
本页内容
对运维团队来说,必须将可观测性指标的检测作为网络和应用中的优先事项,才能深入了解出现的问题,并为未来的扩展和支持做好准备。在之前《可观测场景的下的语义规范》一文中,我们用 V 模型将可观测性的方法分为三个层次:
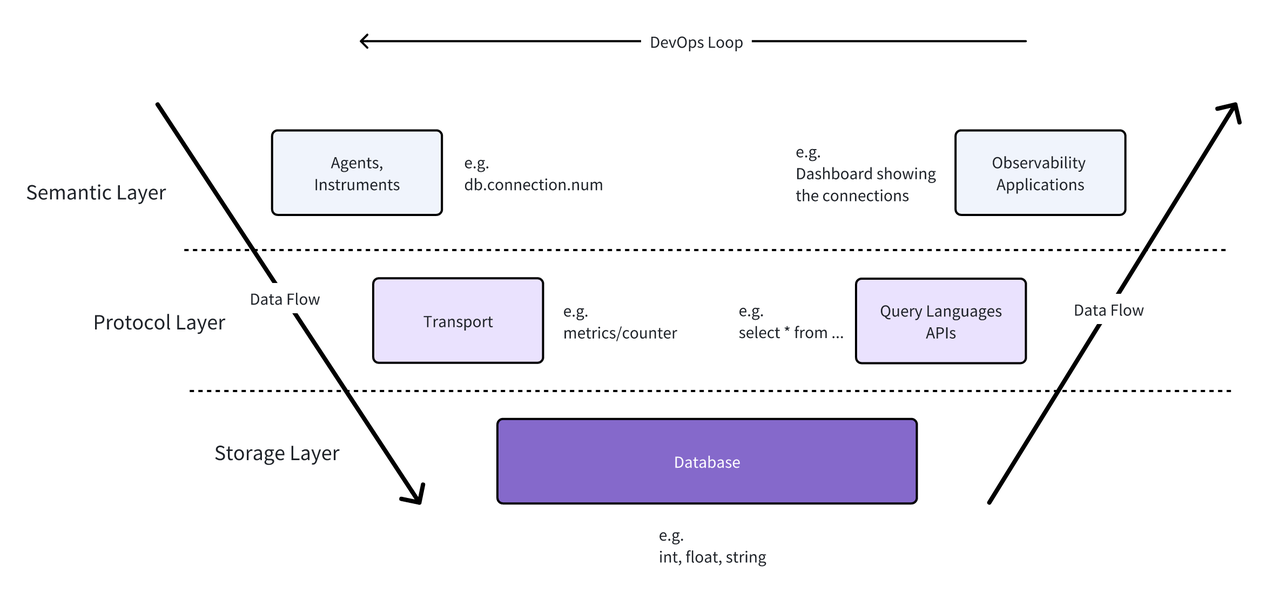
- 语义层:这个层次关注的是如何确定需要收集的数据,以及如何理解所收集的数据。主要包括:
- 定义有意义的指标和事件;
- 建立告警阈值和规则;
- 设计仪表盘和可视化工具;
- 实施标记和标签策略,以便根据组织定义的语义事件轻松分类数据。
- 协议层:这个层次专注于数据如何传输和通信。主要包括:
- 选择合适的数据传输协议;
- 实施数据序列化格式(如 JSON、Protocol Buffers);
- 使用API和SDK,促进存储层与语义层之间的数据路由。
- 存储层:这个层次处理的是如何存储和检索可观测性数据。主要包括:
- 为组织的具体用例选择合适的数据库;
- 确定数据模型以适应所使用的数据类型;
- 管理数据压缩和归档;
- 确保数据的持久性和备份策略;
- 优化智能索引,以实现最佳的读写性能。
目前,OpenTelemetry 主要聚焦于协议层,它并不规定具体要存储什么或如何处理这些数据,而是更关注数据的格式以及如何在各层之间传输。
OpenTelemetry 是什么
**OpenTelemetry (OTel) 是一套开源标准,用于基于可观测性数据或信号来监控应用程序或网络的健康状况。**这些数据分为三种不同的类型:指标(Metrics)、日志(Logs)和追踪(Traces)。
简而言之,指标和日志能帮助理解问题是什么以及在哪里发生,而追踪数据(Traces)则有助于关联这些事件,以识别它们何时以及按什么顺序发生。这些信号提供了系统健康状况的全貌,使运维人员能够确保网络顺畅运行。OpenTelemetry 特别擅长服务于分布式系统,能够提供跨应用程序和主机的连续上下文,将跨应用程序和主机的系统事件对齐,从而为复杂系统提供清晰的洞察。这样,运维团队能够更清晰地理解问题是什么,哪里发生,以及何时发生。
尽管 OpenTelemetry 与开源生态中许多其他流行的应用程序和框架有很多重叠之处,OTel 通过定义一套供应商中立的协议标准和接口,强烈体现了其开源理念。得益于这种透明性和可组合性,OTel 在可观测性领域得到了广泛采用。
那么,运维团队究竟如何使用这些不同的数据信号类型来确保其网络的健康呢?下面我们来逐个分析:
指标数据 (Metrics)
指标数据包括描述与应用程序健康状况相关的某些性能、基准或统计数据的定量数据,一些例子包括:
- 特定接口接受的字节数;
- 某个服务返回 HTTP 500 错误的次数;
- 在给定时间间隔内的内存使用率;
- 服务运行某个进程时遇到的超时次数。
指标数据可以按用户定义的方式聚合和导出,帮助团队了解事件发生的详细信息,并允许团队调用回退机制以确保系统的稳定性。例如,团队可能会捕获一个指标,如磁盘使用率,以了解给定存储节点上的可用容量,并在使用率超过某个给定阈值时触发数据清除机制。
日志数据(Logs)
**日志是最早帮助开发人员了解代码中发生情况的监控工具。**日志为开发人员提供了一种简单的、非结构化的方式,从运行中的进程中发出消息,以提供更多有关代码过程和状态的上下文。
大多数开发人员会使用其所选语言中的知名日志库来辅助开发过程。OTel 决定支持旧有的日志解决方案,通过添加桥接组件或在数据进入 OTel 收集器的过程中进行转换,将这些日志扩展为 OTel 支持的日志数据格式。这意味着即使使用的是旧版的日志记录工具或系统,OTel 也能通过这些扩展或转换机制来兼容并处理这些日志数据,从而将其整合到 OpenTelemetry 的系统中。这为团队开始使用 OpenTelemetry 提供了一个更简单的入门过程。
Traces
**追踪数据记录了一个请求在分布式系统中流经各种服务和组件的过程。**它们有助于跟踪单个请求的路径和性能,从而帮助运维人员更容易地识别出卡点或错误出现的地方。
Traces 由 Span 组成,每个跨度代表系统中的一个操作或工作单元,比如数据库查询、HTTP 请求或函数执行等。跨度通常按照父子层级结构组织起来,其中一个父跨度可以有一个或多个子跨度。这种结构有助于描绘请求在系统中不同组件之间的流动路径,帮助识别请求经过了哪些组件,以及这些组件是如何相互关联的。
一个典型的 Trace 数据样例如下:
json
{
"trace_id": "4bf92f3577b34da6a3ce929d0e0e4736",
"spans": [
{
"span_id": "6e0c63257de34c92",
"parent_span_id": null,
"name": "GET /api/v1/users",
...
},
{
"span_id": "9a92f9a757bb43e1",
"parent_span_id": "6e0c63257de34c92",
"name": "Cache lookup",
"start_time": "2024-08-24T10:23:45.125Z",
"end_time": "2024-08-24T10:23:45.128Z",
"attributes": {
"cache.hit": true,
"cache.key": "user_123456"
},
"events": [],
"links": []
}
]
}核心组件
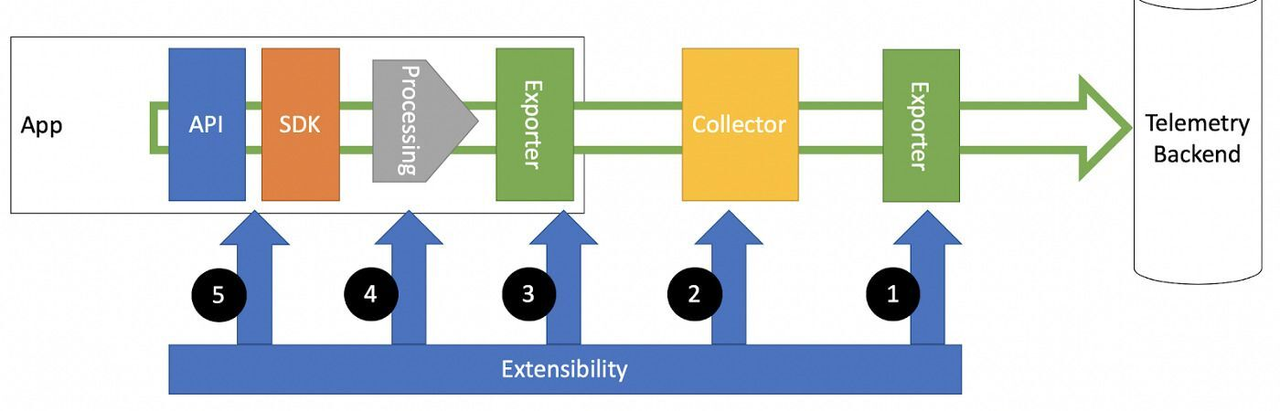
Source: Lumigo(https://lumigo.io/opentelemetry/)
如前所述,OpenTelemetry 是中立的供应商。它提供规范、标准和核心组件,并允许他人根据需要使用这些内容。OpenTelemetry 生态系统的一些关键组件包括:
API:OpenTelemetry API 为应用程序提供了一种标准化的方式来生成遥测数据。它是特定于编程语言的,并提供了创建跨度(spans)、添加属性(attributes)、以及管理上下文(context)的接口。
- 关键实现:Java、Python、Go、JavaScript、.NET、Ruby、PHP、Rust、C++
SDK:SDK 基于 API,并提供了额外的功能,如采样、批处理和导出遥测数据。它是可配置和可扩展的,可满足各种用例。
- 著名的 SDK:OpenTelemetry SDK(官方)、Jaeger SDK、Zipkin SDK
Collector:OpenTelemetry 收集器是一个供应商中立的代理,可以接收、处理和导出遥测数据。它支持多种输入和输出格式,使其更容易与各种后端和数据源集成。
- 关键组件:OpenTelemetry 收集器(官方)、Jaeger 收集器、Fluent Bit
Instrumentation Libraries:这些是特定语言的库,自动为常见的框架和库生成遥测数据,而无需更改应用程序代码。
- 示例:Spring Boot、Django、Express.js、ASP.NET Core 的自动化库
Exporters:导出器是插件,用于将收集的遥测数据发送到各种后端或分析工具。它们支持不同的协议和数据格式。
- 常见的导出器:Prometheus、Jaeger、Zipkin、Datadog、New Relic、Splunk、Elasticsearch
Propagators:这些组件负责跨服务边界传播上下文(如跟踪和跨度信息),实现分布式追踪。
- 常见传播器:W3C Trace Context、B3 Propagator、Jaeger Propagator
Semantic Conventions:OpenTelemetry 定义了一套语义约定,用于命名和结构化遥测数据,确保不同实现和语言之间的一致性。
- 关键领域:HTTP、数据库、消息传递、FaaS、异常
这些核心组件相互配合,提供了一个全面的可观测性解决方案,这个方案可以适应不同的环境,并与可观测性生态系统中的各种工具进行集成。每个组件都有多种实现和集成方式,这表明 OpenTelemetry 标准在整个行业中的灵活性和广泛应用。
示例实现
下面是一个简单的应用程序,说明不同组件如何协同工作:
python
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.instrumentation.flask import FlaskInstrumentor
from opentelemetry.propagate import set_global_textmap
from opentelemetry.propagators.b3 import B3MultiFormat
from opentelemetry.sdk.resources import SERVICE_NAME, Resource
from flask import Flask
import requests
# 1. API & SDK
tracer_provider = TracerProvider(
resource=Resource.create({SERVICE_NAME: "example-service"})
)
trace.set_tracer_provider(tracer_provider)
# 2. Exporter
otlp_exporter = OTLPSpanExporter(endpoint="http://localhost:4317")
span_processor = BatchSpanProcessor(otlp_exporter)
tracer_provider.add_span_processor(span_processor)
# 3. Propagator
set_global_textmap(B3MultiFormat())
# 4. Instrumentation
app = Flask(__name__)
FlaskInstrumentor().instrument_app(app)
tracer = trace.get_tracer(__name__)
@app.route("/")
def hello():
with tracer.start_as_current_span("make-request") as span:
span.set_attribute("custom.attribute", "example value")
response = requests.get("https://api.example.com")
span.set_attribute("response.status_code", response.status_code)
return "Hello, World!"
if __name__ == "__main__":
app.run(debug=True)要运行示例流程,你需要运行一个 OpenTelemetry Collector,它可以作为一个独立的 Docker 镜像或可执行文件来执行。下面是一个示例 Docker 配置的样子:
python
version: "3"
services:
otel-collector:
image: otel/opentelemetry-collector:latest
command: ["--config=/etc/otel-collector-config.yaml"]
volumes:
- ./otel-collector-config.yaml:/etc/otel-collector-config.yaml
ports:
- "4317:4317" # OTLP gRPC receiver
- "4318:4318" # OTLP HTTP receiver
- "8888:8888" # Prometheus metrics exposed by the collector
- "8889:8889" # Prometheus exporter metrics
- "13133:13133" # Health check extension通过执行上述 Docker 文件,并挂载类似于下面的配置文件,可以让 Python 进程将其数据导出到这个目标,例如 otel-collector-config.yaml。
python
receivers:
otlp:
protocols:
grpc:
processors:
batch:
exporters:
logging:
loglevel: debug
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [logging]在这个数据收集过程中有许多不同的部分,很容易让使用者感到困惑。因此写了这篇简短的介绍,讲述了 OpenTelemetry 的不同组件以及它们如何协同工作。在接下来的几期文章中,我们将深入探讨如何使用 OpenTelemetry 构建一个更强大的可观测性管道。
关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack

