本页内容
With the increasing prevalence of IoT devices in various industrial fields, the amount of data generated by these devices is also rapidly growing. For example, sensors, actuators, and connected machines are continuously collecting data about the environment, industrial equipment, and industrial processes in real-time. The data is often generated based on fixed time intervals, usually with a timestamp identifying the time when the data was generated, and is therefore called time-series data.
Time-series data is particularly important in industrial environments. It provides a historical perspective of how variables change over time, enabling trend analysis, anomaly detection, and predictive analysis. Industries can use this data to monitor performance, detect patterns, identify inefficiencies, and predict future events. However, the massive volume of data poses challenges to the traditional centralized cloud computing paradigm. Solutions that transmit all data collected by IoT devices to the cloud for storage and analysis cannot meet the requirements in terms of latency, cost, or scalability.
Considering all the factors mentioned above, it is imperative to analyze and store this data at the source. We will introduce how to address these challenges by deploying a time-series database at the edge, as well as illustrate the technical difficulties and solutions for edge time-series databases.
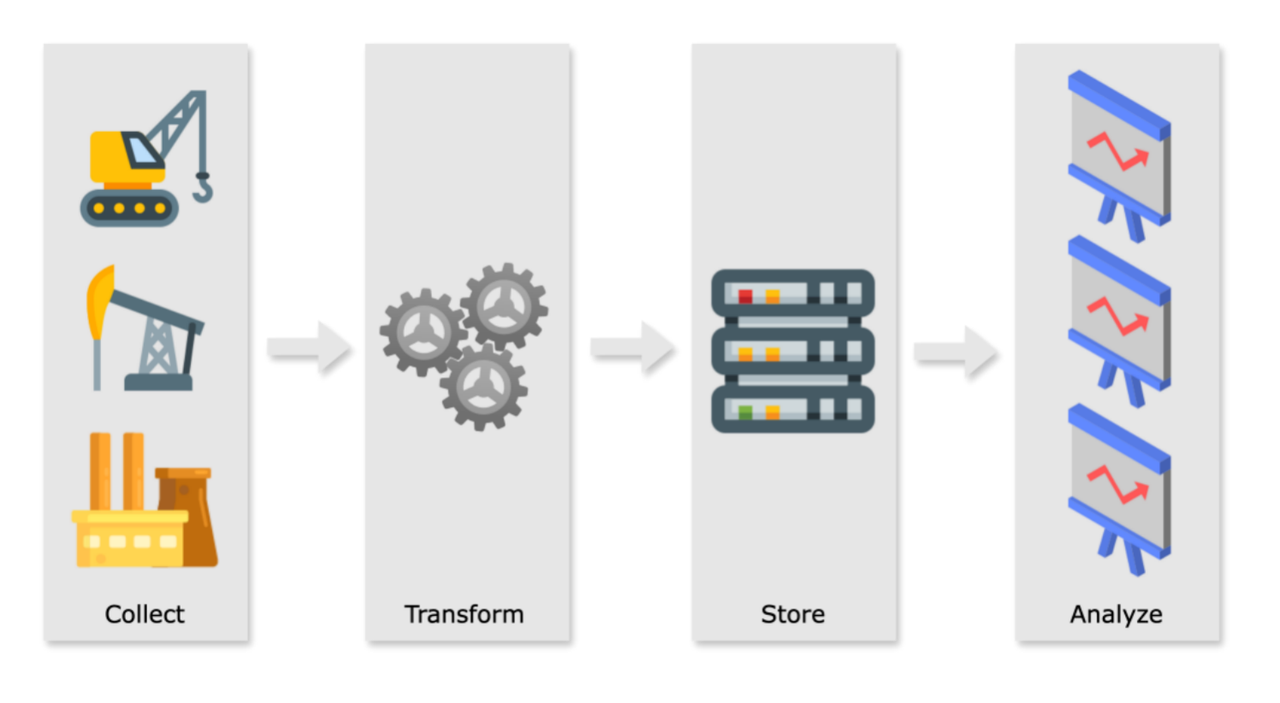
The Conflict Between Data Volume and Resource Limitations in Edge Environment
Even in edge scenarios, the number of connected devices is considerable. For example, in a modern cement production line, there can be thousands of sensors used to detect parameters such as temperature, pressure, liquid level, and flow rate at various stages of the production line. Furthermore, as the process requirements increase, the frequency at which these sensors collect data is also increasing, with some industries even requiring microsecond-level data acquisition frequencies. The combination of these two factors leads to ultra-high-volume data writing requirements.
Since edge scenarios do not have unlimited computing power provided by centralized cloud computing services, the strict power consumption and resource limitations have become one of the key challenges for edge databases.
The solution is to adopt a storage architecture design optimized for high-throughput writing, such as the LSM tree. Mainstream OLTP databases (such as MySQL and PostgreSQL) usually use B-trees and their variants. To ensure query performance, B-trees need to maintain tree balance, which can cause leaf node splits during each data write, affecting write performance. Therefore, they are more suitable for scenarios with high read performance requirements (especially point query performance).
On the other hand, LSM tree is a data structure that uses a write-optimized strategy, mainly composed of two parts: a write buffer in memory (called Memtable or Write Buffer) and multiple levels of persistent files on disk. Data is first written into the in-memory structure and then periodically flushed to disk by background processes in a merge and rewrite manner. Although LSM trees also require WAL (Write-Ahead Log) to ensure data reliability, WAL writes are basically sequential IO, which is more friendly to high-throughput write scenarios.
Even with LSM trees, each component needs to be carefully designed to meet the needs of edge computing. The available memory of edge devices is usually small; even high-end industrial control hosts often have only 2-16GB of memory, significantly smaller than the hundreds GB level of memory found in servers. Therefore, the data structure of the LSM tree's write buffer is extremely important for reducing the overall memory footprint of the database. The data structure typically used for write buffers is a BTree or SkipList, but these can experience severe memory bloat when faced with high-cardinality data writes due to the excessive number of keys.
Moreover, the overhead of the data structure itself cannot be ignored, which can lead to the actual memory usage far exceeding the threshold set by the user. Therefore, a more compact in-memory data structure needs to be designed for edge scenarios. For example, as shown in the figure below, a columnar in-memory data structure such as Apache Arrow is used, and the memory overhead of the key part is further reduced through dictionary encoding, time series merging, and other methods.
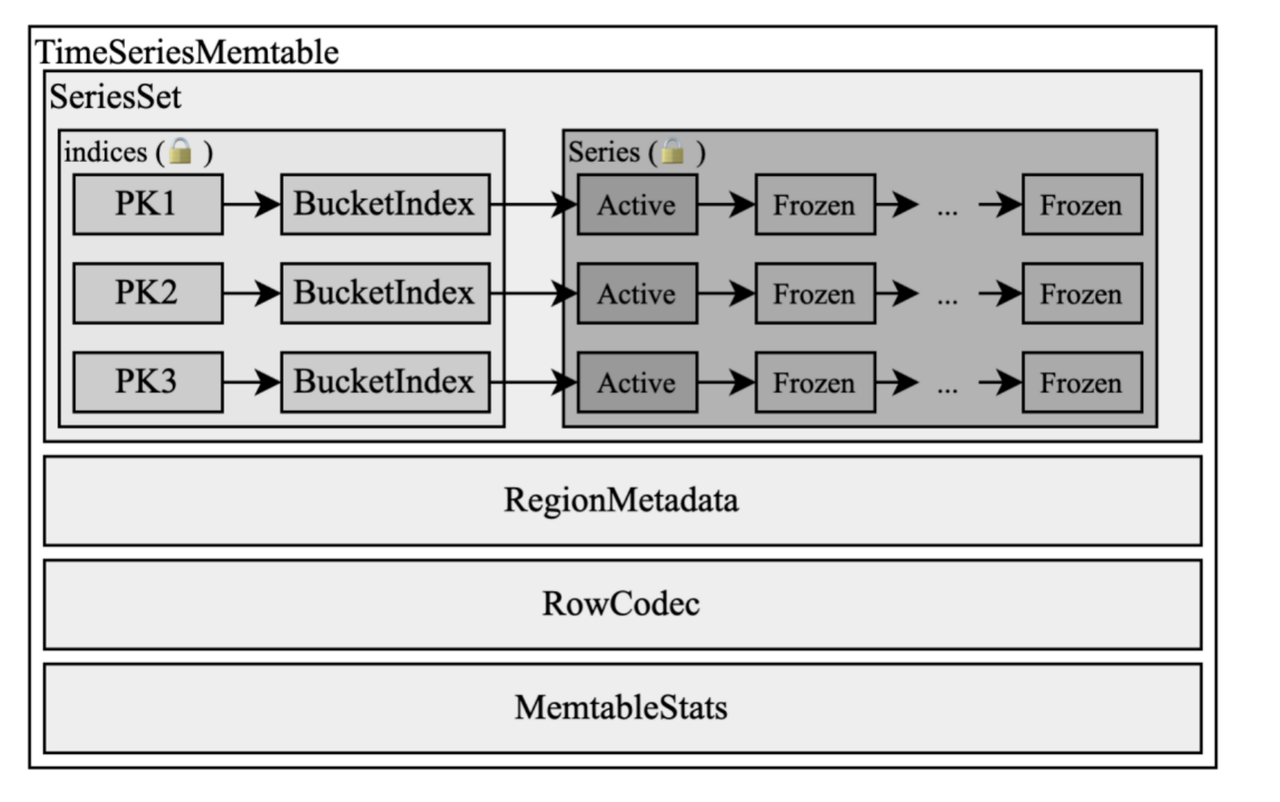
In addition to memory optimizations, a lot of optimization work needs to be done in terms of CPU resource usage to adapt to the limited computing resources of embedded environments. Data structures like LSM trees often require compaction tasks to organize the written data, thereby obtaining better query performance. When the amount of data is large, concurrently executed compaction tasks can consume a lot of CPU and IO resources, which can affect foreground tasks. Therefore, a reasonable task scheduling framework is needed to manage these background tasks.
Data Compression and Storage Optimization
When collecting massive amounts of IoT data, the storage space of edge devices often becomes a bottleneck, and infinitely increasing the storage space of devices often leads to unacceptable costs. Therefore, specific compression algorithms need to be used to compress the collected data.
Traditional row-oriented storage formats, such as JSON/CSV, can only use some general compression algorithms, such as Gzip and Zstandard. Although these compression algorithms have high compression rates, they also bring greater additional CPU overhead and cannot recognize the type and format of the data for targeted compression. In this scenario, columnar storage formats can often achieve better compression results.
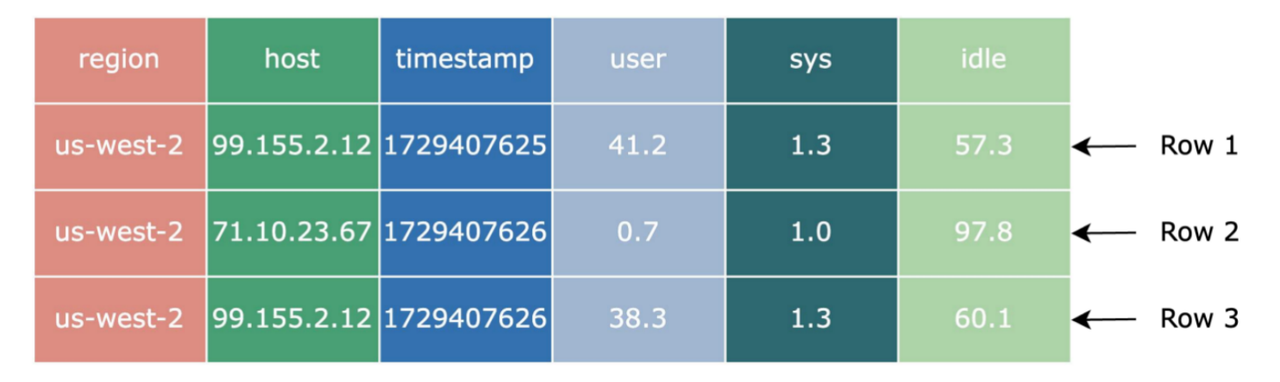
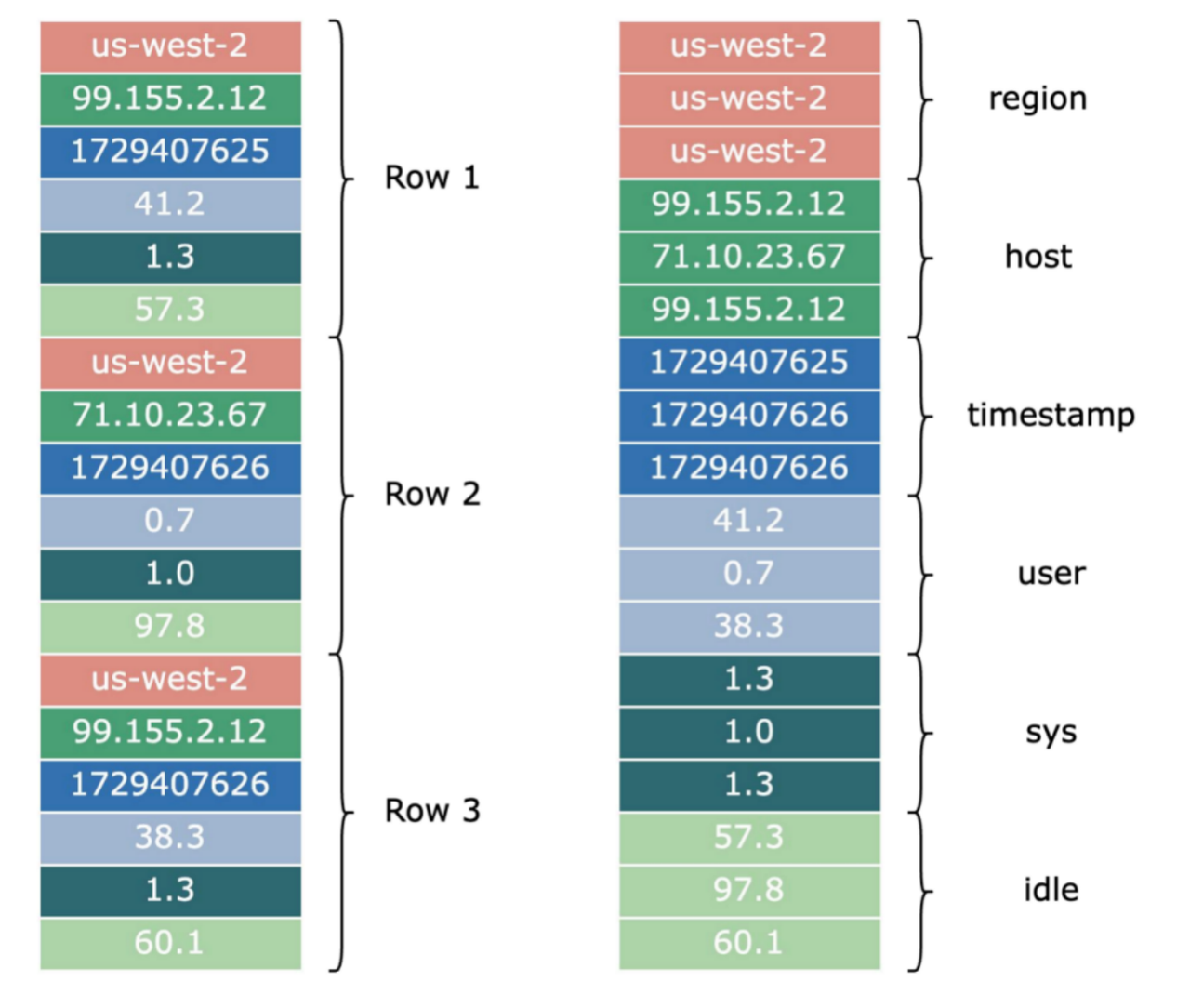
The figure above shows how the same set of data is stored in row and column formats. In row-oriented file formats, data from different columns in the same row is stored together; in column-oriented file formats, data from the same column in different rows is stored together.
Since data in the same column of different rows often has strong correlations, special methods can be used to encode it to reduce the data size. For example, for the region column in the figure above, we can use dictionary encoding. In the metadata dictionary at the beginning of the file, we encode us-west-2 as 0x00, so the region data changes from ["us-west-2", "us-west-2", "us-west-2"] to [0x00, 0x00, 0x00], thereby reducing the space occupied.
For timestamp, since it is basically monotonically increasing, we can use delta encoding, only recording 1729407625 for the first row, and recording the difference from the first row to the remaining rows, which can be encoded as [1729407625, +01, +01]. For floating-point numbers (float and double types), Gorilla encoding can be used to obtain better compression for floating-point numbers.
After encoding these different types, we can further compress them with Gzip or Zstandard to further reduce the file size, thereby using the limited storage capacity of the edge to cope with the massive data collection needs.
Synchronizing Edge Database with Cloud Data Lakes
After data is collected at the edge, it eventually needs to be aggregated in the cloud for further analysis and to generate final reports or decision actions. In traditional solutions, edge devices need to encode the collected data into a transmission format (such as Protocol Buffer) and upload it to the cloud. The cloud often deploys a cluster to parse the data uploaded and then store it in a data warehouse or data lake for BI analysis. When the amount of data expands rapidly, the overhead of edge encoding and cloud parsing becomes unbearable, and the data delay caused by cloud parsing becomes larger and larger, which affects the real-time performance of the data.
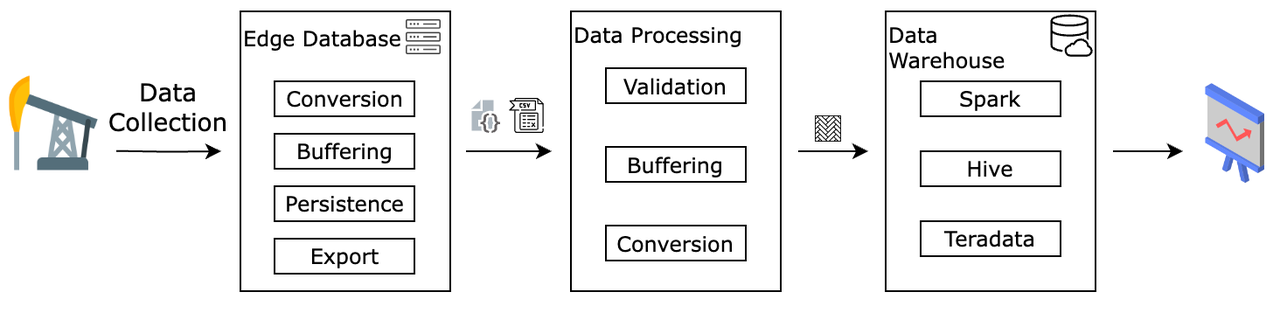
Therefore, a more efficient solution is to use the same file format at the edge and in the cloud, so that no file parsing is required, and cloud data analysis tools can directly use the data files collected at the edge. This places demands on the selection of edge databases, which must be able to support the data formats used by mainstream data warehouses.
Currently, GreptimeDB and IOTDB can achieve similar zero-parsing, zero-copy edge-cloud data synchronization.
Pushing Cloud Queries to the Edge for Lower Cost
In certain scenarios, the edge devices do not have the conditions for wired network access due to geographical location restrictions (such as offshore wind power plants), so they rely on mobile network traffic for uploading. So even with the support of various compression algorithms, the cost of uploading detailed data becomes unbearable. Therefore, it is necessary to be able to perform some filtering and aggregation operations at the edge, and even to be able to push cloud queries to the edge for execution.
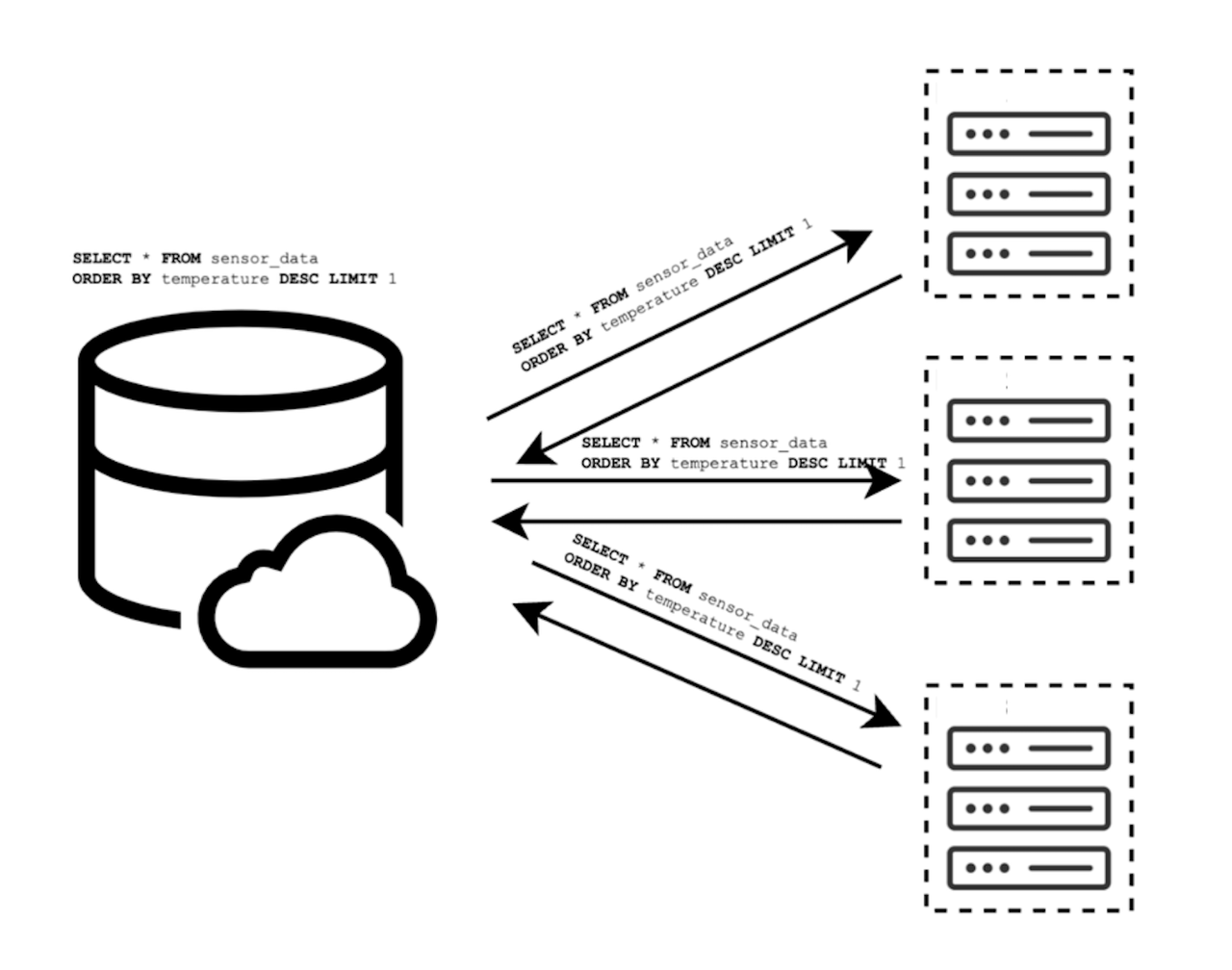
For example, execute the following query statement in the cloud:
sql
SELECT * FROM sensor_data
ORDER BY BY temperature DESC LIMITIn the original query mode, all edge device data needs to be uploaded to the cloud data warehouse before the final result can be obtained. In the edge-cloud integrated query, ORDER BY ... LIMIT 1 can be issued to the edge, and the embedded time-series database of each edge calculates the local result, and then returns this row of results to the cloud server.
In this solution, the amount of data uploaded from the edge to the cloud will be reduced from the full amount of data to a constant level, thereby greatly saving the traffic cost of uploading data without affecting the accuracy of the cloud analysis results. Of course, to achieve this effect, the edge data and the cloud database must have a certain degree of integrated analysis capabilities.
GreptimeDB Edge-Cloud Integrated Solution
Greptime's edge-cloud integrated solution is based on the architecture of GreptimeDB and is optimized for edge storage and computing requirements in IoT scenarios, successfully addressing the business challenges of IoT enterprises under the quick growth of data volume.
By seamlessly integrating a multi-modal edge database with the cloud-based GreptimeDB Enterprise Edition, the solution dramatically lowers overall costs related to data transmission, computation, and storage. Furthermore, it accelerates data processing, enhances business intelligence, and empowers IoT organizations with more agile and efficient data management, facilitating a faster data-to-decision lifecycle.
For more information, please visit the official website to download the edge-cloud integrated solution white paper: https://greptime.com/whitepaper/db
Overcoming IoT Data Challenges with Edge Databases
This article has explored the challenges that massive IoT data collection and analysis pose to edge time-series databases. These challenges include constraints on computing and storage resources, the need for efficient data compression, and the complexities of edge-cloud data synchronization and querying. We've examined solutions such as optimized data structures and storage architectures, flexible compression algorithms, zero-copy data synchronization, and integrated edge-cloud federated queries.
As new IoT use cases and requirements emerge, continuous innovation in data collection, synchronization, and analysis technologies will be crucial to unlock the full potential of the vast amounts of data generated by IoT devices.
About Greptime
Greptime offers industry-leading time series database products and solutions to empower IoT and Observability scenarios, enabling enterprises to uncover valuable insights from their data with less time, complexity, and cost.
GreptimeDB is an open-source, high-performance time-series database offering unified storage and analysis for metrics, logs, and events. Try it out instantly with GreptimeCloud, a fully-managed DBaaS solution—no deployment needed!
The Edge-Cloud Integrated Solution combines multimodal edge databases with cloud-based GreptimeDB to optimize IoT edge scenarios, cutting costs while boosting data performance.
Star us on GitHub or join GreptimeDB Community on Slack to get connected.

