本页内容
引言
一个 pipeline 工具,除了能支持多种数据协议,对于事件(Metric,Log,Trace)发送的可靠度也是用户的重要考量之一。
Pipeline 工具遇到上游故障或者业务尖峰时,可能会出现写入量激增的情况。此时如果下游存储无法承受如此大的数据量,就会出现“雪崩效应”,导致整个可观测线路出现异常:不仅会丢失业务指标数据,而且还会丢失监控使故障排查雪上加霜。
一般情况下 pipeline 和下游在做容量规划时,需要考虑流量尖刺的情况。因为业务在正常情况下需要相对较高的资源来应对流量尖刺,一般的解决方案是通过下游的动态扩缩容或者增加队列来削峰,但是这两种方案,前者依赖下游存储的设计,后者支持的协议相对单一。为了提供一个解决问题的思路,Vector 引入了 buffer 和 Rate Limits 机制。
Buffer:容纳 Sink 接收事件数据
顾名思义,类似于一个池子,用于容纳 sink 接收的事件数据,我们可以将大部分的 sink 拆分为 buffer 和请求两个组件。请求组件会不断地从 buffer 获取事件,再按照对应的协议要求,组织事件发送到下游。Buffer 可以理解为上游 source transform 与 sinks 连接的蓄水管道。
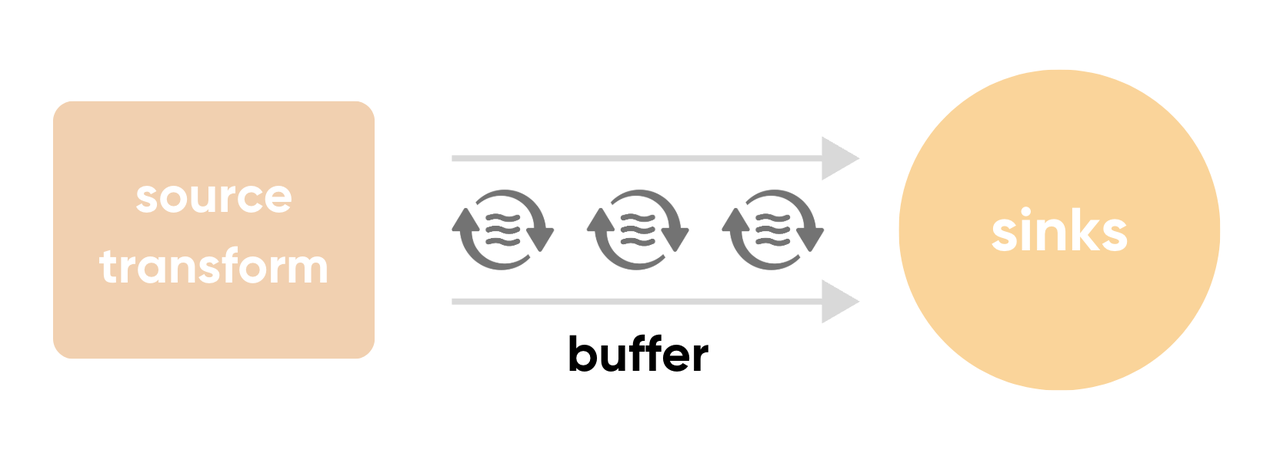
当一个事件被分发到 sink 后,从上游来的数据会首先尝试进入该 sink 的 buffer ,根据 buffer 的状态来决定其行为。如果 buffer 有剩余空间,则事件会被立即写入 buffer;如果下游消费不足,buffer 则处于满载的状态,将根据配置来具体决定这一情况的行为。
Buffer 的分类
Memory
顾名思义,这种 buffer 的数据只存在于内存当中。Vector 默认为每个 source 都创建一个可以容纳 500 条事件的 memory buffer,且 when_full 策略为 block。以这种策略配置的 buffer,会在容量耗尽后阻塞上游的写入操作,占据上游的资源。如果对于数据的完整性有更高要求,并且不想因为阻塞而影响写入端,可以考虑把配置修改为 drop_newest。这种策略会在 buffer 容量耗尽后直接丢弃掉事件,避免对写入端的影响。
Memory 种类的 buffer 好处在于发送和接收事件的速度非常快,基本上没有额外开销。但是一方面内存资源属于价格较高的资源之一,需要对 buffer 的容量设置一个合理的值才不会导致内存的浪费,或者超出内存限制而崩溃;另一方面,进程或者机器故障重启都会导致内存中的数据丢失。这对于数据完整性要求高的应用是无法接受的,因此 Vector 提供了 disk buffer 来解决这些缺点。
Disk
Disk 会将 buffer 中的数据写到文件中,当进程重启后可以通过文件恢复之前 buffer 内的数据。这样就避免了内存 buffer 重启后丢失数据的问题,但是文件会有额外的读写开销,这会导致 disk 类型的 buffer 比 memory 类型的事件消费速率要慢,但获得了相对高的数据完整性。
为什么是相对高的数据完整性?因为 Vector 的 disk buffer 实现不像数据库 WAL 那般要求非常高的数据完整性。它只会将 buffer 中的数据以 500ms 的间隔写入文件(但不是每个事件都写入文件),在这 500ms 内,内存中的数据和文件中的数据是不一致的,这就会导致恢复的时候部分事件被重放或者丢弃。
这么看来两种 buffer 种类虽然解决了一部分削峰的问题,但是各有优劣,需要用户根据自身的需求来决定选择哪种 buffer。Vector 还提供了组合两种 buffer 的机制,可以将 buffer 分为多级 buffer,这里不再详述。
虽然有了 buffer 缓存一部分数据,但 Vector 会以下游的最高速度来下发数据,这样流量尖刺依然会传递到下游,为了保证在容量规划内保持更稳定的流量,我们就需要有一些限流措施来保护下游组件。
Rate Limits 和 Batch
在大规模数据写入的情况下,对数据进行攒批(batch)是一种非常常见的策略,它可以大幅度提高吞吐量。在 Vector 中,所有使用 HTTP 协议写入数据的 sink 都会将事件进行攒批,这样可以在同一个请求里共用一部分数据,且能减少 HTTP 协议本身所需要的消耗。
实现 greptime_logs 这个 sink 时,直接使用 Vector 提供的、非常灵活且健全的 HTTP 请求构建组件,能够给我们提供以下几种开箱即用的功能:
丰富的编码格式,可以自由地组织 body 的组成方式,JSON,Protobuf 等;
现成的
metrics集成;自适应并发控制、重试,以及
rate_limit。
Vector HTTP 组件的配置被 Vector 抽象成了一个 struct TowerRequestConfig。在实现 sink 时,需要定义一个 config struct 对 sink 进行配置。在这个 config struct 引入 HTTP 组件的功能,仅需直接引入 TowerRequestConfig 并且在构造 sink service 的时候使用这个配置即可,非常方便。
通过阅读 Vector 的代码可知,其 HTTP 组件底层使用了 Tower 作为 HTTP 的客户端,下面的配置会直接作用在 Tower 中的 service。Service 是一个请求中间层,包含了一些状态,帮我们管理了并发控制、重试和 rate_limit 的状态流转。
toml
batch.max_events = 1000
request.rate_limit_duration_secs = 1
request.rate_limit_num = 1如上所示的数字示意为:
batch.max_events代表每个 batch 的最大事件数量(单位个);request.rate_limit_duration_secs为限流的窗口时间(单位秒);request.rate_limit_num则是每个窗口时间中的最大请求数(单位个)。
将上面的配置参数最终反应到事件数量上,即表示单位时间内只允许最多 batch.max_events * request.rate_limit_num / request.rate_limit_duration_secs 个事件。
通过这样的配置下游的压力就趋于恒定,只要 buffer 的大小设置合理,流量尖峰时的数据就会暂时缓存在 buffer 内,下游会因为流控的存在感受不到流量尖峰。这对下游的基础组件来说是一种保护性质的措施,不至于击溃整条链路,对整个链路的健壮性和数据完整性给予了一定的保证。
小结
通过组合 Vector 提供的 buffer 和 rate limit 机制,我们就可以获得一个比较健壮的数据链路,对上游和下游都起到了一定的保护作用,并且在相对恒定的资源下可以应对正常的流量起伏,节省了链路的硬件成本。
Vector 系列文章:
后续文章持续更新中,敬请关注。
关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack

