
本页内容
今天,GreptimeDB v1.0 GA 正式发布。
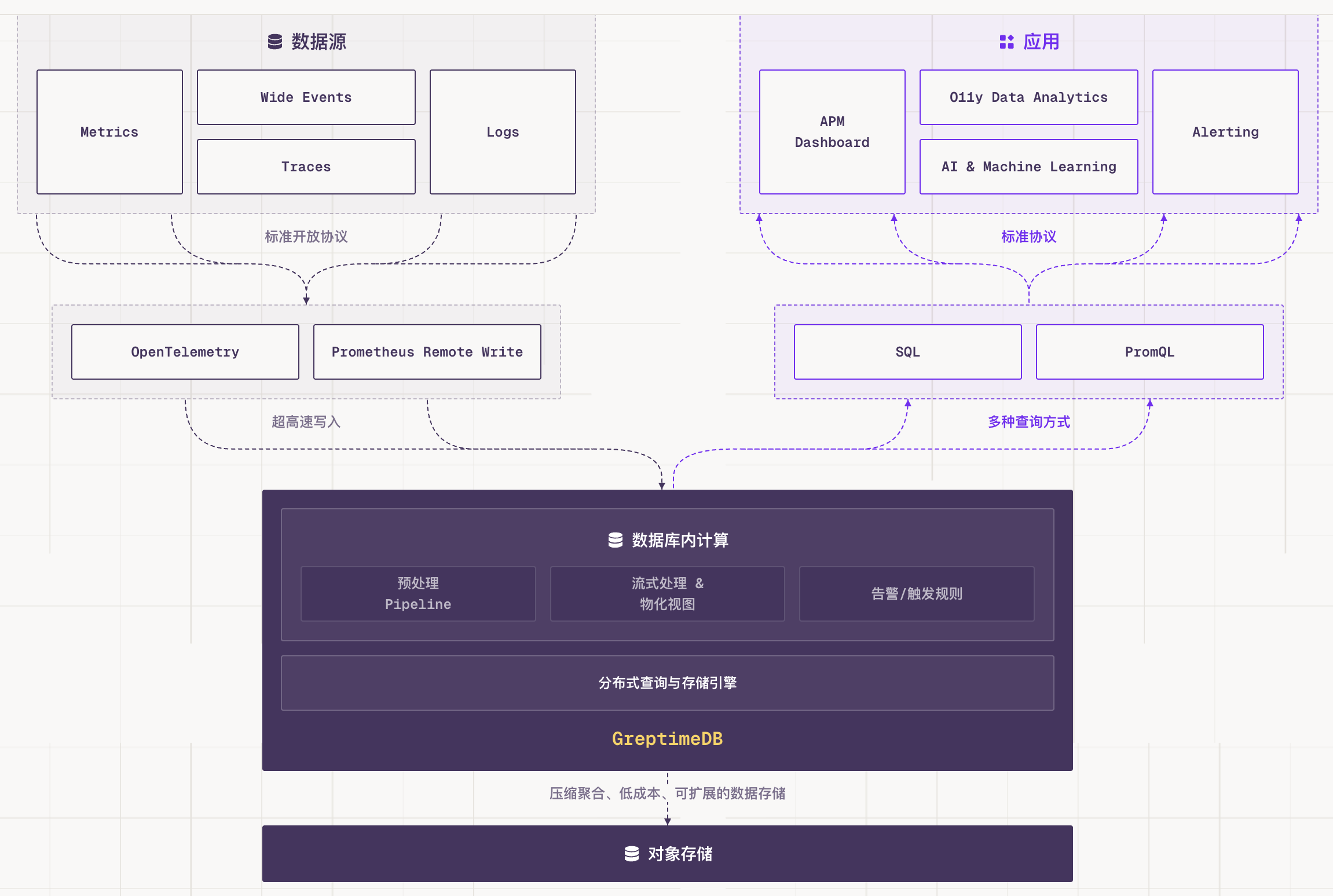
GreptimeDB 是一个开源的云原生可观测性数据库,用同一套引擎处理 metrics、logs 和 traces。它基于对象存储构建,支持 SQL 和 PromQL 查询,可以替代 Prometheus + Loki + Elasticsearch 的组合。
从去年 11 月的 Beta1 到今天的 GA,中间经历了 Beta2、RC1 和 RC2。过去几个月我们一直在做同一件事:把一个方向明确但还在快速推进的系统,收敛成一个更稳的版本。
v1.0 更像一个分界点。从这个版本开始,我们得按一个长期维护的基础软件项目来要求自己。
GreptimeDB 这几年一直在坚持几件事:
- 统一处理 metrics、logs 和 traces
- 尽量接入现有生态,而不是要求用户重写整条链路
- 不把"功能多"当成目标,把可维护和可持续演进放在前面
到了 v1.0,这些判断已经经过几个版本的推进和真实场景的检验。
从 Beta 到 GA
回头看这条发布线,Beta 把能力铺开,RC 开始收口。
Beta 里我们放出了 BulkMemtable、全局索引重建、Region 批量迁移这些能力。到了 RC,重点逐渐变成了性能打磨、稳定性验证、兼容性修复,以及那些平时不显眼但确实影响生产体验的细节。
GA 是这两条线汇合的节点。前面放出来的能力,加上后面补的稳定性和兼容性,到这个版本拼成了一个更完整的形态。
v1.0 的主要变化
Flat 现在是默认 SST 格式
v1.0 里最重要的变化之一,是 Flat 成了默认 SST 格式。
这个变化针对的是高基数(high-cardinality)场景。原来的 primary_key 格式把所有 tag 列编码成一个二进制列,memtable 为每条时间线分配独立的 buffer。时间线到百万级别之后,内存开销和查询效率都会恶化得很明显。Flat 格式把 tag 列拆回独立的 Parquet 列存储,配合新的 BulkMemtable 取消了按时间线分配 buffer 的设计。TSBS 基准测试里,200 万时间线场景下写入吞吐提升约 4 倍,部分查询延迟降低最多 10 倍。详细的设计和性能数据可以看这篇文章。
从 v1.0 开始,flush、compaction 和 scan 都统一走 Flat 路径,Flat scan path 支持同时读取 flat 和 primary_key 两种格式的数据。
对已有用户来说,这个变化是可控的:
- 已有的
primary_key格式表可以继续正常工作 - 新建表默认采用 Flat
- 如果有需要,可以显式切回
primary_key
sql
ALTER TABLE my_table SET 'sst_format' = 'primary_key';通过 HTTP 写入时也可以用 header 指定格式:
x-greptime-hints: sst_format=primary_key写入链路继续往前走
写入链路是 v1.0 里另一条主线。
Metrics 场景里,Metric Engine 支持了批量写入,做了 pending rows batching,并且实现了 Prometheus schemas 的自动对齐。Prometheus remote write 的写入吞吐有提升,更完整的测试报告会在后续单独发布。
OTLP 场景里解决了两个生产环境中常见的问题:trace ingestion 支持了 partial success,部分错误不再影响整批写入;trace 写入过程中遇到 int 到 float 的类型不匹配时,可以自动做 schema 适配,不用手动处理。
查询侧也补了一轮
PromQL range functions 的执行路径做了重写,聚合查询的 group accumulators 支持了 state wrapper,带 LIMIT 的窗口查询去掉了不必要的排序。改动不大,但实际查询的响应时间会有体感。
内置 Dashboard
这个版本加入了内置 Perses Dashboard 支持,Dashboard 更新到 v0.12.0。
数据接进来之后,可以直接在 GreptimeDB 里查询和展示,不用额外搭一套可视化工具。最新版本的 GreptimeDB MCP Server 也加入了创建 Perses Dashboard 的能力,可以通过 LLM 对话直接创建仪表盘。
PostgreSQL 兼容性
v1.0 里还有一类不起眼的改动:PostgreSQL 协议兼容性修复。扩展查询优化、ParameterDescription size limit、8-bit int 到 smallint 的映射,以及 PostgreSQL 格式相关的同步清理问题都做了修复。
v1.0 GA 对用户意味着什么
v1.0 GA 不等于所有事情都做完了,架构也还会继续演进。
但核心方向经过了从 Beta 到 GA 的连续验证,关键能力已经走到可以长期维护的阶段。用户可以用更稳定的预期来评估和接入 GreptimeDB。
升级和兼容性
对大多数用户来说,升级到 v1.0 的路径是平稳的。需要关注 release note 里的两项 breaking changes。
1. 新建表默认采用 Flat SST 格式
从 v1.0 开始,新建表默认使用 Flat SST 格式:
- 旧的
primary_key格式不会失效,已有表继续正常工作 - 如有必要,可以显式指定或切回旧格式
- 配置文件里的
region_engine.mito.default_experimental_flat_format需要改成region_engine.mito.default_flat_format - 之前显式配置过
region_engine.mito.parallel_scan_channel_size的,升级后需要移除
2. Arrow IPC HTTP 输出格式从 file 改为 stream
HTTP Arrow IPC 输出从 file 格式调整成了 stream 格式。这主要影响直接消费 GreptimeDB Arrow HTTP 输出的自定义客户端或集成逻辑,升级前需要确认读取端支持 Arrow IPC stream 格式。
后面还会做什么
按照公开的 2026 Roadmap,v1.0 GA 之后的方向已经比较明确:
- v1.1(Q2):Remote Compaction/Indexing 达到生产可用,Metric Engine 优化,Import/Export Tool v2
- v1.2(Q3):Adaptive Resource Management 第一阶段(细粒度内存跟踪、cost-based 自适应调度、zero-tuning 自适应 spilling),Auto Rollup,Flow Engine 增强
- v1.3(Q4):Adaptive Resource Management 第二阶段,Pandas DataFrame SQL 查询,Log 上下文搜索,开放表格式兼容(Iceberg/DeltaLake)
Adaptive Resource Management 是今年最大的工程投入,分两个阶段交付。详细内容见 Roadmap tracking issue。
开发数据
从 Beta1 到 GA,共合入 474 个 PR,27 位贡献者参与,其中 8 位是第一次为 GreptimeDB 提交代码。
v1.0.0 这个版本收录了 81 项变更:29 项功能增强、22 项错误修复、7 项代码重构、3 项性能优化、3 项文档更新、2 项测试增强、13 项工程与杂项任务。
v1.0.0 的 4 位首次贡献者:
感谢所有贡献者。

结语
感谢每一个提过 issue、提交过 PR、参与讨论、在真实环境里跑过 GreptimeDB 的人。

