
本页内容
2024 年 11 月,Prometheus 3.0 正式发布。这是自 2017 年 2.0 以来的首个大版本,中间跨越 7 年,累计超过 7,500 次提交。在这段时间里,Prometheus 从一个新兴的监控工具发展为云原生监控的事实标准。与此同时,一些无法作为小版本发布的改动逐渐积累——默认启用 UTF-8、引入新的传输协议、全面重写 UI——这些都需要一个大版本作为分界线。
本文将逐一介绍 Prometheus 3.0 的核心变化,并说明 GreptimeDB 如何适配这些变化,继续作为 Prometheus 的 drop-in 后端。

为什么需要大版本?
Prometheus 2.0 重写了存储引擎 TSDB。此后的 7 年间,项目每 6 周发布一个小版本,始终保持向后兼容。
然而,有些改动无法作为小版本发布——默认开启 UTF-8、弃用旧 UI、引入新的 Remote Write protobuf 消息格式。同时,项目也需要清理一批废弃的 feature flag。这些工作需要大版本来完成,3.0 应运而生。
全新 UI
这是最直观的变化。旧 UI 基于过时的 Bootstrap 版本,经过五年的增量修改已经相当杂乱。新 UI 采用 Mantine(一个现代 React 组件框架)进行了完全重写,并内置了此前需要单独安装 PromLens 工具才有的功能。
新增功能包括:
- PromLens 风格的表达式树视图——将 PromQL 查询可视化为子表达式树,鼠标悬停即可查看每个节点的计算结果。在调试复杂查询时非常实用。
- 指标浏览器——提供带上下文信息的指标列表,包括类型和标签维度,比旧 UI 的纯文本列表丰富得多。
- Explain 标签页——直接在 UI 中查看查询行为分析。
- UTF-8 指标名显示——包含 dot、连字符等非 ASCII 字符的指标名可以正确渲染。
需要注意的是,3.0 初始版本的新 UI 仍缺少 exemplar 展示和热力图功能。如需使用这些功能,可通过 --enable-feature=old-ui 切回旧界面。
UTF-8 支持:弥合 OpenTelemetry 的命名差异
对整个可观测性 (Observability) 生态而言,这可能是 3.0 中影响最大的一项变化。
在 3.0 之前,Prometheus 的指标名和标签名只允许 [a-zA-Z_:][a-zA-Z0-9_:]* 字符集。而 OpenTelemetry 的语义约定大量使用 dot 作为分隔符——http.server.duration、system.cpu.utilization、db.client.connections.usage。当 OTel 指标进入 Prometheus 时,dot 会被转换为下划线。SDK 端的 http.server.duration 在查询时变成了 http_server_duration,这种不一致给同时使用两个生态的团队带来了持续的困扰。
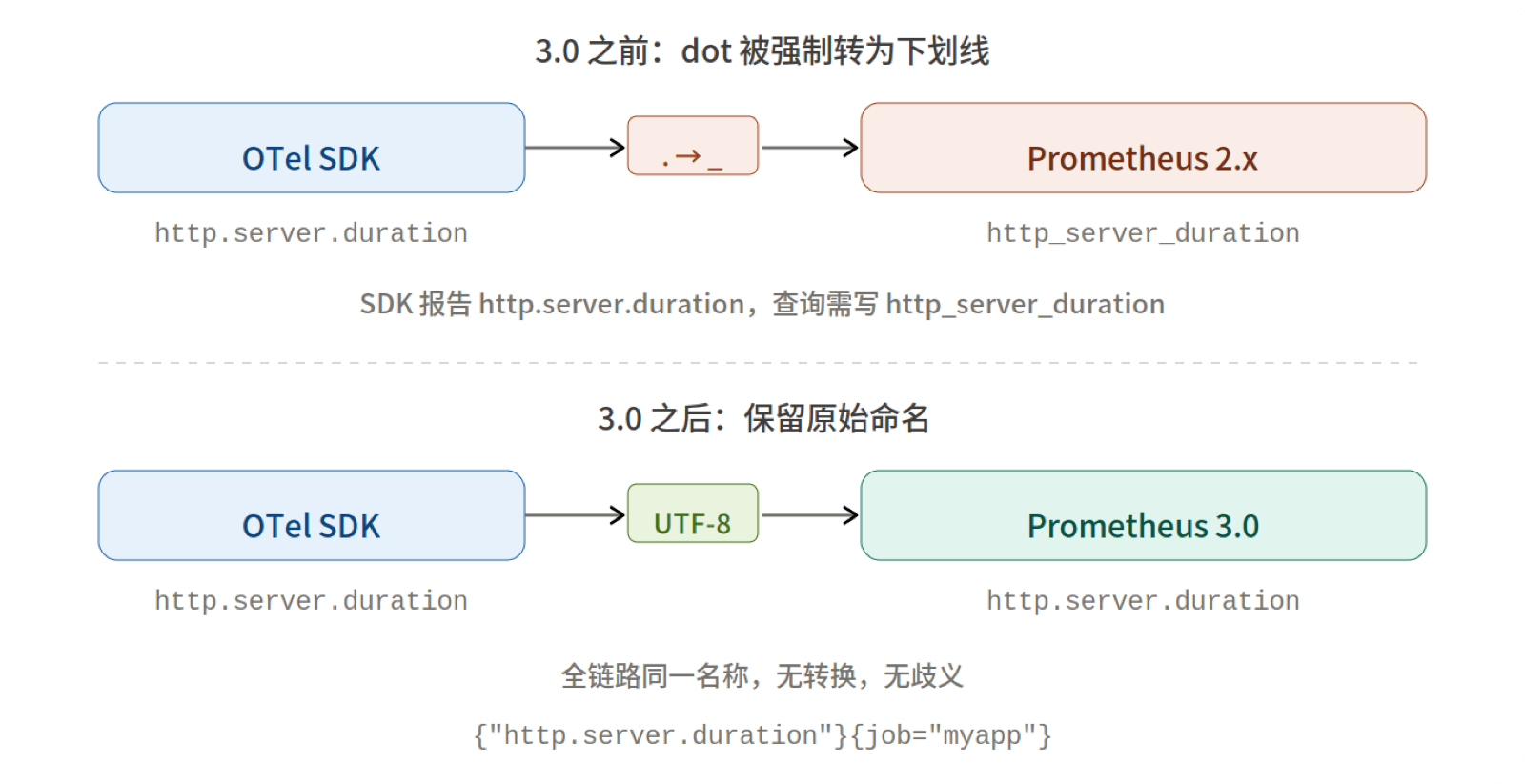
Prometheus 3.0 默认接受所有合法的 UTF-8 字符。PromQL 新增了引号语法来支持这类指标名:
promql
# 传统写法仍然有效
http_server_duration_seconds_bucket{job="myapp"}
# 使用 OTel 原始 dot 命名进行查询
{"http.server.duration"}{job="myapp"}
# 或显式使用 __name__ 标签
{__name__="http.server.duration", job="myapp"}如果需要兼容旧工具,可以按 scrape job 配置传统验证模式:
yaml
scrape_configs:
- job_name: legacy-app
metric_name_validation_scheme: legacy
- job_name: otel-app
metric_name_validation_scheme: utf8注意:截至 3.0,只有 Go 客户端库 (
client_golang) 完整支持发出 UTF-8 指标名,其他语言的 SDK 正在跟进。
Remote Write 2.0:协议的正式升级
Remote Write 是 Prometheus 向外部存储推送指标的机制——Thanos、Cortex、Mimir、GreptimeDB 等长期存储方案都依赖这一协议。1.0 规范于 2023 年 4 月正式发布,但在此之前已有数十个实现在使用这一协议。
这里有一个值得注意的细节。1.0 规范文档定义了一个最小化的 proto 结构:TimeSeries 只包含 labels 和 samples。但 Prometheus 实际的实现(prompb/types.proto)已经超越了规范的范围——TimeSeries 中包含了 exemplars(field 3)和 histograms(field 4),WriteRequest 中包含了 MetricMetadata(field 3)。1.0 规范将这些标注为「实验性的,不在规范范围内」,并明确说明:「Prometheus 目前有对发送 metadata 和 exemplars 的实验性支持。」[1]
Remote Write 2.0 正式规范化了这些数据类型。它引入了新的 protobuf 消息 io.prometheus.write.v2.Request,同时加入了 string interning(字符串驻留)——这是性能层面最重要的改进。

2.0 的主要变化
String interning(字符串驻留):每个唯一字符串只存储一次,放在 symbols 数组中,后续引用使用整数索引。根据 KubeCon NA 2024 上展示的基准测试[2],这一优化带来了显著的效果:传输数据量减少 60%,内存分配减少 90%,CPU 使用减少 70%。
数据类型的正式定义:Exemplars 和 metadata 虽然在 1.0 的 proto 实现中已经存在,但接收方没有统一的标准来保证这些字段的存在和处理方式。2.0 正式定义了完整的数据类型:
- Metadata(类型、帮助文本、单位)——嵌入到每个 TimeSeries 中,不再是单独的数组
- Exemplars——要求必须携带时间戳,以便可靠地去重
- Created timestamp——记录 counter 首次初始化的时间,使
rate()在进程重启后计算更准确 - Native histograms——指数桶直方图类型的正式 wire format 支持
标准化的部分写入处理:精确的响应头报告每种数据类型的写入数量:
X-Prometheus-Remote-Write-Samples-Written: 42
X-Prometheus-Remote-Write-Histograms-Written: 10
X-Prometheus-Remote-Write-Exemplars-Written: 5Native Histograms(原生直方图)
经典 Prometheus 直方图要求预定义桶边界(le 标签值)。边界选择不当会在关键区间丢失精度,而修改边界则会影响现有的仪表盘和告警规则。
Native histograms 采用了不同的方案:桶边界按指数增长,由 schema 参数控制分辨率。用户只需选择精度等级,边界会自动计算。一个 series 替代原来的 N 个桶 series,同时支持乱序写入——这对 OpenTelemetry 数据和网络中断后的补数据场景非常有用。
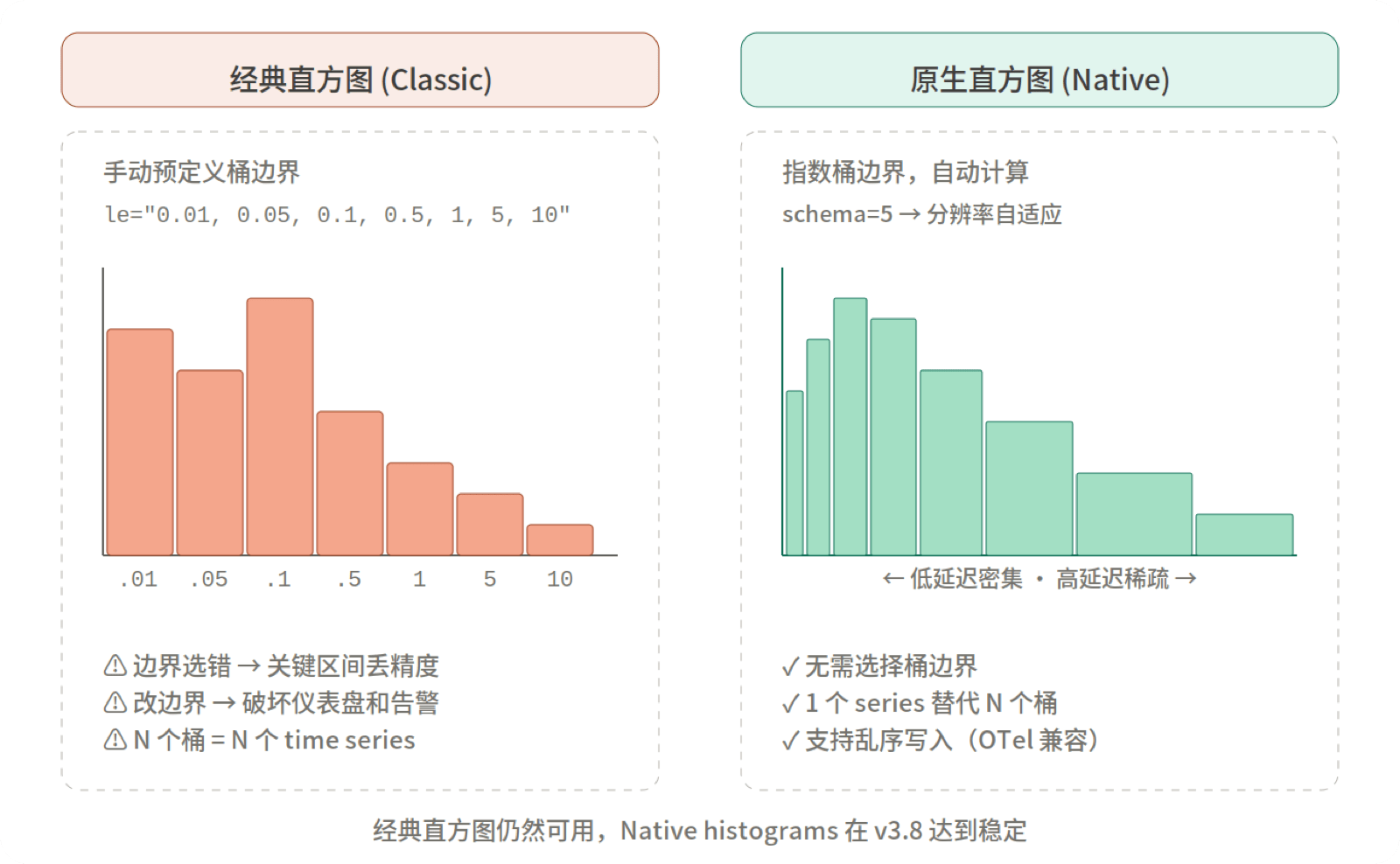
Native histograms 在 Prometheus v3.8(2025 年 11 月)达到稳定状态[3],但采集仍需显式开启:
yaml
scrape_configs:
- job_name: my-app
scrape_native_histograms: true从 v3.9 开始,旧的 --enable-feature=native-histograms flag 已无效。
注意:Native histograms 的文本暴露格式和部分访问函数仍在设计中。经典直方图不受影响,继续正常使用。
此外,3.0 将 holt_winters() 函数重命名为 double_exponential_smoothing(),并移到 experimental-promql-functions feature flag 后面。
原生 OTLP 接收
Prometheus 3.0 可以直接接收 OTLP 指标数据,不再需要 OpenTelemetry Collector 作为中间层。
bash
prometheus --web.enable-otlp-receiver这会暴露 /api/v1/otlp/v1/metrics 端点。OTel SDK 可以直接发送数据:
bash
export OTEL_EXPORTER_OTLP_PROTOCOL=http/protobuf
export OTEL_EXPORTER_OTLP_METRICS_ENDPOINT=http://localhost:9090/api/v1/otlp/v1/metrics
export OTEL_TRACES_EXPORTER=none
export OTEL_LOGS_EXPORTER=noneOTLP 指标名到 Prometheus 的映射方式由 translation strategy 控制,共有四种选择:
| 策略 | 行为 | 适用场景 |
|---|---|---|
UnderscoreEscapingWithSuffixes | dot → 下划线 + 类型/单位后缀 | 默认;现有 Prometheus 技术栈 |
UnderscoreEscapingWithoutSuffixes | dot → 下划线,不加后缀 | 较少使用;存在命名冲突风险 |
NoUTF8EscapingWithSuffixes | 保留 dot + 添加后缀 | 新建的支持 UTF-8 的技术栈 |
NoTranslation | 不做任何转换 | 完全保留 OTel 原始命名 |
yaml
otlp:
translation_strategy: NoUTF8EscapingWithSuffixes
promote_resource_attributes:
- service.instance.idPromQL 行为变化
Range selector 变为左开右闭
Range selector 从左闭右闭变为左开右闭:
Prometheus 2.x:metric[5m] 在时间 T → 包含 [T-5m, T] 内的样本
样本均匀间隔时,如果边界恰好对齐,可能返回 6 个样本
Prometheus 3.x:metric[5m] 在时间 T → 包含 (T-5m, T] 内的样本
均匀间隔时始终返回 5 个样本这一变化主要影响 subquery,因为 subquery 的求值时间戳天然与分辨率的倍数对齐。
正则 . 的匹配行为
. 现在匹配所有字符,包括 \n。如果需要保留旧行为,使用 [^\n]:
promql
my_metric{label=~"foo[^\n]*"}性能提升
在基准测试节点(8 CPU、49 GB 内存)上,使用 prombench 基准[4]运行相同的查询和配置,Prometheus 3.0 相比 2.0 及中间版本在内存和 CPU 使用上都有明显下降。
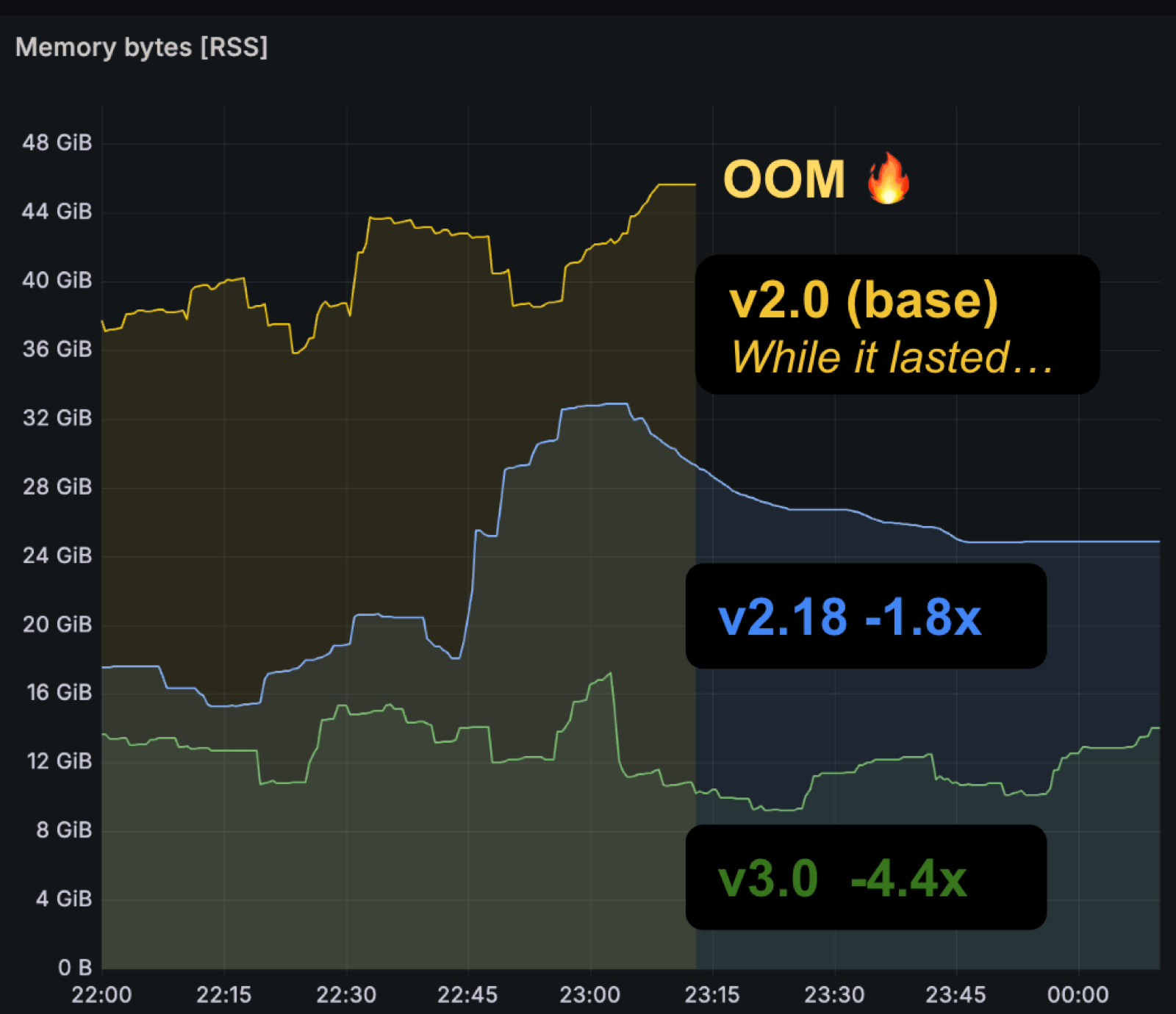
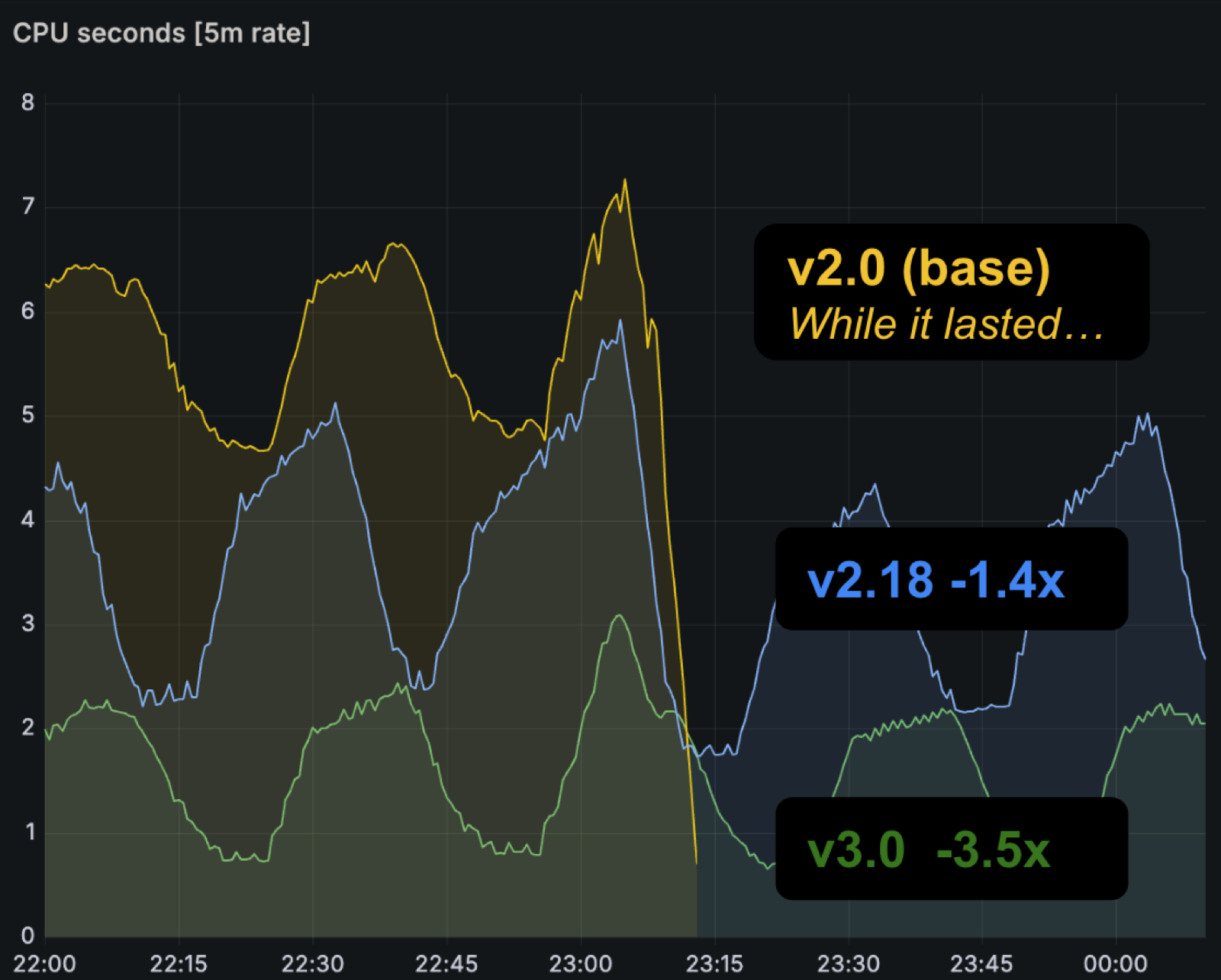
其他优化包括:GOMAXPROCS 和 GOMEMLIMIT 自动匹配容器资源限制(可通过 --no-auto-gomaxprocs / --no-auto-gomemlimit 禁用),以及新版 Service Discovery manager 在配置 reload 时跳过未变化的服务发现配置。
迁移注意事项
Breaking changes 数量不多,但需要注意。
升级路径:先升级到 v2.55 并验证正常运行,再升级到 v3.0。从 3.0 只能回退到 v2.55——TSDB 索引格式在 v2.55 做了变更。
主要变化:
- 7 个 feature flag 被移除,变为默认行为:
utf8-name、native-histograms、agent、remote-write-receiver、promql-at-modifier、promql-negative-offset、new-service-discovery-manager - scrape target 的 Content-Type 无效或缺失时直接失败;需要时配置
fallback_scrape_protocol - 不再自动为 scrape target 添加或移除端口号
- 日志格式切换到 Go 的
log/slog - 要求 Alertmanager v0.16.0+(v1 API 已移除)
- Kubernetes SD 移除了
v1beta1版本的 EndpointSlice 和 Ingress
完整详情参见迁移指南。
GreptimeDB 与 Prometheus 3.0
GreptimeDB 是一个开源的可观测性数据库 (Observability Database),可以作为 Prometheus 的 drop-in 后端——通过 Remote Write 接收数据,通过 Prometheus HTTP API 提供 PromQL 查询,充当长期存储方案。Prometheus 3.0 改变了查询语义和协议行为后,GreptimeDB 进行了系统性的适配。
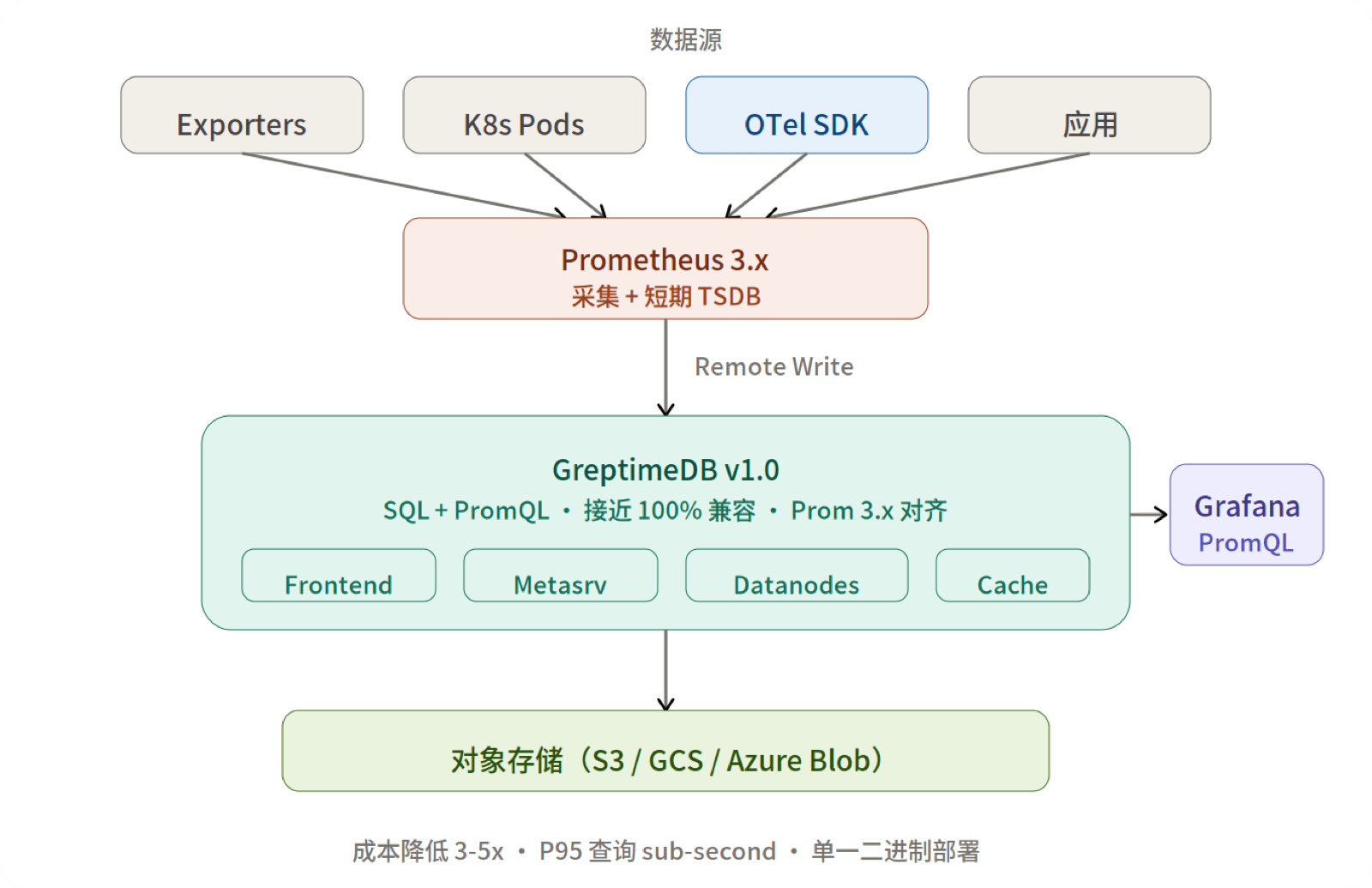
PromQL 兼容性
GreptimeDB 使用 Rust 原生实现了 PromQL——自研了 parser(promql-parser,复用 Prometheus 的 YACC 语法定义)和基于 Apache DataFusion 的执行引擎,而非包装 Go 代码。
在 PromCon EU 2025 上,GreptimeDB 工程师 Ruihang Xia 分享了一项成果[5]:在 PromLabs 兼容性测试套件中,GreptimeDB 在所有非 Prometheus 实现中得分最高——甚至超过了直接引用 Prometheus Go 模块的实现。公开的 tracking issue[6] 记录了兼容率的完整提升过程:从 2023 年 2 月的 13%,到演讲时的 82% 以上。此后 GreptimeDB 持续补齐剩余差异,目前在官方 PromQL 兼容性测试套件上的通过率已接近 100%。
针对 Prometheus 3.0 的行为变化,GreptimeDB 在 v1.0.0-rc.2 中发布了以下适配[7]:
- 左开 range selector(PR #7671)——对齐 3.x 的 matrix selector 语义
- 起始排他的 instant selector(PR #7688)——修正 lookback 对结束边界的处理
- 函数重命名(PR #7700)——
holt_winters→double_exponential_smoothing - Parser 升级——
promql-parserv0.7.0 加入 Prometheus 3 支持(string identifier 和 Unicode 标签名)[8];v0.7.1 在 README 中声明兼容 Prometheus v3.8[9]
Remote Write 协议支持
GreptimeDB 支持 Prometheus Remote Write 1.0 协议,包括 prometheus.WriteRequest proto 中的 sample、metadata 和 histogram 字段。Exemplar 的写入尚未支持,目前在 roadmap 中。
yaml
remote_write:
- url: http://<greptimedb-host>:4000/v1/prometheus/write
remote_read:
- url: http://<greptimedb-host>:4000/v1/prometheus/readRemote Write 2.0(新的 io.prometheus.write.v2.Request 消息和 string interning)正在跟踪中(GitHub Issue #4765[10]),目标是在支持 2.0 的同时保持 1.0 完全可用。
GreptimeDB 还优化了 Remote Write 的解码性能(PR #7737、#7761),并支持三种 UTF-8 验证模式[11]:strict(默认,拒绝非法 UTF-8)、lossy(替换为 U+FFFD)、unchecked(不验证,追求最大吞吐)。
为什么在 Prometheus 后面使用 GreptimeDB?
Prometheus 的 TSDB 定位于短期数据保留,默认只保存 15 天。当需要更长的数据保留周期——用于异常检测模型训练、合规存档或长期趋势分析——就需要外部存储方案。
Thanos 和 Cortex 是常见的选择,但运维开销较高:Sidecar、StoreGateway、Compactor 等多个组件需要分别部署和监控。
GreptimeDB 采用了不同的方案:
- 单一二进制、一条 Helm 命令即可部署
- 对象存储为主存储(S3、GCS 或 Azure Blob),成本比块存储低 3–5 倍
- 同一份数据上使用 SQL + PromQL——PromQL 驱动仪表盘和告警,SQL 用于即席分析和 JOIN
- 接近 100% 的 PromQL 兼容——切换端点后,现有 Grafana 仪表盘无需修改即可使用
- 统一可观测性——同一个数据库通过 OTLP 和 Loki 协议接收指标、日志和链路追踪数据
典型部署方式:
bash
helm repo add greptime https://greptimeteam.github.io/helm-charts
helm upgrade --install prom-lts greptime/greptimedb-cluster \
--set 'meta.backendStorage.etcd.endpoints[0]=etcd.etcd-cluster.svc.cluster.local:2379' \
--set objectStorage.s3.bucket="prom-data" \
--set objectStorage.s3.region="us-west-2" \
--set objectStorage.s3.root="prom-lts" \
--set objectStorage.credentials.accessKeyId="<your-access-key-id>" \
--set objectStorage.credentials.secretAccessKey="<your-secret-access-key>" \
-n observabilityyaml
remote_write:
- url: http://prom-lts-frontend:4000/v1/prometheus/write
remote_read:
- url: http://prom-lts-frontend:4000/v1/prometheus/read无需修改代码,无需学习新的查询语言。
Prometheus 的后续发展方向
3.0 之后,社区的主要方向包括:
- Native histogram 自定义桶和持续稳定化
- Delta temporality——counter 只发送变化量而非累计值
- OpenMetrics 2.0——已纳入 Prometheus 治理
- Start timestamp 存储——v3.11+ 开始实验性支持
- 更多语言的 UTF-8 SDK 支持
截至 2026 年 5 月,Prometheus 最新版本为 v3.12,LTS 版本为 v3.5.x(支持到 2026 年 7 月)。
下一步行动
- 阅读迁移指南——特别注意 TSDB 格式变化和必须先升级到 v2.55 的要求
- 检查 PromQL 查询——确认是否有使用
.正则并依赖旧的「不匹配换行符」行为的地方 - 如果正在使用 GreptimeDB 作为 Prometheus 后端——升级到 v1.0+ 以获得 Prometheus 3.x selector 行为的对齐
参考链接
Prometheus Remote Write 1.0 规范——"Prometheus currently has experimental support for sending metadata and exemplars" ↩︎
KubeCon NA 2024 Remote Write 2.0 深入分析——消息量减少 60%,内存分配减少 90%,CPU 使用减少 70% ↩︎
Prometheus Native Histograms 文档——"Starting with v3.8.0, native histograms are supported as a stable feature" ↩︎
Prometheus 3.0 发布公告——性能基准测试 ↩︎
promql-parser README——"compatible with prometheus v3.8" ↩︎
GreptimeDB 配置参考——UTF-8 验证模式 ↩︎

