
本页内容
自 0.6 版本起,GreptimeDB 分布式版本具备了将 Datanode 上的数据表分区(Region)数据迁移到另一个 Datanode 的能力。在上一篇《Region Migration 技术原理》的文章中,我们详细介绍了 Region Migration 实现的具体的技术细节。
本文将演示如何使用这项功能。
前置条件
开始之前请确保环境中的分布式集群满足以下条件;若不满足任意一项,都将导致 Region Migration 失败。
使用 Remote WAL
使用共享存储(例:AWS S3)
我们以名为 monitor 的数据表为例,并演示如何将数据表分区(Region)迁移到另一个 Datanode 节点上。
sql
CREATE TABLE monitor (
host STRING,
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP() TIME INDEX,
cpu DOUBLE DEFAULT 0,
memory DOUBLE,
PRIMARY KEY(host));并写入一些数据:
sql
INSERT INTO monitor
VALUES
("127.0.0.1", 1702433141000, 0.5, 0.2),
("127.0.0.2", 1702433141000, 0.3, 0.1),
("127.0.0.1", 1702433146000, 0.3, 0.2),
("127.0.0.2", 1702433146000, 0.2, 0.4),
("127.0.0.1", 1702433151000, 0.4, 0.3),
("127.0.0.2", 1702433151000, 0.2, 0.4);查询数据表分区(Region)分布
首先我们需要查询该数据表分区(Region)分布情况,即查询数据表中的 Region 分别在哪一些 Datanode 节点上。
sql
select
b.peer_id as datanode_id,
a.greptime_partition_id as region_id
from
information_schema.partitions a
left join
information_schema.greptime_region_peers b
on a.greptime_partition_id = b.region_id
where a.table_name='monitor'
order by datanode_id asc;查询结果如下,该数据表总共包含一个 Region,Region ID 为 4398046511104,并在运行在 Datanode ID 为 1 的节点上。
sql
+-------------+---------------+
| datanode_id | region_id |
+-------------+---------------+
| 1 | 4398046511104 |
+-------------+---------------+
1 row in set (0.01 sec)执行 Region 迁移
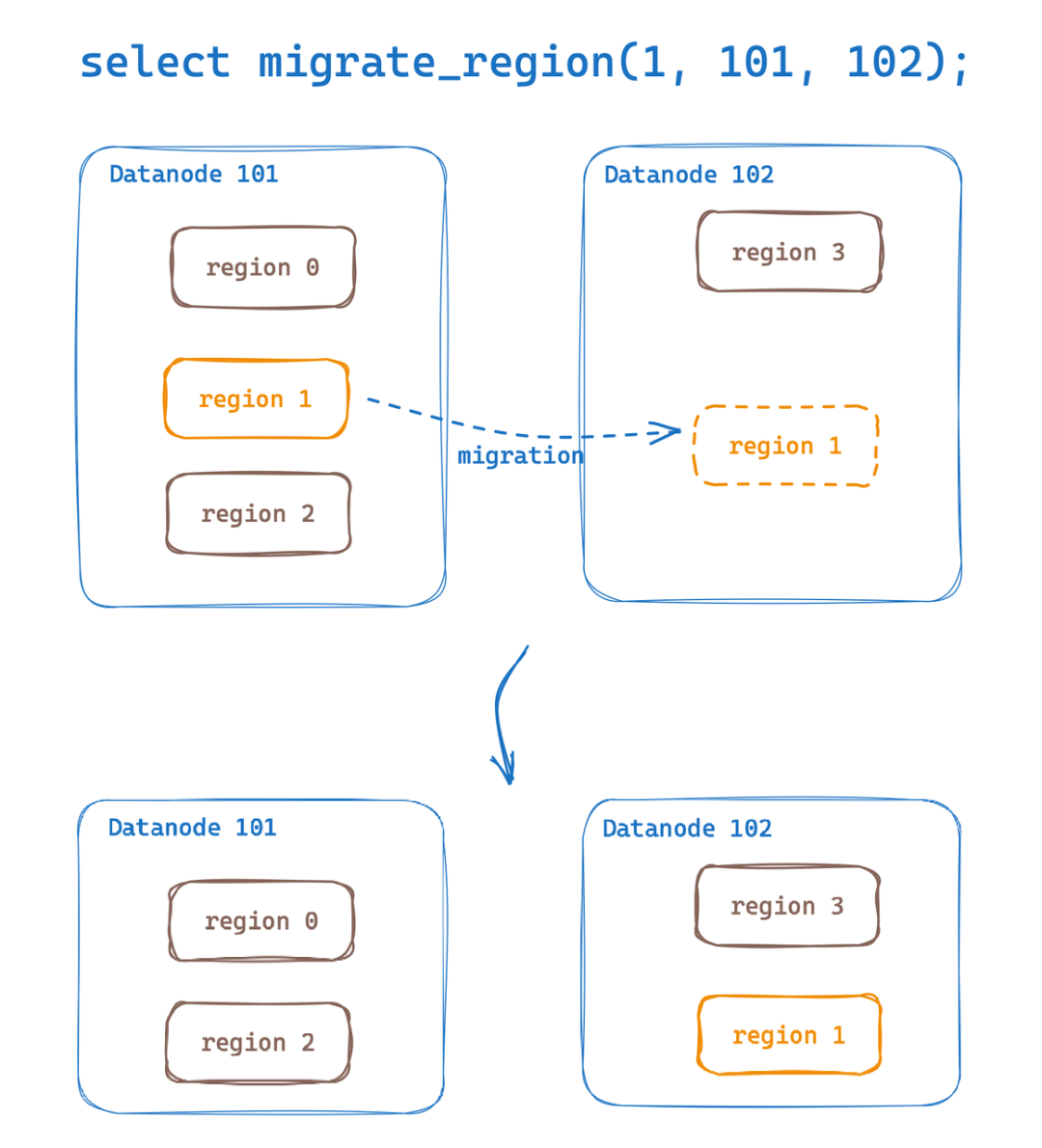
我们可以将数据表的 Region 迁移至另一个不同的节点上(演示集群包含 3 个 Datanode 节点,ID 分别为 0、1、2)。
如下所示,会将 ID 为 4398046511104 的 Region 迁移至 Datanode ID 为 2 的节点上。
🌟 第四个参数为可选参数(默认值为 10s),用于设置迁移 Region 的 Replay Timeout (secs)。若 Kafka 到 Datanode 之间节点网络带宽过小且导致无法按时完成迁移时,可适当调大该参数。
sql
select migrate_region(4398046511104, 1, 2, 60);sql
+------------------------------------------------------------------+
| migrate_region(Int64(4398046511104),Int64(1),Int64(2),Int64(60)) |
+------------------------------------------------------------------+
| 0f65f485-2790-4bf3-8b71-74f73ef15457 |
+------------------------------------------------------------------+
1 row in set (0.00 sec)迁移执行后会返回执行迁移的 Procedure ID,可通过该 ID 查询迁移状态。
查询迁移状态
sql
select procedure_state('0f65f485-2790-4bf3-8b71-74f73ef15457');sql
+---------------------------------------------------------------+
| procedure_state(Utf8("0f65f485-2790-4bf3-8b71-74f73ef15457")) |
+---------------------------------------------------------------+
| {"status":"Done"} |
+---------------------------------------------------------------+
1 row in set (0.00 sec)当查询返回 status 为 Done 时,表明该 Procedure 已成功执行完成。
查询迁移后的 Table Region 信息
当我们再次查询 Table Region 信息时,可以注意到 Region 已经被迁移到 ID 为 2 的 Datanode 上。
sql
select * from information_schema.greptime_region_peers;sql
+---------------+---------+--------------------------------------------------------------+-----------+--------+--------------+
| region_id | peer_id | peer_addr | is_leader | status | down_seconds |
+---------------+---------+--------------------------------------------------------------+-----------+--------+--------------+
| 4398046511104 | 2 | greptimedb-datanode-2.greptimedb-datanode.my-greptimedb:4001 | Yes | ALIVE | NULL |
+---------------+---------+--------------------------------------------------------------+-----------+--------+--------------+
1 row in set (0.02 sec)更多内容
想了解更多关于 GreptimeDB 分布式版本的内容,欢迎阅读相关文章,更深入了解 GreptimeDB 的分布式能力,发挥更大的价值。
使用 Helm Chart 部署分布式 GreptimeDB
本篇文章旨在帮助您充分认识和使用 GreptimeDB 分布式版本的强大功能,为您的数据管理和分布式计算带来更大的便利和效益。若在使用中遇到任何疑问或困难,我们鼓励您查阅相关文档,以深入理解系统的各个方面。
同时,社区也是一个宝贵的支持网络,欢迎您积极参与讨论,向经验丰富的用户和开发团队请教,获取及时而专业的支持。如果您遇到任何问题,欢迎前往 GitHub Discussion 进行讨论,也可以扫码添加下方小助手微信,加入技术交流群。我们期待您的反馈!
关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack

