
本页内容
测试结论
- 相比初次引入日志相关功能的 GreptimeDB v0.9,v0.12 在读写性能、资源占用方面得到了极大的优化,写入吞吐最高提高了 67.5%, 写入过程的 CPU 占用降低至 40%。
- 在日志写入场景下,无论结构化数据还是非结构化数据,GreptimeDB 都具备极高的写入吞吐,约为 **ClickHouse 的 111%,Elasticsearch 的 470%,**且使用低成本的对象存储时写入性能无明显下降。
- 在日志查询场景下,GreptimeDB 与 ClickHouse 和 Elasticsearch 各有适用场景,但是均维持在相同量级。得益于 GreptimeDB 的各级缓存优化,在数据位于对象存储时仍能维持查询性能不退化,从而获得更好的成本/性能平衡。
- 得益于 GreptimeDB 的列式存储和压缩算法,GreptimeDB 提供了三者中最优的数据压缩率,持久化数据大小仅为 ClickHouse 的 50% 和 Elasticsearch 的 12.7%,能够进一步降低数据长期持有的成本。
测试场景
测试数据和流程
我们选用 nginx access log 作为写入数据,一行数据的样例如下:
plaintext
129.37.245.88 - meln1ks [01/Aug/2024:14:22:47 +0800] "PATCH /observability/metrics/production HTTP/1.0" 501 33085我们使用 Vector 这个开源可观测数据 Pipeline 来生成并写入上面的数据。整体测试的流程如图:
针对不同的查询和存储需求,我们分别测试了结构化数据模型和非结构化数据模型两种写入查询模式的表现:
- 结构化数据模型:通过 Vector 对写入的日志数据的字段进行切割,并将不同字段写入到表中的不同列当中。在查询时分别针对不同的列进行数据过滤。
- 非结构化数据模型:除解析出时间戳字段外,将日志文本整体作为一个
message字段存储,并启用全文索引。查询时使用关键字匹配方式检索。
软硬件说明
硬件平台
| 服务器型号 | AWS c5d.2xlarge, 8 vCPU 16GiB Memory |
| 操作系统 | Ubuntu24.04 LTS |
服务器型号
| 数据库 | 版本 |
|---|---|
| GreptimeDB | v0.12 |
| ClickHouse | 24.9.1.219 |
| Elasticsearch | 8.15.0 |
注:各数据库的具体配置文件见附录
读写性能测试
写入表现
| 数据库 | 结构化模型平均 TPS | 非结构化模型平均 TPS |
|---|---|---|
| GreptimeDB (v0.9) | 127226 | 95238 |
| GreptimeDB(v0.12) | 185535 | 159502 |
| GreptimeDB (v0.12, S3) | 182272 | 154209 |
| ClickHouse | 166667 | 136612 |
| Elasticsearch | 39401 | 28058 |
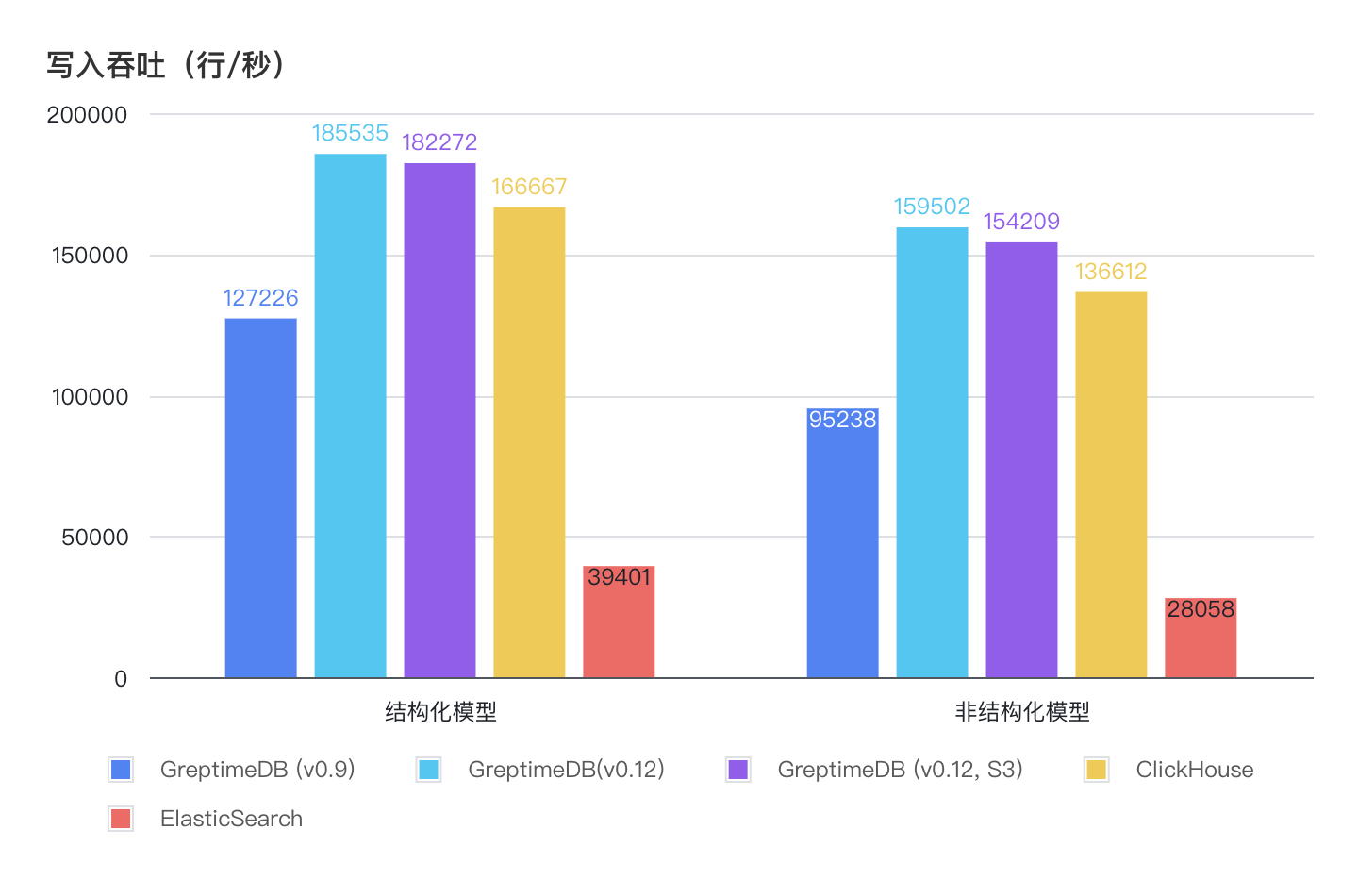
- GreptimeDB v0.12 的写入性能得到了大幅的优化,相较 GreptimeDB v0.9 ,结构化模型下提升了 45.8%,非结构化模型下提升了 67.5%。
- GreptimeDB 的写入性能相对 ClickHouse 小幅领先,但两者都大大优于 Elasticsearch。在结构化模型下,GreptimeDB 的写入吞吐是 Elasticsearch 的 4.7 倍;在非结构化模型下,GreptimeDB 的写入吞吐是 Elasticsearch 的 5.7 倍。
- 在使用 AWS S3 作为底层存储时,GreptimeDB 的写入吞吐仅降低 1~2%,却可以极大地降低成本。
查询表现
我们将查询场景分为 6 个,同时覆盖了比较典型的日志使用场景:
COUNT统计查询:统计全表数据行数;- 关键词匹配查询:匹配日志中的 user、method、endpoint、version、code 分别为特定值;
- 区间统计查询:使用时间范围统计约一半(5,000 万行)数据行数的查询;
- 中间时间范围查询:取时间中间范围一分钟,并查询 1000 行数据;
- 最近时间范围查询:取最近时间范围一分钟,并查询 1000 行数据;
- 关键词匹配 + 区间查询:查询特定时间范围内的字段匹配结果。
注:
- GreptimeDB 和 ClickHouse 都使用 SQL 进行查询,前者使用 MySQL 客户端工具,后者使用 CH 自身提供的命令行客户端。
- Elasticsearch 我们使用 search 的 REST API。
结构化数据
| 查询类别和耗时(毫秒) | GreptimeDB | GreptimeDB on S3 | ClickHouse | Elasticsearch |
|---|---|---|---|---|
| Count Query | 6 | 6 | 46 | 10 |
| Keyword Matching | 22.8 | 24.7 | 52 | 134 |
| Time range | 512.3 | 653.9 | 413 | 16 |
| Middle Time Range | 18.6 | 15.7 | 56 | 32 |
| Recent Time Range | 16.1 | 11.8 | 133 | 25 |
| Keyword Matching+Range Query | 19 | 43.2 | 52 | 88 |

以上数据可以看出:
- GreptimeDB 和 ClickHouse 在结构化数据的查询性能上各有优劣,但总的来说三者性能差距不大。
- 在指定扫描时间段较大时,GreptimeDB 和 ClickHouse 的性能下降较为明显,但是能够在几百毫秒内完成查询。
- 得益于 GreptimeDB 的多级缓存设计,在使用 S3 存储数据时 GreptimeDB 的查询性能并未出现明显降低。
非结构化数据
| 查询类别和耗时(毫秒) | GreptimeDB | GreptimeDB on S3 | ClickHouse | Elasticsearch |
|---|---|---|---|---|
| Count query | 6 | 6 | 8 | 9 |
| Keyword matching | 2547 | 2478 | 2080 | 161 |
| Time range | 1166 | 1330 | 572 | 10 |
| Middle Time Range | 22.4 | 32.2 | 51 | 26 |
| Recent Time Range | 13.5 | 13.8 | 606 | 22 |
| Keyworld Matching and Range Query | 331.8 | 350.2 | 1610 | 122 |
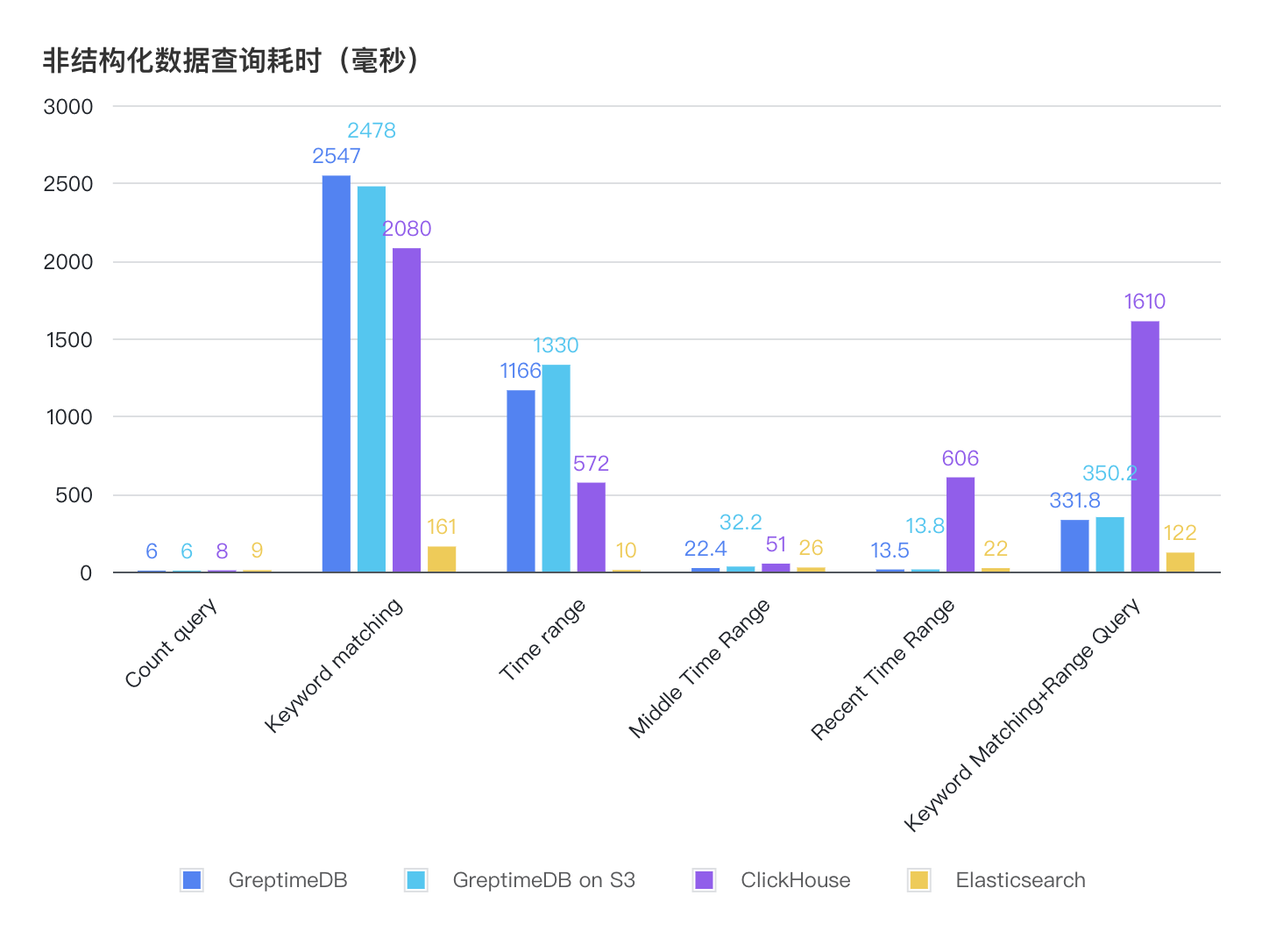
- 相比 GreptimeDB v0.9,v0.12 在大部分非结构化查询的性能都得到了提升。
- 相比结构化数据模型,GreptimeDB 和 ClickHouse 在非结构化模型下的查询性能都出现了退化,并落后于 Elasticsearch。
资源占用和压缩率
资源占用
在限制写入速度为 2 万行每秒的前提下,分别观察 GreptimeDB/ClickHouse/Elasticsearch 的 CPU 和内存占用:
| 数据库 | 结构化数据模型 | 结构化数据模型 | 非结构化数据模型 | 非结构化数据模型 |
|---|---|---|---|---|
| 参数 | CPU(%) | Memory(MB) | CPU(%) | Memory(MB) |
| GreptimeDB (v0.9) | 33.24 | 337 | 16.79 | 462 |
| GreptimeDB (v0.12) | 13.2 | 408 | 10.29 | 624 |
| ClickHouse | 9.56 | 611 | 26.77 | 732 |
| Elasticsearch | 40.22 | 9883 | 47.54 | 9320 |
- 在限制写入吞吐为 2 万行每秒的场景下,ClickHouse 的 CPU 占用率最低,GreptimeDB 略高于 ClickHouse,但是相比 v0.9 版本有较大优化(在结构化模型下从 33.24% 降低到 13.2%,在非结构化模型下从 16.79% 降低到 10.29%)。
- GreptimeDB 的内存占用在三者中最低,而 Elasticsearch 的内存占用比 GreptimeDB/ClickHouse 高出一个数量级。
- GreptimeDB 和 ClickHouse 都是类似于 LSM Tree 的数据结构,因此内存波动较大。
压缩率
测试原始数据文件大小约为 10GB。在所有数据写入完毕后,我们统计各个数据库产品的持久化目录大小,从而可以计算得到如下压缩率:
| 数据库 | 结构化数据模型 | 结构化数据模型 | 非结构化数据模型 | 非结构化数据模型 |
|---|---|---|---|---|
| 参数 | 数据大小(GB) | 压缩比 | 数据大小(GB) | 压缩比 |
| GreptimeDB | 1.3 | 13% | 3.3 | 33% |
| ClickHouse (压缩前) | 7.6 | 26% | 15.5 | 51% |
| ClickHouse (压缩后) | 2.6 | 26% | 5.1 | 51% |
| Elasticsearch(压缩前) | 14.6 | 102% | 19 | 172% |
| Elasticsearch(压缩后) | 10.2 | 102% | 17.2 | 172% |
从以上数据可以得出:
- GreptimeDB v0.12 保持了一直以来的压缩率优势,在结构化数据模型下,持久化文件大小约为原文件大小的 13%,而在非结构化模型下约为 33%。
- 由于结构化数据模型将文本切分为不同的列,针对这些列可以自适应选择合适的编码和压缩策略,因此结构化数据模型的压缩率要远远优于非结构化模型。
注:ClickHouse 和 Elasticsearch 都会在后台持续对文件进行压缩,因此表格中分别记录了压缩前后的数据大小。
附录
软件配置
GreptimeDB 本地存储配置使用默认配置
GreptimeDB 在 S3 上的配置文件如下:
toml
[storage]
type = "S3"
bucket = "<bucket_name>"
root = "log_benchmark"
access_key_id = "<ACCESS_KEY>"
secret_access_key = "<SECRET_KEY>"
endpoint = "<S3_ENDPOINT>"
region = "<S3_REGION>"
cache_path = "<CACHE_PATH>"
cache_capacity = "20G"
[[region_engine]]
[region_engine.mito]
enable_experimental_write_cache = true
experimental_write_cache_size = "20G"Vector 解析日志配置文件
toml
[transforms.parse_logs]
type = "remap"
inputs = ["demo_logs"]
source = '''
. = parse_regex!(.message, r'^(?P<ip>\S+) - (?P<user>\S+) \[(?P<timestamp>[^\]]+)\] "(?P<method>\S+) (?P<path>\S+) (?P<http_version>\S+)" (?P<status>\d+) (?P<bytes>\d+)$')
# Convert timestamp to a standard format
.timestamp = parse_timestamp!(.timestamp, format: "%d/%b/%Y:%H:%M:%S %z")
# Convert status and bytes to integers
.status = to_int!(.status)
.bytes = to_int!(.bytes)
'''建表语句
结构化数据模型
GreptimeDB
sql
--启用了 append 模式,并且将 user、path 和 status 设置为 Tag 类型(即主键)
CREATE TABLE IF NOT EXISTS `test_table` (
`bytes` Int64 NULL,
`http_version` STRING NULL,
`ip` STRING NULL,
`method` STRING NULL,
`path` STRING NULL,
`status` SMALLINT UNSIGNED NULL,
`user` STRING NULL,
`timestamp` TIMESTAMP(3) NOT NULL,
PRIMARY KEY (`user`, `path`, `status`),
TIME INDEX (`timestamp`)
)
ENGINE=mito
WITH(
append_mode = 'true'
);ClickHouse
sql
--使用默认 MergeTree 引擎,定义同样的 sorting key。
CREATE TABLE IF NOT EXISTS test_table
(
bytes UInt64 NOT NULL,
http_version String NOT NULL,
ip String NOT NULL,
method String NOT NULL,
path String NOT NULL,
status UInt8 NOT NULL,
user String NOT NULL,
timestamp String NOT NULL,
)
ENGINE = MergeTree()
ORDER BY (user, path, status);Elasticsearch
json
{
"vector-2024.08.19": {
"mappings": {
"properties": {
"bytes": {
"type": "long"
},
"http_version": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"ip": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"method": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"path": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"status": {
"type": "long"
},
"timestamp": {
"type": "date"
},
"user": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}非结构化数据模型
GreptimeDB
sql
--message 列启用 FULLTEXT 选项,开启全文索引
CREATE TABLE IF NOT EXISTS `test_table` (
`message` STRING NULL FULLTEXT WITH(analyzer = 'English', case_sensitive = 'false'),
`timestamp` TIMESTAMP(3) NOT NULL,
TIME INDEX (`timestamp`)
)
ENGINE=mito
WITH(
append_mode = 'true'
);ClickHouse
sql
SET allow_experimental_full_text_index = true;
CREATE TABLE IF NOT EXISTS test_table
(
message String,
timestamp String,
INDEX inv_idx(message) TYPE full_text(0) GRANULARITY 1
)
ENGINE = MergeTree()
ORDER BY tuple();Elasticsearch
json
{
"vector-2024.08.19": {
"mappings": {
"properties": {
"message": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"service": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"source_type": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"timestamp": {
"type": "date"
}
}
}
}
}关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack

