
本页内容
上周,我们公布了 GreptimeDB v1.0 的主要亮点及发布计划。本周,我们按计划发布了 v1.0.0 的首个 beta 版本。该版本是迈向 v1.0 GA 的关键一环,也是 GreptimeDB 实现成熟生产可用性的重要里程碑。
开发数据概览
以下是开发数据统计:
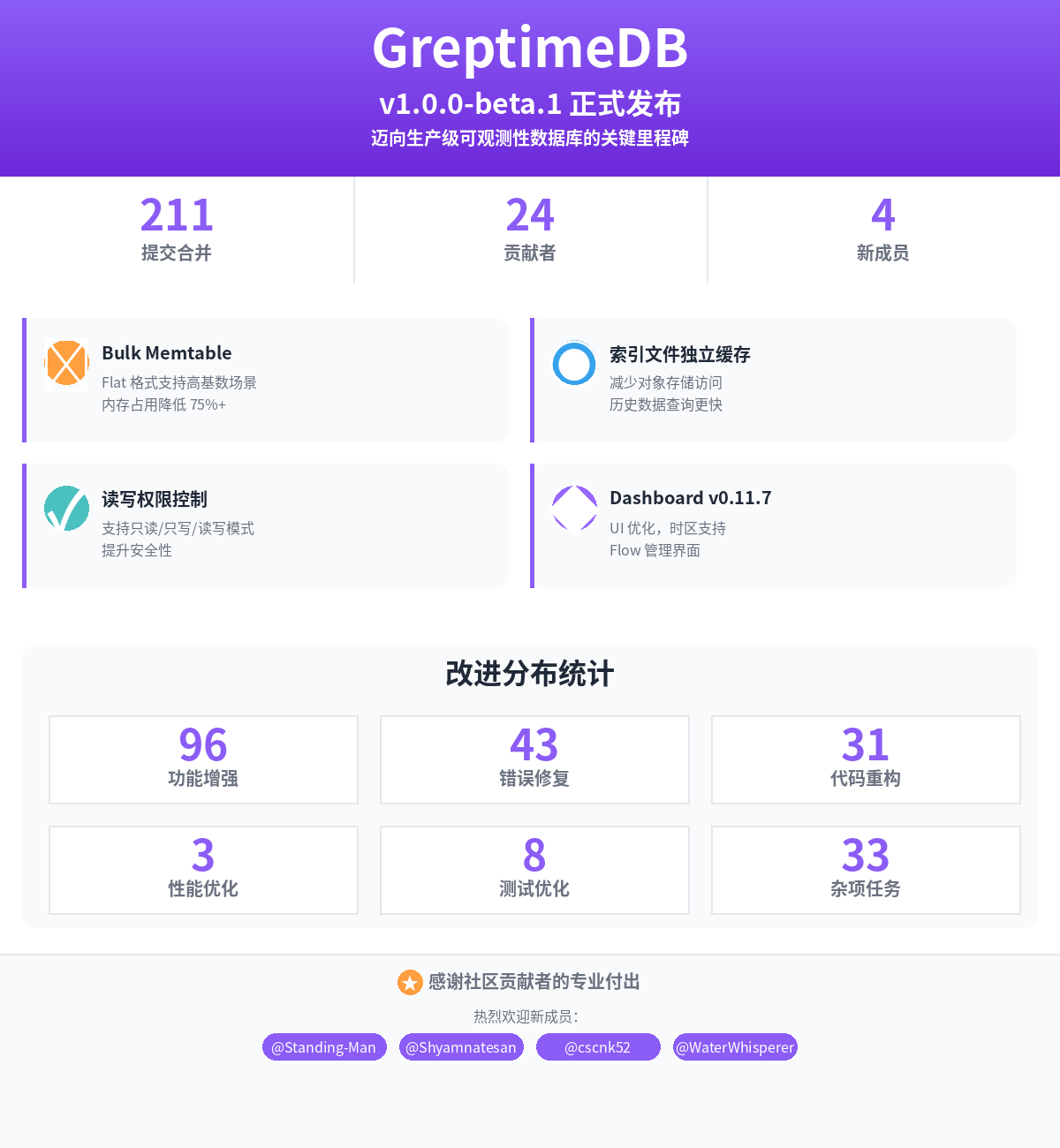
- 211 个提交合并至主分支;
- 24 位独立贡献者参与本次版本开发;
- 其中有 4 位独立贡献者首次提交代码,他们是:
- @Standing-Man
- @Shyamnatesan
- @cscnk52
- @WaterWhisperer
接下来看主要改进分布:
- 96 项功能增强:新增实验性 Flat 格式支持,大幅提升查询性能;实现异步索引构建,优化写入性能
- 43 项错误修复:修复 PromQL 时间戳和列引用问题,解决 Flat 格式相关崩溃和并发限制;改进 Region 迁移和故障检测机制,修复查询别名相关问题
- 31 项代码重构:统一重构 UDF 实现,采用 DataFusion 风格,更易于扩展;重构函数 trait 简化架构;配置与测试框架改进
- 3 项性能优化:Bulk Memtable 提高写入性能,优化 Arrow 到各数据库协议的值转换并提升性能,优化 Jaeger API 查询性能
- 8 项测试优化:新增升级兼容性测试,扩展 Flat 格式测试覆盖,完善删除和过滤场景测试
- 33 项杂项任务:升级 Rust 到 2024 版本,更新 DataFusion 到 50 版本,优化开发工作流和监控指标
👏 **特别感谢 24 位独立贡献者的专业付出,再次热烈欢迎 4 位新加入的社区成员!**我们也诚邀更多对可观测性数据库/技术感兴趣的开发者,一同参与 GreptimeDB 社区的持续建设。
亮点更新
Dashboard v0.11.7 发布
- Metrics UI 优化:标签页分离表格图表,独立即时/范围查询,支持时间选择器和多值显示。
- 时区优化:支持时区验证和本地存储持久化
- Flow 管理:新增管理 flow 任务增删改查的 UI 界面
Bulk Memtable
针对高基数主键的场景,本版本加入了实验性质的 Bulk Memtable 和新的 SST 数据组织方式(flat 格式)。高基数主键场景下,Bulk Memtable 具有更低的内存占用。在主键基数超过两百万的情况下,内存占用可以降低 75% 以上。目前 Bulk Memtable 在写入批大小(batch size)较大的情况下性能表现更好,建议用户使用 Bulk Memtable 时设置 1024 行以上的批大小。此外,新的数据组织方式在高基数场景下也相比原有数据组织方式有更高的查询性能。
用户可以在建表时指定 sst_format 为 flat 来启用新的数据格式和 Bulk Memtable。
sql
CREATE TABLE flat_format_table(
request_id STRING,
content STRING,
greptime_timestamp TIMESTAMP TIME INDEX,
PRIMARY KEY (request_id))
WITH ('sst_format' = 'flat');此外,对于使用旧格式的表,也可以通过 ALTER 语句切换到 flat 格式和 Bulk Memtable。
sql
ALTER TABLE old_format_table
SET 'sst_format' = 'flat';使用 flat 格式的表不支持修改为旧格式。我们后面会逐步将默认格式切换为新的格式。
索引文件独立缓存
本版本为对象存储上的索引文件实现了独立的本地缓存,使得索引文件能够尽可能地缓存在本地的磁盘缓存中,减少查询索引时访问对象存储的机率。默认数据库会将磁盘缓存(Write Cache) 20% 的空间分配给索引文件。用户可以通过设置 index_cache_percent 参数来调整这个比例。
在此前的版本中,用户调大本地磁盘缓存的大小后,只有新产生的数据文件才能够进入本地的写缓存,因此对查询历史数据的提升不大。在新版本中,数据库在启动后,会在后台从对象存储中加载索引文件到本地,降低历史数据查询的耗时。
读写权限控制模式
本次发布为静态用户配置引入了权限模式支持,实现了读写访问控制,支持只读、只写和读写权限。这项增强功能使管理员能够创建具有特定访问级别的用户,从而提高安全性和数据治理水平。
静态用户提供程序现在接受格式为 username:permission_mode=password,其中可选的 permission_mode (权限模式)可以是:
rw(读写):完全访问读写操作ro(只读):仅限制为读取操作wo(只写):仅限制为写入操作
示例:
toml
# 读写用户(默认,向后兼容)
greptime_user=greptime_pwd
# 或显式指定
greptime_user:rw=greptime_pwd
# 只读用户
greptime_user:ro=greptime_pwd
# 只写用户
greptime_user:wo=greptime_pwd此功能与旧格式完全向后兼容 - 未明确指定权限模式的用户默认为读写访问(rw)。
TQL 支持别名
TQL 现已支持 AS 别名,让列名更清晰,SQL 集成更便捷。
sql
TQL EVAL (0, 30, '10s') http_requests_total AS requests;新增 objbench 子命令(Datanode)
本版本新增 greptime datanode objbench 子命令,用于对对象存储中的指定 SST 文件进行读写性能基准测试。该工具可用于分析存储层性能、排查慢查询或 I/O 延迟问题,并支持输出火焰图进行更深入的性能诊断。
主要功能:
- 对单个 SST 文件执行读写性能测试
- 支持详细输出 (
-v/--verbose) - 支持生成 SVG 火焰图 (
--pprof-file) - 可加载 datanode 配置文件 (
--config)
bash
# 基础测试
greptime datanode objbench --config datanode.toml --source <path>.parquet
# 生成火焰图
greptime datanode objbench --config datanode.toml --source <path>.parquet --pprof-file flamegraph.svg兼容性说明
Jaeger Header 移除
HTTP 头 x-greptime-jaeger-time-range-for-operations 已被弃用并移除。所有相关文档和示例已被清理。如果你在 Jaeger 数据源或代理中配置了此 Header,它将不再生效。
Metric Engine 默认启用稀疏主键编码
Metric Engine 现在默认启用稀疏主键编码(sparse primary key encoding),以提升 metric 场景的存储效率和查询性能。
此变更不会导致数据格式兼容性问题,但是如果你依旧希望使用旧的编码,可以在配置中显式禁用稀疏编码。否则,所有的指标表将自动使用稀疏编码。
示例配置:
toml
[metric_engine]
sparse_primary_key_encoding = true # v1.0.0-beta1 的默认行为原参数 experimental_sparse_primary_key_encoding 废弃。
greptime_identity Pipeline 的 JSON 行为变更
greptime_identity Pipeline 的 JSON 处理逻辑已发生变化:
- 嵌套的 JSON 对象将自动展开为使用点号的独立列(例如
object.a,object.b) - 数组将以 JSON 字符串形式存储,而不是 JSON 对象
- 参数
flatten_json_object已被移除 - 新增参数
max_nested_levels,用于控制展开深度(默认 10 层) - 当超过限制时,剩余的嵌套结构将被序列化为 JSON 字符串
此变更统一了 JSON 数据的写入行为,并简化了 schema 管理,但可能需要用户调整配置和查询语句。
结语
完整发行日志请查看: https://github.com/GreptimeTeam/greptimedb/releases/tag/v1.0.0-beta.1
再次感谢所有贡献者和用户对 GreptimeDB 的贡献与关注,接下来我们将按照发布计划稳步迈向 1.0 GA。

