本页内容
Challenges in Observability Storage
In modern distributed systems, the storage and processing of observability data has become a critical component of infrastructure. As systems scale, traditional log and trace storage solutions face increasingly complex challenges.
Logs
Unstructured logs are still the most common type in many systems, usually containing just timestamps and raw message text. While they're easy for humans to read, they're hard for machines to process efficiently.
Semi-structured logs are popular in some enterprise environments, using formats like messages combined with key-value pairs. This approach gives you a good balance between consistency and ease of processing.
Structured logs use standardized formats like JSON and include complete schema information. They work best for automated machine processing and represent where log data is heading in the future.
Traces
Traces is essentially a special form of structured logging. The OpenTelemetry protocol has become the de facto standard for traces, defining unified structural specifications for traces.
From actual deployment perspectives, traces volume is typically several times larger than regular log data, making it too expensive to store everything. To control costs, most enterprises adopt sampling strategies with rates ranging from 10% to 1%, depending on business scale and budget constraints. While sampling effectively controls costs, it introduces new problems—you might encounter situations where critical traces happen to be unsampled during troubleshooting, making problem diagnosis more difficult. This is why many teams need to consider their sampling strategies carefully.
Common Characteristics of Observability Data
Log and traces share several significant common characteristics:
- Massive data volumes: Medium-scale internet companies can generate TB/day of log data
- Relatively fixed query patterns: Mainly focused on keyword searches and contextual analysis
- Low query frequency: Primarily used for issue diagnosis and troubleshooting
- Long-term storage requirements: Typically need to retain weeks to months of historical data
Systemic Issues with Traditional Architectures
Typical Architecture Analysis
Common log storage architectures typically include these components: Data Collection Agent → Message Queue (Kafka) → Stream Processing Engine (Flink) → Analytical Database (ClickHouse/Elasticsearch).
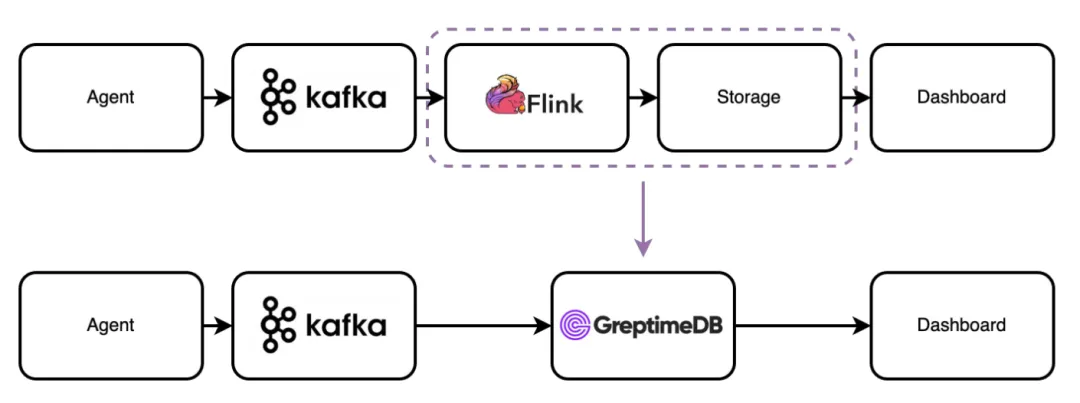
While functionally complete, this architecture has several key pain points:
- Mixed technology stacks: The stream processing layer typically uses Java stack (like Flink), while the storage layer may use C++ stack (like ClickHouse), significantly increasing operational complexity
- Complex resource planning: Requires separate evaluation and planning of compute and storage resources, making capacity planning complex and error-prone
- Compute-storage coupling: Many storage systems have limited compute-storage separation capabilities, forcing simultaneous scaling of compute resources when expanding storage capacity, causing resource waste
- Over-engineered architecture: Using heavy stream processing frameworks for relatively simple preprocessing needs in observability scenarios appears overly complex
GreptimeDB: Unified Observability Storage Architecture
Design Principles
GreptimeDB's core design philosophy is building a unified observability storage solution that handles both logs and traces within a single system while incorporating built-in lightweight stream processing capabilities.
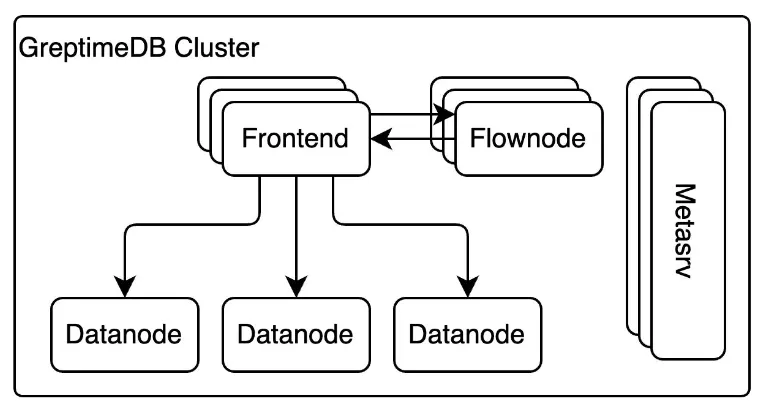
Distributed Architecture Design
- Frontend Layer: Serves as a stateless access gateway, providing multi-protocol read/write interfaces with horizontal scaling capabilities
- Datanode Layer: Handles data sharding and storage responsibilities, with native support for object storage (S3, OSS) and local storage
- Metasrv: Centrally manages cluster metadata, responsible for scheduling, load balancing, and failover
- Flownode: Lightweight stream processing engine specifically designed for preprocessing and aggregation tasks in observability scenarios
Core Technical Advantages
- Cloud-native compute-storage separation: Data stored directly in object storage with compute resources that can be dynamically adjusted based on load
- Unified protocol support: Compatible with different log and trace protocols, simplifying system architecture
- Built-in stream processing: Flow can replace most traditional stream processing tasks, reducing architectural complexity
Real-World Deployment Cases and Performance Optimization
Real-Time Performance Metrics Calculation
In a deployment at a major e-commerce platform, GreptimeDB successfully resolved performance bottlenecks in real-time P99 latency statistics.
The traditional Flink + ClickHouse solution had excessive compute resource consumption and high query latency when processing large volumes of requests. Using GreptimeDB's stream processing functionality, histogram-based pre-aggregation computation was implemented:
- Query response time improved from seconds to milliseconds
- Support for multi-level temporal aggregation (second-level → hour-level → day-level)
- Compute resource consumption reduced by over 60%
Large-Scale UV Statistics Optimization
For typical distinct count scenarios like page visit UV statistics, the HyperLogLog algorithm was employed to achieve efficient probabilistic statistics:
- Stream processing layer pre-computes HyperLogLog data.
- Queries perform secondary calculations on pre-aggregated data.
- Avoids full data scanning, improving query performance by over 100x and reducing query resource consumption to 1/10.
Data Modeling and Storage Optimization
Data Model Design
GreptimeDB adopts an enhanced table model specifically optimized for observability data characteristics:
- Mandatory timestamp column constraint: All data tables must include a timestamp column, ensuring basic characteristics of monitoring data
- Tags column concept: Borrowed from Prometheus label design, tags columns define data timelines, supporting Primary Key syntax to control data sorting and deduplication strategies
- Flexible deduplication mechanisms: Supports Primary Key-based deduplication mode and non-deduplication mode for logging scenarios based on different requirements
Quantified Benefits of Structured Processing
Structured log processing brings significant optimization in both storage efficiency and query performance:
- Storage compression benefits: Structured data effectively utilizes dictionary encoding, prefix compression, and other algorithms. Actual testing shows Nginx access logs reduce storage space by 33% after structured processing
- Query performance improvement: Converting from full-text search to precise field filtering results in more efficient query execution plans
Pipeline Preprocessing Engine
To address the reality of large volumes of unstructured logs in legacy systems, GreptimeDB implemented a lightweight preprocessing engine called Pipeline in Rust:
- Supports multi-level processor chaining
- Provides regular expression and delimiter parsing capabilities
- Supports field mapping and data type conversion
- Can replace most preprocessing tasks in traditional architectures
Full-Text Indexing
Limitations of the Tantivy Solution
The initial version adopted Tantivy as the full-text indexing solution, but encountered several key issues in production environments:
- Excessive storage costs: Full-text indexes require 2-3x storage space compared to raw data, making costs unacceptable in large-scale dataset
- Poor object storage compatibility: Tantivy's design based on local file systems requires downloading complete index directories in object storage environments, affecting query performance
- Poor performance for low-selectivity queries: Matching efficiency for high-frequency keywords (like
SELECT) is lower than direct scanning - Complex query syntax: Query String syntax has high learning costs and poor user experience
Self-Developed Lightweight Full-Text Index
Based on specific requirements of observability scenarios, GreptimeDB developed a specialized lightweight full-text indexing engine:
- Scenario-specific design: Focuses on keyword matching instead of complex search engine features
- Object storage optimization: Redesigned index structure adapted to object storage access patterns
- SQL-compatible syntax: Simplified query syntax providing more intuitive user experience
- Officially released in version 0.14
Future Directions for Observability Storage
Unified storage architecture will become the trend. Single systems processing multiple types of observability data can significantly reduce architectural complexity and operational costs.
Through foundational architectural innovation and gradual maturation of LLMs, future observability storage will have better processing approaches.
- Full utilization of compute-storage separation: In cloud-native architectures, compute-storage separation is not only a cost optimization method but also the foundation for achieving elastic scaling
- AI-driven intelligent operations: Machine learning applications based on large-scale observability data will become new growth areas
Conclusion
GreptimeDB, built with Rust, provides a novel solution for observability storage. Through unified architectural design, deep performance optimization, and cloud-native technical concepts, it successfully addresses pain points in traditional solutions around cost, performance, and operational complexity.
Rust's memory safety, high-performance capabilities, and rich ecosystem provide an ideal technical foundation for building modern infrastructure software.
As observability technology continues to evolve, unified storage architecture will become the new technical standard. GreptimeDB, as an open-source project, will continue to provide users with more efficient and economical observability data solutions.
p.s. This article provides detailed coverage of GreptimeDB's technical architecture and engineering practices. For more technical details or to participate in open-source contributions, please visit the GitHub repository or follow the official technical blog.

