本页内容
在搭建监控体系时,如何高效地将应用的监控数据从数据源传输到目标存储位置,是一个不可回避的关键任务。市面上有许多用于采集和传输监控数据的开源工具,例如 Grafana 系的 Alloy,InfluxDB 系的 Telegraf,如果再算上专为日志采集设计的 Fluentd,Logstash 等老牌工具,就更数不胜数了。
然而,在 Greptime,我们的首选工具非 Vector 莫属。也许其中有我们同为 Rust 出身的缘故,但更重要的是,Vector 在功能、性能和易用性方面的出色表现,尤其是它同时支持日志、指标和追踪三种类型的监控数据。此外,Vector 提供了丰富的内置数据源,更是我们喜爱它的理由。
从 GitHub 仓库的历史记录来看,Vector 项目诞生于 2018 年,至今已有 6 个年头。尽管在 2021 年被 Datadog 收购,但从项目发展上看并没有因此受到影响。实际上,Vector 已经成为 Datadog 一款 Observability Pipeline 商业化产品的核心组成部分,但开源项目依然保持独立运营,持续发布新版本。
基本概念
Vector 将整个流程抽象为数据源(Source)、可选的数据处理(Transform)和数据目的地(Sink)三个模块。在数据类型方面,Vector 将所有可观测数据统一抽象为 Event ,包含了指标(Metric)和日志(Log)两大类。其中 Metric 又进一步细分为 Gauge 、Counter 、Distribution、Histogram 和 Summary 等类型,这些分类与 Prometheus 中的概念十分相似,这里就不多做展开了。
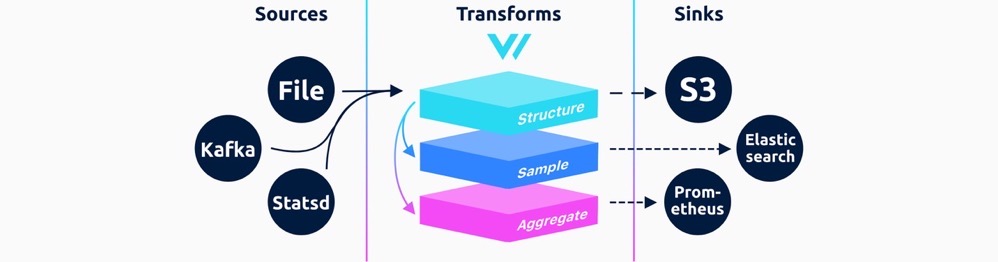
目前,Vector 支持 50 多种 Log 和 Metric 类型的数据源,以及约 15 种数据目的地。此外,一些通用的数据格式,协议数据源和数据目的地使得用户能够轻松集成更多类型的工具。在数据处理环节,Vector 还内嵌了一个 VRL 映射表达式,用户可以通过它定义灵活的数据转换逻辑。
在内部实现上,Vector 引入了端到端的确认机制、多次重试策略和本地缓冲的机制,以确保数据传输的可靠性。在对数据完整性有严格要求的场景,用户可以用 Vector 组合可靠的数据目的地,来达成可靠传输和存储的目的。
采集指标
当使用 Vector 采集指标数据时,用户拥有多种选择,几乎可以满足任意场景下的指标采集和传输需求。以下是几个典型场景的示例:
Prometheus 用户
例如,对于拉模型的 Prometheus 用户来说,Vector 提供两种配置方式:
如果使用 Prometheus Agent 模式,那么 Vector 本身就可以被配置为 Prometheus 的 scrape 服务;
如果使用多个 Prometheus 实例,也可以通过 Remote Write 的方式将数据统一写到 Vector 中进行处理,再发往下游。
以下是一个简单的配置示例,用于抓取本机 9100 端口的 Prometheus Exporter 数据:
# sample.toml
[sources.prom]
type = "prometheus_scrape"
endpoints = [ "http://localhost:9100/metrics" ]推模型用户
对于推模型的用户,比如 Influxdb 系的用户,可以利用 Vector 的 http_server 数据源及 line protocol 解码能力,在 Vector 里启动一个 http 服务器,供产生 Metrics 的应用程序将数据推送到 Vector 。类似地,Vector 目前也支持了 OpenTelemetry 的 OTLP 协议,因此也可以将 Vector 看作一个 OpenTelemetry Collector 来对接更广泛的标准生态。
内置指标采集工具
Vector 内置了一些指标(Metric)采集的工具,可以直接从系统或常见的数据库等软件上采集指标数据,类似于内置了 Prometheus 的一系列 Exporter。
所有的数据源,无论来源是 Prometheus ,InfluxDB 还是特定的软件,Vector 内部都会对数据结构进行统一抽象。这种设计允许数据源和数据目的地之间形成多对多关系,完全兼容并适配各种场景,从而实现源到目的地的数据格式转换。
下面是一个简单的 Vector 配置示例,用于从当前运行的主机上采集 CPU、内存等性能数据,并将其写入到 GreptimeDB 时序数据库中:
# sample.toml
[sources.in]
type = "host_metrics"
scrape_interval_secs = 30
[sinks.out]
inputs = ["in"]
type = "greptimedb"
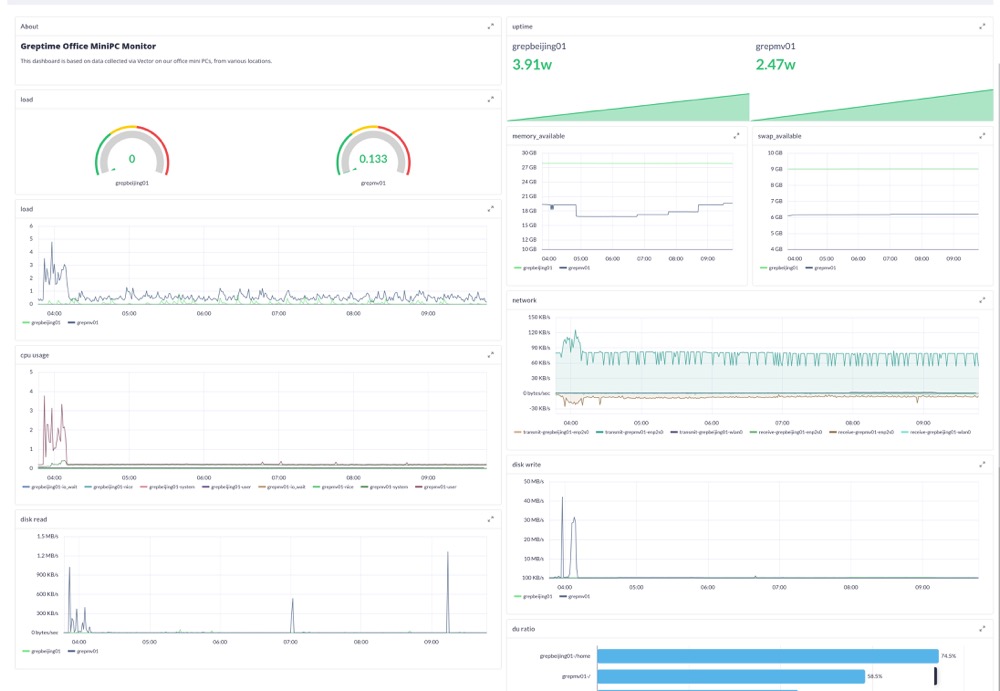
endpoint = "localhost:4001"配置完成后,用户可以利用 Grafana 或 Perses 等可视化工具,直接创建 Dashboard 来直接观察这些指标数据:
采集日志
除了指标数据,Vector 的另一个主要功能是采集和搬运日志类型的数据。在 Vector 中,日志既可以是结构化的键值对,也可以是原始的文本行。
以下是一个以 Nginx 访问日志为例的配置示例:
通过 Vector 跟踪本地日志文件,并利用 Vector 提供的 transform 机制解析 Nginx 访问日志为结构化键值对。
python
[sources.file_source]
type = "file"
include = [ "/logs/the-access.log" ]
[transforms.nginx]
type = "remap"
inputs = ["file_source"]
source = '''
. = parse_nginx_log!(.message, "combined")
'''将 Vector 部署在产生日志的机器上,未结构化的日志数据会被标准化为键值对结构,例如:
python
{
"custom": "field",
"host": "my.host.com",
"message": "Hello world",
"timestamp": "2020-11-01T21:15:47+00:00"
}与指标一样,日志在 Vector 内部也遵循标准化的键值对结构。
未结构化的原始日志在 message 字段,通过 transform 环节解析出来的数据字段会展现在此 JSON 结构的第一层。这个结构会整体传送给日志的目的地,并根据不同目的地的规则特点序列化或落盘。
持久化日志
持久化日志数据只需要配置一个兼容日志的数据目的地即可。这里以 GreptimeDB 作为日志目的地为例:
python
[sinks.sink_greptime_logs]
type = "greptimedb_logs"
table = "ngx_access_log"
pipeline_name = "demo_pipeline"
compression = "gzip"
inputs = [ "nginx" ]
endpoint = "http://greptimedb:4000"由于我们配置了 transform 环节,这里的 inputs 设置为 transform 节点的名称即可。
示例代码与可视化
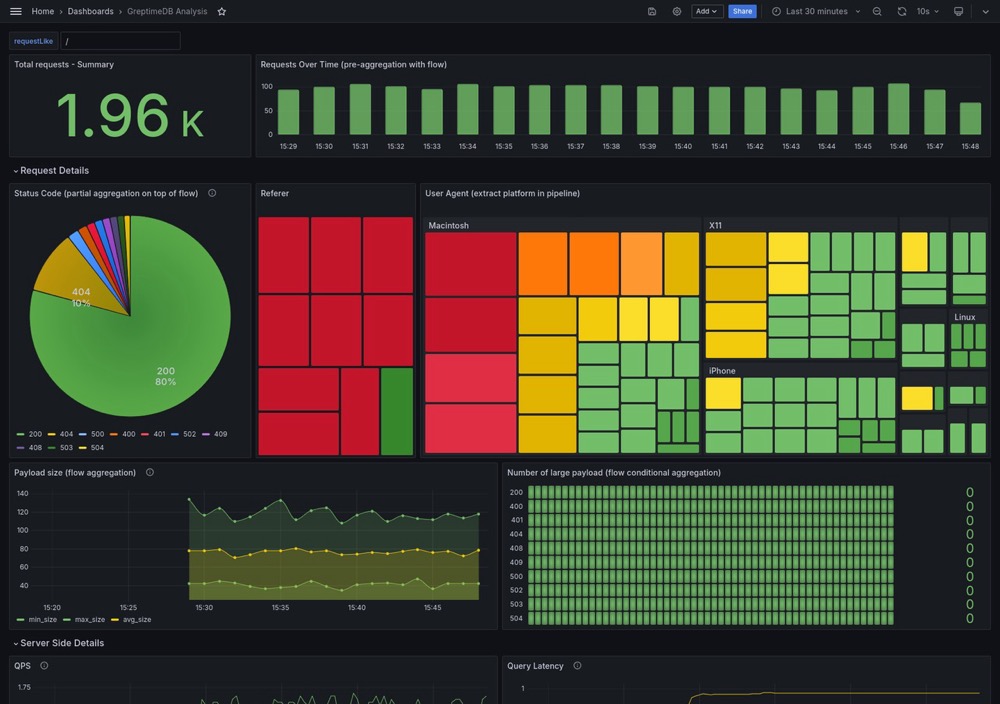
如果你对这个流程感兴趣,我们在 GitHub 示例项目 中提供了完整的配置和流程说明。该项目展示了如何通过 Vector 采集 Nginx 访问日志,并将其传输至 GreptimeDB 进行持久化存储和可视化分析。
从日志数据源中提取指标
在 Vector 中,日志和指标数据可以通过 transform 环节或数据源的解码环节实现相互转化。例如,在一些场景中,我们使用 Kafka 来传输文本编码的 influxdb line protocol 数据,并且在 Vector 内部直接完成解析,然后将文本的 Kafka 消息转化成指标数据,最终存储到 GreptimeDB 或 InfluxDB 这样的时序数据库中。
以下是一个简单的配置示例,其中 decoding.codec 参数已经完成了数据格式的转换配置,因此可以直接使用一个指标目的地来接收这类数据(这里配置了 GreptimeDB 作为目的地):
python
[sources.metric_mq]
type = "kafka"
group_id = "vector0"
topics = ["test_metric_topic"]
bootstrap_servers = "kafka:9092"
decoding.codec = "influxdb"
[sinks.sink_greptime_metrics]
type = "greptimedb"
inputs = [ "metric_mq" ]
endpoint = "greptimedb:4001"在该配置中:
数据源 **
metric_mq:**从 Kafka 的test_metric_topic消费消息,并使用 InfluxDB 格式解码;**数据目的地
sink_greptime_metrics:**将解析后的指标数据写入 GreptimeDB。
我们也在 GreptimeDB 的 demo 仓库里提供了完整的示例代码,展示了如何利用 Vector 消费 Kafka 上的可观测数据,并将其存储到 GreptimeDB 中。欢迎访问仓库了解详情。
下一步
本文介绍了 Vector 中的一些基本概念及常见配置示例,帮助初学者快速上手。在接下来的文章中,我们将深入探讨如何利用 Vector 的 transform 数据处理能力,对可观测数据做更复杂的处理。这意味着 Vector 不仅仅是一个可观测数据管道,还可以成为功能强大的数据清洗工具。
关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack

