
本页内容

在现代云原生架构中,Kubernetes 已成为主流的容器编排平台。随着微服务架构的普及,应用程序的复杂性不断增加,如何高效地收集和处理数据成为了运维团队面临的一大挑战。Vector 是一个高性能的数据管道,能够在 Kubernetes 环境中提供极佳的可观测性解决方案。
Kubernetes 中监控需要收集哪些数据
在 Kubernetes 环境中,运维团队需要监控并收集多种类型的数据来保证系统的稳定性和可观测性,包括日志(Logs)、指标(Metrics)和事件(Events)等。这些数据的收集与处理对于诊断问题、优化性能和提升服务可靠性至关重要。
日志(Logs)
日志是系统运行时产生的文字记录,用于追踪应用程序或服务的运行状态。日志包含关于请求、错误、警告等重要信息,对于排查故障和监控系统行为至关重要。在 Kubernetes 中,日志通常有以下几种来源:
容器日志:每个容器都会生成标准输出(stdout)日志,这些日志可以用于分析容器的运行情况,包括异常和崩溃的原因;
操作系统日志:Kubernetes 节点所在机器上的日志,如
/var/log/messages和dmesg。在排查 Kubernetes 节点问题时,这些日志是重要的辅助工具,可以帮助定位底层原因;Kubernetes 组件日志:如 kubelet、kube-apiserver、kube-controller-manager 等 Kubernetes 组件本身的日志,这些日志可以帮助运维人员了解集群管理和调度情况。
指标(Metrics)
指标通常用于诊断系统性能和健康状况。在 Kubernetes 中,可以从多个层面来收集 Metrics:
节点指标:如 CPU 使用率、内存使用量、磁盘和网络 I/O 等,这些数据有助于了解集群节点的健康状况;
Pod 和容器指标:包括容器的 CPU、内存、网络流量等,帮助监控每个 Pod 或容器的资源消耗情况;
应用程序指标:微服务应用会暴露一些特定的指标,如请求响应时间、TPS(每秒事务数)、错误率等,这些指标对跟踪应用程序的性能尤为重要。
事件(Events)
事件是 Kubernetes 中发生的系统级操作和状态变化的记录,通常用于帮助运维人员发现问题。例如,Pod 启动失败、调度失败、容器崩溃等都会触发事件记录。Kubernetes 中的事件包含以下内容:
Pod 和容器的生命周期事件:如 Pod 启动、停止、重启等;
调度事件:当调度器做出决策时,会记录有关调度的事件信息;
健康检查和资源管理事件:当某个资源或服务达不到设定的健康阈值时,Kubernetes 会生成事件通知。
Vector 在 Kubernetes 中的部署模式
在 Kubernetes 环境中,Vector 通常以 DaemonSet 或 Pod 形式部署。选择何种部署方式通常取决于收集数据的范围和需求。
使用 DaemonSet 部署 Vector
DaemonSet 是 Kubernetes 中的一种控制器,确保集群中每个节点上都运行一个副本的 Pod。部署 Vector 为 DaemonSet 有以下几个优点:
全节点覆盖:确保每个节点都有一个 Vector 实例,能够收集来自每个节点的日志、指标和事件;
集中管理:通过 Kubernetes 原生的管理方式,更方便地进行升级、故障恢复等操作。
高效资源利用:由于每个节点都运行一个 Vector 实例,它能尽量减少对其他应用程序资源的影响,优化集群资源使用。
使用 Pod 部署 Vector
如果收集的范围仅限于某些特定的应用或服务,Vector 也可以作为普通 Pod 部署,与 DaemonSet 部署相比,使用 Pod 部署 Vector 具有更大的灵活性,使用 Pod 部署 Vector 适用于以下几种情况:
特定应用监控:如果只需要收集某个特定服务或容器的日志和指标,而不需要覆盖整个集群时,可以将 Vector 部署为独立的 Pod;
资源隔离:Vector 仅与某些特定应用一起部署,为避免与集群中其他服务共享资源,可以使用 Pod 部署 Vector。这样可以避免其他节点的资源使用对 Vector 性能产生影响;
测试和实验:在测试或实验阶段,使用 Pod 部署 Vector 可以更灵活地调整部署配置、测试不同的输入输出目标或处理规则。
为什么选择 DaemonSet 部署 Vector
将 Vector 部署为 DaemonSet 是 Kubernetes 中最常见的做法,原因如下:
容器化的灵活性:每个 Kubernetes 节点上运行一个 Vector 实例,可以确保从所有节点收集日志和指标,提升数据收集的完整性;
数据的本地化处理:DaemonSet 部署保证了日志、指标和事件可以在数据产生的节点进行处理,减少了网络传输的开销和延迟;
易于扩展和维护:随着集群的扩容,新的节点会自动加入到 DaemonSet 中,确保监控的扩展。
在 Kubernetes 中使用 Vector
在 Kubernetes 中部署 Vector 非常简单,以下是一个基本的部署示例,我们将 Kubernetes 节点的 host_metrics 和容器日志发送到 GreptimeDB:
提示:首先需要安装 Helm 工具,可以根据安装文档 中的说明进行安装。
- 在部署应用程序之前,需要将 Vector 仓库 添加到 Helm 中:
bash
helm repo add vector https://helm.vector.dev
helm repo update- 接着,创建一个
values-vector.yaml来存储 Vector 的配置文件:
yaml
role: "Agent"
tolerations:
- operator: Exists
service:
ports:
- name: prom-exporter
port: 9598
containerPorts:
- name: prom-exporter
containerPort: 9598
protocol: TCP
customConfig:
data_dir: /vector-data-dir
sources:
kubernetes_logs:
type: kubernetes_logs
host_metrics:
type: host_metrics
collectors:
- cpu
- memory
- network
- load
namespace: host
scrape_interval_secs: 15
transforms:
kubernetes_container_logs:
type: remap
inputs:
- kubernetes_logs
source: |
.message = .message
.container = .kubernetes.container_name
.pod = .kubernetes.pod_name
.namespace = .kubernetes.pod_namespace
sinks:
logging:
compression: gzip
endpoint: http://greptimedb.default:4000
table: kubernetes_container_logs
pipeline_name: kubernetes_container_logs
inputs:
- kubernetes_container_logs
type: greptimedb_logs
metrics:
type: greptimedb_metrics
inputs:
- host_metrics
dbname: public
endpoint: greptimedb.default:4001- 部署 Vector
创建运行 Vector 实例:
bash
helm upgrade --install vector vector/vector --values values-vector.yaml -n default查看 Vector 实例:
bash
kubectl get po -n default
NAME READY STATUS RESTARTS AGE
vector-6ggnt 1/1 Running 0 3m49s- 访问数据
在 Vector 配置文件的 customConfig.sources.host_metrics 中,我们定义了收集 Kubernetes 节点的四种指标类型,分别是 CPU、memory、network 和 load,通过 customConfig.sinks.metrics 发送到 GreptimeDB。访问 GreptimeDB dashboard 可以查看这四种指标的详细内容:
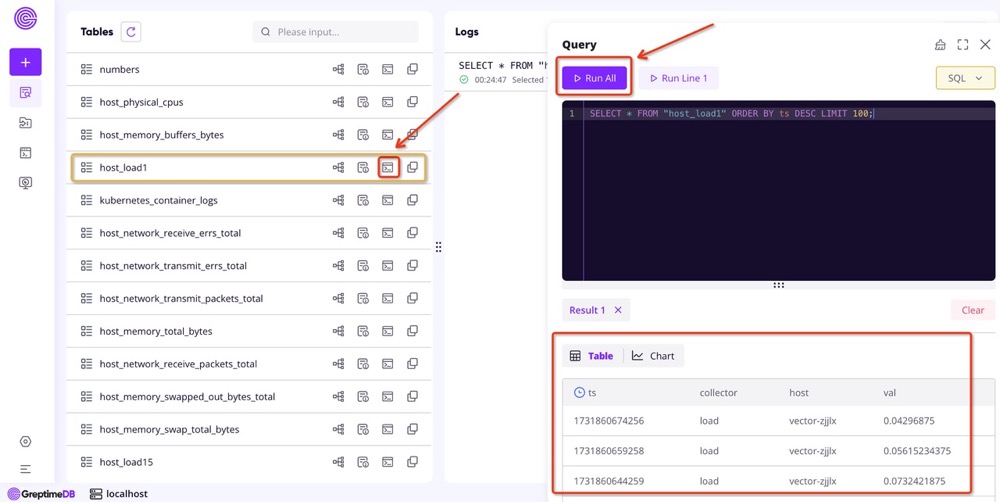
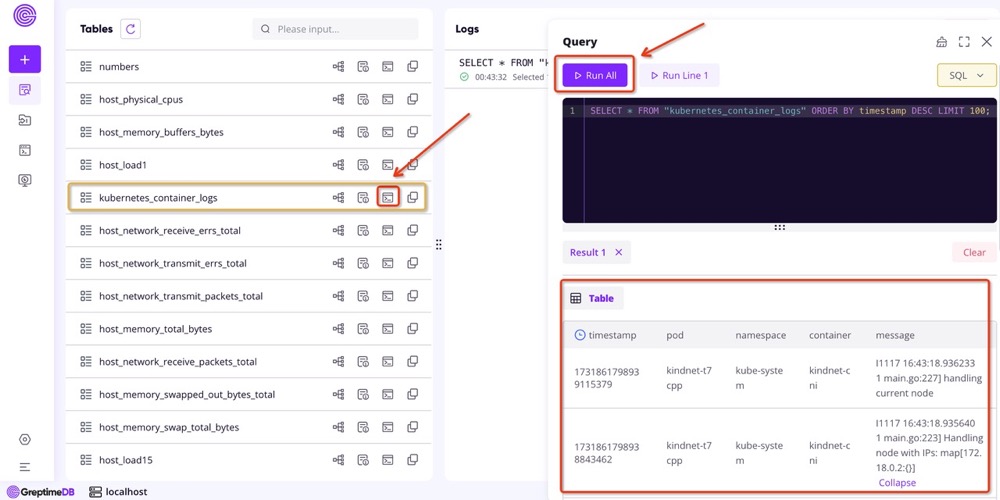
Vector 配置中的 customConfig.sources.kubernetes_logs 定义了采集 Kubernetes 容器日志的方式,通过 customConfig.sinks.logging 将 Kubernetes 的容器日志发送到 GreptimeDB 的 kubernetes_container_logs 表中,查询这张表可以查看所有的容器日志:
总结
Vector 是一个强大且灵活的日志和指标收集工具,特别适合在 Kubernetes 环境中使用。通过其高性能、灵活的配置和强大的数据处理能力,Vector 可以帮助团队监控云原生应用程序。无论是处理日志、指标还是事件,Vector 都能提供可靠的解决方案,助力 DevOps 和 SRE 团队提升工作效率和系统稳定性。
Vector 系列往期文章:
后续文章发布中,敬请期待!
关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack

