
本页内容
这不是一篇庆功稿,而是一次阶段性的回望:为什么出发,怎样选择,错过了什么,又因为什么坚持到今天。
2022 年 11 月 15 日傍晚,我们在办公室里等着 GitHub 上那个花了半年多心思的 repo 从 private 翻成 public。点下按钮的那一刻,我有点小激动还把 GitHub 密码忘了,晓丹(我们的 CEO)录了视频,笑着说这是未来值 5 亿美金的公司。没有更多仪式感的东西了,我们嬉笑着各自回工位继续写代码。
过去四年,GreptimeDB 从一个时序数据库的创业想法,走到了今天的 v1.0。版本、功能和社区这些结果当然重要,但如果回头看,真正值得复盘的还是当时为什么这么选,哪些判断后来证明是对的,哪些代价我们一开始没看清。
我是冯家纯,GreptimeDB 的联创之一,也是数据库内核的研发负责人。晓丹之前写过几篇文章,聊了创业的初心和踩过的商业化的坑。这篇我想从技术负责人的角度,把这四年重新捋一遍:我们做过哪些决策,犯过哪些错,社区是怎么一点点做起来的,以及我自己这几年最真实的感受。
一、为什么是这件事
2022 年我们决定做 GreptimeDB 的时候,时序数据库赛道已经不算新了。InfluxDB、TimescaleDB、TDengine 都已经有了相当的用户基础。我们不是没看到竞争,而是看到了一些我们认为还没被解决好的问题,这个判断来自我们亲手踩过的坑。
在创业之前的四年,我们团队大部分人在国内某大型互联网公司做自研时序数据库。我们和大团队一起,构建了一整套时序数据处理系统:采集可观测数据,建模实体和关联关系,结合海量数据挖掘、专家经验和智能算法(也就是 AIOps),搭建起一个可观测的实时数据集市。这套系统用来做异常巡检、可用性监控、预警和根因定位,效果非常好;后来还扩展到了容器资源弹性调度、全站性能诊断优化等更多场景。在当时,这个时序数据库支撑着全站每秒超过 1 亿数据点的写入。
但就是这样一个经过大规模验证的系统,我们依然看到了它的天花板。
存储成本高。每日万亿级的新增数据叠加存量数据,带来了巨额的存储开支,而且随着业务增长只会越来越贵。实时分析难做。时序数据天然是高基数据,快速、准确甚至智能化的查询分析能力,当时的架构根本扛不住,算法同学一拉数据,我们就慌得一批。数据类型单一。它只能存 metrics,logs 和 traces 完全无法支持,可观测数据被割裂在不同的系统里。
我们在市面上也找过替代方案,但没有一个能同时解决这三个问题。"理想中的那个产品"其实在我们脑子里活跃了很久,只是一直苦于业务压力,没有人力和精力真正投入。直到有一天,晓丹边喝咖啡边不经意地说了句"我们出去创业吧,做这个"。一拍即合。
为什么选择开源? 做基础设施软件,用户需要能审视你的代码才会信任你,这是最根本的原因。团队里大部分人本身就是从开源社区成长起来的,我们想把这些年从开源中获得的东西回馈回去。所以从第一天起,我们就按最终开放的标准来要求自己:code style、commit message、分支管理、PR 规范,从写下第一行代码就逐步完善和执行。后来证明,这个决定的回报比我们当时想的要大。
但说实话,当年我们对开源的理解还比较表面,觉得开源就是"把代码放到 GitHub 上,用 Apache 2.0 协议,认真写 README"。四年下来最大的认知变化是:开源是一种工作方法,不只是一种发布方式。设计文档要写清 trade-off,PR 要假设将来有完全不了解上下文的人来读,issue 的响应不能随缘。说到底,开源是先把屋子收拾到别人能进来、能看懂、能继续一起住的程度。
开源也不等于社区。有 star 不等于有用户,有用户不等于有信任。一个数据库要赢得生产环境的信任,靠的是年复一年的稳定性、负责任的 release 节奏,以及出了问题时你能多快地回应。
二、几个真正改变方向的关键决策
四年里做过无数个决策,但真正改变后续走向的只有几个。这一节不铺时间线,只挑那些回头看仍然觉得"如果当时选了另一条路,今天会完全不同"的节点。
决策一:选择 Rust

2022 年选 Rust 写数据库,在国内算少数派。但对我们来说这个选择几乎没有争议,团队已经写了快四年 Rust,经验不是问题。更关键的是,数据库需要精确控制内存、管理复杂并发、在高吞吐下保持稳定延迟,这些要求指向的是一门没有 GC、性能可预期的系统级语言。Go 和 Java 的 GC 在大多数场景下够用,但在存储引擎层面,一次 GC pause 就可能意味着延迟毛刺,这对我们来说不可接受。Rust 的所有权模型天然保证内存安全和线程安全,零成本抽象让我们不用在设计和性能之间做取舍。
四年后回头看,Rust 带来的收益比我们当时想的还大,但它的门槛和成本也确实比预期更高。
好的方面:Rust 帮我们避免了大量并发和内存相关的 bug,CI 里几乎从不出现 segfault,在 C++ 数据库项目里这很难想象。另一个意外收益是社区吸引力。Rust 社区的开发者天然对基础设施项目感兴趣,来提 PR 的人往往不只是改 typo,而是能参与到引擎层面。
难的方面:招聘是最直接的挑战。国内 Rust 工程师的池子比 Java、Go 小了不止一个数量级,"懂数据库"和"懂 Rust"的交集更小。每个新人加入,我们都需要有足够的耐心让他学习和熟悉 Rust。编译速度和磁盘占用嘛,不多说了。
不过到了 2025 年,Rust 给了我们一个意外之喜:它可能是最适合 vibe coding 的语言。AI 写 Rust 犯的错不少,但 Rust 的编译器会把错误精确地拍回来,形成一个极其高效的"生成-报错-修正"循环。换成其他语言,AI 生成的代码"看起来对了",bug 可能藏在运行时的某个角落;Rust 代码只要编译通过,一大类内存和并发错误就已经被消灭了。当年选 Rust 的时候,我们可没想到会有这个红利。
如果重来一次,我们还是会选 Rust。前期确实更难,但把时间拉长看,值得。
决策二:重写存储引擎
v0.3 之前的存储引擎,更像是一个"先把系统跑起来"的第一代实现。memtable 本质上是把数据按行塞进 BTreeMap,每个 region 各自维护写入状态。这个版本帮我们很快把产品轮廓做出来了,但它对时序场景并不友好。时序数据最大的特点是同一条时间线反复写入大量 tags 基本不变的数据,用行存 BTreeMap 去装,主键和标签被一遍遍重复存储,内存放大严重,flush 出来的 SST 又偏小,继续拖累查询和 compaction。写路径上也类似:region 各写各的,锁和状态分散,很难做真正高效的攒批。
从 v0.1 到 v0.3,这些问题不断被性能测试和 profiling 印证。瓶颈不在某个局部函数,在数据组织方式本身。继续在老架构上修补只能拿到局部优化,拿不到数量级的改善。再拖下去,是继续给未来堆技术债。
于是我们在 v0.4 做了一次彻底的重写:Mito2。memtable 换成按时间线组织的 Series 结构,compaction 引入受 Cassandra 启发的 TWCS,数据存储切换为列式,基本上是推倒重来。对一个开源项目来说,这尤其伤筋动骨。用户已经在跑着老引擎,contributor 也已经在老引擎上提 PR。重写不只是代码问题,我们还得提前在 GitHub 上把"为什么要重写、新设计是什么、迁移路径怎么走"讲清楚,同时继续维护旧引擎。
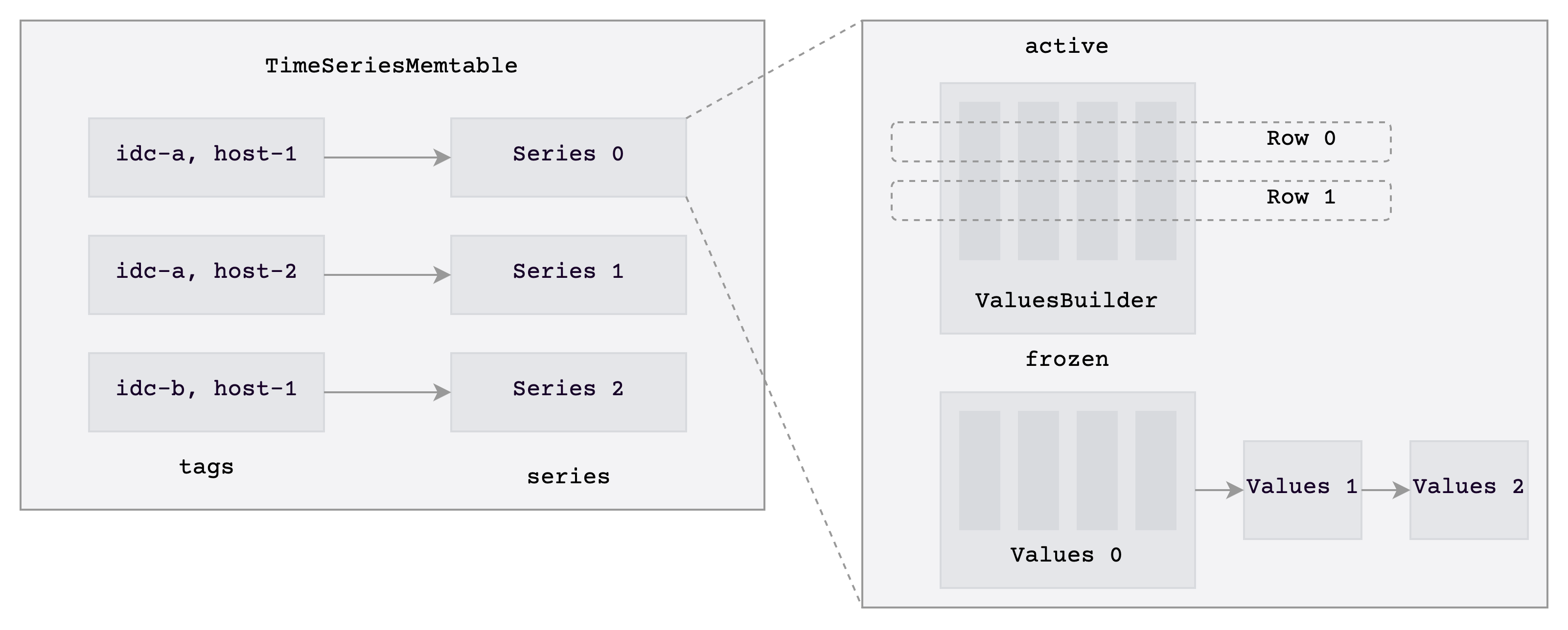
Mito2 上线之后效果很明显:写入有稳定提升,扫描类查询提速数倍,个别场景超过 10 倍,底层 memtable 的写入效率和内存占用改善更明显。但这些提升背后,是几个月的高压开发。压力最大的地方不在引擎本身,在它的"爆炸半径":为了适配新引擎,整个分布式通信协议甚至调度架构都要跟着调整,改动范围实实在在地大。而真正让人焦虑的是:投入这么大的成本,最终能不能拿到预期的效果?动手之前没有人能给你确定的答案,但拍板的决定必须有人做。
存储引擎的演进到 v1.0 也没有停。随着越来越多用户把高基数列(比如请求 ID)放进主键,我们碰到了一个新瓶颈:老的 primary_key 格式为每条时间线维护独立结构,时间线一多,内存效率和查询性能都会退化严重。有用户的表每次 flush 要处理超过 1400 万条时间线,写入基本不可用。为此,v1.0 引入了 Flat 格式:为 tag 列增加了独立存储,配合新的 BulkMemtable 取消了按时间线维护独立 buffer 的设计。200 万时间线下写入吞吐提升了 4 倍多,部分查询从 17 秒降到 3 秒。这个改动看起来是存储格式的优化,但它背后的判断和 Mito2 一样:瓶颈到了数据组织方式这一层,局部修补拿不到根本性的改善。
回头看,这次重写教会我一件事:"什么时候重写"比"要不要重写"更关键。 太早,你还没真正理解用户的需求模式;太晚,技术债会把你拖死。我们选在 v0.4,是因为前三个版本积累了足够的用户反馈和性能数据。如果在 v0.1 就动手,大概率会写出另一个"看起来不错但解决不了真实问题"的引擎。
决策三:统一 metrics/logs/traces 的数据模型
事后回看,这很容易被讲成一个从第一天就设计好的宏大愿景。真实情况不是这样。
我们最开始的切入点就是 metrics。团队有积累,问题足够痛,Prometheus 生态也已经成熟,先把 metrics 做好是最现实的选择。但我们在上一段经历里吃过三套系统割裂的苦:系统出了问题,用户不会只看指标波动,他会追问那一刻的日志、那条调用链、根因在哪一层。三类数据散在不同系统里,标签体系都对不齐,数据明明都在却关联不起来。所以虽然从 metrics 起步,脑子里始终有一个问题:能不能不要再让用户在三套系统之间来回跳?
让这个方向逐渐清晰的,是做产品过程中一种越来越强的别扭感:我们一边在做 metrics,一边不断碰到单靠 metrics 解释不清的场景,需要和日志、链路一起看,却只能在系统外手工拼接。慢慢地我们意识到,metrics、logs、traces 虽然长得不一样,但本质上都是带时间戳、带上下文的事件,只是载荷和查询模式不同。再往后看,它们与其说是三种完全不同的数据,不如说是同一份可观测数据在不同抽象层上的视图。方向不是规划出来的,是被真实问题一步步推到了这条路上。
落地的方式也不是把产品改个名字就完了。我们逐步做实:先把 metrics 的模型从兼容 Prometheus 往更通用的表模型推进,再把 logs 纳入统一的数据入口和查询体系,最后补上 traces。过程中我们越来越明确一件事:统一的是用户心智、数据关联方式和查询入口,底层依然可以针对不同 workload 做不同优化。否则你得到的就是一个什么都想做、什么都做不好的大杂烩。
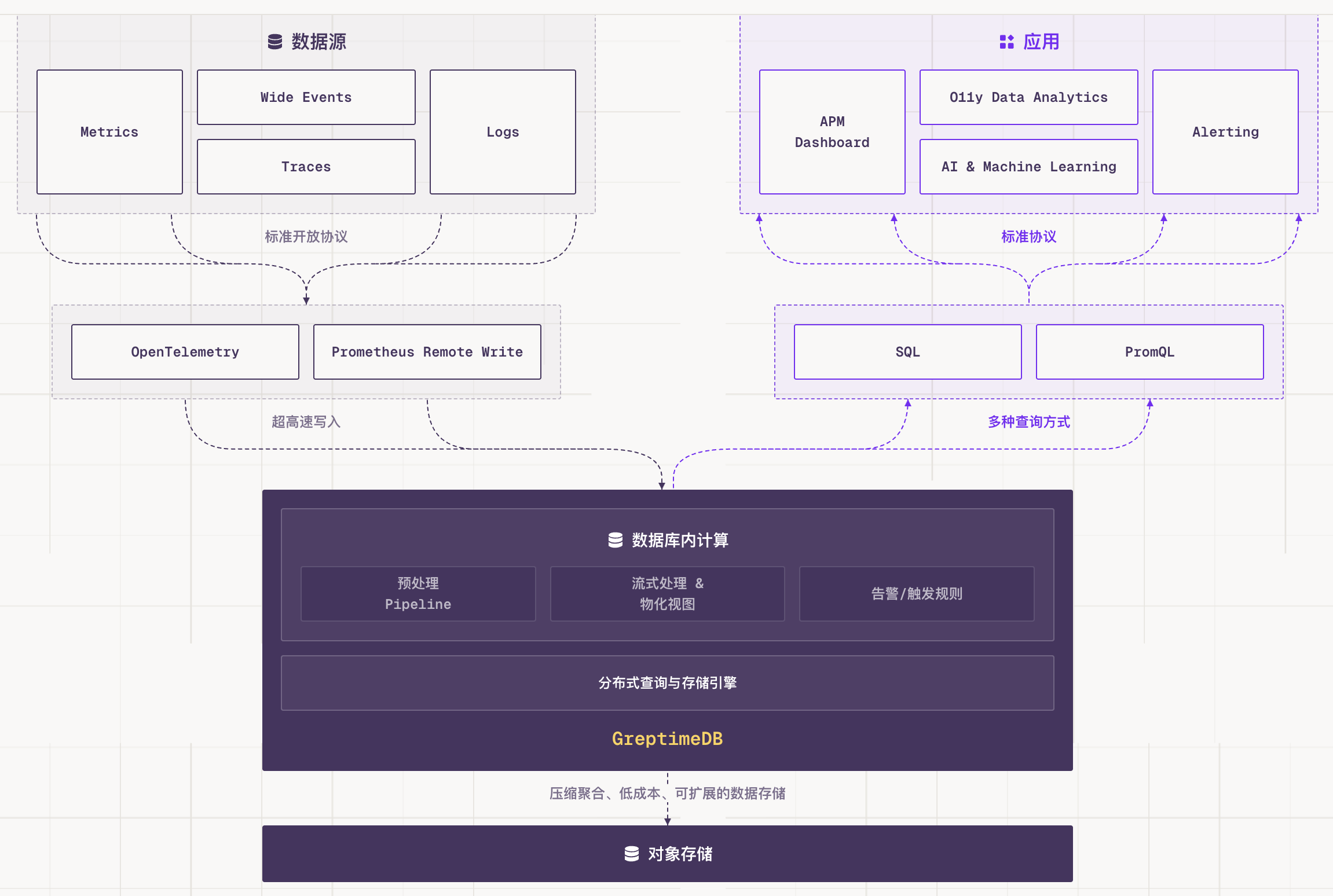
走到今天,我们对这件事的理解又往前推了一步。Honeycomb 的 Charity Majors 提出了 Observability 2.0 的概念:传统"三大支柱"各自为政的方式是 1.0,以"宽事件"(wide events)为核心、从同一份原始数据派生 metrics/logs/traces 的方式是 2.0。我们做的统一数据模型,本质上就是在数据库层为 2.0 打基础。
AI Agent 时代让这件事变得更加迫切。Agent 的可观测数据天然就是高基数、高维度、上下文丰富的宽事件:一次 Agent 执行可能包含 prompt、response、tool calls、reasoning、memory state 几十上百个字段,传统方式要么塞进 logs 丢失结构,要么塞进 traces 但 schema 太死板。Hebo 团队用 GreptimeDB 构建他们的 AI Agent 可观测平台,就是看中了统一存储加上原生 OTLP 写入的能力,可以把 GenAI 的 traces、token 用量、推理延迟放在同一个地方查询和分析。我们也发布了一个完整 Demo,展示如何用 GreptimeDB 配合 OpenTelemetry GenAI Semantic Conventions,把 GenAI 应用的 traces、metrics 和对话日志统一存到一个后端。这也让我们越来越确定:GreptimeDB 在构建的,就是可观测性 2.0 的数据库。
回头看,统一数据模型是 GreptimeDB 这几年的核心判断之一。它不是一开始就想清楚的,却反而因此更接近真实需求。我们真正想统一的,从来不是三种文件格式或三套协议,而是用户对同一套系统行为的理解方式。数据库层如果继续把指标、日志、链路割裂开,用户最终还是要自己在系统之外完成那次"统一",那不如由我们来做。
三、踩过的坑:有些弯路不能只用一句话带过
如果只讲做对了什么,这篇文章和 PR 稿没有区别。有价值的部分是:我们愿意具体承认哪些判断失误。
做过但用户并不真正需要的东西
最典型的一个例子,是 Python 协处理器。从技术人的视角看,这个方向当时非常有吸引力:数据库如果能把用户自定义逻辑直接带到数据旁边执行,听起来既灵活,又很有想象空间;我们也确实见过一些分析和处理场景,似乎很适合用这种方式来扩展能力。所以当时做这个决定,并不是为了炫技,而是真心觉得"可编程性"可能会成为一个关键需求。
但后来我们逐渐意识到,至少在那个阶段,用户在意的并不是"我能不能在数据库里写一段 Python",而是更朴素也更直接的问题:能不能更容易接进现有系统,协议兼容是不是足够好,查询是否稳定,性能是否可预期,文档是不是清楚,出了问题有没有人及时响应。我们把一部分精力放在了一个确实有价值但优先级判断错误的方向上。
这件事让我意识到,技术负责人最容易犯的一类错误,其实是过早去做那些"如果做成会很漂亮"的东西。Python 协处理器不是一个错误的想法,但在那个时间点,它不该排在可用性、兼容性和稳定性前面。
低估了社区建设的难度
社区不是把仓库公开就会自然发生的事。我们后来才真正理解这一点。
早期我们对这件事的理解,说得直白一点,还是有些天真。那时候总觉得,只要产品方向对、代码质量够好、仓库保持整洁,社区就会慢慢长出来。后来才发现,这种想法忽略了一个最基本的事实:对外部贡献者来说,项目的第一印象往往不是你的架构有多漂亮,而是 issue 有没有人回、文档能不能看懂、第一次提 PR 会不会卡在一堆没有写出来的隐含规则里。我们并不是故意对外部贡献者不友好,但在相当长一段时间里,我们确实没有把"如何让陌生人参与进来"当成一个需要专门设计的问题。
早期做得不够的地方其实很具体:issue 的响应不够稳定,文档和 contributor guide 补得不够早,对外部 PR 的反馈有时也不够及时。很多在内部看起来理所当然的上下文,对外部人来说其实是完全缺失的。更现实的一点是,数据库项目的参与门槛本来就高,很多所谓的 Good First Issue,对新人来说并没有那么 first。你以为只是让对方改一小段代码,实际上他可能得先理解一层执行流程、两层抽象边界、再补一堆背景知识,才能真正动手。后来我们在降低门槛上做了不少努力:写 contributor guide、录架构讲解视频、在 Slack 的 #contributors 频道即时回答问题。但这些都是逐步补上的,不是一开始就做好的。
技术债与架构代价
如果一定要说哪一类技术债后来最贵,我会选那些"当时为了尽快把系统跑起来而没有划清的边界"。
创业早期这很常见,很多时候也确实是对的:你不可能在 v0.1 就把单机引擎、分布式协议、调度流程、存储格式之间的抽象边界一次定义完美。那个阶段更重要的是先让系统跑起来,先让用户真的开始用。
问题在于,边界一旦没有在早期被有意识地控制住,后面就会不断放大改动的半径。前面聊存储引擎重写时那种"牵一发动全身"的感受,很大程度上就是这类债的利息。看起来像是引擎内部的一次演进,最后却要牵动分布式通信协议和调度架构一起调整。这类代价在早期并不显眼,系统还小、链路还短的时候,很多问题靠核心成员的上下文记忆就能撑过去。可一旦产品继续演进、团队继续变大,那些"先这样吧,以后再收拾"的地方,就会变成真正要花大代价偿还的债。我们不是不知道这些地方迟早要处理,是低估了它们放大的速度。
四、社区给我们的,不只是数字
GitHub 上的数字是好看的:6100 stars、5200 多个 commits、226 个 releases。但让我觉得做开源有意义的,从来不是这些数字,是一些具体的人和具体的时刻。

一个印象深刻的贡献者故事
让我印象很深的一位贡献者,是 Lanqing(GitHub 上的 lyang24)。他的轨迹很能说明一个开源数据库项目里,"路过一下"和"真正留下来"之间到底差了什么。
他的起点是 2023 年一个改善 compression type 使用体验的 PR(#2765),很典型的外围贡献:解决一个具体的小问题,顺手把用户体验打磨一下。但他没有停在那里。再往后,贡献范围明显在往更深的地方走,从元数据服务的 KvBackend,到系统表和 Postgres 协议适配,再到更靠近内核的 Mito 引擎观测和性能优化。一步一步把上下文啃下来,最后真的走进了系统内部。2025 年他成为了我们的 committer。
打动我的不是"又多了一个 committer"这件事本身。是你真的能看到,一个原本只是顺手提 PR 的人,会沿着一次次 issue 和小改动,慢慢变成项目里很重要的一部分。
用户教会我们的事:先进入他的世界
有一个用户故事后来让我印象特别深。2024 年,DeepXplore 公开写过他们从 Thanos 迁到 GreptimeDB 的过程。打动我的不是"他们觉得我们更快",而是迁移理由本身:他们不想继续把大量时间花在维护一套复杂的长期存储系统上,而是希望把精力放回自己的产品。对一个创业团队来说,这个判断太真实了。用户在比较的,从来都是哪一种方案更省心、能让团队把时间花在自己关心的事情上。
更关键的是,迁移之所以成立,恰恰是因为不用重写。他们把 Grafana Alloy 里的 remote write URL 切到 GreptimeDB,PromQL 查询侧几乎不用调整,只是换了一个 endpoint。这件事后来也让我们越来越确定:用户要的是一个能直接接进现有系统、少折腾、少维护的东西,不是一个听起来更先进的新数据库。
这类反馈改变的不是某一个功能点,而是我们看产品的方式。用户不生活在我们的架构图里,他们生活在自己已经存在的生产环境里。你得先进入那个环境,后面的一切才有机会被看见。
五、关于 v1.0
写这篇文章的时候,GreptimeDB v1.0 正在 RC 阶段。对我们来说,v1.0 不是收工,是从这个版本开始,很多事情要按长期负责的标准来做了。
它意味着一些核心判断已经被验证:统一 metrics/logs/traces 的方向,以及产品必须进入现有生态,不能要求用户重写链路。这些在早期更多是信念,到了 v1.0,已经有足够多的用户、场景和工程经验告诉我们,这条路走得通。核心能力也终于从"能跑"走到了"可依赖",出了问题我们知道怎么定位、怎么修、怎么继续演进。
v1.0 也不是终点。架构会继续演进,产品定义不会封闭,社区建设远没有完成。在这之前,我们更多是在验证这条路能不能走通;v1.0 之后,重点变成怎么把它长期做好,怎么对用户负责。
六、四年之后,我们真正想清楚了什么
四年之后,我们比一开始更清楚的,不只是接下来做什么,而是什么事情值得我们持续投入很多年。
前面这些决策和教训,最后都落到同一个问题上:做选择本身没那么难,难的是在它还没被证明之前,团队还能不能继续扛着往前走。
重写引擎的那几个月没有人能保证结果会好,统一数据模型的方向在很长时间里都只是一个还没被市场充分验证的信念。这些事情最后能走通,不是因为我们一开始就想得很明白,是因为很多关键阶段虽然没那么确定,我们也没有停下来。做基础软件,判断当然重要,但很多时候更稀缺的是耐心。
这四年让我越来越相信,最后拉开差距的往往不是谁更聪明,而是谁愿意在一个难问题上多待几年,不轻易换题。我理解的同路人,也不只是认同这条技术路线的人,而是愿意一起面对复杂问题,接受这件事本来就需要时间的人。
七、感谢,以及邀请
感谢每一个提过 issue、提交过 PR、在 Slack 里问过问题的人。感谢早期用户,那些在项目还不成熟时依然愿意尝试、愿意指出问题的人。
你们可能觉得那只是一个小小的 bug report 或者一个不起眼的文档修复,但对我们来说,每一次互动都是一个信号:有人在用,有人在乎。
如果你也在关注可观测数据接下来会怎么演进,或者你也愿意做那些短期不那么热闹、但长期值得做的事,欢迎来看看 GreptimeDB:
- GitHub: https://github.com/GreptimeTeam/greptimedb
- Contributor Guide: https://docs.greptime.cn/contributor-guide/overview
- Slack: https://greptime.com/slack
- 2026 Roadmap: https://github.com/GreptimeTeam/greptimedb/issues/7685
不管你是用户、贡献者、同行,还是刚刚第一次听说我们的人,欢迎来找我们。四年不算长,尤其对一个基础软件项目来说,不够长到让一切尘埃落定,但足够长到让一些判断被验证,让一些关系慢慢建立起来。

