
本页内容
我们上周发布了 GreptimeDB 第一份正式的性能报告《单集群 100 节点!资源占用远小于 Grafana Mimir——GreptimeDB 海量数据写入性能报告》,该报告基于 Prometheus benchmark 工具,主要体现的是 GreptimeDB 在可观测场景下处理海量时间线的能力,尤其是分布式水平扩展能力。
这周,我们带来 GreptimeDB 和老牌时序数据库 InfluxDB 的性能对比报告,此报告基于开源的 TSBS 性能测试套件,该测试主要反馈时序数据库的单表读写性能。由于 InfluxDB 3.x 开源版本迟迟没有就绪,我们测试的仍然是 InfluxDB v2 版本。
本次测试采用了 Greptime 团队 fork 的 TSBS 分支,相比官方版本增加了对 GreptimeDB 和 InfluxDB v2 的支持。
在开始详细报告之前,我们先把结论放前面。
测试结论
- GreptimeDB 的写入吞吐是 InfluxDB 的 2 倍以上。
- GreptimeDB 的查询性能在处理大数据量或者重运算场景时优势明显,部分查询速度可达 InfluxDB 的 11 倍以上。
- 查询涉及少量数据时,InfluxDB 查询略快,但两者查询时间都很短,在同一数量级。
- GreptimeDB 在 S3 上的读写性能与本地存储相当,建议使用对象存储时启用本地缓存。
- 在处理大于 10 亿行数据时,GreptimeDB 的分布式版本具备良好的水平和垂直伸缩性,而 InfluxDB 开源版本无法胜任此类场景。
以下是详细的测试报告。
测试环境
硬件环境:
| 实例类型 | c5d.2xlarge |
|---|---|
| 处理器规格 | 8 核 |
| 内存 | 16GB |
| 硬盘 | 100GB(GP3) |
| 操作系统 | Ubuntu Server 24.04 LTS |
软件版本:
| 数据库 | 版本 |
|---|---|
| GreptimeDB | v0.9.1 |
| InfluxDB | v2.7.7 |
除了 GreptimeDB 为了测试存储 S3 而设置了本地缓存,其他参数配置均未进行特别调整,均采用默认设置。
测试场景
本次压测的数据集采用 TSBS 生成的测试数据集,测试数据文件格式为 InfluxDB 的 Line protocol 格式。
plain
cpu,hostname=host_0,region=eu-central-1,datacenter=eu-central-1a,rack=6,os=Ubuntu15.10,arch=x86,team=SF,service=19,service_version=1,service_environment=test usage_user=58i,usage_system=2i,usage_idle=24i,usage_nice=61i,usage_iowait=22i,usage_irq=63i,usage_softirq=6i,usage_steal=44i,usage_guest=80i,usage_guest_nice=38i 1686441600000000000其中 cpu 为 measurement 名称,数据分别包含 1 个时间戳,10 个 tags 和 10 个 fields。生成的数据为若干个主机一段时间内 CPU 的指标。
其中 tags 用来唯一标识该主机,包括:hostname、region、datacenter、 rack、os、arch、 team、service、service_version 和 service_environment。
而 fields 包含机器 CPU 相关的指标,包括:usage_user、usage_system、usage_idle、usage_nice、usage_iowait、usage_irq、usage_softirq、usage_steal、usage_guest 和 usage_guest_nice。
压测工具涉及到的相关关键参数的含义如下:
| 参数名 | 含义 |
|---|---|
| seed | 生成测试数据的随机数种子 |
| scale | 模拟的测试主机数量,即有多少个主机同时上报数据 |
| timestamp-start | 测试数据的开始时间 |
| timestamp-end | 测试数据的结束时间 |
| log-interval | 主机上报数据的间隔 |
TSBS 生成的查询类型和含义如下: 由于一共有 10 个 field 来记录 CPU 相关指标,因此表格里会说明具体取了几个 CPU 指标,表示查询了几个 field。
| 查询类型 | 含义 |
|---|---|
| cpu-max-all-1 | 查询 1 个主机 8 个小时内每个小时所有 CPU 指标的最大值 |
| cpu-max-al1-8 | 查询 8 个主机 8 个小时内每个小时所有 CPU 指标的最大值 |
| double-groupby-1 | 查询所有主机 12 个小时内 1 个 CPU 指标每个小时的平均值 |
| double-groupby-5 | 查询所有主机 12 个小时内 5 个 CPU 指标每个小时的平均值 |
| double-groupby-all | 查询所有主机 12 个小时内所有 CPU 指标每个小时的平均值 |
| groupby-orderby-limit | 1 个 CPU指标最近 5 分钟内的最大值 |
| high-cpu-1 | 1 个主机 12 个小时内 CPU 指标超过 90.0 的所有数据 |
| high-cpu-all | 所有主机 12 个小时内 CPU 指标超过 90.0 的所有数据 |
| lastpoint | 所有主机的最新一行数据 |
| single-groupby-1-1-1 | 1 个主机 1 个小时内 1 个 CPU 指标每分钟的最大值 |
| single-groupby-1-1-12 | 1个主机 12 个小时内 1 个 CPU 指标每分钟的最大值 |
| single-groupby-1-8-1 | 8 个主机 1 个小时内 1 个 CPU 指标每分钟的最大值 |
| single-groupby-5-1-1 | 1 个主机 1 个小时内 5 个 CPU 指标每分钟的最大值 |
| single-groupby-5-1-12 | 1 个主机 12 个小时内 5 个 CPU 指标每分钟的最大值 |
| single-groupby-5-8-1 | 8 个主机 1 个小时内 5 个 CPU 指标每分钟的最大值 |
测试的数据生成参数为:
| 参数名 | 值 |
|---|---|
| seed | 123 |
| scale | 4000 |
| timestamp-start | 2023-06-11T00:00:00Z |
| timestamp-end | 2023-06-14T00:00:00Z |
| log-interval | 10s |
产生的数据超过一亿行(共 103680000 行),数据文件大小约 34G。
本测试中, GreptimeDB 和 InfluxDB 都使用 InfluxDB Line protocol 写入, GreptimeDB 兼容该协议。
测试结果
写入性能
| 数据库 | 写入吞吐(行/秒) |
|---|---|
| InfluxDB | 109356.73 |
| GreptimeDB 基于 EBS | 234620.19 |
| GreptimeDB 基于 S3 | 231038.35 |
查询性能
| 查询类型 | 查询执行次数 | InfluxDB平均耗时(毫秒) | GreptimeDB基于EBS平均耗时(毫秒) | GreptimeDB 基于S3平均耗时(毫秒) |
|---|---|---|---|---|
| cpu-max-all-1 | 100 | 4.29 | 14.75 | 17.59 |
| cpu-max-all-8 | 100 | 10.49 | 30.69 | 38.76 |
| double-groupby-1 | 50 | 1732.68 | 987.85 | 949.09 |
| double-groupby-5 | 50 | 7238.52 | 1455.95 | 1452.27 |
| double-groupby-all | 50 | 14361.24 | 2143.96 | 2186.79 |
| groupby-orderby-limit | 50 | 14951.26 | 1353.49 | 1221.38 |
| high-cpu-1 | 100 | 6.51 | 8.24 | 8.82 |
| high-cpu-all | 50 | 31518.43 | 5312.82 | 5451.37 |
| lastpoint | 100 | 1574.67 | 576.06 | 587.22 |
| single-groupby-1-1-1 | 100 | 1.44 | 6.01 | 6.04 |
| single-groupby-1-1-12 | 100 | 6.22 | 7.42 | 7.28 |
| single-groupby-1-8-1 | 100 | 2.77 | 10.20 | 10.43 |
| single-groupby-5-1-1 | 100 | 2.96 | 6.70 | 6.76 |
| single-groupby-5-1-12 | 100 | 22.02 | 8.72 | 8.48 |
| single-groupby-5-8-1 | 7.11 | 12.07 | 12.51 |
可以看到,在涉及到所有主机 12 个小时内的数据查询,例如 double-group-by-1、double-group-by-5、double-group-by-all 以及 high-cpu-all 等,或者需要排序计算的场景如 groupby-orderby-limit、lastpoint 等 ,GreptimeDB 都体现了较大的查询性能优势(2 - 11 倍不等)。
涉及数据量较少的查询, InfluxDB 仍然体现出一定优势,不过 GreptimeDB 仍然处于同一水平,这是由于两者的架构实现上的差异导致。
我们用柱状图来展示,会更为明显(Y 轴为耗时,越小值表示查询越快):
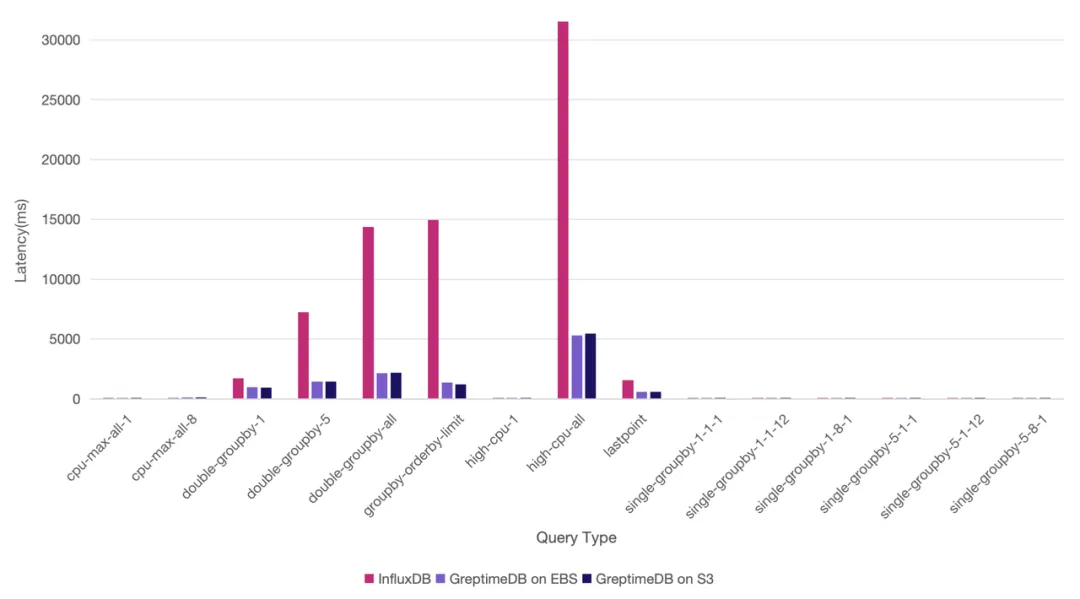
11 亿行数据测试
我们尝试将数据扩展到 40 万个主机,来看看两个数据库的能力。测试数据生成参数如下:
| 参数名 | 值 |
|---|---|
| seed | 123 |
| scale | 400000 |
| timestamp-start | 2023-06-11T00:00:00Z |
| timestamp-end | 2023-06-13T00:00:00Z |
| log-interval | 60s |
产生数据约 11.5 亿行(共 1152000000 行),约 380G。
我们在测试时去掉了部分结果集异常大,失去实际参考意义的查询。
InfluxDB 结果
首先我们尝试将数据写入 InfluxDB,很快就出现了以下报错:
bash
unexpected error writing points to database: engine: cache-max-memory-size exceeded: (1100848220/1073741824)随后,我们也做了一系列的尝试,包括调大报错中提到的参数,使用更大规格的机器(升级到 24C 的机器),都还是无法顺利完成数据写入,写入吞吐会逐渐跌到 2 万行每秒,并触发 TSBS 的反压。
bash
[worker 6] backoff took 5.40sec
[worker 4] backoff took 3.77sec
[worker 8] backoff took 3.77sec
[worker 13] backoff took 3.77sec
[worker 11] backoff took 2.29sec
[worker 2] backoff took 6.09sec
[worker 12] backoff took 6.09sec
[worker 14] backoff took 6.09sec
[worker 3] backoff took 6.09sec
[worker 15] backoff took 6.09sec
[worker 1] backoff took 6.09sec
[worker 9] backoff took 6.09sec
1722445355,62999.07,6.922500E+08,229983.34,6299.91,6.922500E+07,22998.33同时,写入时数据库实际上处于不可用状态,因此 InfluxDB 的测试以失败告终。
GreptimeDB 结果
使用的机器同样为 c5d 系列机器,基于 EBS 存储。集群的容器规格如下:
| 服务 | 实例数 | 容器规格 |
|---|---|---|
| etcd | 3 | 2C4G |
| meta | 1 | 1C2G |
| frontend | 2 | 4C6G |
| datanode | 4 | 4C8G |
测试一共创建了 8 个 region,建表语句如下:
sql
CREATE TABLE IF NOT EXISTS cpu (
hostname STRING NULL,
region STRING NULL,
datacenter STRING NULL,
rack STRING NULL,
os STRING NULL,
arch STRING NULL,
team STRING NULL,
service STRING NULL,
service_version STRING NULL,
service_environment STRING NULL,
usage_user BIGINT NULL,
usage_system BIGINT NULL,
usage_idle BIGINT NULL,
usage_nice BIGINT NULL,
usage_iowait BIGINT NULL,
usage_irq BIGINT NULL,
usage_softirq BIGINT NULL,
usage_steal BIGINT NULL,
usage_guest BIGINT NULL,
usage_guest_nice BIGINT NULL,
ts TIMESTAMP(9) NOT NULL,
TIME INDEX (ts),
PRIMARY KEY (hostname, region, datacenter, rack, os, arch, team, service, service_version, service_environment)
)
PARTITION ON COLUMNS (hostname) (
hostname < 'host_144998',
hostname >= 'host_144998' AND hostname < 'host_189999',
hostname >= 'host_189999' AND hostname < 'host_234998',
hostname >= 'host_234998' AND hostname < 'host_279999',
hostname >= 'host_279999' AND hostname < 'host_324998',
hostname >= 'host_324998' AND hostname < 'host_369999',
hostname >= 'host_369999' AND hostname < 'host_54999',
hostname >= 'host_54999'
);写入吞吐:在 250000 ~ 360000 rows/s 之间,可以顺利完成数据写入。
查询测试结果:
| 查询类型 | 查询执行次数 | 查询耗时(ms) |
|---|---|---|
| cpu-max-al1l-1 | 100 | 140.28 |
| cpu-max-all-8 | 100 | 258.47 |
| high-cpu-1 | 100 | 86.83 |
| single-groupby-1-1-1 | 100 | 23.63 |
| single-groupby-1-1-12 | 100 | 67.67 |
| single-groupby-1-8-1 | 100 | 119.07 |
| single-groupby-5-1-1 | 100 | 22.02 |
| single-groupby-5-1-12 | 100 | 67.90 |
| single-groupby-5-8-1 | 100 | 110.88 |
得益于云原生分布式架构,GreptimeDB 可以通过水平扩展机器,支撑更大规模的数据的读写,而 InfluxDB 无法处理同样场景。
测试手册
为了方便开发者能重现本次测试,我们提供了测试手册,您可以按照该文指示,重现本次测试。
手册地址: https://github.com/GreptimeTeam/tsbs/blob/master/docs/greptimedb-vs-influxdb-manual-zh.md
总结
通过本次测试, GreptimeDB 充分体现了优秀的单表的读写性能,对比 InfluxDB v2 有较为明显的优势,并且在使用对象存储的时候保持了同样优秀的读写能力。未来我们也将持续优化更多查询场景,与业界其他时序数据库继续做对比测试,并在 InfluxDB v3 就绪的时候重新运行此测试。敬请期待。
GreptimeDB v0.9.1 已发布,修复 v0.9.0 发布以来发现的一些 bug,推荐正在使用 v0.9.0 的朋友升级,详细 release note 请阅读: https://github.com/GreptimeTeam/greptimedb/releases/tag/v0.9.1
关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack

