
数据量较大时,建议按 measurement 和时间范围分批导出,控制单批文件大小,并保留断点记录。
对高基数 tag 的 measurement,导入前先确认 GreptimeDB 表的主键列是否符合预期;自动建表会把 line protocol tags 映射为主键列。
导入后至少校验每个 measurement 的行数、时间范围、字段非空数量和关键聚合查询。
常用校验 SQL:
sql
SELECT
count(*) AS row_count,
min(greptime_timestamp) AS min_ts,
max(greptime_timestamp) AS max_ts
FROM readings;
SELECT
count(*) AS row_count,
min(greptime_timestamp) AS min_ts,
max(greptime_timestamp) AS max_ts
FROM diagnostics;
SELECT fleet, count(*) AS row_count
FROM readings
GROUP BY fleet
ORDER BY row_count DESC;4. 迁移 InfluxQL 到 GreptimeDB SQL
TSBS 的 InfluxDB IoT 查询覆盖了两类场景:
实时状态查询:查某些车辆的最后位置、低油量、高载重、是否长时间行驶等。
分析查询:按 fleet、model、driver、天或 10 分钟窗口聚合。
迁移 InfluxQL 时先看 GreptimeDB SQL 中对应的表达:
InfluxQL 的 measurement 对应 GreptimeDB 表名,例如
readings、diagnostics。InfluxQL 的 tag 和 field 在 GreptimeDB 中都是列;tag 通常也是主键列。
InfluxQL 的
time对应 line protocol 自动建表后的greptime_timestamp。InfluxQL 的
GROUP BY time(10m), "name", "driver"可以改成 GreptimeDB range query:avg(value) RANGE '10m' ... ALIGN '10m' BY (name, driver)。如果只是普通离散分桶,也可以使用
date_bin('10 minutes'::INTERVAL, greptime_timestamp)后再GROUP BY。ORDER BY time DESC LIMIT 1这类 selector 查询,建议改成row_number() OVER (...),明确表达“每个分组的最新点”。difference()、elapsed()这类 InfluxQL 状态变化查询,通常用lag()、lead()和 CTE 改写,可读性会更好。
下面举一些 TSBS IoT 的 InfluxQL 迁移到 GreptimeDB SQL 的例子。假设 TSBS 数据通过 line protocol 写入 GreptimeDB,因此时间列为 greptime_timestamp。
InfluxQL 的改写可以交给 AI 工具完成大部分工作。一个简单的提示词:
“我在迁移 InfluxDB 到 GreptimeDB。帮我把以下 InfluxQL 改写为 GreptimeDB 支持的 SQL:
<要迁移的 InfluxQL>
请至少参考以下文档:
GreptimeDB 的 InfluxDB 数据模型:https://docs.greptime.cn/user-guide/ingest-data/for-iot/influxdb-line-protocol/#数据模型
GreptimeDB 针对时序场景优化的 Range Query:https://docs.greptime.cn/reference/sql/range/
GreptimeDB 的 SQL reference:https://docs.greptime.cn/reference/sql/overview/”
4.1 10 分钟窗口内平均速度低于阈值的车辆
TSBS InfluxQL:
sql
SELECT "name", "driver"
FROM (
SELECT mean("velocity") AS mean_velocity
FROM "readings"
WHERE time > '2026-01-01T00:00:00Z' AND time <= '2026-01-01T00:10:00Z'
GROUP BY time(10m), "name", "driver", "fleet"
LIMIT 1
)
WHERE "fleet" = 'South' AND "mean_velocity" < 1
GROUP BY "name";这类查询的核心是“按 10 分钟窗口、车辆维度聚合速度”。GreptimeDB range query 可以直接表达这个窗口语义:
sql
WITH velocity_by_window AS (
SELECT
greptime_timestamp,
name,
driver,
avg(velocity) RANGE '10m' AS mean_velocity
FROM readings
WHERE greptime_timestamp > '2026-01-01T00:00:00Z'::TIMESTAMP
AND greptime_timestamp <= '2026-01-01T00:10:00Z'::TIMESTAMP
AND fleet = 'South'
ALIGN '10m' BY (name, driver)
)
SELECT name, driver, greptime_timestamp, mean_velocity
FROM velocity_by_window
WHERE mean_velocity < 1;这里的 RANGE '10m' 表示每个聚合窗口覆盖 10 分钟数据,ALIGN '10m' 表示每 10 分钟输出一个对齐后的窗口结果,BY (name, driver) 对应 InfluxQL 中的 tag 分组。
4.2 4 小时内长时间驾驶的车辆
TSBS 的长驾驶查询会先按 10 分钟窗口计算平均速度,再统计平均速度大于 1 的窗口数量。InfluxQL 结构大致如下:
sql
SELECT "name", "driver"
FROM (
SELECT count(*) AS ten_min
FROM (
SELECT mean("velocity") AS mean_velocity
FROM readings
WHERE "fleet" = 'South'
AND time > '2026-01-01T00:00:00Z'
AND time <= '2026-01-01T04:00:00Z'
GROUP BY time(10m), "name", "driver"
)
WHERE "mean_velocity" > 1
GROUP BY "name", "driver"
)
WHERE ten_min > 22;迁移成 GreptimeDB SQL 后,可以把“10 分钟驾驶窗口”作为 CTE,再做二次聚合:
sql
WITH driving_windows AS (
SELECT
greptime_timestamp,
name,
driver,
avg(velocity) RANGE '10m' AS mean_velocity
FROM readings
WHERE fleet = 'South'
AND greptime_timestamp > '2026-01-01T00:00:00Z'::TIMESTAMP
AND greptime_timestamp <= '2026-01-01T04:00:00Z'::TIMESTAMP
ALIGN '10m' BY (name, driver)
)
SELECT
name,
driver,
count(*) AS driving_10m_windows
FROM driving_windows
WHERE mean_velocity > 1
GROUP BY name, driver
HAVING count(*) > 22;22 来自 TSBS 的阈值计算:4 小时内每小时允许休息 5 分钟,剩余驾驶时长折算为 10 分钟窗口。24 小时长驾驶查询的改写方式相同,只需要把时间范围扩大到 24 小时,并把阈值换成对应的 10 分钟窗口数量。
4.3 每日平均驾驶时长
TSBS 的每日驾驶时长查询同样先做 10 分钟窗口聚合,再按天统计窗口数量并除以 6,把 10 分钟窗口换算成小时。InfluxQL 结构可以概括为:
sql
SELECT count("mv") / 6 AS "hours driven"
FROM (
SELECT mean("velocity") AS "mv"
FROM "readings"
WHERE time > '2026-01-01T00:00:00Z'
AND time < '2026-01-02T00:00:00Z'
GROUP BY time(10m), "fleet", "name", "driver"
)
WHERE time > '2026-01-01T00:00:00Z'
AND time < '2026-01-02T00:00:00Z'
GROUP BY time(1d), "fleet", "name", "driver";GreptimeDB SQL:
sql
WITH ten_minute_windows AS (
SELECT
greptime_timestamp,
fleet,
name,
driver,
avg(velocity) RANGE '10m' AS mean_velocity
FROM readings
WHERE greptime_timestamp > '2026-01-01T00:00:00Z'::TIMESTAMP
AND greptime_timestamp < '2026-01-02T00:00:00Z'::TIMESTAMP
ALIGN '10m' BY (fleet, name, driver)
),
daily_sessions AS (
SELECT
fleet,
name,
driver,
date_bin('1 day'::INTERVAL, greptime_timestamp) AS day,
count(*) / 6.0 AS hours_driven
FROM ten_minute_windows
WHERE mean_velocity > 1
GROUP BY fleet, name, driver, day
)
SELECT
fleet,
name,
driver,
avg(hours_driven) AS avg_daily_hours
FROM daily_sessions
GROUP BY fleet, name, driver
ORDER BY fleet, name, driver;这条查询展示了一个常见迁移模式:第一层 range query 负责把原始点规整成 10 分钟窗口,第二层普通 SQL 再做日级别汇总。对于这种多阶段聚合,CTE 通常比 InfluxQL 的多层嵌套更容易维护。
小结
从 InfluxDB 迁移到 GreptimeDB,可以把工作拆成两条线并行推进:
写入和历史数据迁移走 InfluxDB line protocol 兼容路径,先让数据可靠地进入 GreptimeDB。
查询迁移从 InfluxQL 转到 SQL,把 measurement/tag/field 转成表和列,把
GROUP BY time(...)转成date_bin(...)或 GreptimeDB range query。
对 TSBS IoT 这类典型时序分析负载,GreptimeDB 的 SQL 表达会比 InfluxQL 更直接:最新点用窗口函数,状态切换用 lag()/lead(),固定窗口聚合用 date_bin(),需要按时间步长对齐和填充时则用 RANGE ... ALIGN ... BY ... FILL ...。迁移时不要只做语法替换;先还原业务语义,再选择 GreptimeDB 中最清晰、可维护的 SQL 写法。

