
本页内容

随着 AI 技术的发展,GPT-4 在多种语言处理任务上表现卓越,包括机器翻译、文本分类和文本生成。同时,也有其他优质开源大语言模型涌现,比如 Llama、ChatGLM、Qwen 等等。这些优秀的开源模型可以帮助团队快速搭建一个出色的 LLM 应用。
然而,这些模型框架并未提供一致的可观测体验,这增加了开发者在不同框架之间对比迁移的难度。如何在减少开发成本的同时,能够统一使用 OpenAI 的接口?如何能高效地持续监控 LLM 应用的运行表现,而又不增加额外的开发复杂度?
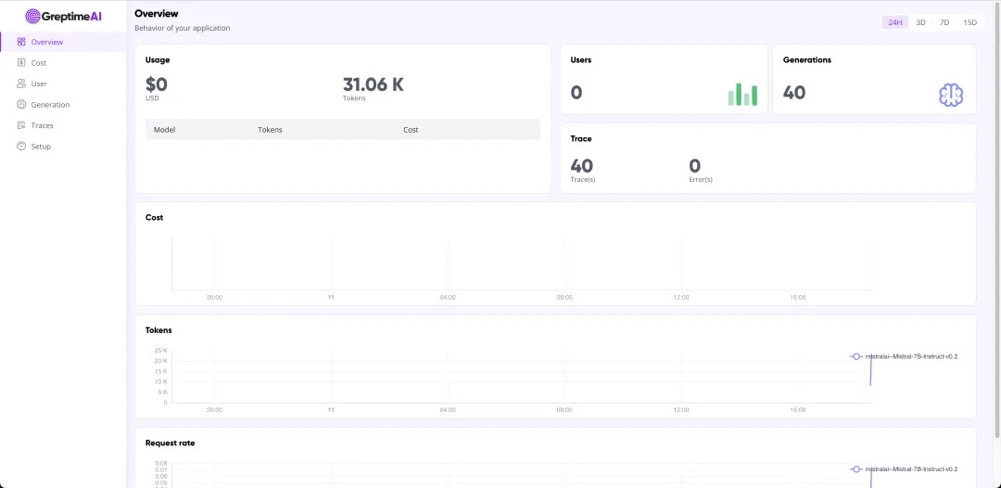
在这些问题上,GreptimeAI 和 BentoCloud 提供了切实可行的解决方案。最终观测控制台效果如下:
GreptimeDB & GreptimeAI
GreptimeDB 是一款用 Rust 语言编写的时序数据库,具有分布式、开源、云原生、兼容性强等特点,帮助企业实时读写、处理和分析时序数据的同时,降低长期存储的成本。
GreptimeAI 构建于开源时序数据库 GreptimeDB 之上,是为大语言模型(LLM)应用提供的一套可观测解决方案,目前已经支持 LangChain 和 OpenAI 的生态。GreptimeAI 使您能够实时全面地了解成本、性能、流量和安全性方面的情况,帮助团队提升 LLM 应用的可靠性。
BentoML and BentoCloud
BentoML 旨在为机器学习模型的服务,打包和部署提供统一的框架。它支持实时 API 服务、推理优化、批处理、模型组合等多种功能,以处理不同的 AI 用例。
BentoCloud 提供了一个专为运行 AI 模型优化的 Serverless 平台,具备自动伸缩能力、安全性和可观察性。
使用 BentoML 部署大语言模型
BentoML 提供了简化的 Service APIs,用于部署大语言模型 (LLMs)。以下是一个使用 vLLM 作为后端的 BentoML Service 示例,使用 LLM mistralai/Mistral-7B-Instruct-v0.2 生成结果,并提供了与 OpenAI 兼容的接口。
它通过 Prompt 模板指定模型行为,设置了最大 token 限制,并通过 stream 的方式来确保交互的实时性。
python
import uuid
from typing import AsyncGenerator
import bentoml
from annotated_types import Ge, Le
from typing_extensions import Annotated
# Import utility for creating OpenAI-compatible endpoints. See https://github.com/bentoml/BentoVLLM.
from bentovllm_openai.utils import openai_endpoints
MAX_TOKENS = 1024
# Define a prompt tem)plate to guide the model's behavior and response style
PROMPT_TEMPLATE = """<s>[INST]
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
{user_prompt} [/INST] """
MODEL_ID = "mistralai/Mistral-7B-Instruct-v0.2"
# Decorators to mark the class as a BentoML service with OpenAI-compatible endpoints
@openai_endpoints(served_model=MODEL_ID)
@bentoml.service(
name="mistral-7b-instruct-service",
traffic={
"timeout": 300,
},
resources={
"gpu": 1,
"gpu_type": "nvidia-l4",
},
)
class VLLM:
def __init__(self) -> None:
from vllm import AsyncEngineArgs, AsyncLLMEngine
ENGINE_ARGS = AsyncEngineArgs(
model=MODEL_ID,
max_model_len=MAX_TOKENS
)
self.engine = AsyncLLMEngine.from_engine_args(ENGINE_ARGS)
@bentoml.api
async def generate(
self,
prompt: str = "Explain superconductors like I'm five years old",
max_tokens: Annotated[int, Ge(128), Le(MAX_TOKENS)] = MAX_TOKENS,
) -> AsyncGenerator[str, None]:
from vllm import SamplingParams
SAMPLING_PARAM = SamplingParams(max_tokens=max_tokens)
prompt = PROMPT_TEMPLATE.format(user_prompt=prompt)
stream = await self.engine.add_request(uuid.uuid4().hex, prompt, SAMPLING_PARAM)
cursor = 0
async for request_output in stream:
text = request_output.outputs[0].text
yield text[cursor:]
cursor = len(text)想要更详细地了解 BentoML Service 并将其部署到 BentoCloud,请参见 此教程。
一旦它开始运行,你可以在 BentoCloud 的控制台上与之交互。
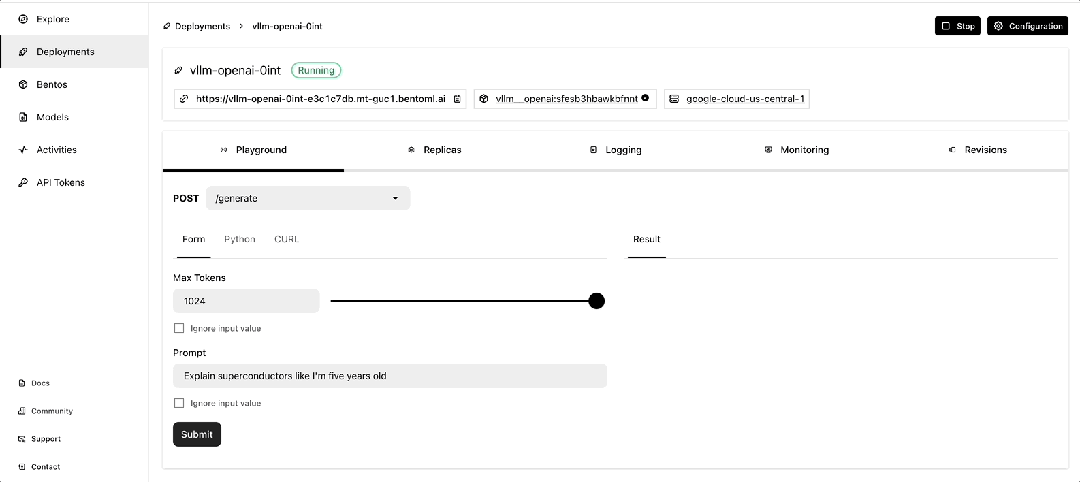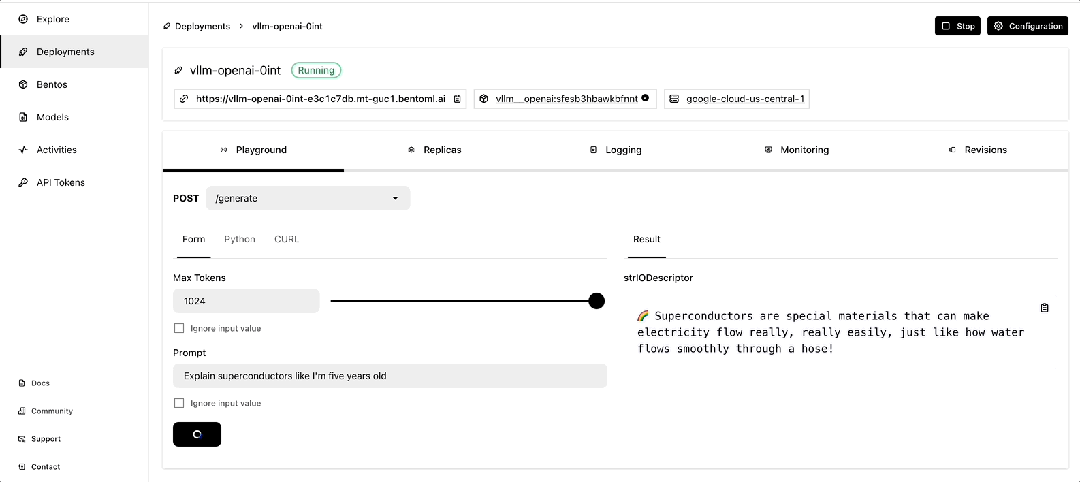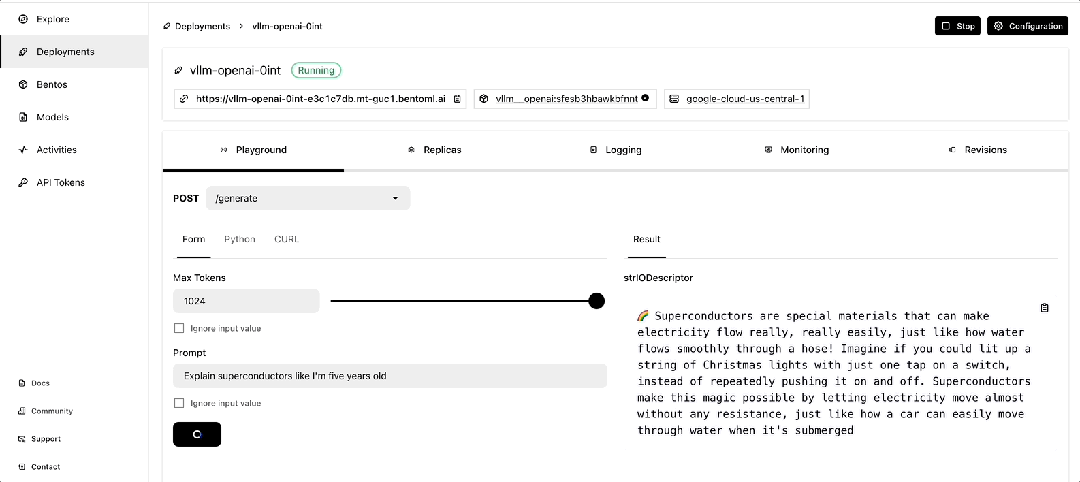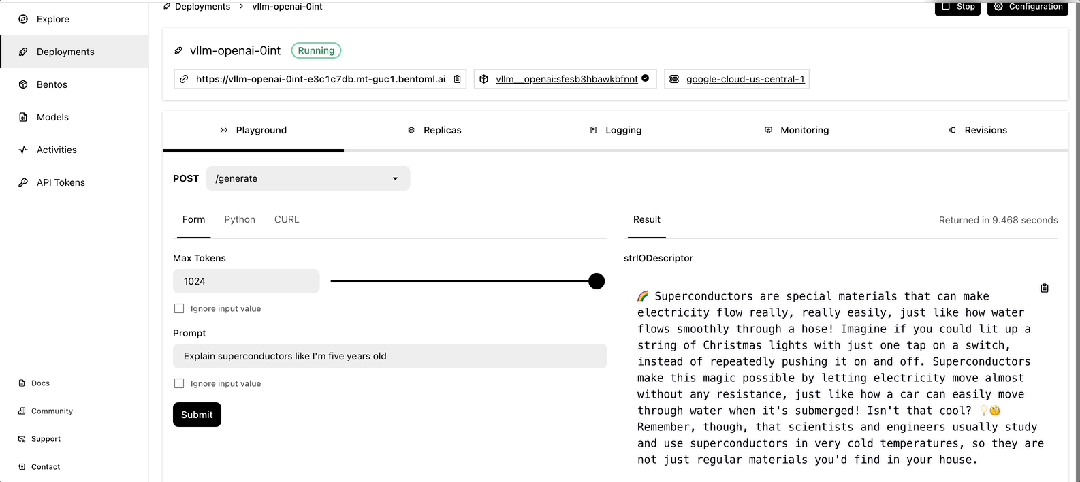
使用 GreptimeAI 监控 LLM 应用
安装 GreptimeAI
bash
pip install openai greptimeai设置 GreptimeAI 凭证
免费注册 GreptimeCloud,创建一个 service,点击进入 Solution tab 开启 LLM Observability 开关。
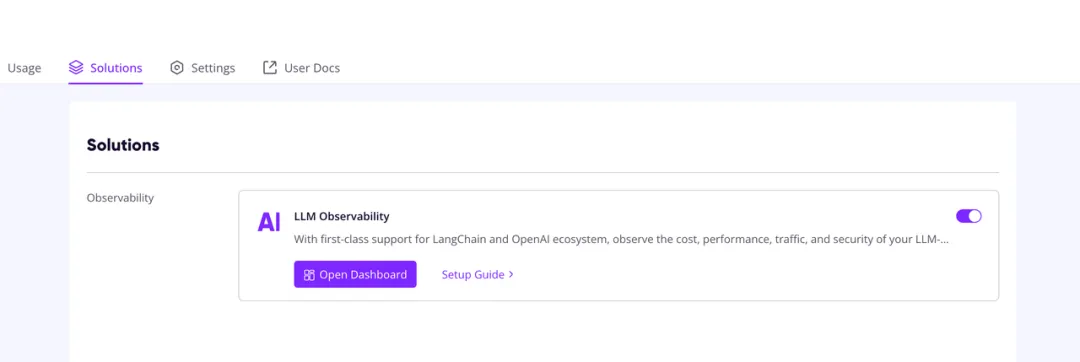
点击 Setup Guide 了解如何设置凭证。
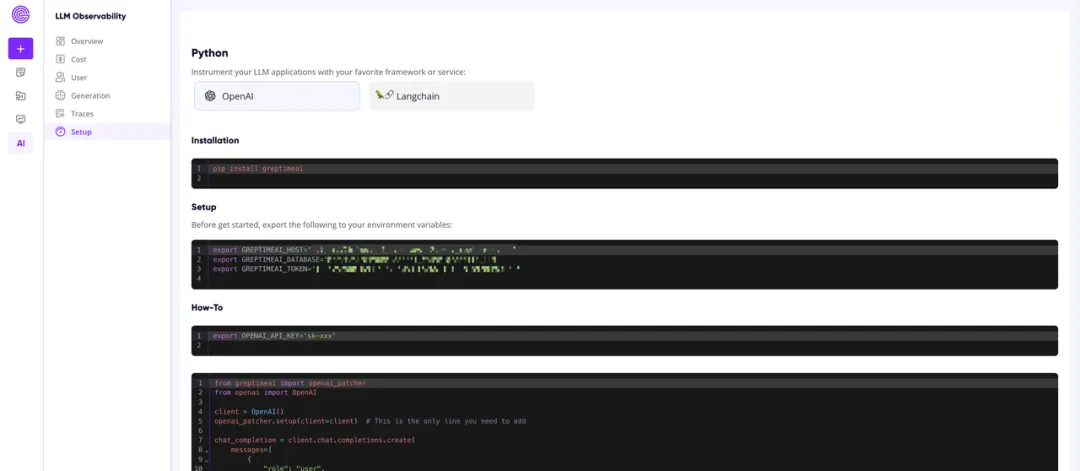
如果你不想将这些凭证导出为环境变量,可以直接将 host, database 和 token 传递给 openai_patcher.setup() 方法。
Patch OpenAI 客户端
只需按照如下的方式设置 OpenAI 客户端,即完成与 GreptimeAI 的集成:
python
# you can pass <host>, <database>, <token> into this setup method
# if you do not want to export the credentials as environmental variables.
openai_patcher.setup(client=client)以下是完整的示例代码:
python
from openai import OpenAI
from greptimeai import openai_patcher
client = OpenAI(base_url='<your_bentocloud_deployment_url>/v1', api_key='na')
openai_patcher.setup(client=client)
chat_completion = client.chat.completions.create(
model="mistralai/Mistral-7B-Instruct-v0.2",
messages=[
{
"role": "user",
"content": "Explain superconductors like I'm five years old"
}
],
stream=True,
)
for chunk in chat_completion:
print(chunk.choices[0].delta.content or "", end="")GreptimeAI 看板
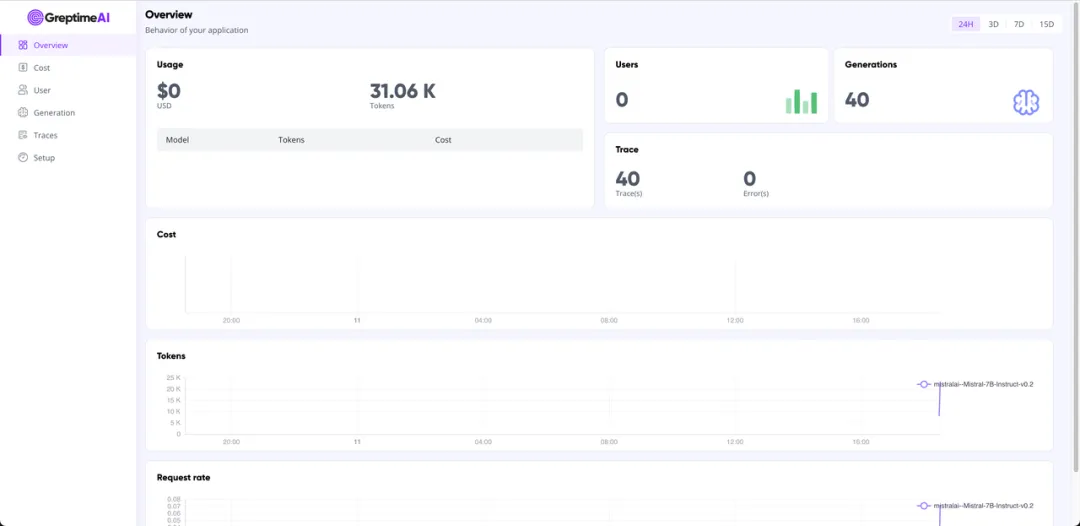
LLM 应用调用 OpenAI 接口的 metrics 和 trace 数据会被自动收集到 GreptimeAI 服务中,你可以在 GreptimeAI Overview 中看到整体使用情况,并在对应的功能标签找到你感兴趣的、有价值的数据。
总结
如果您正在使用开源模型构建 LLM 应用,希望用 OpenAI 的风格进行 API 调用,也想使用 serverless 服务来减少维护的复杂度,那么使用 BentoCloud 来管理推理模型是个不错的选择。同时结合 GreptimeAI 的可观测能力,可以帮助您高效地了解和优化模型的性能和资源消耗,相信 GreptimeAI + BentoCloud 的应用组合能够帮助您构建出生产级的 LLM 应用。
欢迎尝试 GreptimeAI + BentoCloud 的方案,也欢迎分享使用这个方案的体验和见解。
关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack

