本页内容
现如今,各行各业的发展都离不开数据,企业对数据库的要求也越来越高。一个理想的高性能数据库需同时满足海量读写需求,拥有强大的分析能力,还要能低成本存储历史数据。在业务中,人们还希望能够低门槛迁移,无缝扩展。
而目前的数据库远未能支持从用户手里大量的数据中挖掘足够多的价值。虽然这样的产品很难得,但不是没有。
我们总结 GreptimeDB 的特点主要包含三个:
- 高可用、高可靠、可伸缩性强
GreptimeDB 能支撑海量时序数据及时间线的高频读写,具备优秀的可伸缩性。这种伸缩能力还体现在我们对 GreptimeDB 的版本规划上,从嵌入式的单机数据库(甚至可以是纯内存的嵌入式数据库),到传统专有云大规模分布式系统,再到完全基于云上的 Cloud Native 版本,用户可以根据自己的实际情况自由地选择相应的部署结构,支持在不同版本间无缝伸缩。
- 完全面向云原生系统设计
GreptimeDB 从底层构建多租户系统,做好资源隔离和权限控制;采用存储与计算分离架构,充分利用云上的廉价对象存储,计算节点面向弹性设计;全过程加密,用户数据完全自主可控。除了架构系统设计之外,我们也将提供可以在云上(甚至多云)开箱即用的云上部署、运维和管控系统,甚至商用的全托管服务。
- 复杂分析能力强
在数据库系统内,通过提供 SQL 分析和 Script(尤其是 Python )运算能力,进一步提升了 GreptimeDB 满足复杂计算和 AI 训练及运行的能力,降低了计算的延时,以及用户的学习、使用和长期维护成本。
针对这三个特点, 下文将展开说明我们的设计理念和概要设计。
系统概览
GreptimeDB 的整体架构如下:
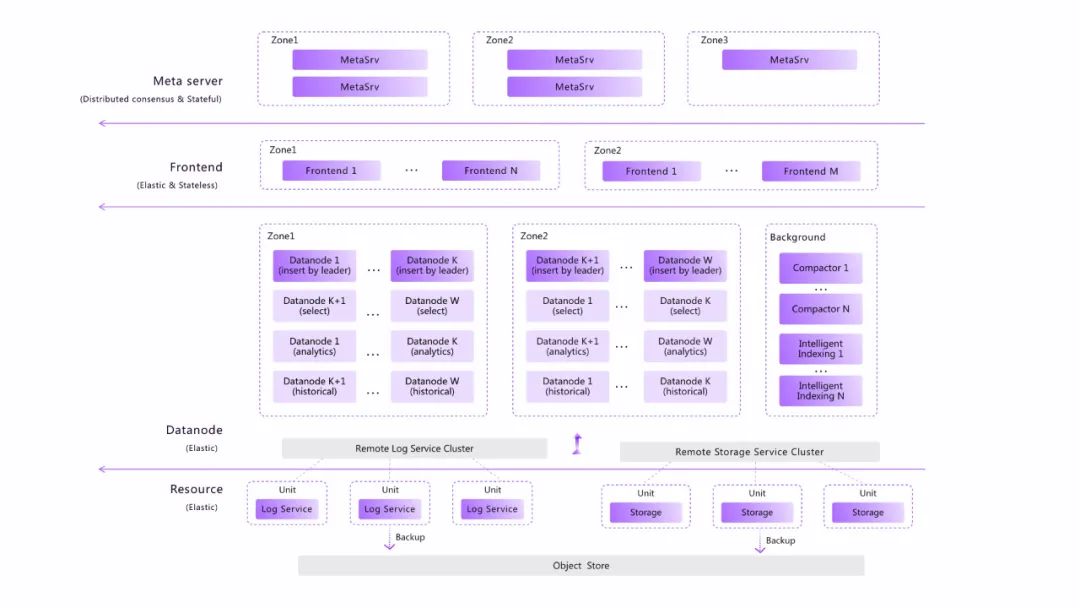
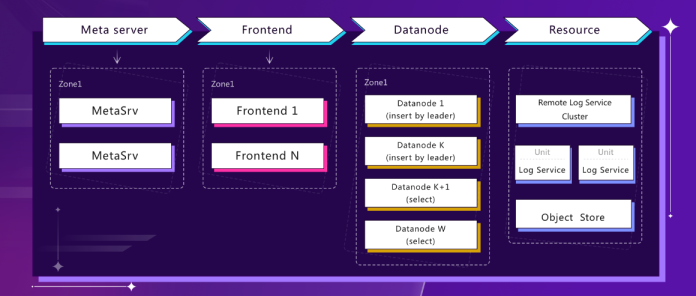
GreptimeDB 主要组件包括:
- MetaServer 集群
用以保存和管理整个 GreptimeDB 集群的元信息,包括节点元信息(IP地址、端口、角色等)、表的位置信息(region 及分布)、表的元信息(schema、选项等)以及集群的状态管理(节点状态、各类全局状态、全局任务状态等)。MetaServer 之间基于 Raft 协议实现强一致协议,也可以直接使用 etcd/zookeeper 等开源组件作为后端。
- Frontend 集群
作为前端节点,承担代理和路由的角色,根据表的位置信息以及负载均衡规则等将读写请求路由到正确的后端节点,并且承担跨 region 或者跨表的分布式查询功能。Frontend 实现了绝大部分开源协议的写入支持,例如 MySQL, PostgreSQL, OpenTSDB, InfluxDB, Prometheus 以及我们自己的私有 gRPC 和HTTP RESTful 协议等,我们尽量支持多样化的写入协议,方便大家快速接入 GreptimeDB。在查询方面,我们主要支持SQL语言,因为熟悉SQL的开发者众多,并且围绕SQL的周边生态非常强大,用户同样可以通过 MySQL, PostgreSQL, RESTful, gRPC 等协议来使用 SQL 查询和分析 GreptimeDB 中的数据。未来查询语言我们还将支持 PromQL,因为在云原生可观测领域,大家对 PromQL 的接受度更高。
- Datanode 集群
Datanode 是存算分离架构中的主要计算节点(Frontend 也承担了部分分布式查询的能力),实现并集成了时序数据引擎及 SQL 查询引擎、Python 分析引擎等主要数据处理功能。Datanode 具备读、写、分析以及计算等能力,这几种能力还可以按照配置和集群角色来区分为不同的算力池子:读节点、写节点、分析和计算节点等,实现了不同算力的隔离和细分,并且在云原生版本下可以做到按需弹性扩展。
- Remote storage
存算分离中的存储层,包括分布式 WAL 的 remote log service,以及数据存储 remote storage service。GreptimeDB 同样是使用 WAL 来实现数据的高可靠和高效写入,也是基于 WAL 来设计高可用方案和实现数据的复制备份等。我们设计了一个支持高吞吐读写、高可靠和高可用的分布式日志架构,具体将在之后的博客中描述。GreptimeDB 中的数据和日志,都将存储到对象存储 ObjectStore(基于 OpenDAL 项目),它可能是 S3, OSS 等云计算厂商提供的廉价、可靠的对象存储,也可能是本地磁盘介质。基于前者将是一个 Cloud Native 的架构,而后者是典型的传统分布式方案。针对本地磁盘方案,我们还将提供同步复制和异步复制方案来解决数据的高可靠问题。
最后,我们要特别指出,上述这 4 个组件中 MetaServer 与 Remote storage 是可选部署的,而 Frontend 和 Datanode 可在同一个进程内部署,具体可见下图:
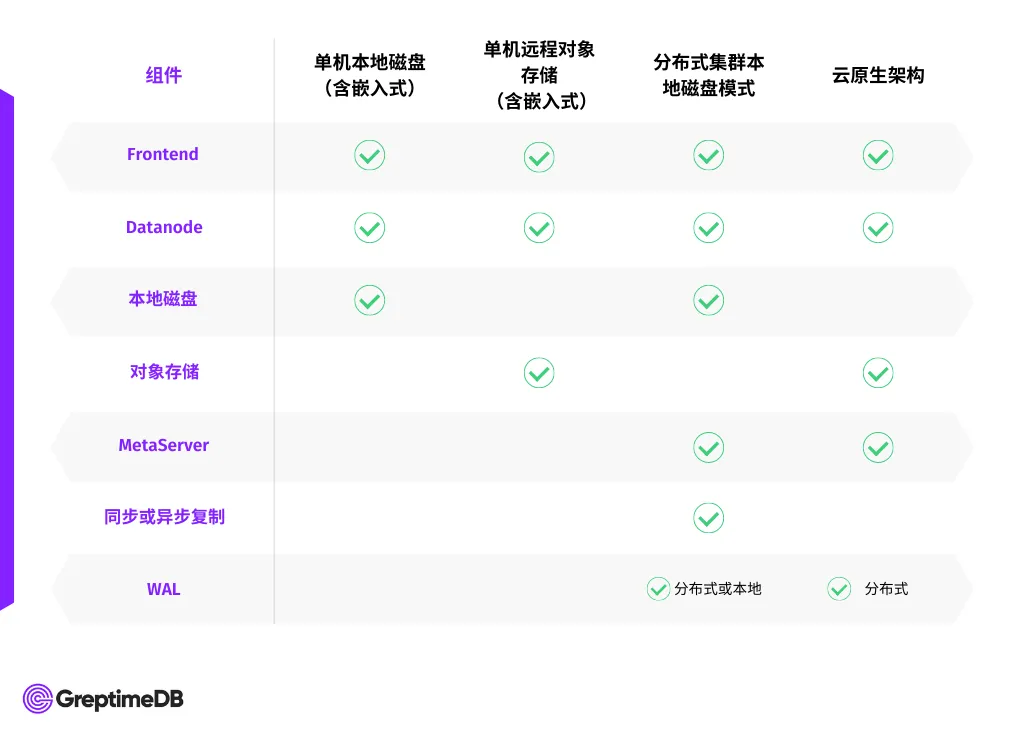
用户可以根据自己的业务情况和需求等来选择部署方式,我们也提供了 K8s operator 以及命令行工具 gtctl 来帮助用户在 K8s 环境下方便的运维和管理 GreptimeDB 集群。同时我们也提供了全托管的 Greptime Cloud 云服务来让大家零门槛地测试和使用 GreptimeDB。
数据模型
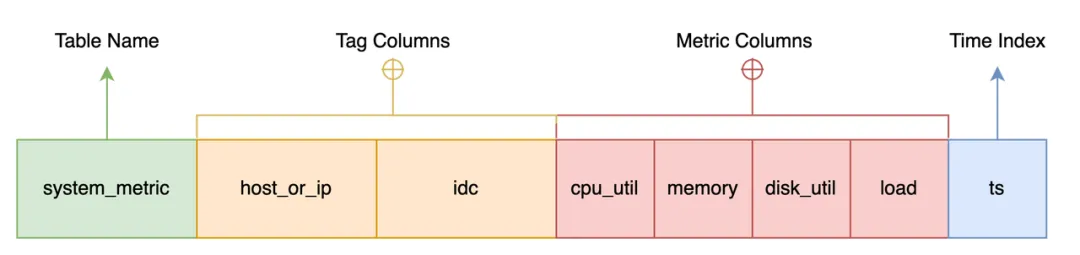
数据模型上,我们是以关系数据库中的表模型为主,结合时序数据特点来设计。举个例子,如果要设计一个单机上的系统资源监控,你可以设计如下表:
sql
CREATE TABLE system_metric {
host_or_ip STRING NOT NULL,
idc STRING default 'idc0',
cpu_util DOUBLE,
memory DOUBLE,
disk_util DOUBLE,
load DOUBLE,
ts TIMESTAMP NOT NULL,
TIME INDEX(ts),
PRIMARY KEY(host_or_ip, idc),
};其中 host_or_ip 是采集的单机的 hostname 或者 IP 地址,idc 列是该机所在的机房,cpu_util、memory、disk_util 和 load 就是采集的单机指标,ts 是采集的时刻(Unix 时间戳)。这些都跟大家熟悉的表模型非常类似,比较特别的是 TIME INDEX(ts) 这个约束,它是用来指定这张表的时间索引列为 ts 列。
我们将这样的表称之为时序表 (TimeSeries Table),它由四部分组成:
表名:通常也是指标名,比如这里的 system_metric。
时间索引列:必备项,通过 time index 约束指定,一般用来表示这行数据的产生时间,如例子中的 ts 列。
指标列(Metric Column):采集的数据指标,一般随时间而变化,比如例子中的 cpu_util、memory 等 4 个数值列。指标一般是数值,但是也可能是其他类型的数据,比如字符串、地理位置等。GreptimeDB 是一个多值模型(一行数据可以有个多个指标列),而不是类似 OpenTSDB 或者 Prometheus 这样的单值模型。
标签列(Tag Column):采集指标上附带的标签,比如例子中的 host_or_ip 和 idc 列,一般是对这些指标的某个特征的描述。
之所以基于 Table 模型来设计,原因有以下几点:
首先是大家对 Table 这套模型的接受度非常高,它是易于掌握和学习的。我们只是针对时序的模型引入了时间索引的概念,时间索引将用于指导数据的组织、压缩和过期管理等。
Schema 是描述数据特征的元信息,可以更好地方便管理和维护,并且通过引入 schema 版本的概念,也能更好地管理数据兼容性。
Schema 信息对于存储和计算的优化能带来很大帮助,由于具备类型、长度等信息,可以做更多针对性的优化。
基于 Table 模型,引入 SQL 变成自然而然的事情,并且可以使用 SQL 做各种指标表之间的关联分析和聚合查询,进一步降低用户的学习和使用成本。
但是同时我们对 schema 定义不是强制的,更偏向于 MongoDB 这样的 schemaless 的方式,可以动态地在写入数据的时候创建表,动态地增加列(指标列,标签列都可以),并且和 Prometheus, OpenTSDB, InfluxDB 等开源协议的数据模型兼容,将这些协议的数据无缝转化为时序表模型,自动建表和增加列等(单值模型默认映射为 greptime_value 列)。
关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack

