On this page

六月即将过半,伴着夏日的声声蝉鸣,GreptimeDB v0.3 如期而至。
在 4 月中旬发布的 v0.2 版本 中,我们主要目标集中在单机,PromQL 兼容,写入性能优化等方面。
v0.2 的单机版本有了较好的基础,而在 v0.3 版本,我们的关键词则是 “分布式”,也就是所有的能力或是更新均在分布式版本上提供(分布式提供了单机版本不具备的扩展性、高可用性和容错性等)。总结来讲,主要有以下几个方面:
分布式性能优化:实现了 Region 级别的高可用性,提供了快速的容灾切换调度。同时也对分布式写入性能进行了优化。
查询能力提升:包括支持分布式查询优化、重要 SQL 查询 (如 TopK) 的改善以及优化数据压缩策略来加快查询速度。
稳定性增强:为了增加系统的健壮性和可靠性,引入了 Procedure 框架来保障多步操作的最终一致性。同时提供了更细粒度的 Hybrid-flush 策略以提高写入的稳定性,并增加了更多性能指标度量的埋点来提升系统的可观测性,支持如 Tokio console 等工具。
从 0.2 到 0.3,一个半月时间,仅 GreptimeDB 项目就合并了 222 PRs, 涉及到 674 个文件修改,包含了 120+ 个功能优化,50+ 个修复以及 20+ 重构,这些数字的背后是 27 位社区贡献者的努力,我们衷心地感谢社区和团队的努力。接下来,我们重点讲述 v0.3 的核心内容。
GreptimeDB v0.3 重点内容
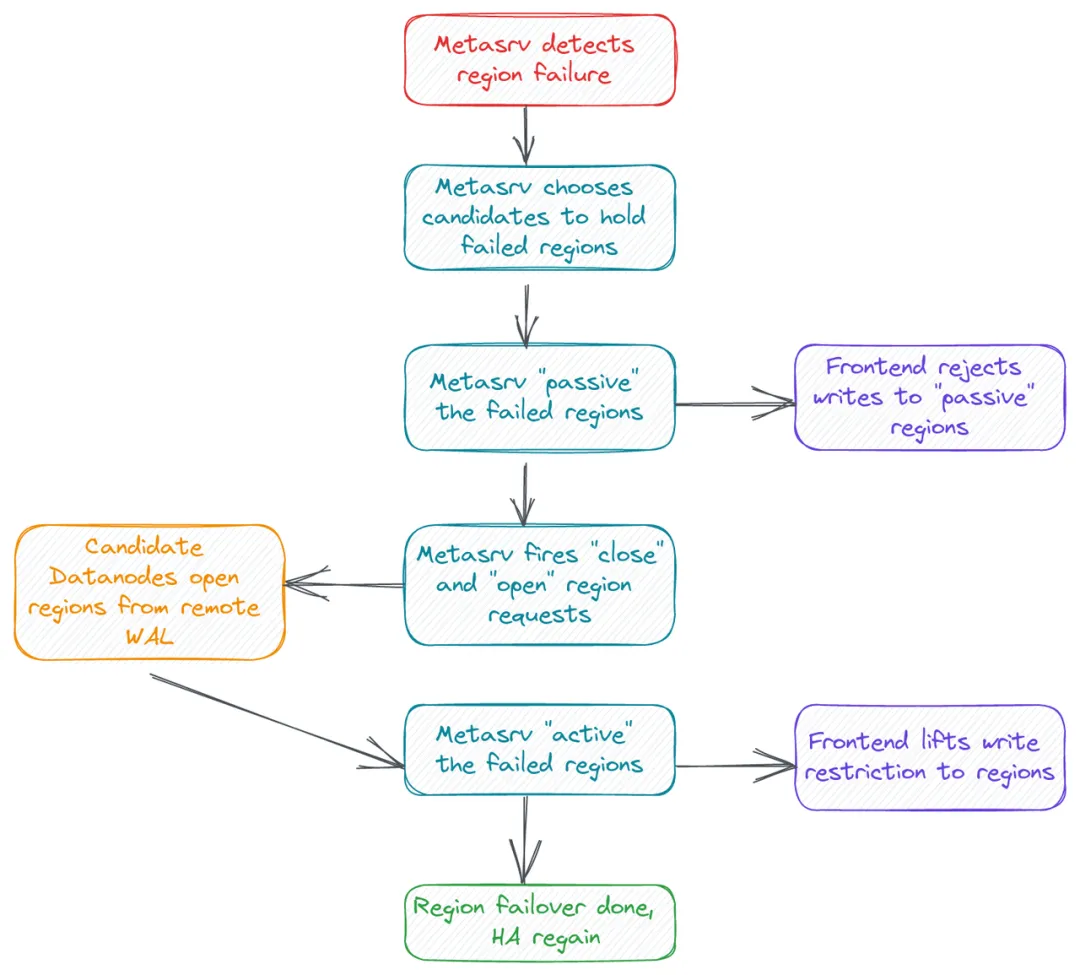
实现 Region 级别的高可用
实现 Region 级别的高可用在分布式系统中,为了保障高可用,需要做到 region 级别的容灾, GreptimeDB 在 v0.3 版本中支持了这一特性,是最终达到分布式高可用的重要里程碑,由于涉及到 Frontend, Meta 和 Datanode 等不同组件的改造,影响面较广,我们通过 Issue#1126 来跟踪整个实现过程,如果你对此感兴趣,欢迎关注。当然,一切是从 RFC: Region Fault Tolerance 开始:
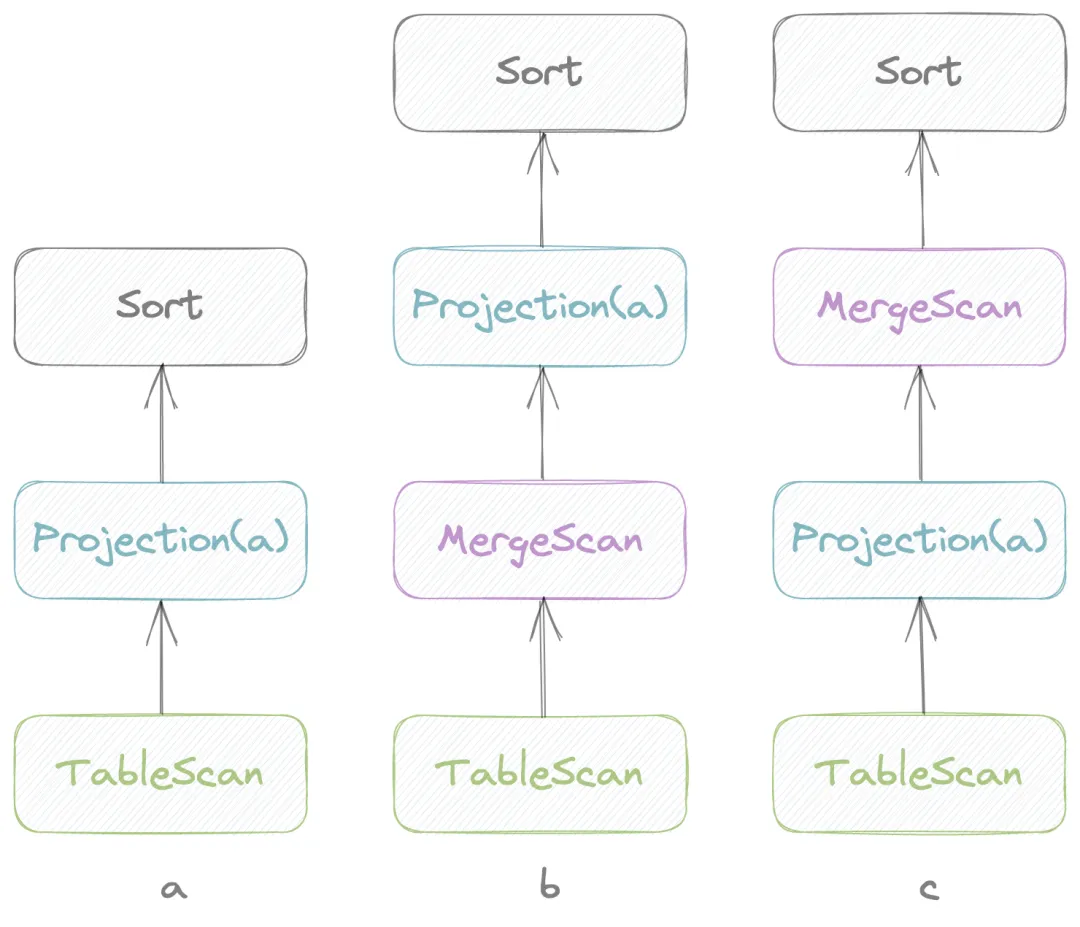
重要的 SQL 查询场景优化
基于过去的业务经验,在 GreptimeDB v0.3 开发中重点优化了最常用的查询场景,比如 TopK 等,主要还是利用了剪枝的思维,我们也将整个工作分成了多个子任务,并通过 Issue#1286 跟踪。
分布式查询优化,支持常用算子下推
为了数据库的分析能力,很早就有人提出 Near-Data Processing 的方式,也就是给予存储层一定的算力,让一些简单的计算在数据中心完成之后再返回,这样可以避免大量原始数据的传输,而算子下推 (operator push-down) 是最常见的实现方式,GreptimeDB v0.3 支持了 PromQL 大部分算子和谓词的下推,优化分布式查询。这么重要的功能,我们也事先通过 RFC: Distributed Planner 讨论实现方案,具体实现可参见 PR#1660。
(Greptime 开发日常:这个 PR 超过了 1000 行代码的修改,在我们内部是极不推荐的,但因为 author 会发红包,大家也就勉强原谅了 ta,甚至还有点期待。)
引入了 Procedure 框架,保障多步操作的最终一致性
为了增加系统的健壮性和可靠性,受 Apache HBase's ProcedureV2 framework 启发,GreptimeDB 也用 Rust 写了一个 Procedure 框架来保障多步操作的最终一致性,这又是一个从 RFC: Procedure Framework 开始的故事,而且有一个超级庞大的 Issue#286 在跟踪,v0.3 并不是他的终点,故事还将继续。 (对了,如果你觉得 RFC 太枯燥,也可以参考 《从制作九转大肠来谈起|GreptimeDB 如何提高多步操作的容错能力》 这篇文章来理解到底什么是 Procedure。)
增加更多的性能指标提升系统的可观测性
作为可观测体系下的可靠存储方案,GreptimeDB 自身的可观测性也必须做好,在 v0.3 版本中,增加了更多的 metric 指标用来检测系统的运行情况,这部分内容遍及到每个组件中,可以参看 PR list 。
其他细节的优化:
支持查询外部数据,导入导出 CSV/JSON/Parquet 格式文件;
支持
TQL EXPLAIN/TQL ANALYZE从句,分析 PromQL 查询性能;提高了 PromQL 兼容性;
在单机/集群模式下均支持启用 Tokio 控制台;
等等。
整体上,v0.3 会是一个初步可以试用的分布式版本,它具备了 region 粒度的服务高可用(数据高可靠还待后续版本完成),重点场景的分布式查询(重点是 PromQL 查询方向)和写入性能均达到或者略微超过主流同类数据库性能的水位线。
升级注意事项
如果您是从 0.2 升级而来,需要特别注意以下几点:
使用本地存储,需要修改配置
data_dir,该选项已经废弃,假设您原来设置data_dir = "/greptimedb/data", 那么需要修改为data_home = "/greptimedb",data_home替代指定数据根目录;建议升级之前使用
COPY命令备份数据。
GreptimeDB v0.4 计划
从 0.3 开始便将研发重点聚焦到分布式,并制定了中长期计划,按月迭代,0.4 的主题就是性能和完善现有功能,将聚焦在以下几个功能:
分布式 DDL 语句的支持像 Create Table, Drop Table 等接入 Procedure 框架确保分布式多步操作的正确执行;
异步的压缩和索引,提升查询性能;
在 0.3 版本我们支持了 PromQL 大部分算子和谓词的下推,0.4 版本将聚焦到 SQL 中的常见算子的下推以提升 SQL 查询性能;
重点优化表引擎和存储引擎,提升读写性能,降低资源消耗。
致谢社区
感谢亲爱的社区和所有贡献者们,是你们的每一个建议、BUG 修复和代码贡献,才让这个项目不断壮大、迈向新的高峰。

关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack