
本页内容

引言
在现代应用程序架构中,数据的采集、处理和传输是保障系统高效运输的重要环节。随着数据量的激增,高效、灵活且可扩展的解决方案变得更加重要。
Vector 是一个开源的高性能数据收集和传输工具,能够在生产环境中提供出色的性能与可靠性。本文将探讨如何在生产环境中使用 Vector,以实现其高效的数据管道功能。
部署模式
分布式拓扑
在分布式拓扑中,可以在每个客户端节点上安装 Vector 代理。其中 Vector 直接在客户端节点与下游服务之间进行通信。在这种模式下,每个客户端节点都充当数据收集和转发的角色。Vector 代理会独立运行,处理来自本地资源(如应用程序日志、系统指标等)的数据。这种拓扑的设计理念是避免中间层,直接将数据传输到目标系统。
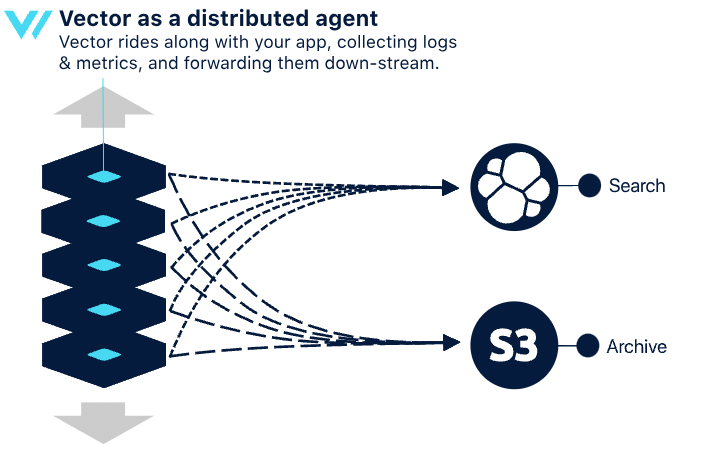
优点:
简单:结构简单,易于理解和实现。
弹性:可以随着应用的扩展,资源随着扩展而增长。
缺点:
效率较低:复杂的管道可能耗费更多资源,影响其他应用的性能。
耐久性差:由于数据缓存在主机上,可能在不可恢复的崩溃中丢失重要数据。
下游压力大:下游服务可能会收到更多小请求,影响其稳定性。
缺乏多主机上下文:缺乏对其他主机的感知,无法跨主机执行操作。
集中式拓扑
集中式拓扑在简单性、稳定性和控制之间取得了良好的平衡。在这种模式下,数据首先由客户端节点的 Vector 代理收集,然后发送到一个或多个集中式的 Vector 聚合器。这种架构通过集中管理和处理数据,提高了整体的效率和可靠性。
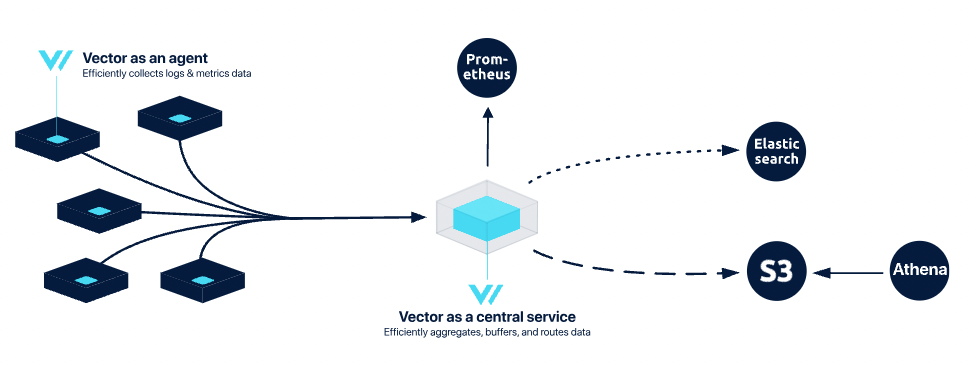
优点:
更高效:集中式服务缓冲数据,提供更好的压缩和优化请求,降低客户端节点和下游服务的负担。
更可靠:通过平滑的缓冲和刷新策略,保护下游服务免受流量峰值的影响。
多主机上下文:能够跨主机执行操作,适合大规模部署。
缺点:
更复杂:需要同时运行 Vector 的代理和聚合器角色,增加了管理复杂性。
耐久性差:如果中央服务发生故障,可能会丢失缓冲数据。
流式拓扑
这种拓扑通常用于需要高耐久性和弹性的环境,适合大型数据流的处理。在流式拓扑中,需要部署 Vector 代理来收集数据,并将其发送到流处理系统(如 Kafka)。配置文件应指定数据源、流处理的参数以及下游系统的连接。代理将数据转发到 Kafka,Kafka 再将数据分发给消费者。
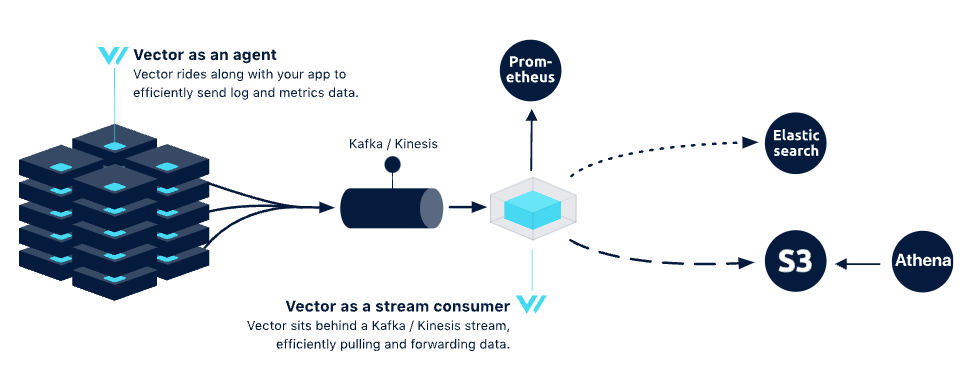
优点:
最耐用和可靠:流服务(如 Kafka)设计用于高耐久性,数据在多个节点间复制。
效率高:代理的负担较轻,能够专注于路由而不是耐久性。
重流能力:可以根据流的保留期重新流式传输数据。
缺点:
管理开销增加:需要有经验的团队来设置和管理流服务,增加了管理复杂性。
更复杂:需要深入理解生产级流的管理。
成本更高:除了管理成本,流集群的资源需求也会增加运营成本。
Vector API Modules
Vector 中的 API 模块提供了与外部系统交互的能力,支持多种操作和监控。这些 API 使用户能够方便地管理 Vector 实例,获取系统状态信息,并进行数据查询和配置管理。
Health Check API
设置 Vector 开启 API 和探针,用于检查 Vector 的健康状态,以确保实例处于可用状态。可以通过以下配置启用 API:
yaml
role: "Agent"
tolerations:
- operator: Exists
livenessProbe:
httpGet:
path: /health
port: api
readinessProbe:
httpGet:
path: /health
port: api
customConfig:
data_dir: /vector-data-dir
api:
enabled: true
address: 0.0.0.0:8686
playground: true
sources:
kubernetes_logs:
type: kubernetes_logs
sinks:
stdout:
type: console
inputs:
- kubernetes_logs
encoding:
codec: json获取 Vector 的 Health Status:
bash
curl 127.0.0.1:8686/health
{"ok":true}GraphQL API
Vector GraphQL API 允许用户与运行中的 Vector 实例通过 graphql endpoint 进行交互,它基于 GraphQL 语言提供灵活且高效的数据查询和操作方式。
请注意:只有启用了 playground endpoint,才会启用 graphql endpoint。
- 获取当前 Vector 配置
bash
curl -X POST http://127.0.0.1:8686/graphql \
-H "Content-Type: application/json" \
-d '{"query": "query { sources { edges { node { componentId componentType } } } sinks { edges { node { componentId componentType } } } }"}'
{"data":{"sources":{"edges":[{"node":{"componentId":"kubernetes_logs","componentType":"kubernetes_logs"}}]},"sinks":{"edges":[{"node":{"componentId":"stdout","componentType":"console"}}]}}}- 查询 Vector 版本信息
bash
curl -X POST http://127.0.0.1:8686/graphql \
-H "Content-Type: application/json" \
-d '{"query": "query { meta { versionString hostname } }"}'
{"data":{"meta":{"versionString":"0.42.0 (aarch64-unknown-linux-gnu 3d16e34 2024-10-21 14:10:14.375255220)","hostname":"vector-2p6ts"}}}Playground API
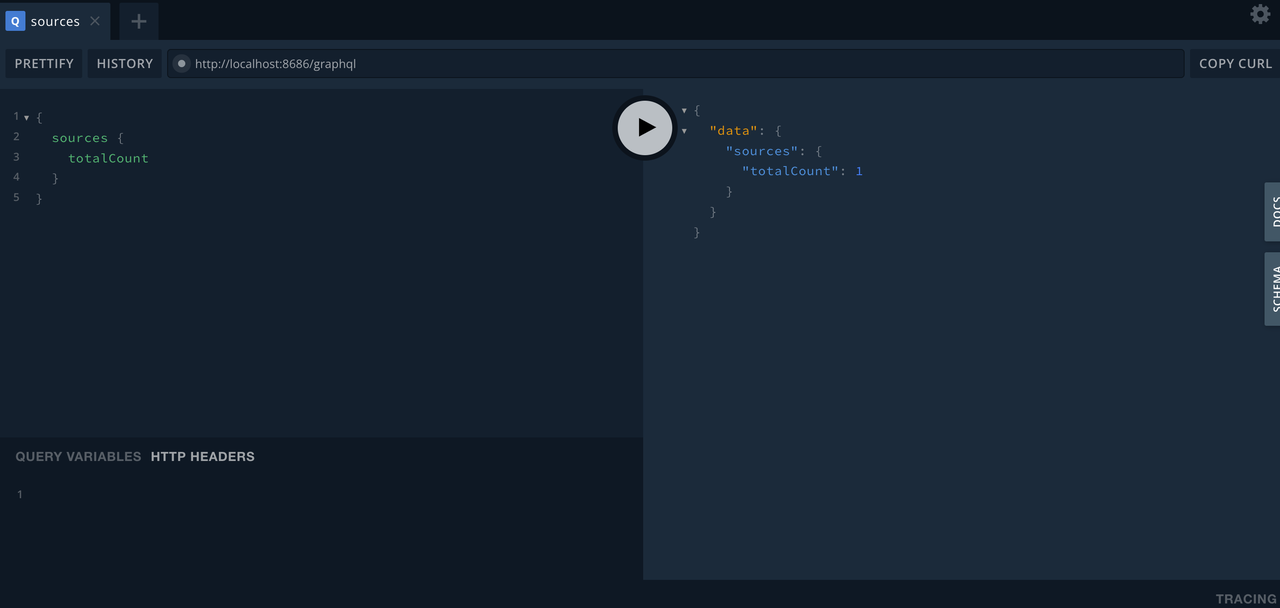
Vector Playground API 提供了一个用户友好的界面,可以输入一些条件来获取信息,通过访问 http://localhost:8686/playground 来访问:
Vector 自监控
指标(Metrics)
Vector internal_metrics source 用于收集和导出 Vector 自身的内部指标。这些指标可以帮助我们监控 Vector 的性能和健康状态:
yaml
role: "Agent"
tolerations:
- operator: Exists
service:
ports:
- name: prom-exporter
port: 9598
containerPorts:
- name: prom-exporter
containerPort: 9598
protocol: TCP
customConfig:
data_dir: /vector-data-dir
sources:
vector_metrics:
type: internal_metrics
scrape_interval_secs: 10
sinks:
prom-exporter:
type: prometheus_exporter
inputs:
- vector_metrics
address: 0.0.0.0:9598bash
curl 127.0.0.1:9598/metrics
# HELP vector_buffer_byte_size buffer_byte_size
# TYPE vector_buffer_byte_size gauge
vector_buffer_byte_size{buffer_type="memory",component_id="prom-exporter",component_kind="sink",component_type="prometheus_exporter",host="vector-xbw7f",stage="0"} 0 1731949489084
# HELP vector_buffer_events buffer_events
# TYPE vector_buffer_events gauge
vector_buffer_events{buffer_type="memory",component_id="prom-exporter",component_kind="sink",component_type="prometheus_exporter",host="vector-xbw7f",stage="0"} 0 1731949489084
# HELP vector_buffer_max_event_size buffer_max_event_size
# TYPE vector_buffer_max_event_size gauge
vector_buffer_max_event_size{buffer_type="memory",component_id="prom-exporter",component_kind="sink",component_type="prometheus_exporter",host="vector-xbw7f",stage="0"} 500 1731949489084
# HELP vector_buffer_received_bytes_total buffer_received_bytes_total
# TYPE vector_buffer_received_bytes_total counter
vector_buffer_received_bytes_total{buffer_type="memory",component_id="prom-exporter",component_kind="sink",component_type="prometheus_exporter",host="vector-xbw7f",stage="0"} 73519 1731949489084
...以下为指标(Metrics)参考:
| 指标名称 | 指标类型 | 描述 |
|---|---|---|
| adaptive_concurrency_averaged_rtt | Histogram | 当前窗口的平均往返时间 (RTT)。 |
| adaptive_concurrency_in_flight | Histogram | 当前等待响应的出站请求数量。 |
| adaptive_concurrency_limit | Histogram | 自适应并发功能为当前窗口决定的并发限制。 |
| adaptive_concurrency_observed_rtt | Histogram | 观察到的请求往返时间 (RTT)。 |
| aggregate_events_recorded_total | Counter | 聚合转换记录的事件数量。 |
| aggregate_failed_updates | Counter | 聚合转换遇到的失败指标更新和添加的数量。 |
| aggregate_flushes_total | Counter | 聚合转换完成的刷新次数。 |
| api_started_total | Counter | Vector GraphQL API 启动的次数。 |
| buffer_byte_size | Gauge | 当前缓冲区中的字节数。 |
| buffer_discarded_events_total | Counter | 非阻塞缓冲区丢弃的事件数。 |
| buffer_events | Gauge | 缓冲区中当前的事件数量。 |
| buffer_received_event_bytes_total | Counter | 缓冲区接收到的字节总数。 |
| buffer_received_events_total | Counter | 缓冲区接收到的事件总数。 |
| buffer_send_duration_seconds | Histogram | 发送负载到缓冲区所花费的时间。 |
| buffer_sent_event_bytes_total | Counter | 缓冲区发送的字节总数。 |
| buffer_sent_events_total | counter | 缓冲区发送的事件总数。 |
| build_info | Gauge | 构建版本信息。 |
| checkpoints_total | Counter | Checkpoint 文件数。 |
| checksum_errors_total | Counter | 通过校验和识别文件的错误总数。 |
| collect_completed_total | Counter | 组件完成的指标收集总次数。 |
| collect_duration_seconds | Histogram | 收集此组件的指标所花费的时长。 |
| command_executed_total | Counter | 执行命令的总次数。 |
| command_execution_duration_seconds | Histogram | 命令执行的持续时间(以秒为单位)。 |
| component_discarded_events_total | Counter | 组件丢弃的事件总数。 |
| component_errors_total | Counter | 组件遇到的错误总数。 |
| component_received_bytes | Histogram | 源接收的每个事件的字节大小。 |
| component_received_bytes_total | Counter | 组件从源接受的原始字节总数。 |
| component_received_event_bytes_total | Counter | 该组件从标记来源(如文件和 uri)或从其他来源累计接受的事件字节数。 |
| component_received_events_count | Histogram | Vector 内部拓扑中每个内部批次中传递的事件数量的直方图。 |
| component_received_events_total | Counter | 组件从标记来源(如文件和 uri)或从其他来源累计接受的事件数。 |
| component_sent_bytes_total | Counter | 组件发送到目标接收器的原始字节数。 |
| component_sent_event_bytes_total | Counter | 组件发出的事件字节总数。 |
| component_sent_events_total | Counter | 组件发出的事件总数。 |
| connection_established_total | Counter | 建立连接的总次数。 |
| connection_read_errors_total | Counter | 读取数据报时遇到的错误总数。 |
| connection_send_errors_total | Counter | 通过连接发送数据时的错误总数。 |
| connection_shutdown_total | Counter | 连接关闭的总次数。 |
| container_processed_events_total | Counter | 处理的容器事件总数。 |
| containers_unwatched_total | Counter | Vector 停止监视容器日志的总次数。 |
| containers_watched_total | Counter | Vector 开始监视容器日志的总次数。 |
| events_discarded_total | Counter | 组件丢弃的事件总数。 |
| files_added_total | Counter | Vector 监视文件总数。 |
| files_deleted_total | Counter | 删除的文件总数。 |
| files_resumed_total | Counter | Vector 恢复监视文件的总次数。 |
| files_unwatched_total | Counter | Vector 停止监视文件的总次数。 |
| grpc_server_handler_duration_seconds | Histogram | 处理 gRPC 请求所花费的时间。 |
| grpc_server_messages_received_total | Counter | 接收到的 gRPC 消息总数。 |
| grpc_server_messages_sent_total | Counter | 发送的 gRPC 消息总数。 |
| http_client_requests_sent_total | Counter | 发送的 HTTP 请求总数,按请求方法标记。 |
| http_client_response_rtt_seconds | Histogram | HTTP 请求的往返时间 (RTT)。 |
| http_client_responses_total | Counter | HTTP 请求的总数。 |
| http_client_rtt_seconds | Histogram | HTTP 请求的往返时间 (RTT)。 |
| http_requests_total | Counter | 组件发出的 HTTP 请求总数。 |
| http_server_handler_duration_seconds | Histogram | 处理 HTTP 请求所花费的时间。 |
| http_server_requests_received_total | Counter | 接收到的 HTTP 请求总数。 |
| http_server_responses_sent_total | Counter | 发送的 HTTP 响应总数。 |
| internal_metrics_cardinality | Gauge | 从内部指标注册表发出的指标总数。 |
| invalid_record_total | Counter | 被丢弃的无效记录总数。 |
日志(Logs)
Vector internal_logs 用于收集和处理 Vector 自身生成的内部日志,可以帮助我们了解 Vector 的运行状态,以及诊断故障问题等。
yaml
role: "Agent"
tolerations:
- operator: Exists
service:
ports:
- name: prom-exporter
port: 9598
containerPorts:
- name: prom-exporter
containerPort: 9598
protocol: TCP
customConfig:
data_dir: /vector-data-dir
sources:
vector_logs:
type: internal_logs
sinks:
stdout:
type: console
inputs:
- vector_logs
encoding:
codec: json告警
通过暴露 Vector 的 internal_metrics,可以获取 Vector 自身的指标并编写 Prometheus 规则实现告警。
- 发送中断
数据发送发生中断并持续一分钟后,则按规则判定为发送中断,将产生告警:
yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: vector-sink-down
spec:
groups:
- name: vector
rules:
- alert: "VectorSinkDown"
annotations:
summary: "Vector sink down"
description: "Vector sink down, sinks: {{ $labels.component_id }}"
expr: |
rate(vector_buffer_sent_events_total{component_type="${SINK_NAME}"}[30s]) == 0
for: 1m
labels:
severity: critical- 延时
系统计算最近五分钟的 95th 百分位延迟,如果大于 0.5 秒并且持续一分钟,则产生告警:
yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: vector-high-latency
spec:
groups:
- name: vector
rules:
- alert: "VectorHighLatency"
annotations:
summary: "High latency in Vector"
description: "The 95th percentile latency for HTTP client responses is above 0.5 seconds."
expr: |
histogram_quantile(0.95, rate(vector_http_client_response_rtt_seconds_bucket[5m])) > 0.5
for: 1m
labels:
severity: warning- 错误率
计算最近五分钟 HTTP 请求发生 5xx 错误率大于 5%并且持续两分钟,则产生告警:
yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: vector-high-error
spec:
groups:
- name: vector
rules:
- alert: "VectorHighERROR"
annotations:
summary: "High error rate in Vector"
description: "The error rate for HTTP client responses exceeds 5% over the last 5 minutes."
expr: |
rate(vector_http_client_responses_total{status=~"5.*"}[5m]) / rate(vector_http_client_responses_total[5m]) > 0.05
for: 2m
labels:
severity: warningVector 调试
日志级别
Vector 的 log level 默认为 info,支持的值为 trace、debug、info、warn、error 和 off。我们可以将其修改为 debug,并将日志格式化为 json:
yaml
role: "Agent"
tolerations:
- operator: Exists
logLevel: "debug"
env:
- name: VECTOR_LOG_FORMAT
value: "json"VRL 语法
Vector Remap Language (VRL) 是 Vector 中用于数据转换和处理的语言。它的设计目标是简化数据流的处理,使我们能够以更灵活和直观的方式操作数据管道。
通过访问 https://playground.vrl.dev/ ,可以检验 VRL 语法的正确性。
总结
Vector 是一个高效且灵活的数据处理工具,能够满足生产环境的复杂需求。它不仅支持多种数据源和目标,还提供丰富的转换功能,使得数据处理过程更加高效和简便。Vector 的实时监控和日志管理能力使得问题的定位和解决更加迅速。通过合理的配置和优化,可以显著提升数据管道的性能和可靠性,从而提升系统的可维护性和响应速度。
关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack

