
本页内容
GreptimeDB 是一款云原生的高性能时序数据库,旨在为用户提供灵活的时序数据管理解决方案。
统一处理时序数据
在处理数据时,我们不仅关注传统的指标(Metrics),还将时间戳和上下文信息的整合视为关键要素。无论是事件**(Events)、日志(Logs),还是 Traces**,GreptimeDB 都能够实现对这些时序数据的统一管理与处理。这种统一化的管理方式使你能够轻松整合和分析各种数据类型,进而全面监控系统状态,最大化数据的价值。
sql
SELECT
time,
host,
approx_percentile_cont(latency, 0.95) RANGE '15s' as p95_latency,
count(error) RANGE '15s' as num_errors,
FROM
metrics INNER JOIN logs on metrics.host = logs.host
WHERE
time > now() - INTERVAL '1 hour' AND
matches(path, '/api/v1/avatar')
ALIGN '5s' BY (host) FILL PREV从你熟悉的协议开始
GreptimeDB 支持多种协议进行时序数据的写入和查询。无论你习惯使用 SQL、Prometheus、InfluxDB 还是 OpenTSDB 协议,GreptimeDB 都能无缝适配,确保数据写入流程的平稳过渡。此外,GreptimeDB 提供了 SQL 和 PromQL(Prometheus Query Language)用于数据查询,带来了灵活而强大的数据检索能力。无论你的需求如何,GreptimeDB 都能满足并帮助你快速上手,轻松管理时序数据。
无处不在的时序数据
GreptimeDB 的强大之处在于其灵活的部署能力。它不仅可以在云端运行,还能部署在边缘端,充分利用边缘计算的算力优势。通过在数据生成源头处理数据,GreptimeDB 能够显著减少数据传输量,最多可节省 97% 的带宽消耗。这一设计使得海量数据的写入无需经过冗长的 Pipeline,直接提升了系统的吞吐量。
云原生 & 无惧规模
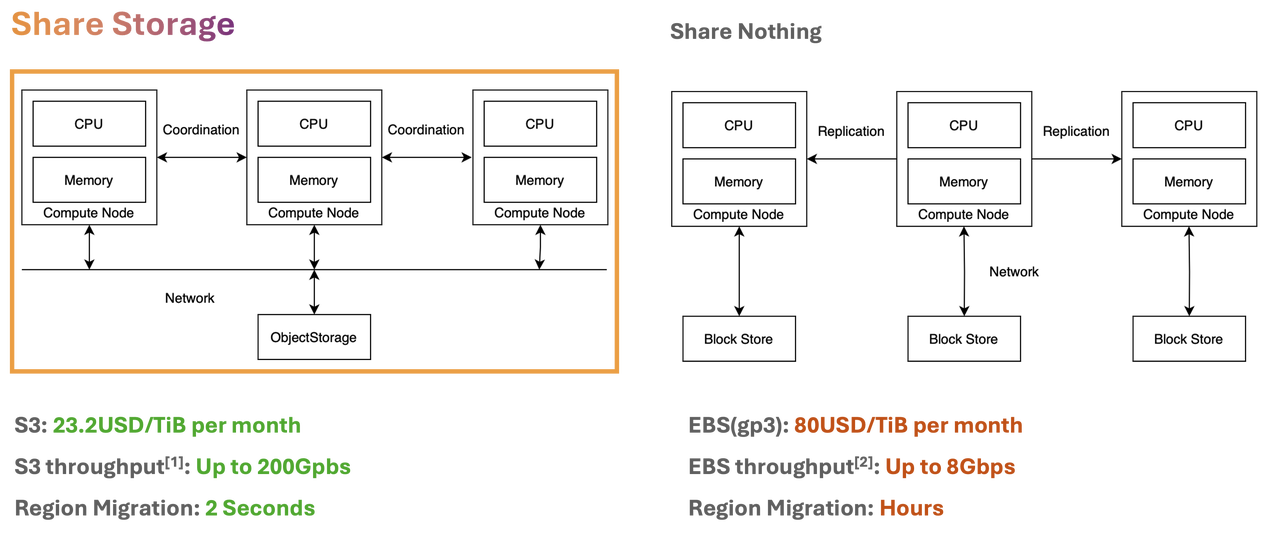
GreptimeDB 的架构设计充分发挥了云原生的优势,采用共享存储架构,将 S3 作为共享存储介质。相比 EBS (gp3),S3 只需 1/4 的成本,却能在单台计算资源上提供至高 200Gbps 的吞吐能力。这种架构设计大幅降低了存储成本,同时在大规模数据处理场景下依然表现出色。此外,共享存储架构使得分区迁移的效率得到了极大的提升,从传统的 Share Nothing 架构中耗时数小时的迁移时间缩短到秒级,甚至百毫秒级别,确保系统的零停机时间和业务的连续性。
模块化设计
从零开始构建一个数据库系统是一个复杂且庞大的工程,涉及多个关键组件的实现,如 Catalog、SQL 解析器、数据类型系统、WAL、数据存储、优化器和查询引擎等。每个组件的开发都需要投入大量资源和时间。

然而,软件工程的发展趋势正朝着模块化设计的方向发展。正如编译器的发展史所示,LLVM 的出现使得诸如 Swift 和 Rust 等新编程语言能够共享其后端,极大地促进了技术的快速迭代与共享。类似地,通过模块化的组件设计,数据库系统的开发可以显著加速,并提升系统的灵活性。
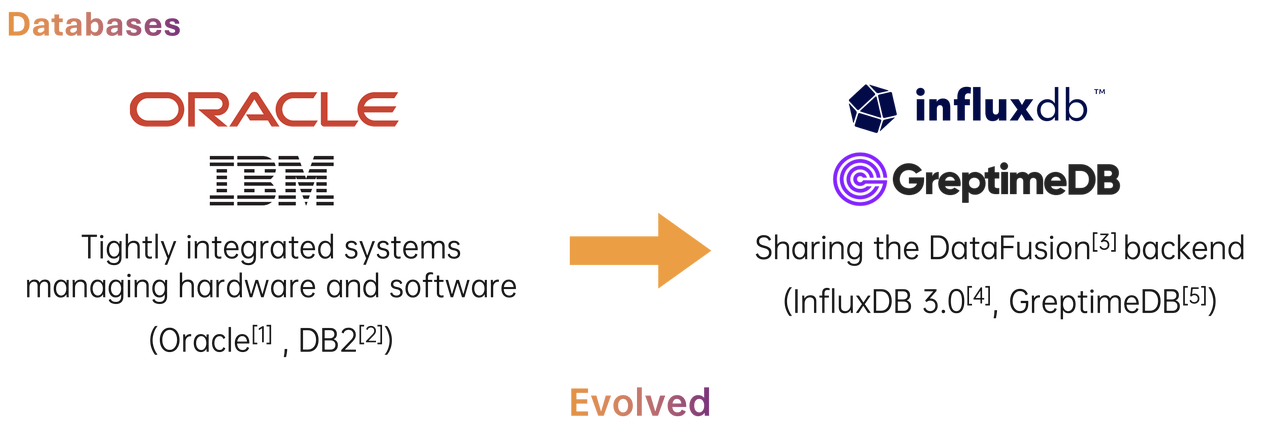
基于 ASF 开源项目构建时序数据库
在构建我们的时序数据库系统时,我们使用了以下关键的 Apache 开源项目:
- Apache Arrow::提供了一种高效的内存列式格式,支持快速的随机访问和内存中数据处理。
- Apache DataFusion:是一个快速、可嵌入且可扩展的查询引擎。它提供了 SQL 和 DataFrame APIs,并使用 Apache Arrow 作为其内存模型,确保高效的数据处理和查询性能。
- Apache OpenDAL:提供了统一的数据访问层,简化了不同数据源的集成和管理。
- Apache Parquet:一种列式存储格式,用于高效地存储和读取大规模数据集。
- Apache Kafka(可选):用作 Remote WAL,支撑秒级分区迁移。
扩展 SQL
在时序数据处理中,常常需要查询和聚合特定时间范围内的数据。然而,通用的 SQL 语言在原生支持时序查询方面存在局限。为了解决这一问题,GreptimeDB 引入了扩展的 SQL 语法,使时序查询与 SQL 的灵活性相结合,增强了对时序数据的原生支持。
sql
SELECT
ts,
avg(temp) RANGE '1d' FILL LINEAR.
FROM
temperature
WHERE
city="beijing" and ts < 1682985600000
ALIGN '1d';在 GreptimeDB 中,我们为 SELECT 语句引入了 ALIGN 关键字,用于设置时序查询的步长,并将时间对齐到日历上。同时,RANGE 关键字用于指定数据聚合的范围。对于空值的数据点,FILL LINEAR 提供了通过数据平均值填充缺失数据的功能。这些扩展功能使得时序查询变得更加灵活和高效。
支持 PromQL
为了兼容 Prometheus 生态系统,GreptimeDB 实现了整套 PromQL 查询支持,这是目前第三方独立实现中兼容程度最高的(高达 82%)。我们将 PromQL 作为一种新方言集成到 DataFusion 的执行引擎中,使得 GreptimeDB 在 Prometheus 生态中能够更好地服务用户需求。
轻松支持多云
GreptimeDB 使用了 Apache OpenDAL 作为数据访问层,通过统一的 API 接入大多数现有存储服务(支持绝大数的对象存储服务,例如 AWS S3,Google Cloud Storage, 阿里云 OSS)。通过开源协作,我们与社区一道,优化 OpenDAL 的读写性能,确保其能够充分利用对象存储服务的网络带宽,提升数据处理的效率。

与开源同行
我们始终致力于与开源社区共同成长。GreptimeDB 的核心开发者夏瑞航(Ruihang Xia)已成为 Apache DataFusion 项目的 PMC 成员,积极参与并推动社区的发展。此外,我们将 datafusion-orc 库捐赠给了 datafusion-contrib 组织,并计划在近期将该项目捐赠给 Apache,作为 ORC 的 Rust 实现仓库 (datafusion-orc#120)。这些努力不仅推动了 GreptimeDB 的发展,也为开源生态的繁荣贡献了一份力量。
实现一次,惠及全局
开源社区的魅力之一在于,在上游项目中实现一次改进,下游的所有项目都能从中受益。例如,受到学术论文的启发,我们为 OpenDAL 贡献了并发上传功能,使得写入性能实现线性增长。这不仅提升了 GreptimeDB 的性能,也让其他依赖 OpenDAL 的项目同样受益,真正体现了“实现一次,惠及全局”的理念。
愿开源与你同在
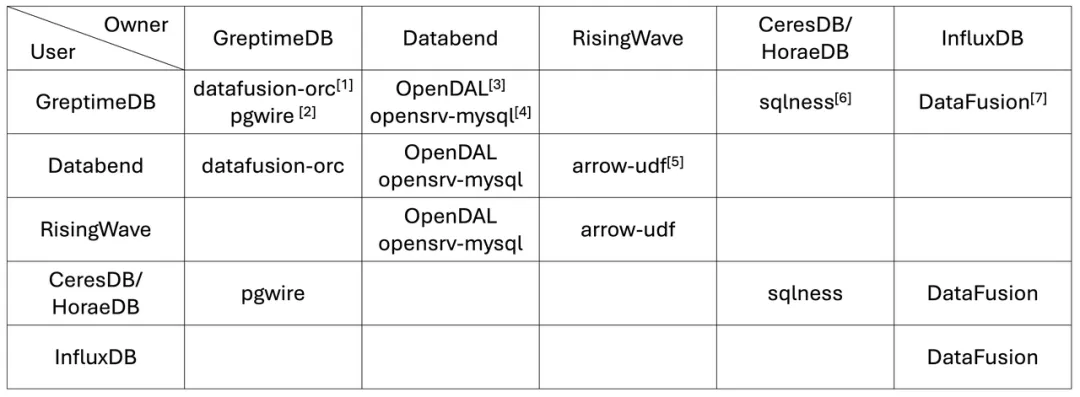
在今天的开源社区中,各个项目之间相互依存、互相贡献,形成了“你中有我,我中有你”的紧密关系。多个由不同社区贡献的开源项目已经在各个生态系统中被广泛采用,体现了开源世界中的合作精神和共享价值观。例如:
- GreptimeDB 贡献了
datafusion-orc和pgwire项目。datafusion-orc被 Databend 采用,而pgwire则被 CeresDB/HoraeDB 使用。 - 由 Databend 主导了
OpenDAL和opensrv-mysql项目。OpenDAL 已在多个社区中被广泛采用,包括 Vector、ParadeDB、QuestDB、RisingWave 和 GreptimeDB,同时opensrv-mysql也被 GreptimeDB 使用。 - RisingWave 贡献了
arrow-udf项目,该项目不仅用于 RisingWave 自身,还被 Databend 采用。 - CeresDB/HoraeDB 主导的
sqlness项目,该项目也被 GreptimeDB 使用。 - 由 InfluxDB 开源的
DataFusion项目,该项目在多个社区中被广泛采用,包括 GreptimeDB 和 CeresDB/HoraeDB。
结语
在这个飞速发展的技术时代,构建和管理时序数据库不仅是技术的挑战,更是一次与全球开发者共同探索与创新的旅程。GreptimeDB 通过灵活的架构设计、强大的协议支持,以及对开源社区的深度参与,展示了现代数据库系统的无限可能。无论是在云端还是边缘,无论是数据存储还是查询优化,我们始终坚持模块化和开源的理念,与全球开发者一起,推动技术的进步。
Reference
[1] S3 throughput : Dominik Durner, Viktor Leis, and Thomas Neumann. 2023. Exploiting Cloud Object Storage for High-Performance Analytics. Proc. VLDB Endow. 16, 11 (July 2023), 2769–2782. https://doi.org/10.14778/3611479.3611486
[2] EBS throughput: https://docs.aws.amazon.com/ebs/latest/userguide/ebs-volume-types.html
[3] IBM System / 390: https://en.wikipedia.org/wiki/IBM_System/390
[4] Solaris: https://en.wikipedia.org/wiki/Oracle_Solaris
[5] LLVM: https://llvm.org
[6] Swift: https://www.swift.org
[7] Rust: https://www.rust-lang.org
[8] Oracle: https://www.oracle.com/database/
[9] DB2: https://www.ibm.com/db2
[10] InfluxDB: https://www.influxdata.com
[11] GreptimeDB: https://greptime.com
[12] sunng87/pwrire: https://github.com/sunng87/pgwire
[13] datafuselabs/opensrv: https://github.com/datafuselabs/opensrv
[14] risingwavelabs/arrow-udf: https://github.com/risingwavelabs/arrow-udf
[15] ceresdb/sqlness: https://github.com/CeresDB/sqlness
[16] apache/arrow: https://arrow.apache.org/
[17] apache/datafusion: https://datafusion.apache.org/
[18] apache/opendal: https://opendal.apache.org/
[19] apache/parquet: https://parquet.apache.org/
[20] apache/kafka: https://kafka.apache.org/
[21] datafusion-contrib/datafusion-orc: https://github.com/datafusion-contrib/datafusion-orc
[22] GreptimeDB/promql-parser: https://github.com/GreptimeTeam/promql-parser
[23] datafusion-contrib/datafusion-orc#120: https://github.com/datafusion-contrib/datafusion-orc/issues/120
[24] apache/opendal#3942: https://github.com/apache/opendal/pull/3942
关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack

