
本页内容
本文介绍小米智能工厂如何基于 GreptimeDB 构建系统交互日志存储方案,实现十亿级日志的高效存储与检索。
背景
在小米智能工厂的数字化运营中,日志监控系统承担着关键角色——它需要实时采集设备与业务系统之间的交互日志,支持工程师快速定位问题、追踪调用链路。
本文讨论的 GreptimeDB 存储对象为系统交互日志,主要用于服务调用排障、链路追踪和运行状态分析,不以生产业务明细或个人敏感信息为分析对象。
随着部署场景扩展,部分工厂提出了私有化部署等合规诉求——希望系统交互日志能够在工厂本地的私有化集群里完成采集、存储与查询。以核心服务为例,一个月的系统交互日志量可达数十亿行,这对存储与检索方案提出了较高要求:
- 大时间范围查询:在小时级、天级范围内检索日志要稳定不超时
- 正文关键词检索:需要在海量正文中按关键词快速定位
- TraceID 链路追踪:基于 TraceID 跨服务追踪调用链路,要求"秒刷结果"的体验
工程团队需要一个能支撑十亿级日志存储、提供高效索引检索、同时兼容业界成熟采集链路的方案。
方案要点
经过调研与验证,小米的系统交互日志方案采用 Promtail 作为采集端、GreptimeDB 作为存储与查询底座。主要考量包括:
原生支持 Promtail 接入
GreptimeDB 提供 Loki Push API 接口,Promtail 可直接将日志推送到 GreptimeDB,无需更换采集组件。原有的 Promtail 配置、日志格式定义都可以复用。
丰富的索引支持
GreptimeDB 提供多种索引类型,可以根据查询模式为不同字段选择合适的索引策略:
| 索引类型 | 适用场景 | 示例字段 |
|---|---|---|
| 跳数索引 (Skipping Index) | 高基数等值查询 | trace_id、span_id |
| 倒排索引 (Inverted Index) | 低基数筛选 | log_level、service |
| 全文索引 (Fulltext Index) | 日志正文关键词检索 | message |
SQL 查询能力
GreptimeDB 支持标准 SQL 查询,工程师可以使用熟悉的 SQL 语法进行复杂的日志分析。
自动 Schema 演进
日志字段经常变化。GreptimeDB 支持自动推断新字段类型并扩展表结构,无需手动维护 Schema。
系统架构
系统交互日志的整体架构如下:
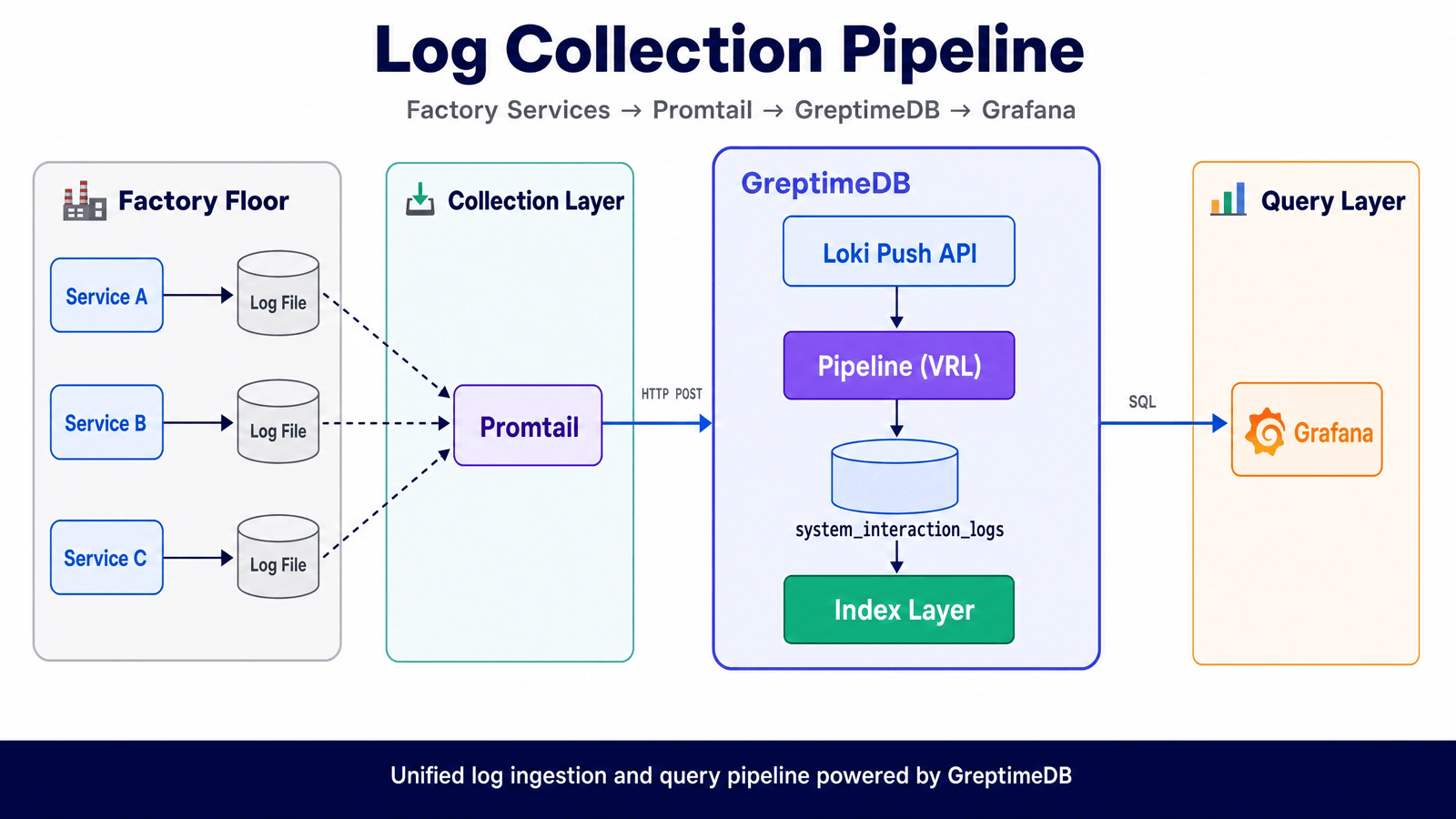
各环节的职责:
- Promtail 采集:部署在各节点采集日志文件,通过 HTTP 推送
- Pipeline 解析:通过 VRL 脚本将 JSON 日志解析为结构化字段
- 多级索引:根据查询模式为不同字段配置合适的索引
- SQL 查询:Grafana 通过 GreptimeDB 插件使用 SQL 查询日志
在这套架构中,GreptimeDB 存储的是解析后的系统交互日志字段,主要服务于系统运行诊断、调用链路排查和日志检索分析。
部署实践
第一步:配置日志推送接口
Promtail 通过 GreptimeDB 提供的 Loki Push API 推送日志,配置如下:
yaml
clients:
- url: http://<greptimedb-host>:4000/v1/loki/api/v1/push
headers:
Authorization: "Basic <base64_encoded_credentials>"
x-greptime-db-name: "public"
x-greptime-log-table-name: "system_interaction_logs"注意认证方式:GreptimeDB 使用 HTTP Basic Auth,需要将 username:password 进行 Base64 编码后放入 Authorization Header。
提示:如果遇到认证相关错误,请优先检查 Basic Auth 配置。这是部署中最常见的问题。
第二步:配置 Pipeline 解析 JSON 日志
系统交互日志采用 JSON 格式,包含丰富的结构化字段。为了将这些字段提取到独立的列,需要配置 GreptimeDB Pipeline(数据管道)。
从 v0.15 开始,GreptimeDB 支持使用 VRL (Vector Remap Language) 处理器,配置示例如下:
yaml
version: 2
processors:
- vrl:
source: |
msg = parse_json!(.loki_line)
. = {
"log_time": parse_timestamp!(msg.timestamp, "%Y-%m-%d %T%.3f"),
"log_level": msg.level,
"logger": msg.logger,
"message": msg.message,
"exception": msg.exception,
"service": .loki_label_job,
"server_ip": msg.server_address,
"client_ip": msg.client_ip,
"thread": msg.thread,
"duration_ms": to_float!(msg.time_spent),
"trace_id": msg.trace_id,
"span_id": msg.span_id,
}
transform:
- field: log_time
type: time, ms
index: timestamp几个关键点:
- 使用
.loki_line:通过 Loki Push API 接入时,日志正文在 GreptimeDB 中映射为loki_line字段 - 使用
.loki_label_*:Promtail 的 Label 在 GreptimeDB 中以loki_label_前缀访问 - 时间字段处理:通过
parse_timestamp!解析日志中的时间戳,作为时间索引 (Time Index)
创建 Pipeline 后,在 Promtail 配置中指定:
yaml
headers:
x-greptime-pipeline-name: "system-interaction-log-json-parse"第三步:配置索引加速查询
根据实际查询模式,为关键字段配置合适的索引。小米团队为 trace_id 配置了 Bloom 类型的跳数索引:
sql
ALTER TABLE system_interaction_logs
MODIFY COLUMN trace_id
SET SKIPPING INDEX WITH(
granularity = 4096,
type = 'BLOOM',
false_positive_rate = 0.01
);索引调优建议:
granularity值越小,查询越快,但索引空间越大- 如果查询性能仍不理想,可以尝试将 granularity 降到 2048 或 1024
- 索引变更只影响新写入的数据,老数据的索引不会更新
如需对日志正文开启全文检索:
sql
ALTER TABLE system_interaction_logs
MODIFY COLUMN message SET FULLTEXT INDEX;第四步:配置 Grafana 数据源
使用 GreptimeDB Grafana 插件查询日志:
- 安装 GreptimeDB Grafana 数据源插件
- 配置数据源连接
- 在 Dashboard 中使用 SQL 查询日志
sql
SELECT greptime_timestamp, message, trace_id, log_level
FROM system_interaction_logs
WHERE greptime_timestamp >= $__fromTime
AND greptime_timestamp <= $__toTime
AND log_level = 'ERROR'
ORDER BY greptime_timestamp DESC
LIMIT 1000第五步:设置数据生命周期
生产环境的日志通常只需按合规要求保留一定时间。使用 TTL 自动清理过期数据,保留周期请根据实际合规要求配置,下面仅为示例:
sql
ALTER TABLE system_interaction_logs SET 'ttl' = '30d';数据删除在 Compaction 时异步执行,不会阻塞写入和查询。即使对超大数据量的表设置 TTL,也不会导致系统卡死。
踩坑与经验
日志重复问题
部署初期发现日志出现重复,每行日志都多出一条完全相同的记录。排查后发现这是 Promtail 侧的配置问题——Logback 和 Promtail 同时采集了同一份日志文件,导致重复写入。
建议:如果发现日志重复,优先检查采集链路的配置,而非 GreptimeDB 侧。
版本选择
生产环境建议使用稳定版本。在部署过程中,团队最初使用了 v0.17 版本,遇到了进程 CPU 异常的问题(火焰图显示全是 kernel timer 中断),回退到 v0.16 后恢复正常。
建议:关注 GreptimeDB 的 Release Notes,新版本上线前先在测试环境充分验证。目前 GreptimeDB 已发布 v1.0 正式版,稳定性得到进一步提升。
监控 GreptimeDB 自身
GreptimeDB 暴露 /metrics 端点,可以用 Prometheus 采集其自身的运行指标,及时发现内存、CPU 异常。官方提供了 Grafana Dashboard 模板。
在使用 v0.16 期间,团队曾遇到一次 OOM 导致进程重启的情况,通过监控指标及时发现并处理。
TTL 语法注意事项
设置 TTL 时,选项名需要带引号:
sql
-- 正确写法
ALTER TABLE system_interaction_logs SET 'ttl' = '30d';
-- 错误写法(会报错)
ALTER TABLE system_interaction_logs SET TTL = '30d';效果与收益
目前,小米智能工厂已完成一个车间的系统交互日志方案灰度验证,整体运行表现符合预期。
查询性能
- TraceID 查询:达到亚秒级响应,满足"秒刷结果"的体验要求
- 时间范围:支持小时级时间窗口的日志检索,运行稳定
- 全文检索:支持基于关键词的高效日志搜索
存储效率
GreptimeDB 的列式存储 (Columnar Storage) 和压缩能力在十亿级日志规模下提供了良好的存储效率。同时,TTL 功能自动清理过期数据,无需手动维护。
运维体验
- 兼容现有采集链路:Promtail 配置改动最小化
- 自动 Schema 演进:新增日志字段无需手动建表
- 标准 SQL:降低了查询的学习成本
总结
基于 GreptimeDB 构建系统交互日志方案,关键步骤包括:
- 配置日志推送接口:Promtail 通过 Loki Push API 写入 GreptimeDB,并配置 Basic Auth 认证
- 设计 Pipeline:根据日志格式编写 VRL 字段提取规则
- 优化索引:根据查询模式为高基数字段配置跳数索引,必要时降低 granularity 提升性能
- 使用 SQL 查询:通过 GreptimeDB Grafana 插件以 SQL 完成日志检索
以下资源可作为进一步参考:
延伸阅读
如果你也在考虑从 Loki 迁移,OceanBase Cloud 在更大规模上走了同样的路:OceanBase Cloud:从 Loki 到 GreptimeDB,300TB 日志的迁移实践——80+ 集群、300 TB 日志,日志存储成本下降超过 60%。
感谢小米智能工厂研发团队在部署过程中的反馈与协作,帮助我们持续优化 GreptimeDB 的日志处理能力。

