
本页内容
我们的工程师夏锐航在 PromCon EU 2025 分享了如何在以 Go 为主导的 Prometheus 生态中引入 Rust,以及 GreptimeDB 如何取得除 Prometheus 本身之外最高的 PromQL 兼容性得分。
打开 PromQL 兼容性测试页面,清一色的 Gopher 图标似乎在宣告一个事实:想深度参与 Prometheus 生态,Go 是唯一的选择。
但在 PromCon EU 2025 的第二天,我们的工程师夏锐航 (Ruihang Xia) 带来了一个不同的故事——用 Rust 重新实现 Prometheus 的核心组件,并取得了除 Prometheus 本身之外最高的 PromQL 兼容性得分。
本文基于他的演讲 "Engage Prometheus in the Rust Ecosystem" 整理。
开场:一些必要的"内容警告"
"我不是那种叫嚷着要用 Rust 重写一切的人。"Ruihang 在演讲开始时这样说。
作为 Apache DataFusion PMC 成员和 Apache Arrow Committer,他的日常工作确实在 Rust 生态中,但这次演讲的目的不是挑起语言之争。他坦诚地给出了几个"内容警告":这是在 Go 主导的项目中谈论 Rust;有些对比涉及自家代码,可能存在偏见;以及——"broken English, not very fluent。"
这种坦诚为整场演讲定下了基调:技术讨论,而非语言战争。
WHY:为什么要把 Prometheus 带入 Rust
Go 主导的现实
打开 PromLabs 的 PromQL 兼容性测试页面[1],你会看到一个有趣的画面:所有被测试的项目旁边都是 Go 的吉祥物 Gopher。从 Amazon Managed Service for Prometheus 到 VictoriaMetrics,从 Cortex 到 Thanos,无一例外。
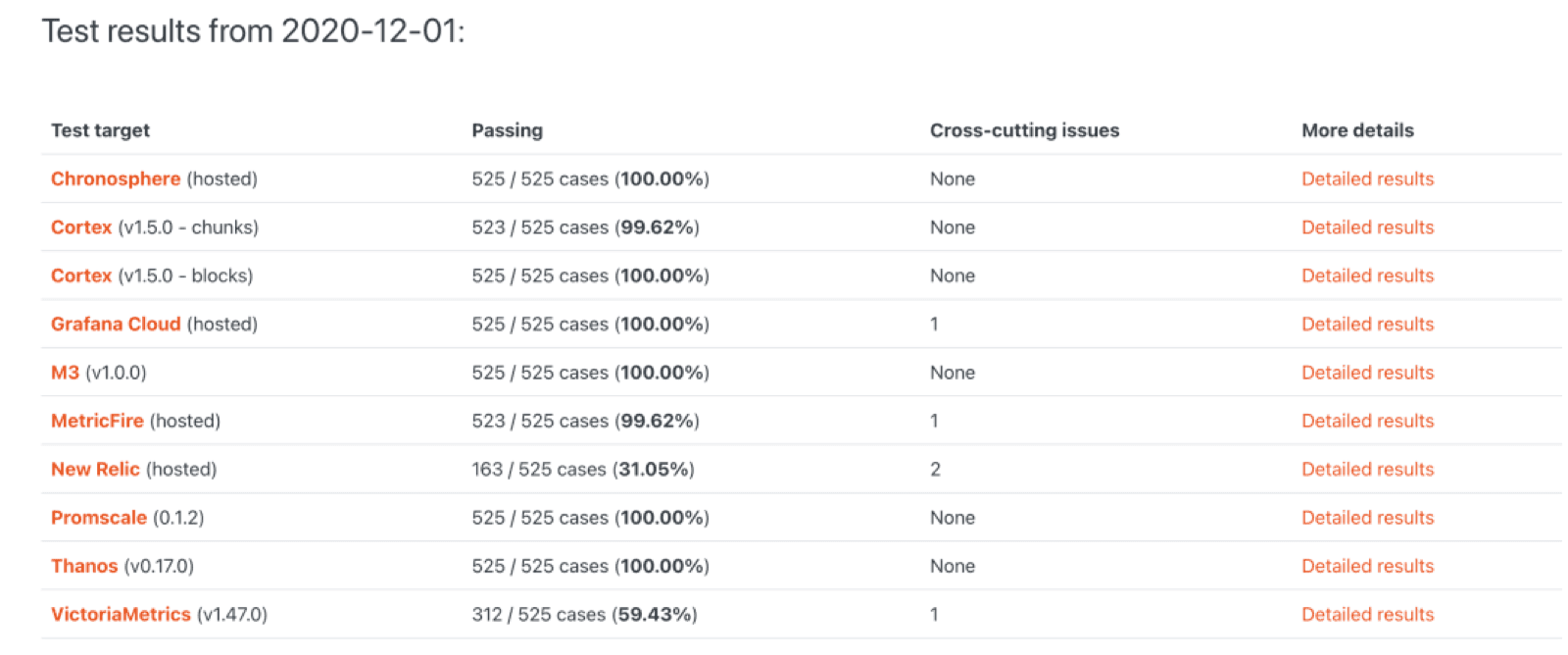
这不是偶然。Prometheus 生态形成了一个强大且经过实战检验的技术栈:Prometheus 本身、Cortex/Mimir、Thanos、M3DB,以及各云厂商的托管服务。创新通常发生在 Go 生态内部——通过 import Prometheus 的内部模块,你可以快速构建新功能。
"如果你参与 Prometheus 生态,基本上只能做 metrics exporter——只能用 SDK 向 Prometheus 上报数据,无法真正利用你的系统来处理这些数据。"Ruihang 指出。
CGO 的痛苦经历
Ruihang 分享了一段亲身经历:他曾花费近一年时间,尝试通过 CGO 将一个 Rust 编写的键值存储引擎集成到某个 Golang 项目中。
"那是我做过的最差的技术决策之一。" Ruihang 坦言。实际上,大约 70% 的时间不是花在项目本身,而是在 Go 和 Rust 之间的 CGO 协调上。
CGO 确实允许你将 Rust 或 C++ 代码集成到 Go 项目中,但实践中的摩擦成本远超预期。这段经历促使他思考:与其在 Go 生态中艰难地引入 Rust,不如直接在 Rust 中重建 Prometheus 的核心能力。
Rust 生态的独特优势
选择 Rust 不仅是语言偏好,更是为了获取 Go 生态无法轻易触及的能力。
前沿数据格式的支持差异
演讲中展示了一张对比表,列出了近年涌现的创新数据格式:
| 格式 | 描述 | 源语言 | Go SDK |
|---|---|---|---|
| BtrBlocks | 轻量级编码/压缩 (SIGMOD'23) | C++ | ❌ |
| FastLanes | SIMD 友好的新格式 (VLDB'25) | C++ | ❌ |
| Lance | 面向 ML/AI 的列式格式 | Rust | ❌ |
| Nimble (Meta) | 宽表/特征存储优化 | C++ | ❌ |
| Vortex | 压缩 Arrow 数组,LF AI 孵化 | Rust | ❌ |
"这张表不是我刻意找来证明什么的。实际上,这是客户发给我们的一份清单,问我们是否支持这些格式。我调研后发现,除了古老的 Apache ORC,其他创新格式都没有官方 Go SDK。"
这并不意外。更多底层创新发生在 Rust 和 C++ 生态中,尤其是数据基础设施领域。
跨语言绑定的核裂变效应
Rust 代码可以相对容易地生成其他语言的绑定。Ruihang 举了两个例子:
promql-parser:我们开发的 Rust PromQL 解析器,社区已为它创建了 Python 和 Lua 绑定。
Apache OpenDAL:这个 Rust 编写的云存储访问层,已有 C、C++、Java、Python、Node.js、Go 等 15+ 种语言的绑定。
"想象一下,你可以在 NGINX 的 Lua 脚本中编写插件来拦截 PromQL 查询。如果你完全在 Go 生态中,这种跨语言的可能性要困难得多。"
跳出 Go 生态,就像核裂变一样释放出多语言的能量。理论上 Go 也能通过 CGO 实现类似效果,但实践中很少看到这样的案例。
WHAT:把 Prometheus 视为标准
这段实践经历改变了 Ruihang 对 Prometheus 的认知。
"我不再把 Prometheus 看作一个单体系统,而是更像一个标准。"
Prometheus 定义了三个核心接口:
- OpenMetrics — 数据格式标准
- PromQL — 查询语言标准
- Remote Write — 传输协议标准
这三个接口都有对应的兼容性测试[2]。标准本身不绑定特定语言——只要你的实现符合这些接口规范,就是 Prometheus 生态的一部分。
"如果一个东西听起来像 Prometheus,看起来像 Prometheus,用起来也像 Prometheus,那它就是 Prometheus。"
这种视角转变意义重大:你可以用任何语言、任何技术栈来实现 Prometheus 兼容的系统,而不必局限于 Go 生态。
HOW:两种截然不同的实现策略
演讲分享了两个案例,代表两种完全不同的实现策略。
案例一:promql-parser — 忠实跟随
promql-parser[3] 是我们开源的纯 Rust PromQL 解析器,策略是尽可能忠实地跟随 Prometheus 的原生实现。
技术实现
大约五年前,Prometheus 从手写的解析器迁移到了基于 YACC 的生成式解析器。这为跨语言复用创造了条件:YACC 语法定义是语言无关的。
promql-parser 复用了 Prometheus 的 YACC 语法定义,只做了必要的移植工作(Prometheus 使用 GoYACC,与标准 YACC 略有差异)。核心输出是两部分:
- AST(抽象语法树)定义 — 描述 PromQL 查询的结构
- 生成的解析逻辑 — 将查询字符串转换为 AST
rust
use promql_parser::parser;
let promql = r#"
http_requests_total{
environment=~"staging|testing|development",
method!="GET"
} offset 5m
"#;
match parser::parse(promql) {
Ok(expr) => {
println!("Prettify:\n{}\n", expr.prettify());
println!("AST:\n{expr:?}");
}
Err(info) => println!("Err: {info:?}"),
}依赖选择的考量
Rust 社区的依赖库与 Go 并非一一对应。团队花了大约一半的时间来谨慎选择依赖,确保最大程度的兼容性。
应用场景
- PromQL 查询分析
- 查询拦截和改写
- 结构化告警规则处理
- 在 Lua 脚本中解析 PromQL(通过 lua-promql-parser 绑定)
项目现状
- GitHub: https://github.com/GreptimeTeam/promql-parser
- crates.io 下载量:300,000+
- 已被 GreptimeDB、OpenObserve 等项目使用
演讲时 promql-parser 兼容 Prometheus v2.45.0。演讲结束后不久,我们发布了 v0.7 版本,新增对 Prometheus 3 的支持——包括 string identifier、Unicode 标签名等新语法特性[4]。通过复用 YACC 语法定义,我们可以相对容易地跟进上游更新。
案例二:PromQL 执行引擎 — 完全重构
GreptimeDB 中的 PromQL 执行引擎走了一条完全不同的路:彻底解构 PromQL,用数据湖的方式重新实现。
核心洞察:"监控数据是垃圾数据"
"监控数据是垃圾数据。"Ruihang 直言。
这不是贬义。它意味着单条监控数据的价值很低——你关心的不是某一个时刻的 CPU 使用率,而是它的变化趋势、异常检测、聚合统计。只有大量存储和处理这些数据,才能产生价值。
这正是数据湖擅长的事情。
Data Lake + Prometheus
GreptimeDB 将 PromQL 的语义完全映射到 SQL 模型:
| PromQL 概念 | SQL/数据湖映射 |
|---|---|
| Binary Operator | JOIN |
| Range Vector | 数组切片(Array of Array) |
| Filter | WHERE 条件 |
| Aggregation | GROUP BY + 聚合函数 |
这种映射允许复用成熟的 SQL 执行引擎能力。更重要的是,这种方法具有通用性——"如果你想用 DuckDB 来实现你自己版本的 PromQL,你也可以。至少对我来说,我有信心在一个月内完成。"
技术栈:全 Apache 项目
GreptimeDB 选择的技术栈:
- Apache Parquet — 列式文件格式,同时也作为索引格式
- Apache DataFusion — 查询执行引擎,PromQL 到 SQL 的重映射直接复用其能力
- Apache Arrow — 内存数据格式,不仅用于计算层,还用于协议层和内存缓存层
- Apache OpenDAL — 云存储访问层,支持多种存储服务
"我们没有根据项目名称选择依赖,但它们恰好都带着 Apache。"Ruihang 开玩笑说。
达成的目标
- Drop-in replacement:只需更改查询端点即可从 Prometheus 切换
- 最高 PromQL 兼容性:在 PromQL Compliance Test 中取得最高分(除 Prometheus 本身),甚至高于那些依赖 Prometheus 本身的项目
- 内置分布式支持:无需额外组件即可水平扩展
从 SQL 世界吸收的能力
重新实现带来了意想不到的收获——可以直接使用 SQL 生态中成熟的技术:
- Query Optimizer:自动重写低效查询,或直接拒绝可能拖垮系统的查询
- EXPLAIN ANALYZE:可视化查询执行计划,精确到每个步骤的耗时
- 分布式执行:开箱即用的分布式查询支持

SQL + PromQL 混合查询
一个独特的能力是可以在同一个查询中混合使用 SQL 和 PromQL:
sql
WITH
tql_data (ts, val) AS (TQL EVAL (0, 40, '10s') metric),
filtered AS (SELECT * FROM tql_data WHERE val > 5)
SELECT count(*) FROM filtered;TelemetryQL(TQL)是 GreptimeDB 对 PromQL 的封装命名。
这利用了 SQL 的 CTE(Common Table Expression)特性。第一部分是 PromQL 查询,然后用 SQL 过滤,再用 SQL 做聚合。两种查询语言各有所长,现在你可以按需选择。
这是怎么实现的?我们将所有查询逻辑统一转换到一个中心化的中间表示(IR,即逻辑计划)。在这个层面上,你无法区分某个步骤来自 SQL 还是 PromQL——它们完全混合在一起,可以无缝协作。
想了解 TQL + CTE 在 Kubernetes 监控中的实际应用?请参阅当 PromQL 遇上 SQL:用混合查询解锁 Kubernetes 监控分析。
丰富的索引支持
除了演讲中提到的核心能力,GreptimeDB 还提供了丰富的索引支持来加速查询:
| 索引类型 | 用途 | 底层实现 |
|---|---|---|
| Inverted Index | 时序查找 | 自研 |
| Skipping Index | 大规模时序过滤 | 自研 |
| Fulltext Index | 关键字搜索 | 自研/tantivy |
| Vector Index | 相似性查询 | 正在实现 |
可扩展的语义
完全重新实现也意味着可以扩展 PromQL 的语义:
- Optional extrapolate:控制是否启用外推计算
- Strict mode:查询不存在的 metric 时报错(而非返回空结果,这更像 SQL 的行为)
- Rich types:支持 Duration、Interval、DateTime 等丰富类型
- Multi-values:将 load1、load5、load15 等相关指标物理上存储在一起
关于 rich types,Ruihang 举了一个有趣的例子:"你有没有想过查询浮点数以外的东西?比如 Duration?Interval?DateTime?我家里的 Home Assistant 有一个毫米波雷达,它会报告是否有人类活动——这个数据用 interval 类型表示。"
抓住根本:协议、数据、计算
Ruihang 总结了这种重新实现方法的核心思路:抓住三个根本要素。
- 协议(Protocol) — 兼容 Prometheus 的接口标准
- 数据(Data) — 用数据湖的方式存储和组织
- 计算(Computation) — 复用 SQL 执行引擎的能力
只要抓住这三个根本,具体的实现方式可以完全不同。这也是为什么"看起来像 Prometheus、用起来像 Prometheus"的系统,可以用完全不同的技术栈来构建。
PromQL 兼容性之路
GreptimeDB 的 PromQL 兼容性不是一蹴而就的。GitHub 上的 tracking issue[5] 记录了完整的演进历程:
| 时间 | 兼容率 | 里程碑 |
|---|---|---|
| 2023-02 | 13.14% | 初始支持 |
| 2023-02 | 33.03% | 支持 aggr_over_time 函数 |
| 2023-04 | 54.38% | 修复 offset 等边界情况 |
| 2023-06 | 66.61% | 支持 predict_linear |
| 2023-12 | 82.12% | 支持 histogram_quantile |
从最初的 13% 到超过 82%,这是两年持续投入的结果。目前 GreptimeDB 已取得除 Prometheus 本身之外的最高分,我们仍在持续提升兼容性。
结语
"用 Rust,用多种语言,用最适合的技术栈。"Ruihang 在演讲结尾说道。
Prometheus 作为标准的开放性,意味着更多的可能性:
- 新的工具箱被打开:Rust 生态的前沿数据基础设施现在可以服务于 Prometheus 用户
- 跨语言协作成为可能:从 Rust 出发,可以绑定到几乎任何语言
- 用数据湖的方式扩展时序:吸收 SQL 世界几十年的工程智慧
这不是要取代 Go 生态的 Prometheus 项目,而是为 Prometheus 标准提供更多元的实现选择。
Q&A
演讲结束后,主持人感慨道:"我一直在等着有人某天醒来说,让我们用 Rust 重写 Prometheus 吧。很高兴这正在发生,真的很令人兴奋。"
有听众问道:"我们在哪里可以跟进你们的工作?"
"对于 parser,我们有一个专门的仓库,你也可以尝试为其他语言添加绑定。对于查询引擎,它是 GreptimeDB 仓库中的一个独立模块,虽然没有单独的仓库,但代码本身是分离的。"
本文基于夏锐航在 PromCon EU 2025(Munich)的演讲 "Engage Prometheus in the Rust Ecosystem" 整理。夏锐航是 GreptimeDB 高级软件工程师,Apache DataFusion PMC 成员。

