本页内容
JSONBench 是今年初由 ClickHouse 团队推出的 OLAP 基准测试套件,专注于对 JSON 文档执行分析型查询。该测试使用从 Bluesky 导出的 10 亿条 JSON 文档来运行分析查询。初始测试的范围涵盖 ClickHouse、Elasticsearch、MongoDB、DuckDB 和 PostgreSQL 等数据库,后续预计增加 VictoriaLogs 参与对比。
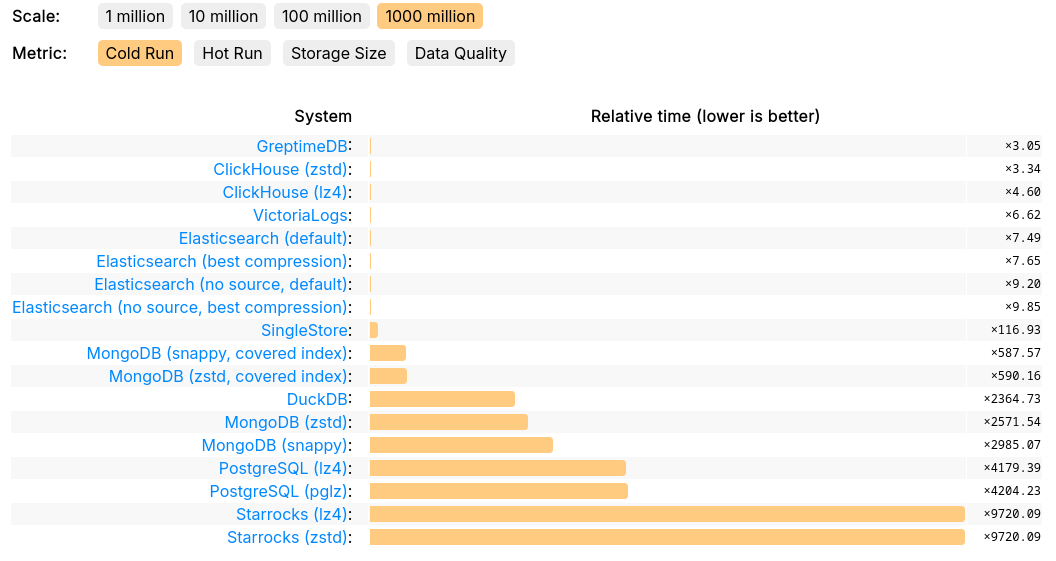
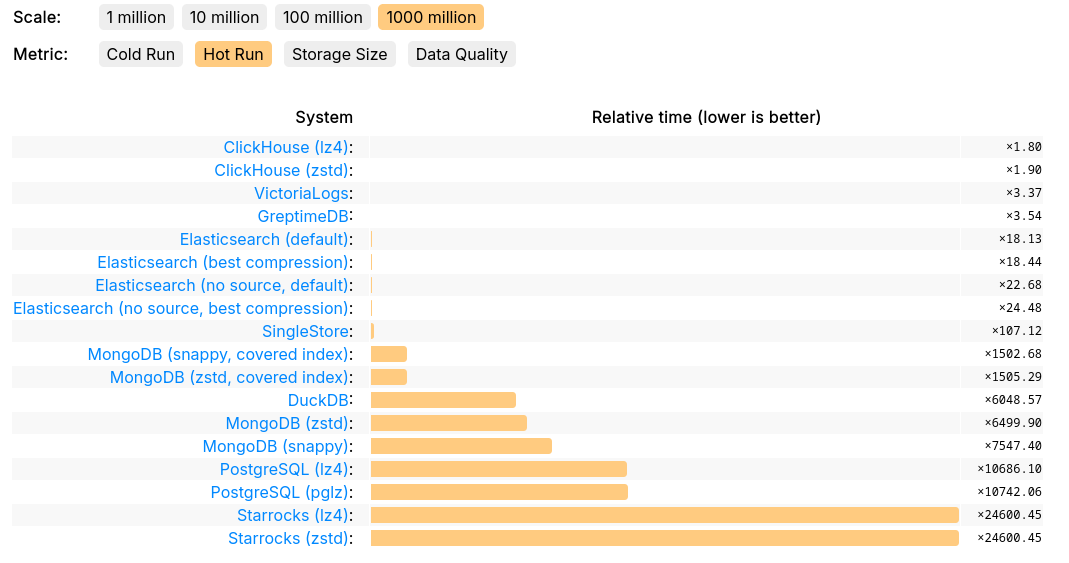
GreptimeDB 在 JSONBench 中的表现验证了其处理海量数据集的竞争力,性能与 ClickHouse 和 VictoriaLogs 处于同一梯队。在查询速度方面,GreptimeDB 以十亿级冷启动查询斩获榜首,在多数查询场景中展现优于 Elasticsearch、DuckDB、StarRocks 和 PostgreSQL 的性能。其采用的高效存储引擎在压缩比和 I/O 性能方面显著优于传统存储格式,实现了卓越的存储效率。

作为面向海量可观测数据设计的新一代实时数据库,GreptimeDB 通过原生 JSON 支持应对结构化日志采集趋势。其内置 Pipeline(ETL)引擎与云原生架构深度整合,充分发挥对象存储作为主数据存储和 Kubernetes 管理集群的优势,大幅降低实际应用场景的运营成本。
本文我们将深入解读 GreptimeDB 的 JSON 处理能力在基准测试中的表现,并揭示测试未覆盖但极具实用价值的进阶功能。
在 GreptimeDB 上复现 JSONBench
虽然测试流程已通过 JSONBench 仓库的 greptimedb 目录脚本实现自动化,但理解以下关键步骤仍具参考价值(需使用 GreptimeDB v0.13.1 及以上版本):
JSON 数据写入优化
推荐使用日志写入 API 实现高效 JSON 文档写入。虽然 GreptimeDB 支持原生 JSON 数据类型存储/查询,但为追求极致性能与存储效率,我们将元数据字段写入作为主键,并将其用作数据排序的主键,与其他数据库处理数据的方式类似:
yaml
# 数据处理 Pipeline 配置
processors:
- epoch:
fields:
- time_us
resolution: microsecond
- simple_extract:
fields:
- commit, commit_collection
key: "collection"
ignore_missing: true
- simple_extract:
fields:
- commit, commit_operation
key: "operation"
ignore_missing: true
# 字段类型转换规则
transform:
- fields:
- did
type: string
- fields:
- kind
- commit_collection
- commit_operation
type: string
index: inverted
tag: true
- fields:
- commit
type: json
on_failure: ignore
- fields:
- time_us
type: epoch, us
index: timestampPipeline 处理将自动生成一个表结构。在该 Pipeline 定义中,collection、operation 和 kind 字段被直接提取为标签(即主键)。通过 Pipeline 的数据定义能力,系统将自动生成如下 bluesky 表结构,这种自动化建表机制大幅简化了数据工程流程:
sql
CREATE TABLE IF NOT EXISTS "bluesky" (
"did" STRING NULL,
"kind" STRING NULL INVERTED INDEX,
"commit_collection" STRING NULL INVERTED INDEX,
"commit_operation" STRING NULL INVERTED INDEX,
"commit" JSON NULL,
"time_us" TIMESTAMP(6) NOT NULL,
TIME INDEX ("time_us"),
PRIMARY KEY ("kind", "commit_collection", "commit_operation")
)
ENGINE=mito
WITH(
append_mode = 'true'
)接下来,我们需要稍微调整一下 GreptimeDB 的 http 选项,以允许批量写入大型数据集,并禁止分析查询超时:
bash
# 提高请求大小限制
export GREPTIMEDB_STANDALONE__HTTP__BODY_LIMIT=1GB
# 关闭查询超时限制
export GREPTIMEDB_STANDALONE__HTTP__TIMEOUT=0完成配置后执行 start.sh 即可启动测试(建议使用 AWS EC2 m6i.x8large等同规格环境复现结果)。
GreptimeDB 的实战优势
对象存储深度集成
官方测试未充分体现 GreptimeDB 的革命性设计:将对象存储(如 AWS S3 或阿里云 OSS 等)作为主数据后端,本地磁盘仅用于缓存。该架构突破存储容量限制,显著降低海量可观测数据存储成本。
我们在 1GB 本地缓存条件下对 1 亿文档进行对象存储(S3)测试时发现:
- 冷启动首次查询:因缓存预热略有延迟;
- 后续查询:性能与本地磁盘方案基本持平;
- 最终结果:GreptimeDB 在成本效益与高性能之间的平衡能力超强。
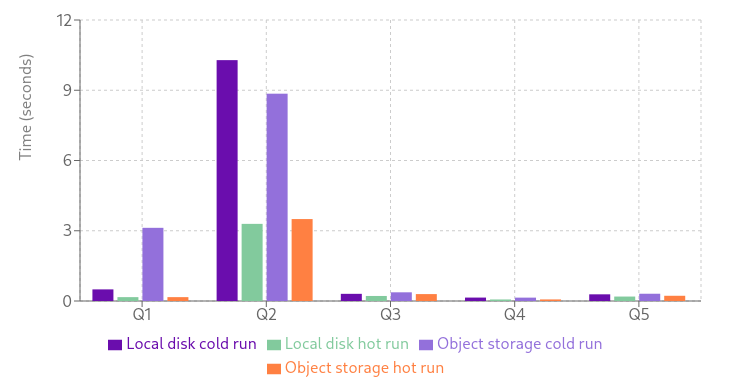
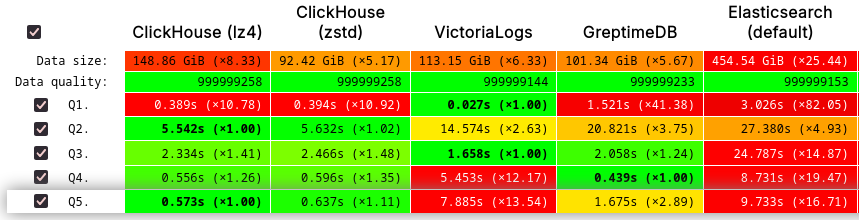
Q1 的绝对值可能不具有特别的意义,因为它主要反映的是缓存预热所需的时间,但其余数据表明,与本地磁盘相比,使用对象存储作为主后端仍能提供强大的性能。在实际应用场景中,这意味着在不影响服务质量的前提下节省了大量成本。
流式计算引擎
对于某些 COUNT 查询,GreptimeDB 的执行速度比部分友商稍慢,因此 GreptimeDB 对这些类型的查询和更复杂的聚合查询提供了一个内置流引擎,以增量方式计算结果。如果用户需要将此类查询用于仪表盘或实时分析,强烈建议使用我们的流引擎,以显著提高性能。
针对 COUNT 类查询的优化需求,GreptimeDB 内置的流式计算引擎可将复杂聚合查询性能提升 10 倍以上。以 Q1 查询为例,通过 Flow 任务实现毫秒级响应:
sql
-- 创建实时统计流
CREATE FLOW live_count
SINK TO bluesky_count_by_event
AS
SELECT
commit_collection AS event,
count(1) AS cnt
FROM
bluesky
GROUP BY event;启用流式计算后,亿级数据集的统计查询耗时从 165ms 降至 4.5ms,实现近 O(1) 时间复杂度:
sql
public=> select event, cnt from bluesky_q1 order by cnt desc;
event | cnt
----------------------------+----------
app.bsky.feed.like | 44994712
app.bsky.graph.follow | 36362556
app.bsky.feed.post | 8740921
app.bsky.feed.repost | 5625691
app.bsky.graph.block | 1433188
app.bsky.actor.profile | 1118161
app.bsky.graph.listitem | 913702
| 603435
app.bsky.graph.listblock | 86211
app.bsky.graph.list | 35906
app.bsky.graph.starterpack | 35656
app.bsky.feed.threadgate | 28676
app.bsky.feed.postgate | 12751
app.bsky.feed.generator | 7636
app.top8.theme | 246
app.bsky.labeler.service | 40
app.kollective.catalog | 23
app.kollective.profile | 3
(18 rows)
Time: 4.522 ms结语
JSONBench 验证了 GreptimeDB 在事件和日志处理领域的卓越能力,我们由衷感谢 ClickHouse 团队构建的严谨测试框架。
未来我们将拓展该框架至 Prometheus 查询等更多可观测场景,敬请期待技术演进!
关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack

