本页内容
不久前,我们公布了 GreptimeDB v1.0 的主要亮点及发布计划。本周,我们发布了 v1.0.0 的第二个 beta 版本——这是迈向 v1.0 GA 的关键一步,也是 GreptimeDB 走向生产就绪的重要里程碑。
开发数据概览
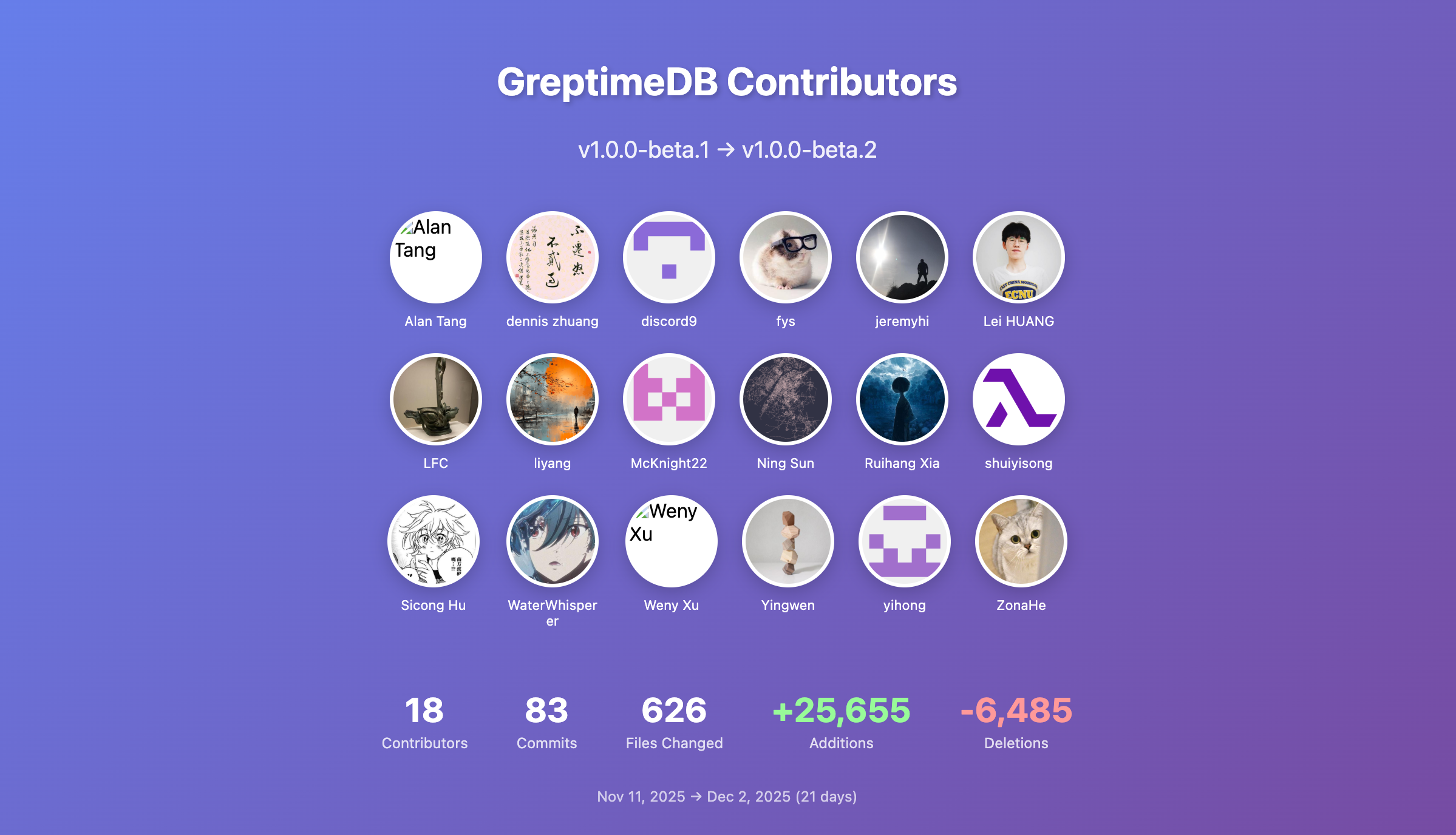
以下是 beta2 的开发统计(2025.11.11 → 2025.12.02,共 21 天):
- 83 个 PR 合并,涉及 626 个文件
- 代码变更:
+25,655 / -6,485 - 18 位贡献者参与,其中 6 位独立贡献者贡献了 9.5% 的提交
- 新晋贡献者:@McKnight22,欢迎加入 GreptimeDB 社区!
主要改进分布:
- 34 项功能增强:批量 Region 迁移、动态启停 Tracing、支持
Dictionary类型、COPY DATABASE并行化等 - 18 项错误修复:写入特定情况下停滞、Metric Engine 变更 schema 潜在死锁、索引缓存修复、PostgreSQL/MySQL 协议兼容等
- 8 项代码重构:移除 export metrics 旧配置、优化
SHOW TABLES性能、统一元数据加载等 - 5 项性能优化:TSID 生成加速、并行化 Region 加载、消除不必要的 Merge Sort 等
👏 特别感谢本次参与的 18 位贡献者,欢迎新成员 @McKnight22!
我们诚邀更多对可观测性数据库感兴趣的开发者加入 GreptimeDB 社区。
亮点更新
Bulk Ingest 支持 Flat Format
在 v1.0.0-beta1 中,我们引入了 Flat Format,显著提升高基数主键场景下的写入与查询性能。但当时 Flat Format 仅支持传统行协议,无法与 Bulk Ingest 配合使用。
beta2 中,Bulk Ingest (SDK) 与 Flat Format 实现了全面对接:
- Bulk Ingest 不支持主键的限制已彻底消除
- Bulk Ingest 的列式批量写入能力可直接用于 Flat Format 表
- 写入性能较旧版 Bulk Ingest 提升 60% 以上
以下是在笔记本电脑 (Apple M2 Pro, 16GB) 上的实测数据:
| 写入方式 | 表类型 | 吞吐量 |
|---|---|---|
| Regular API | 普通表 | 104,237 rows/s |
| Bulk API | 普通表 | 155,099 rows/s |
| Bulk API | Flat Format 表 | 257,136 rows/s |
Bulk API + Flat Format 组合相比 Regular API 实现了约 2.5 倍的性能提升。
批量 Region 迁移
我们优化了 Region 迁移的调度方式:同一目标 Datanode 上的多个 Region 迁移步骤会自动合并为一次批处理请求,不再为每个 Region 单独发起分布式调用。
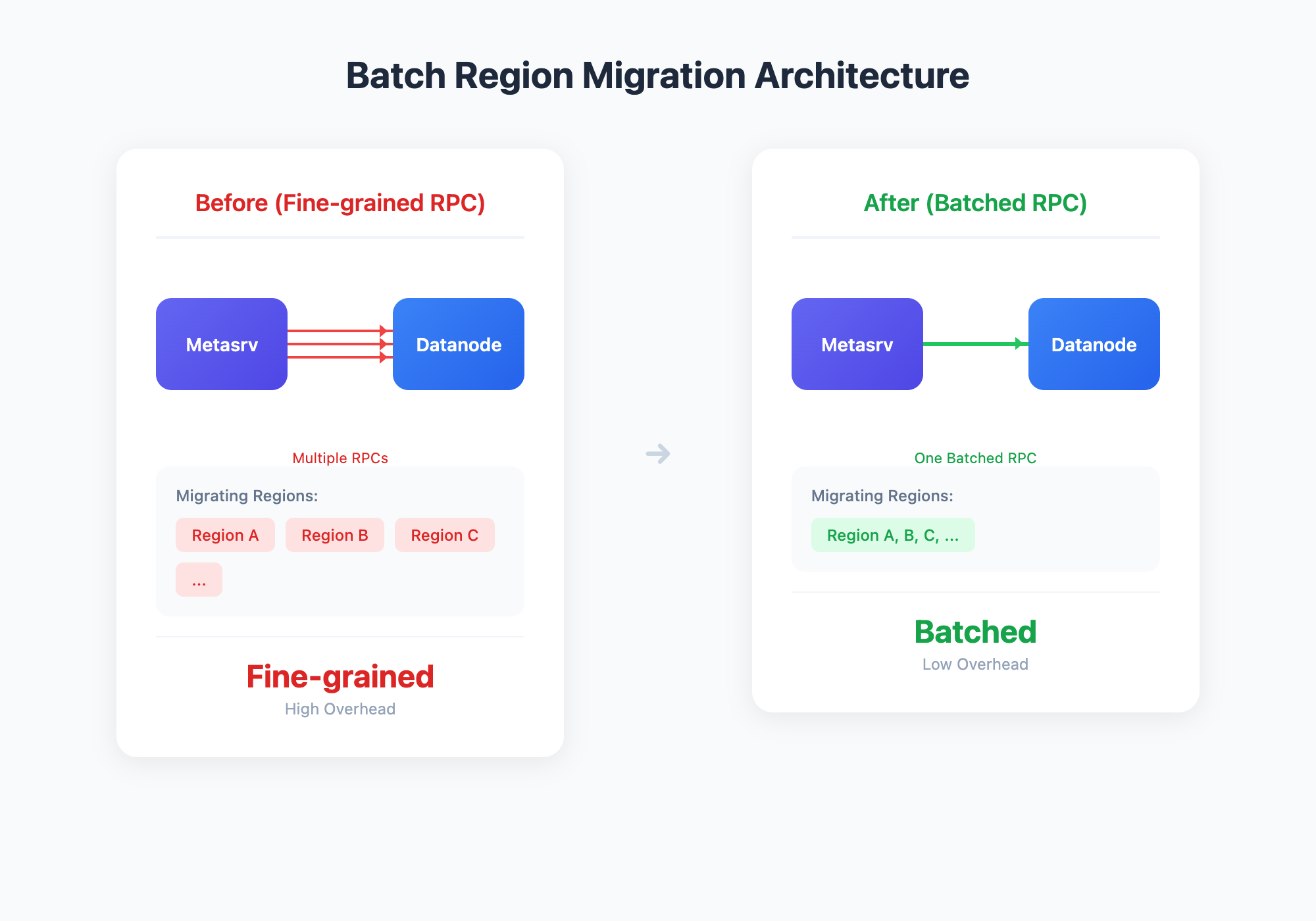
这种批量化迁移带来显著收益:
- 大幅减少 RPC 调用量,降低迁移过程中的网络与调度压力
- 加速扩缩容与故障恢复
- 迁移过程更稳定,避免多 Region 并发迁移导致的 Datanode 抖动
- 对大型集群尤为有效,解决成百上千 Region 迁移时的资源消耗和协调开销
ALTER DATABASE 增强
新增 ALTER DATABASE 选项,支持在线调整压缩参数:
sql
-- 修改压缩时间窗口
ALTER DATABASE db SET 'compaction.twcs.time_window'='2h';
-- 修改压缩最大输出文件大小
ALTER DATABASE db SET 'compaction.twcs.max_output_file_size'='500MB';
-- 修改触发压缩的文件数
ALTER DATABASE db SET 'compaction.twcs.trigger_file_num'='8';
-- 取消压缩选项
ALTER DATABASE db UNSET 'compaction.twcs.time_window';MySQL/PostgreSQL 协议兼容性增强
beta2 大幅提升了数据库协议兼容性,重点改进包括:
- PostgreSQL 时区设置与扩展查询解析
- 数值类型别名与标准对齐
- PreparedStatement 批量插入兼容
感谢积极反馈的用户,你们的帮助让 GreptimeDB 不断改进。
此版本还提升了 GreptimeDB 作为 StarRocks JDBC External Catalog 接入时的兼容性,欢迎测试:
sql
CREATE EXTERNAL CATALOG greptimedb_catalog
PROPERTIES (
"type" = "jdbc",
"user" = "your_username",
"password" = "your_password",
"jdbc_uri" = "jdbc:mysql://<greptimedb_host>:4002",
"driver_url" = "https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.28/mysql-connector-java-8.0.28.jar",
"driver_class" = "com.mysql.cj.jdbc.Driver"
);其他改进
- Dictionary 类型:新增 Dictionary 编码,适用于低基数字符串列的存储优化
- 压缩导出:
COPY DATABASE导出 CSV/JSON 时支持压缩 - COPY DATABASE 并行化:支持并行表操作,加速大规模数据导出
- 动态 Tracing:支持运行时启用/禁用 trace,无需重启服务
- 可重载 TLS 配置:TLS 客户端配置支持热重载
欢迎将评估和测试中遇到的问题提交到 GitHub Issues,我们会积极响应。
重要修复
- 写入特定情况下停滞:修复某些情况下 flush 逻辑导致的 write stall 无法恢复问题
- Metric Engine 死锁:修复变更 schema 时批量 alter tables 可能导致的死锁
- 索引缓存:修复 page 放入索引缓存前需要 clone 的问题
性能优化
- TSID 生成加速:使用 fxhash 替代 mur3,常规场景提升 5–6 倍,含 NULL 标签场景提升约 2.5 倍
- 并行化 File Source Region:加速 Region 加载
- 消除不必要的 Merge Sort:减少查询开销
- 并行构建 Partition Sources:提升分区表构建效率
- SHOW TABLES 优化:存在大量表的场景下性能显著提升
兼容性说明
本版本包含以下 breaking changes:
Metric Engine TSID 生成算法变更
我们将 TSID 生成算法从 mur3::Hasher128 替换为 fxhash::FxHasher,并为无 NULL 标签的场景新增了快速路径。
影响说明:在升级时刻 t,升级前写入的数据使用旧算法生成 TSID,升级后使用新算法。如果查询时间范围跨越 t,在 t 附近的部分时间序列匹配可能出现轻微偏差;不跨越 t 的查询不受影响。
对于无法接受该差异的用户,建议使用「数据导出 → 升级 → 数据导入」的方式完成升级。详见备份与恢复文档。
MySQL/PostgreSQL 兼容性改进
数值类型别名已与标准 MySQL/PostgreSQL 对齐,部分非标准用法可能需要调整。
移除 export_metrics 功能及配置
GreptimeDB 主动推送监控指标的 export_metrics 功能已经被整体移除,请删除配置文件中的 [export_metrics] 相关配置。
结语
完整发行日志请查看 GitHub Release。
感谢所有贡献者和用户的支持,我们将继续按计划稳步迈向 1.0 GA。

