本页内容
GreptimeDB 通过一个名为 Mito 的存储引擎来存储时序数据。Mito 负责接收写入、保证数据持久化、为后续读取组织数据,并在后台清理过期或相互重叠的文件。
时序数据有着鲜明的特征:写入频繁,绝大多数行都是带着更新时间戳追加进来的;查询通常只关心某个时间范围、部分时间线以及少数几列;删除和更新虽然存在,但远不如插入常见。Mito 正是围绕这些特征来设计的,而非像通用的事务型存储引擎那样工作。
本文将自顶向下地介绍 Mito:为什么采用 LSM-tree 设计、数据如何流经写入路径、数据在存储文件内部如何组织、扫描时如何跳过不必要的数据,以及索引和 compaction 如何融入整个引擎。
为什么 LSM 适合时序场景
Mito 采用了 LSM-tree 风格的设计。在 LSM-tree 中,新数据先写入内存和持久化日志,之后再 flush 成不可变文件。这种方式非常适合时序负载,因为它让写入路径保持高效,并把大量小写入聚合成更大的顺序文件写入。
Mito 以 region 为单位存储数据。region 是表数据的一个物理分片,每个 region 拥有自己的元数据、内存缓冲区、SST 文件、manifest 以及存储选项。SST 是不可变的存储文件,而 manifest 是记录 region 变更(例如新 flush 出的文件,或被 compaction 移除的文件)的元数据日志。
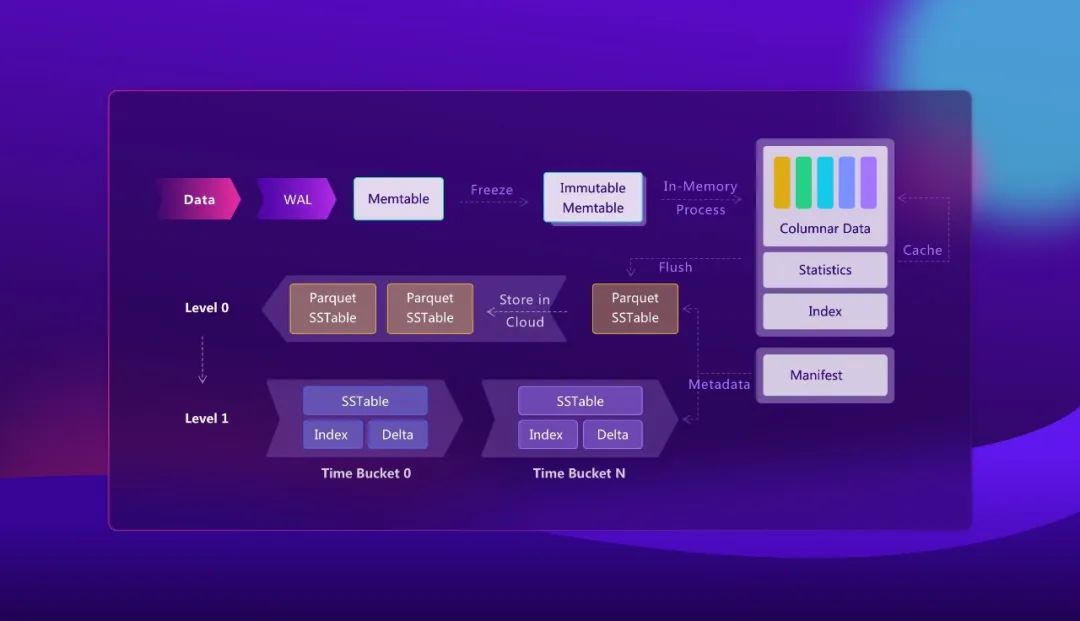
下图展示了 Mito 周围的主要组件,以及数据如何在内存、持久化日志、SST 文件、元数据和对象存储之间流动。
写入路径主要分为三步:
- Mito 首先把进入的行写入 WAL。WAL(write-ahead log,预写日志)在数据被 flush 成不可变文件之前先保证其持久化。根据部署方式不同,WAL 可以存储在本地磁盘、EBS 之类的云块存储,或者 Kafka 上。
- Mito 把同样的行写入一个可变的 memtable。memtable 是一块内存缓冲区,用于服务近期写入,并在持久化前累积数据。
- 当 memtable 达到持久化条件时,Mito 把它 flush 成 Parquet 格式的 SST 文件,并在 region manifest 中记录这些文件的元数据。
这样的设计让数据摄入保持简单:当一条写入在 WAL 中持久化、并在内存中可见后即可向客户端确认,随后在后台再把缓冲的数据转换成列式文件。
数据如何组织
Mito 围绕时序场景常见的读取模式来组织数据:先缩小时间范围,再选择一组时间线,然后只读取需要的列。
在一个 region 内部,行会从可变 memtable 转到不可变 memtable,再到 SST 文件。刚 flush 出来的 SST 文件在主键和时间范围上可能相互重叠,后台 compaction 之后会把它们重写成数量更少、组织更好的文件。
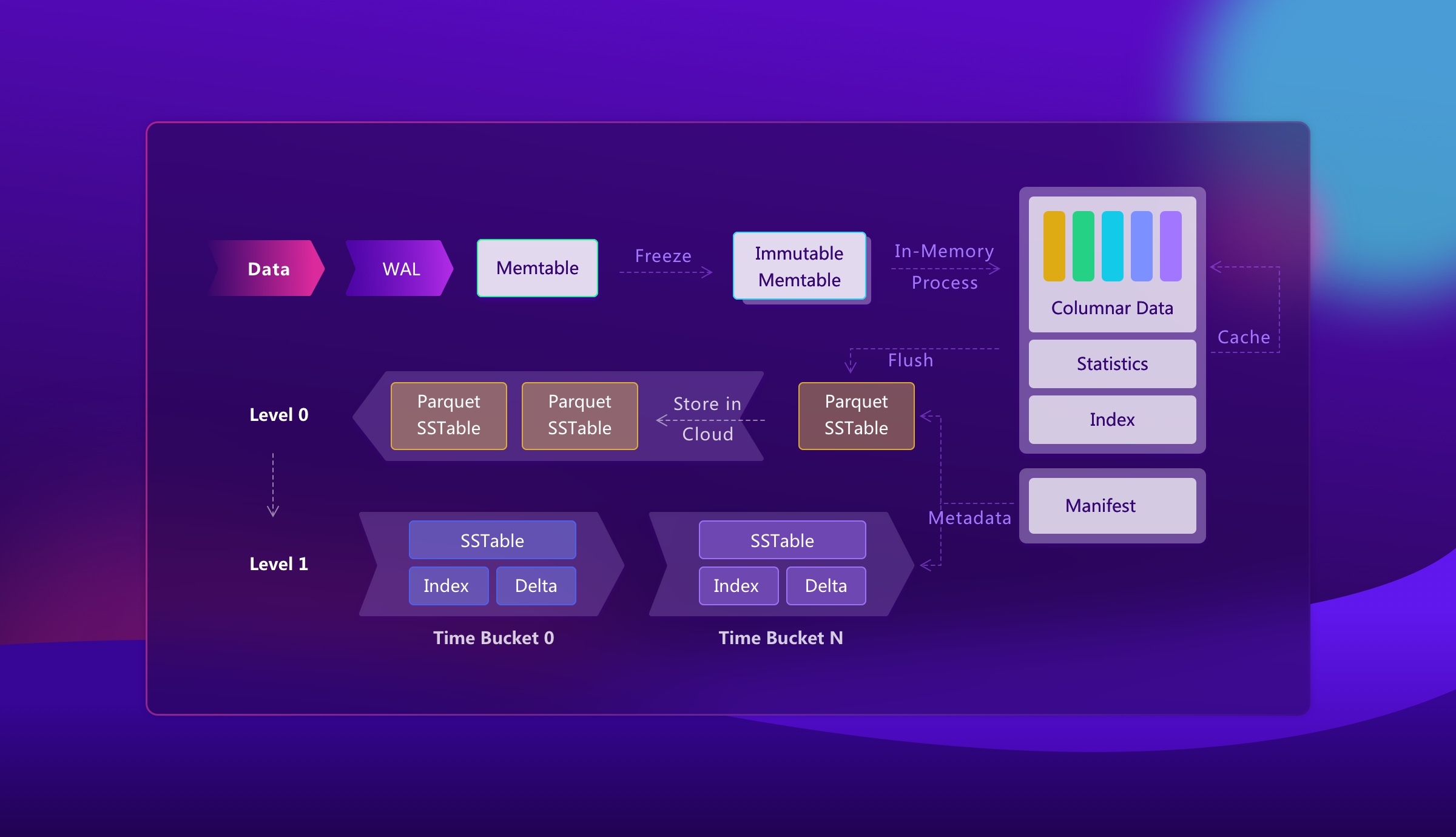
下图展示了 SST 文件的逻辑布局,以及读取时所用到的元数据。

其中最重要的两个排序概念是主键(primary key)和时间索引(time index)。
主键通常由标识一条时间线的 tag 列组成,比如 host 和 region。拥有相同主键的行属于同一条时间线。时间索引则是时间戳列,它对一条时间线内的数据点进行排序,也是时间范围查询中最主要的剪枝维度。
举例来说,假设有一张存储主机指标的表:
sql
CREATE TABLE host_metrics (
host STRING,
region STRING,
ts TIMESTAMP TIME INDEX,
cpu DOUBLE,
memory DOUBLE,
PRIMARY KEY (host, region)
);从概念上看,行按主键分组、按时间排序:
| host | region | ts | cpu | memory |
|---|---|---|---|---|
| host-a | us-east | 10:00 | 0.42 | 7.1 |
| host-a | us-east | 10:01 | 0.47 | 7.4 |
| host-a | us-west | 10:00 | 0.31 | 6.8 |
| host-b | us-east | 10:00 | 0.80 | 8.6 |
在存储中,host 和 region 是主键列,ts 是时间索引,cpu 和 memory 是字段(field)列。Mito 还会存储一些内部列,例如编码后的主键数据、序列号(sequence number)和操作类型(operation type),以便在从多个 memtable 和 SST 文件读取时,能够正确地进行合并、去重和应用删除。
每个 Parquet SST 会被切分成若干 row group。row group 是 Parquet 能够高效读取或跳过的基本单位。对于每个 row group,Parquet 会存储列统计信息,例如最小值、最大值和 null 数量。Mito 还会记录文件级别的元数据,包括文件时间范围、行数、文件大小、row group 数量、可用索引,以及在有条件时记录主键范围。
时间窗口(time window)是布局中另一个重要部分。时间窗口是一段时间戳范围,后续会被 compaction 和数据保留(retention)所使用。
Mito 如何扫描数据
一次扫描从查询可见的数据开始:当前的 memtable 和相关的 SST 文件。它同时也知道查询的谓词和时间范围。Mito 利用这些信息来减少需要打开、解码和过滤的数据量。
下图展示了剪枝流程。关键在于 Mito 并不依赖单一的剪枝机制,而是把时间范围、row group 统计信息和索引结合起来使用。

以下面这条查询为例:
sql
SELECT ts, cpu
FROM host_metrics
WHERE host = 'host-a'
AND region = 'us-east'
AND ts >= '2026-05-29 10:00:00'
AND ts < '2026-05-29 11:00:00'
AND cpu > 0.7;Mito 首先从时间索引上的谓词中提取时间范围。那些存储时间范围与查询范围不相交的文件和 memtable,在打开 reader 之前就可以被跳过。对于时序数据来说,这通常是最廉价、也最重要的剪枝步骤。
接下来,Mito 使用 min-max 统计信息。如果某个 row group 的统计信息能够证明其中没有任何行可能匹配谓词,那么这个 row group 就会被跳过。例如,一个 cpu 最大值为 0.6 的 row group 不可能匹配 cpu > 0.7。row group 统计信息比较粗粒度,但代价低廉,在数据具有局部性时效果很好。
当统计信息还不够时,索引可以提供更具选择性的剪枝。索引是为一列或多列构建的辅助数据,使得扫描在解码数据列之前就能排除更多的行或 row group。Mito 把索引数据存储在 Puffin 文件中。Puffin 是一种辅助文件格式,用于把索引数据放在 SST 元数据旁边,而不必塞进主 Parquet 数据文件内部。
在扫描规划阶段,Mito 会检查查询谓词是否能够利用可用的索引。索引的结果会与经过时间范围和 min-max 剪枝后存活下来的 row group 相结合。随后 reader 扫描剩余数据,并应用精确过滤。
对于可能包含更新或删除的表,Mito 还会根据序列信息和操作类型对行进行合并与去重。对于 append-only 的表,当查询不要求输出有序的时间线时,扫描可以省去较多的排序工作。
索引与 Compaction
索引是存储布局的一部分。当 Mito 写出 SST 文件时,它可以同时为那些能从选择性剪枝中获益的列构建索引文件。SST 元数据会记录存在哪些索引、各自覆盖哪些列。
这种设计非常契合对象存储:数据文件和索引文件可以一起管理、在有用时一起缓存,并在元数据证明它们与某次查询无关时一起被跳过。
Compaction 让 LSM-tree 保持健康。如果没有 compaction,大量小文件或相互重叠的 SST 文件会不断累积,使读取代价越来越高。在 compaction 过程中,Mito 读取选定的 SST 文件,合并其中的行,写出新的 SST 文件,在需要时更新相关索引元数据,并通过 region manifest 提交结果。
下图展示了 region 级别的时间窗口。每个窗口是一个时间戳桶(bucket),其中可能包含多个 SST 文件。TTL 可以从较旧的桶中移除过期文件,而 compaction 可以合并同一个桶内相互重叠的 SST 文件。

Mito 默认使用时间窗口压缩策略(Time Window Compaction Strategy,简称 TWCS)作为 compaction 策略。TWCS 按时间戳范围把候选文件分组,因此同一窗口内的文件会被一起 compaction。当一张表配置了 TTL 时,compaction 还可以移除那些数据落在保留窗口之外的过期 SST 文件。
总结
Mito 是 GreptimeDB 面向时序负载的存储引擎。它把高效的 LSM 风格写入路径与列式 SST 布局、region 级别元数据、row group 统计信息、可选的索引文件以及时间窗口 compaction 结合在一起。
整个设计的核心在于避免不必要的工作:时间范围跳过整个文件,min-max 统计信息跳过 row group,索引剪除具有选择性的谓词,compaction 把相互重叠的文件重写成更整洁的时间窗口并移除过期数据。
这些部件共同作用,让 GreptimeDB 既能承接高频的时序数据摄入,又能让常见的时间范围查询和面向时间线的查询保持高效。
如果你对 GreptimeDB 的存储引擎感兴趣,欢迎在 Slack 或 GitHub 加入我们。
关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack

