
本页内容
响应查询请求时,数据库通常需要从存储引擎中检索出满足查询条件的数据行。在未进行优化的情况下,执行方法往往将扫描所有文件,以寻找符合条件的数据行。
这种方法效率很低。为了提升查询速度,开发者通常会从以下两个角度优化系统性能:一是减少查询工作量,例如减少需要扫描的文件数量和行数;二是增强计算能力,例如实施多任务并行处理或提升机器的运算能力。
本文将深入探讨专为大规模时序数据设计的数据库 GreptimeDB 中的索引技术及其在提高查询性能中的关键作用,重点介绍 GreptimeDB 如何通过使用 MinMax 索引和 0.7 版本新引入的倒排索引来减轻查询工作量,从而提升查询性能。
数据存储结构
首先,我们需要了解 GreptimeDB 数据存储结构的基本情况。GreptimeDB 的存储引擎会将属于同一个 Region 的时序数据分成多个文件存储。每个文件内部可以存储数百万至数十亿行时序数据,数据行由 Tag 列、Timestamp 列和 Field 列组成。在文件内部,数据行首先按 Tag 列进行排序,随后依据 Timestamp 列排序。不同文件中的 Tag 列和 Timestamp 列可能会有重叠。

MinMax 索引简单高效的数据排除策略
MinMax 索引基于一个简单的原理:记录每组数据中的最大值和最小值。当查询条件超出这些极值时,该组数据可以被直接排除,避免不必要的扫描。
在 GreptimeDB 的存储结构中,MinMax 索引被应用于两个层次:首先是 Region 级别,这里记录了每个文件的 Timestamp 列的最小值和最大值;其次是文件级别,这里记录了每个 Row Group 内所有列的最小值和最大值。
当查询条件包含对 Timestamp 的具体要求时,Region 级别的 MinMax 索引能有效地帮助排除不符合时间条件的文件。在文件扫描过程中,文件级的 MinMax 索引可以迅速地判断并跳过那些不满足条件的 Row Group,极大地减少了需要进一步检查的数据行数量。这种策略在实际应用中已被证明能够满足大多数时序数据查询的需求,尤其是当 Tag 列的排序得到恰当安排时,对首个 Tag 列和 Timestamp 列的查询过滤表现出色。
尽管 MinMax 索引在多个场景中表现良好,但仍存在一些局限性:
过滤粒度相对较粗:即使只有极少数数据行满足查询条件,存储引擎还是需要读取整个 Row Group,也就是说,需要处理 102400 行数据。降低 Row Group 的容量可以调细过滤粒度,从而改善这一局面,但这种做法会增加 Row Group 的数量,对元数据管理造成额外压力。
索引过滤能力有限:MinMax 索引在处理排列有序的数据行时,主要优化效果集中在首列。从第二列开始,列值越来越不规则,MinMax 索引的过滤效果逐渐减弱。
为了解决这些问题,GreptimeDB 在 0.7 版本中引入了一种新的索引结构——倒排索引,以弥补 MinMax 索引的不足。
倒排索引精确定位和高效过滤
设计文档:https://github.com/GreptimeTeam/greptimedb/blob/main/docs/rfcs/2023-11-03-inverted-index.md
通过采用倒排索引,GreptimeDB 的存储引擎在减少扫表工作量方面取得了显著进展,特别是在特定查询场景下,查询性能有时能够提升数倍。倒排索引的优势主要体现在两方面:
索引信息更精确:倒排索引为每个 Tag 列记录了该列值在文件中的分布位置;
过滤粒度更细:倒排索引的分布单位是更小的 Segment,其默认大小仅为 1024 行。
相较于 MinMax 索引,倒排索引提供了更细粒度和更高精度的数据过滤能力。我们先看一个应用不同索引带来的性能差异对比,然后介绍倒排索引的实现细节。
性能对比
本节通过对无索引、MinMax 索引与倒排索引三种状态下的性能展开对比,聚焦于 TSBS single-groupby-5-8-1 场景,下图展示不同索引策略在扫描行数、扫描 Row Group 数量及平均响应时间方面的表现差异。
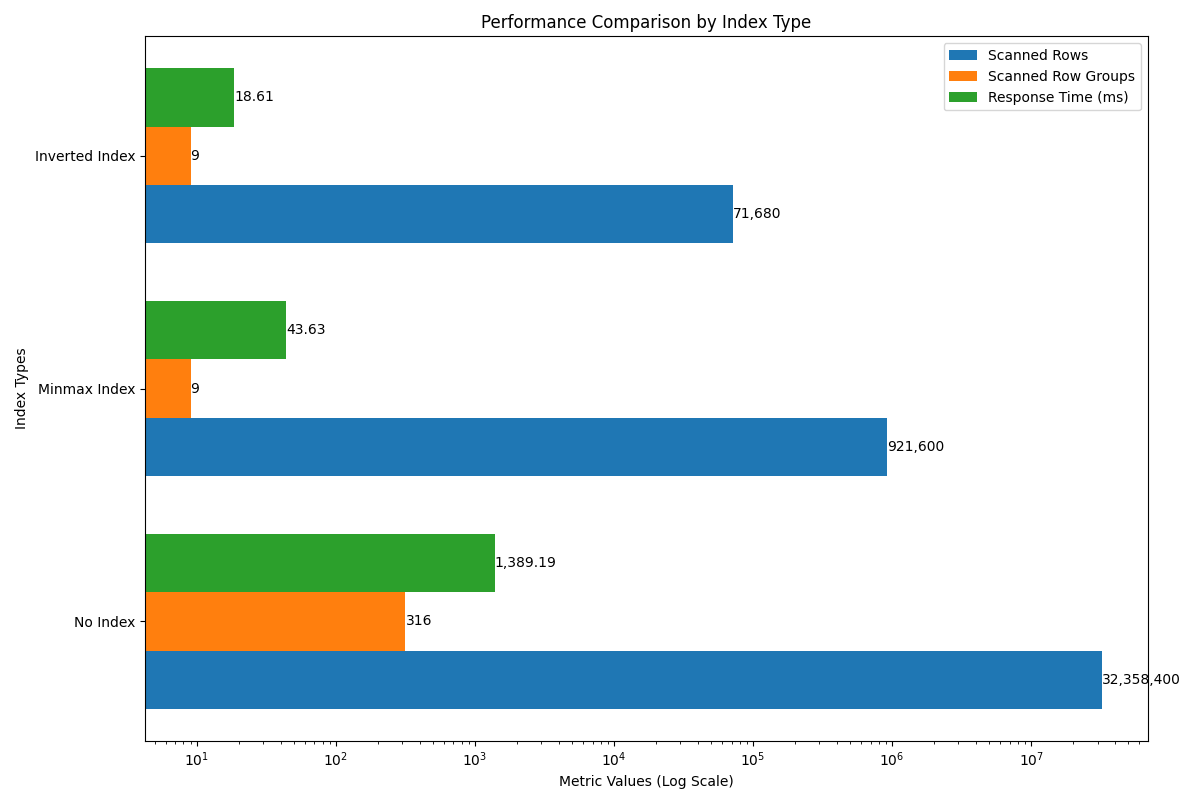
通过这个图表,我们可以直观地看到不同索引策略的性能差异,其中倒排索引表现最好。
倒排索引的详细实现
具体来说,GreptimeDB 的倒排索引是在文件级别建立的,它为文件中的每个 Tag 列构建了独立的索引,从而能够高效地处理针对任意 Tag 列的查询。相较于只在第一个 Tag 列显示显著过滤效果的 MinMax 索引,倒排索引显著扩展了索引的适用范围。此外,倒排索引采用了 FST (Finite State Transducer) 技术,这是一种将键映射到值的高效数据结构,广泛用于索引构建以实现快速数据检索。FST 支持单点查询、范围查询、正则表达式搜索和模糊搜索等多种操作,使得倒排索引在处理复杂查询时表现出强大能力,并在多种查询场景中展现明显性能优势。
与以 Row Group 为过滤单位的 MinMax 索引不同,倒排索引采用了可调整大小的 Segment,索引粒度的选择直接影响过滤效果和索引存储成本。在控制索引存储成本的前提下,GreptimeDB 将 Segment 大小设置为 1024 行,这一粒度是 Row Group 的百分之一,使得在大多数情况下,倒排索引的查询性能优于 MinMax 索引。
在实际实现中,存储引擎为数据文件中的各个 Tag 列分别构建了从 Tag 列值到 Segment 编号列表的映射。这些映射使用 FST 数据结构,其中列值作为键,而 Segment 编号列表则以位图形式存储作为值。执行查询时,存储引擎通过查询条件搜索 FST,获取 Segment 编号列表,随后仅读取相应的 Segment,极大地减少了需要扫描的数据量。
未来展望
组合索引
为了提高涉及多列查询的性能,GreptimeDB 将探索组合倒排索引。这种索引将多个 Tag 列的值合并为一个复合键,从而提供更精确的数据过滤。尽管这会增加构建和存储的成本,但通过按需构建索引,即仅针对频繁使用的列组合创建索引,可以有效控制资源消耗。
全文索引
GreptimeDB 计划引入针对特定列的全文索引,以提供日志场景的查询能力。用户将能够执行基于关键字的搜索,快速定位到日志中的特定条目。
关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack

