
本页内容
前置条件
首先,你需要能够访问部署 InfluxDB 的服务器,以直接操作数据文件。如果你使用 InfluxDB 的官方 Docker 镜像运行服务器,存储数据文件的引擎路径为 /var/lib/influxdb2/engine/。
本教程将指导你如何迁移 InfluxDB 服务器上的数据,查看文末附录了解如何准备环境。
获取云上 GreptimeDB 集群
假设你已经有了运行中的 InfluxDB 服务器,要将数据迁移到 GreptimeDB 上,你首先需要启动一个 GreptimeDB 集群。
获取 GreptimeDB 集群最快的方式是注册 [GreptimeCloud](https://greptime.com/product/cloud) 并启动一个 hobby plan service(完全免费,不需要任何银行卡信息)。
根据指示创建一个新的 GreptimeDB 服务,点击 Connection Information 按钮获取连接信息,导出所需的环境变量值:
shell
export GREPTIME_DB="<dbname>"
export GREPTIME_HOST="<host>"
export GREPTIME_USERNAME="<username>"
export GREPTIME_PASSWORD="<password>"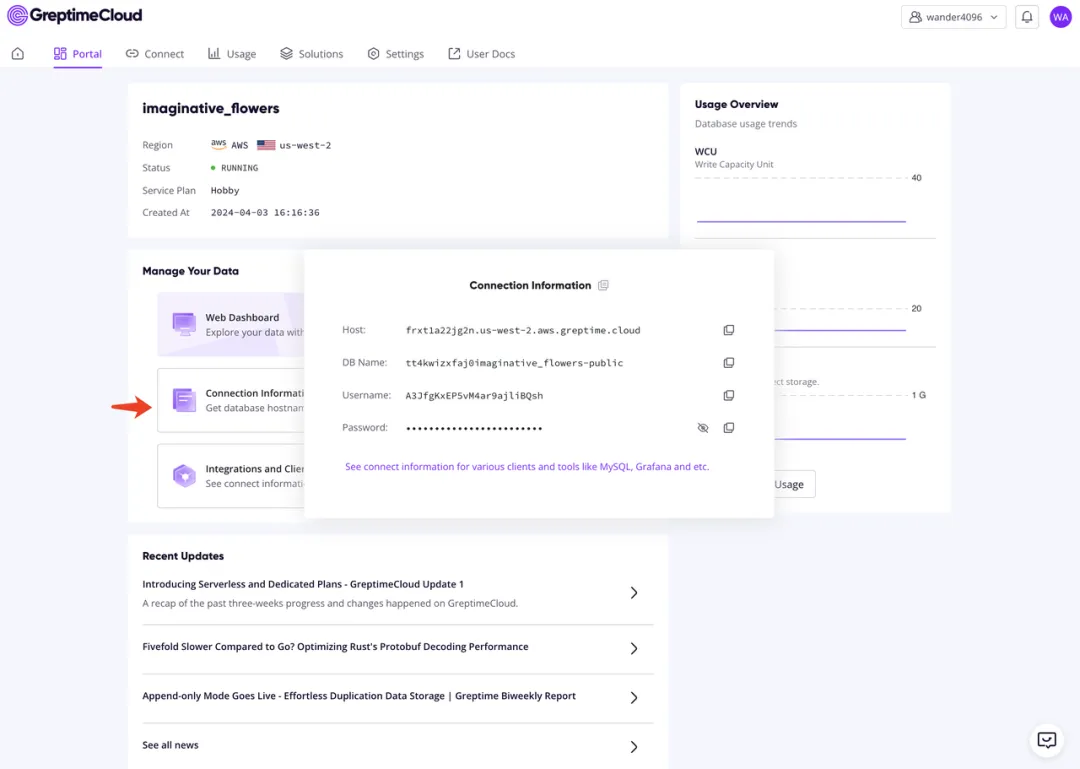
从 InfluxDB v2 服务器导出数据
现在,我们使用 InfluxDB CLI 获取要迁移的 bucket ID:
shell
influx bucket list如果你按附录中的设置操作,可以运行如下指令:
shell
docker exec influxdb2 influx bucket list输出示例如下:
text
ID Name Retention Shard group duration Organization ID Schema Type
22bdf03ca860e351 _monitoring 168h0m0s 24h0m0s 41fabbaf2d6c2841 implicit
b60a6fd784bae5cb _tasks 72h0m0s 24h0m0s 41fabbaf2d6c2841 implicit
9a79c1701e579c94 example-bucket infinite 168h0m0s 41fabbaf2d6c2841 implicit假设你想从 example-bucket 迁移数据,那么对应的 ID 就是 9a79c1701e579c94。
登录你部署的 InfluxDB v2 服务器,运行以下命令以 InfluxDB Line Protocol 格式导出数据:
shell
# 引擎路径通常是 "/var/lib/influxdb2/engine/"
export ENGINE_PATH="<engine-path>"
# 导出 bucket 里的所有数据 example-bucket (ID=9a79c1701e579c94)
influxd inspect export-lp --bucket-id 9a79c1701e579c94 --engine-path $ENGINE_PATH --output-path influxdb_export.lp如果你按附录设置服务,你可运行如下指令:
shell
export ENGINE_PATH="/var/lib/influxdb2/engine/"
docker exec influxdb2 influxd inspect export-lp --bucket-id 9a79c1701e579c94 --engine-path $ENGINE_PATH --output-path influxdb_export.lp输出示例如下:
text
{"level":"info","ts":1713227837.139161,"caller":"export_lp/export_lp.go:219","msg":"exporting TSM files","tsm_dir":"/var/lib/influxdb2/engine/data/9a79c1701e579c94","file_count":0}
{"level":"info","ts":1713227837.1399868,"caller":"export_lp/export_lp.go:315","msg":"exporting WAL files","wal_dir":"/var/lib/influxdb2/engine/wal/9a79c1701e579c94","file_count":1}
{"level":"info","ts":1713227837.1669333,"caller":"export_lp/export_lp.go:204","msg":"export complete"}成功执行导出命令后,数据将导出到 influxdb_export.lp 文件。
🌟 Tip你可以指定更具体的数据集进行导出,如测量值和时间范围。相关详细信息请参考 influxd inspect export-lp 手册。
数据导入 GreptimeDB
将 influxdb_export.lp 文件复制到工作目录。如果你按附录设置,可以运行如下指令:
shell
docker cp influxdb2:/influxdb_export.lp influxdb_export.lp在将数据导入 GreptimeDB 之前,如果数据文件过大,建议将数据文件分割为多个片段:
shell
split -l 1000 -d -a 10 influxdb_export.lp influxdb_export_slice.
# -l [line_count] Create split files line_count lines in length.
# -d Use a numeric suffix instead of a alphabetic suffix.
# -a [suffix_length] Use suffix_length letters to form the suffix of the file name.现在,通过 HTTP API 将数据导入 GreptimeDB:
shell
for file in influxdb_export_slice.*; do
curl -i -H "Authorization: token $GREPTIME_USERNAME:$GREPTIME_PASSWORD" \
-X POST "https://${GREPTIME_HOST}/v1/influxdb/api/v2/write?db=$GREPTIME_DB" \
--data-binary @${file}
# avoid rate limit in the hobby plan
sleep 1
done完成后,你可以在 GreptimeCloud 的 Web Dashboard 上检查已导入的数据。
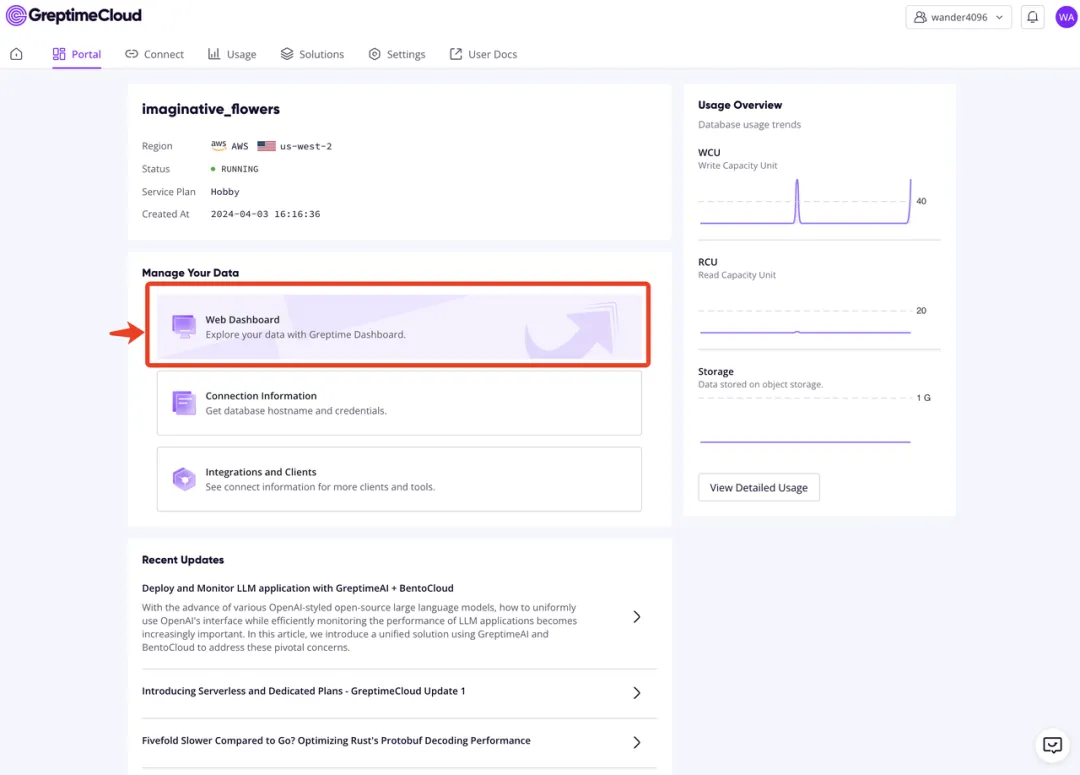
点击 Web Dashboasrd,进入看板页面,你可以使用 SQL 或者 PromQL 进行数据分析,也可以绘制图表。
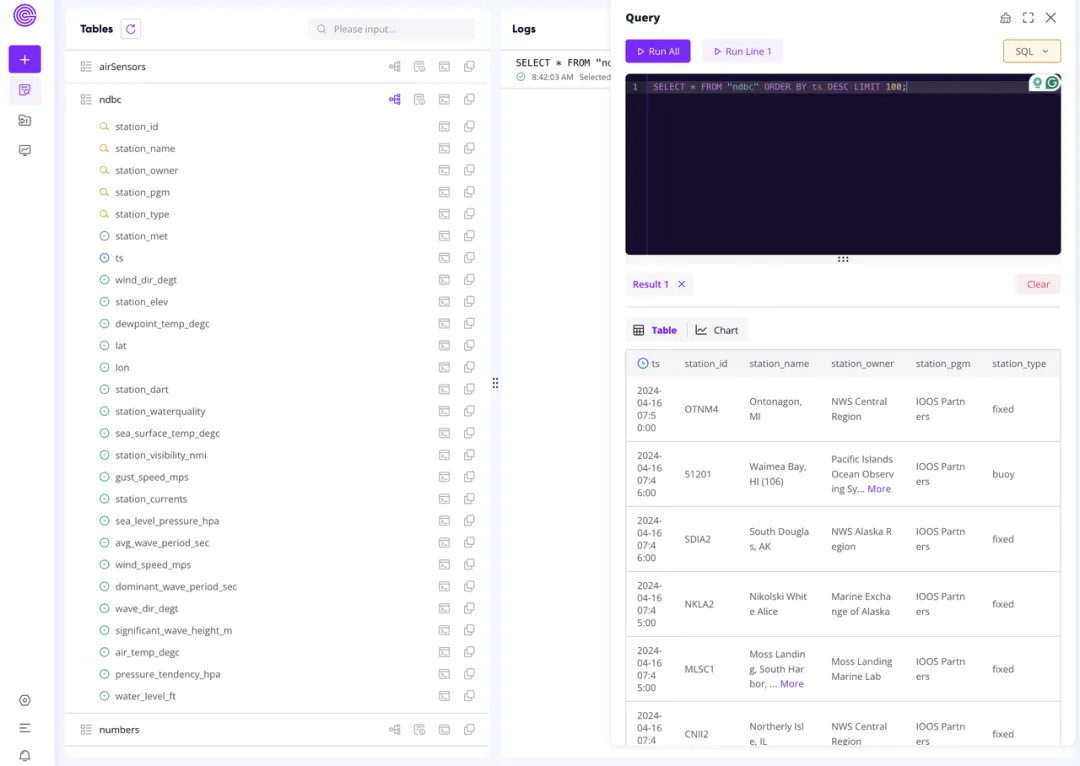
附录:启动并配置 InfluxDB v2 服务
本节展示了如何启动一个 InfluxDB v2 服务器并准备示例数据。
首先进入到一个空目录,并运行以下 Docker 命令启动一个名为 influxdb2 的新容器:
shell
docker run \
-p 8086:8086 \
-v "$PWD/data:/var/lib/influxdb2" \
-v "$PWD/config:/etc/influxdb2" \
--name influxdb2 \
influxdb:2然后,执行 setup 命令以初始化凭证:
shell
export USERNAME=tison
export PASSWORD=this_is_a_fake_passwd
export ORGANIZATION=my-org
export BUCKET=example-bucket
docker exec influxdb2 influx setup \
--username $USERNAME \
--password $PASSWORD \
--org $ORGANIZATION \
--bucket $BUCKET \
--token this_is_a_token \
--force现在,你可以创建并执行导入样例数据的任务:
shell
cat <<END > task.flux
import "influxdata/influxdb/sample"
option task = {
name: "Collect NOAA NDBC sample data",
every: 15m,
}
sample.data(set: "noaa")
|> to(bucket: "example-bucket")
END
docker cp task.flux influxdb2:/task.flux
docker exec influxdb2 influx task create --org my-org -f task.flux
# 确认任务 ID 并配置环境变量
docker exec influxdb2 influx task list
export TASK_TD=<task-id>
# 手动触发任务执行,每 15 分钟任务将被执行一次
docker exec influxdb2 curl -H "Authorization: token this_is_a_token" -X POST http://localhost:8086/api/v2/tasks/$TASK_TD/runs
# 检测任务是否完成
docker exec influxdb2 influx task run list --task-id=$TASK_TD
# 确保样例数据已经导入
docker exec influxdb2 influx query 'from(bucket:"example-bucket") |> range(start:-1d)'关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack

