
本页内容
摘要
在前端可观测分析场景中,需要实时观测并处理多地、多环境的运行情况,以保障 Web 应用和移动端的可用性与性能。传统方案往往依赖代理 Agent ➡️ 消息队列 ➡️ 流计算引擎 ➡️ OLAP 存储的多级架构,虽然能满足基本数据接入与查询需求,但面临以下困难与挑战:
分层架构的精细化演进
当前分层模型在支撑多业务场景时,需要为分钟级、小时级、天级等不同时间粒度的数据视图分别构建计算链路。这种模式在保障灵活性的同时,可能存在存储与计算资源的重复消耗现象,如何通过增量计算或动态视图技术实现"一次计算多级复用",或将成为提升资源利用效率的关键突破点。
复杂分析场景的效能平衡
在应对全量 Join、多维交叉分析等高复杂度场景时,现有的按量计费机制与计算资源调度策略,可能在高频业务周期(如大促活动)中面临成本曲线的非线性增长挑战。探索预计算加速、智能冷热分层与弹性资源调度的深度结合,或许能进一步释放大规模分析场景的性价比潜力。
生产环境的安全加固:
基于 SQL 的敏捷开发模式在提升数据处理效率的同时,也对企业级数据资产管理提出了更高要求。通过强化语法预校验、分区保护机制、操作审计追溯等防护手段,构建覆盖开发、测试、发布全流程的可靠性护城河,将有效降低误操作风险并提升数据治理成熟度。
本文聚焦将前端可观测后端数据分析场景演进到 GreptimeDB 的实践,深入剖析如何利用 GreptimeDB Flow 引擎实现 10s、1m、10m 等多粒度持续聚合,结合 HyperLogLog 与 UDDsketch 函数,为前端可观测场景提供高性能、低成本且易于运维的端到端解决方案。
部署架构

为解决前述痛点,逐步将时序/观测数据场景迁移至 GreptimeDB,并借助其内置的 Flow 引擎(SQL)自动维护秒级、分钟级、小时级等多精度下采样表,可极大简化分层建模和物化视图运维。
GreptimeDB 分布式架构
采用 GreptimeDB 开源的分布式模式,在这种模式下,GreptimeDB 的节点可以分为如下角色:
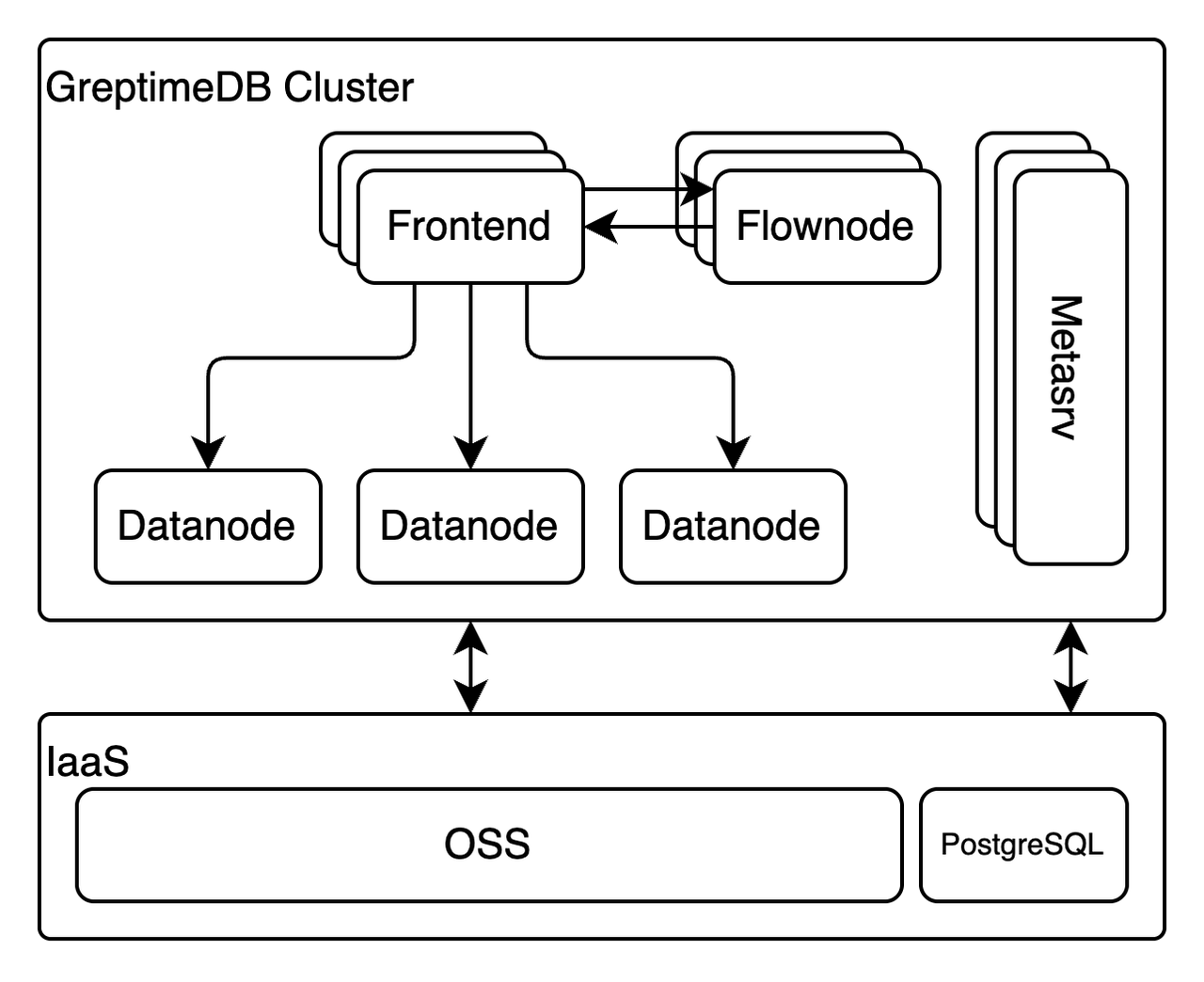
- Frontend:负责协议处理、请求校验和鉴权、初步查询优化,是一个无状态节点,可以根据负载任意扩缩容;
- Datanode:负责管理数据分片、处理数据写入和持久化以及执行具体的查询;
- Flownode:对于配置了流计算任务的集群,Flownode 负责接受 Frontend 镜像而来的写入请求并执行流计算任务。流计算的结果最终会被写入到 Datanode 中进行持久化;
- Metasrv:GreptimeDB 的控制面组件,负责管理集群的元数据(如表的分片路由信息等)。Metasrv 本身是无状态的,这里我们采用 PostgreSQL 作为后端存储。
透明数据缓存
GreptimeDB 对数据访问层进行了高度的抽象,负责管理数据分片的 Datanode 并不需要感知到数据文件位于本地磁盘还是对象存储。但是考虑到当使用对象存储时数据文件的访问延迟会大大增加,因此 GreptimeDB 设计了多层的透明数据缓存来解决此问题。
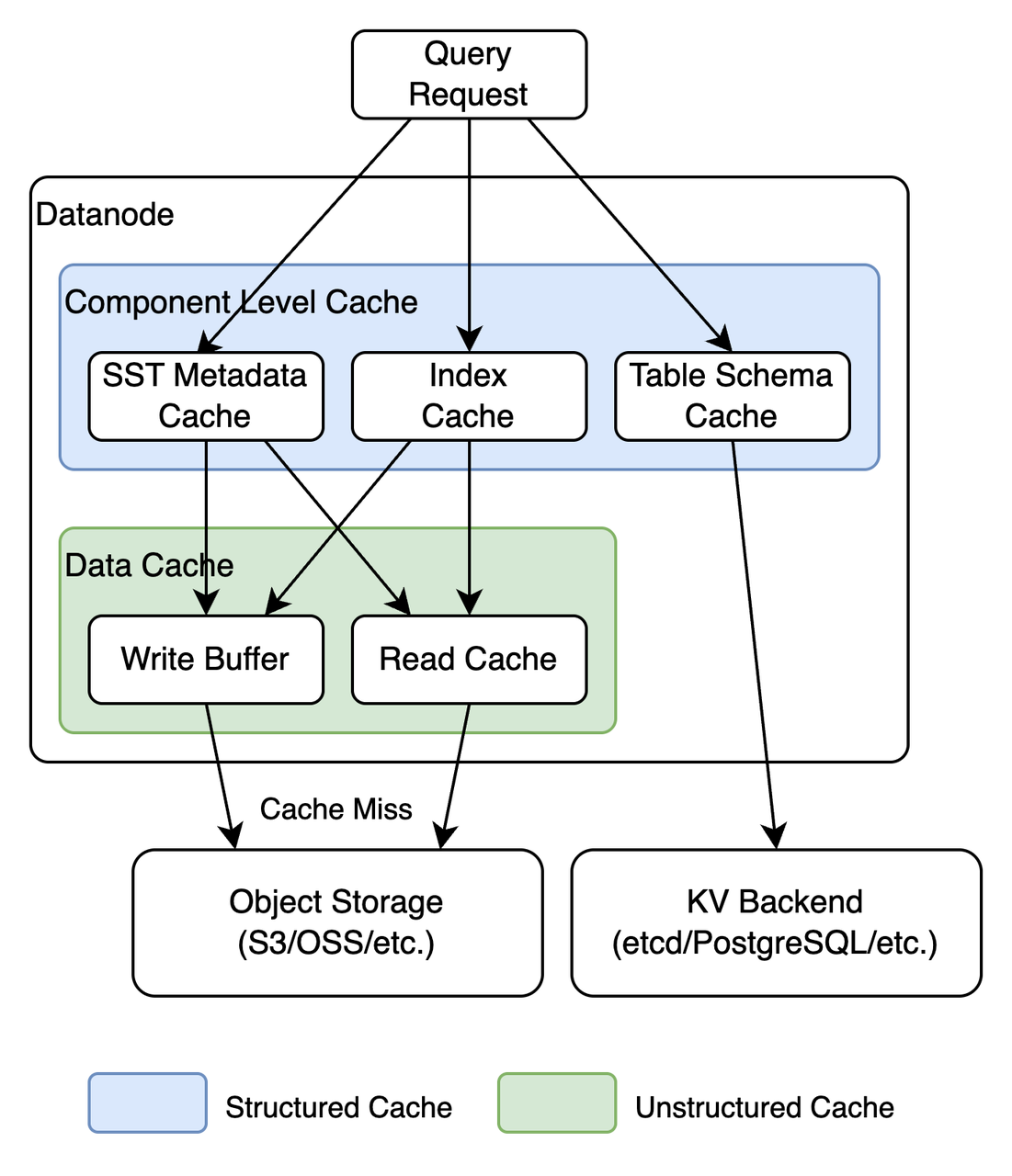
GreptimeDB 的缓存结构如上图所示。从缓存所在位置可以分为磁盘缓存和内存缓存两类:
磁盘缓存的数据来源通常是对象存储,其类似于操作系统的 page cache,只不过 page cache 是利用内存加速磁盘数据的访问,而 GreptimeDB 的这部分缓存则是利用磁盘加速对象存储的访问,将频繁访问的文件按范围缓存到磁盘可以实现更低的查询延迟,并且能够智能根据访问模式实现预取(prefetch)、IO 合并等优化。
内存缓存除了原始的文件内容之外也包括从磁盘/对象存储的原始内容反序列化出来的数据结构,如字段的
min/max,bloomfilter等等。
而从数据类型来分可以分为结构化和非结构化两类:
非结构化缓存的内容通常是文件的二进制内容,而缓存的 key 则是文件名加上字节范围。比如在 flush 的过程中写入到对象存储的文件往往是大概率很快就会被查询的热数据,因此可以在本地缓存一份避免查询请求穿透到对象存储。
结构化缓存则是文件、索引的内容或元数据反序列化得到的结构体,这些数据在查询剪枝时频繁被用到,因此 GreptimeDB 缓存了反序列化之后的结构,避免频繁反序列化带来的开销。
尽管 GreptimeDB 的缓存机制较为复杂,但是用户无需过多了解细节,只需要给定特定的缓存大小,GreptimeDB 会自动分配各类缓存的配额以及管理缓存的分配和释放,具体调优指南请参考这里。
无畏扩缩容
GreptimeDB 的最小数据读写单元是表的数据分片(称之为 region)。Region 可以在不同的节点之间进行迁移。目前开源版本的 GreptimeDB 支持手动通过 migrate_region 函数进行 region 的迁移。当监控发现某些 datanode 的负载较高时,可以将部分 region 迁移到其他较为空闲的 datanode 上避免可用性的降级。

此外,GreptimeDB 是面向云原生基础设施设计的数据库,其 Metasrv 节点能够实时采集各个节点的负载并且将流量在不同节点之间进行分配。对于不同的负载读写特性,还可以利用 Kubernetes 的弹性调度特性来调整不同节点组的副本数量来实现读写分离。关于 GreptimeDB 读写分离的实践,可以参考这篇文章。
GreptimeDB Flow 流计算实践
GreptimeDB Flow 是一个专为时序场景设计的轻量级流计算引擎。 它特别适用于提取——转换——加载 (ETL) 过程或执行即时的过滤、计算和查询,例如求和、平均值和其他聚合。通过在 Frontend 将写入流量镜像一份到 Flownode 进行计算再写回 Frontend 并进行持久化,它可以确保数据被增量和连续地处理,根据到达的新的流数据更新最终结果。
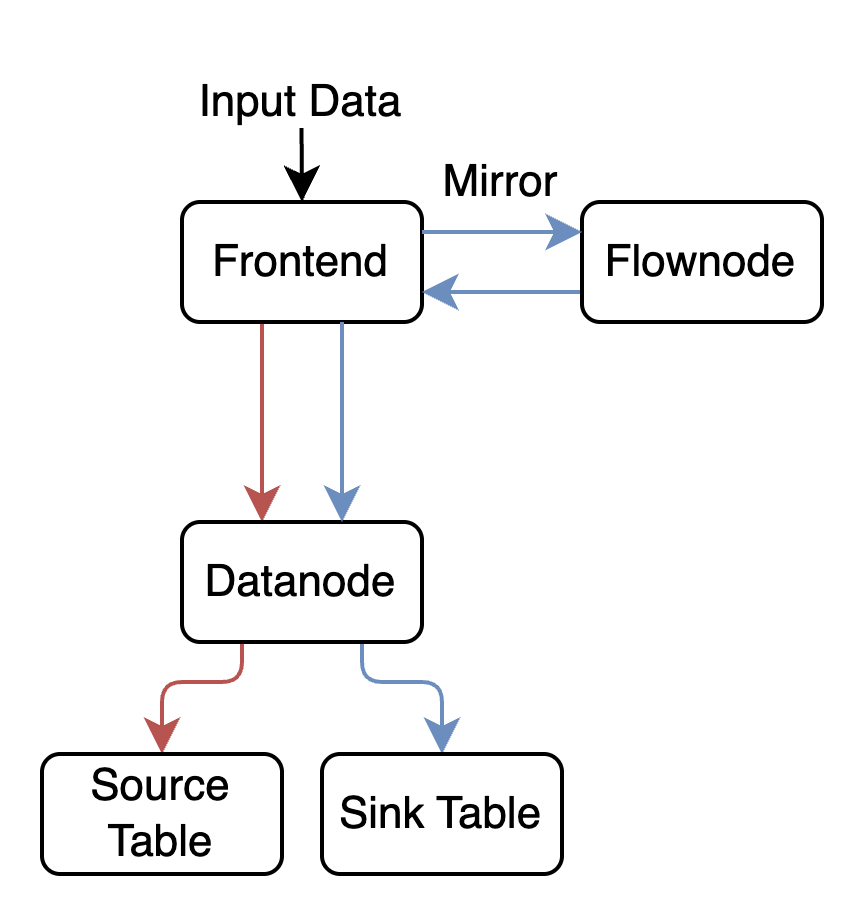
更加重要的是,编写一个 Flow 流计算任务无需额外的学习成本,它完全使用 SQL 语句定义计算任务。如以下语句:

定义了一个名叫 ngx_status_count 的任务,它负责流式地统计 ngx_access_log 表中每分钟内每个不同状态码的访问日志数量。在AS 之后的任务定义部分是一个标准的 SQL,因此对于熟悉 SQL 的开发者来说极容易上手。
多级持续聚合架构
10s 粒度热数据层
sql
CREATE FLOW rpc_cost_10s
SINK TO rpc_cost_10s_agg
EXPIRE AFTER '12hours'::INTERVAL
AS SELECT
app_name,
url,
date_bin('10s'::INTERVAL, timestamp) AS time_window,
uddsketch(cost_time_ms, 0.01, 0.001) AS cost_sketch
FROM rpc_cost_time
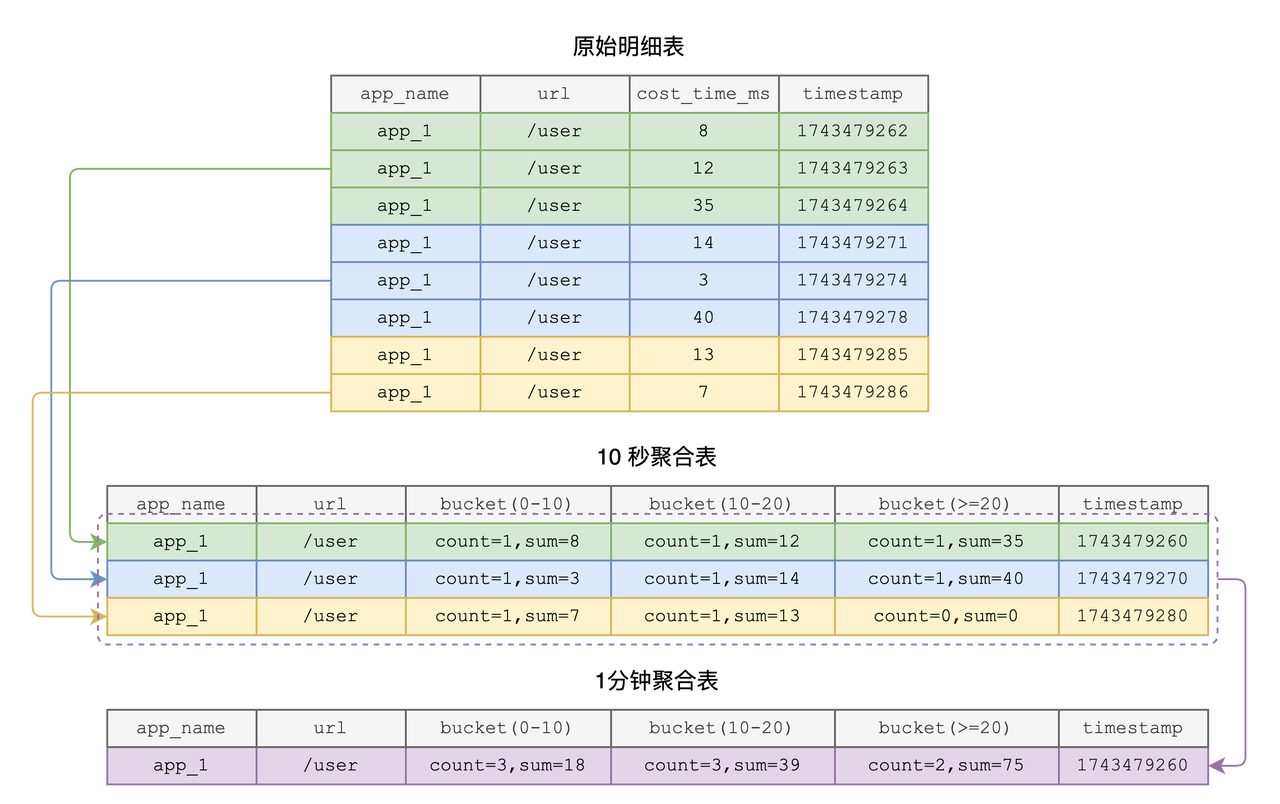
GROUP BY app_name, url, date_bin('10s'::INTERVAL, timestamp);说明:每 10s 计算一次 UDDsketch,近似捕获耗时分布,并写入“热表”,支持毫秒级查询。
1m 粒度中层 Roll‑up
sql
CREATE FLOW rpc_cost_1m
SINK TO rpc_cost_1m_agg
EXPIRE AFTER '30days'::INTERVAL
AS SELECT
app_name,
url,
date_bin('1m'::INTERVAL, time_window) AS time_window_1m,
uddsketch_merge(cost_sketch) AS cost_sketch_1m
FROM rpc_cost_10s_agg
GROUP BY app_name, url, date_bin('1m'::INTERVAL, time_window);说明:周期性合并 10s 粒度的 sketch,生成分钟级聚合,保留 30 天。
10m 粒度冷层
sql
CREATE FLOW rpc_cost_10m
SINK TO rpc_cost_10m_agg
EXPIRE AFTER '180days'::INTERVAL
AS SELECT
app_name,
url,
date_bin('10m'::INTERVAL, time_window_1m) AS time_window_10m,
uddsketch_merge(cost_sketch_1m) AS cost_sketch_10m
FROM rpc_cost_1m_agg
GROUP BY app_name, url, date_bin('10m'::INTERVAL, time_window_1m);说明:进一步合并至 10 分钟级,存入低成本对象存储,保留 180 天。
UV 近似统计:HyperLogLog
和耗时分布统计类似,统计各个 URL 的独立访问量(UV)也是常见的需求。不过想要精确统计特定时间段的 UV 成本是极高的,因此业界往往使用近似算法来实现 UV 计算,如 HyperLogLog。GreptimeDB v0.12 提供了对 HyperLogLog 相关函数的支持,结合 Flow 可以实现强大的任意时间段 UV 近似统计。
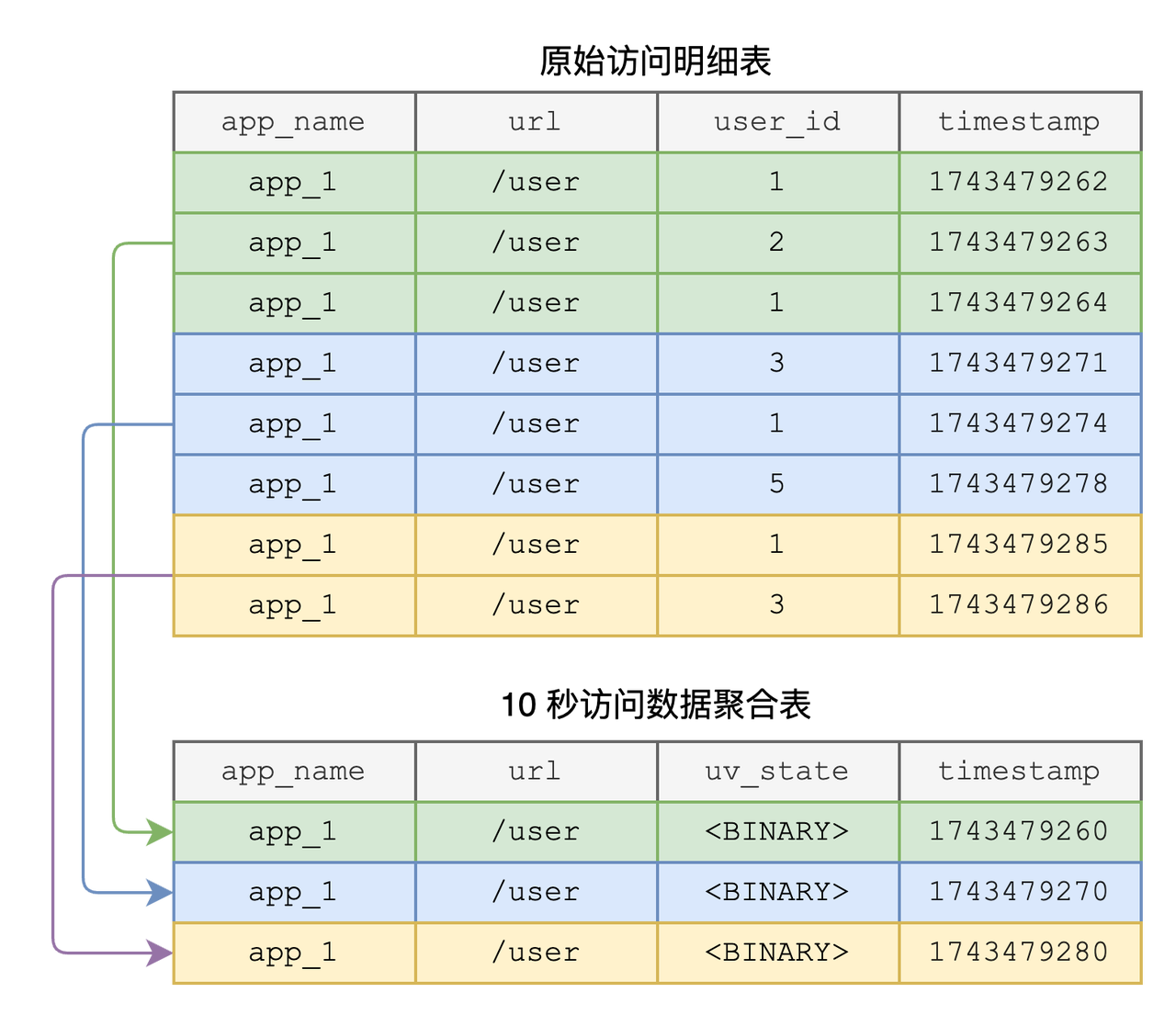
10s UV 状态
sql
CREATE FLOW uv_hll_10s
SINK TO uv_state_10s
EXPIRE AFTER '12hours'::INTERVAL
AS SELECT
app_name,
url,
date_bin('10s'::INTERVAL, ts) AS time_window,
hll(user_id) AS uv_state
FROM access_log
GROUP BY app_name, url, date_bin('10s'::INTERVAL, ts);hll函数: Flow 任务中我们通过hll函数将同一时间窗口内的 user_id 进行散列并写入到uv_state_10s的uv_state字段中;uv_state BINARY类型: 是一个二进制字段(BINARY 类型),无法直接进行查询。如果要查询某个10 秒的时间窗口内的独立访问用户量,需要通过hll_count函数来进行查询。
sql
SELECT
`app_name`,
`url`,
hll_count(`uv_state`) as uv_count
FROM uv_state_10s
WHERE time_window = 1743479260;1m UV 聚合
如果用户需要进一步将 10 秒的访问数据聚合到 1 分钟或者直接需要查询特定时间段内的用户访问数量,则可以通过 hll_merge 函数来对二进制的 HyperLogLog 状态进行合并:
sql
CREATE FLOW uv_hll_1m
SINK TO uv_state_1m
EXPIRE AFTER '180days'::INTERVAL
AS SELECT
app_name,
url,
date_bin('1m'::INTERVAL, time_window) AS time_window_1m,
hll_merge(uv_state) AS uv_state
FROM uv_state_10s
GROUP BY app_name, url, date_bin('1m'::INTERVAL, time_window);查询示例:
sql
SELECT
app_name,
url,
hll_count(uv_state) AS uv_count
FROM uv_state_1m
WHERE time_window_1m = '2025-04-20T15:23:00Z';
GROUP BY app_name, url;效果与收益
- 查询性能显著提升
预聚合 + 多级 Roll‑up,避免全量扫描,P99 查询延迟从秒级降至毫秒级。
- 存储与成本可控
不同粒度数据设置差异化 TTL:10s 热表保留 1 天,1m 中表保留 7 天,10m 冷表保留 180 天,冷热分离降低存储成本
- 资源解偶 & 弹性扩缩容
Frontend、Flownode、Datanode 独立伸缩,流计算、存储、查询三者互不干扰
- 开发效率提升
Flow 编写使用标准 SQL,上手难度低,Roll‑up、HyperLogLog、UDDsketch 等内置函数无需额外学习曲线
最佳实践与落地建议
- 合理划分数据分层:根据监控场景与 SLA 要求确定不同粒度保留策略。
- 调整 sketch 精度:UDDsketch 支持自定义误差范围(α、β 参数),可根据业务侧对 P50/P99 精度要求调优。
- 监控与告警:为各级聚合任务配置失败重试与告警机制,确保持续计算的稳定性。
- 资源规划:根据写入 QPS 与聚合复杂度合理预估 Flownode 与 Datanode 数量,结合对象存储带宽设计分区策略。
关于 Greptime
Greptime 格睿科技专注于打造新一代可观测性数据库,服务开发者与企业用户,覆盖从从边缘设备到云端企业级部署的多样化需求。
- GreptimeDB 开源版:开源、云原生,统一处理指标、日志和追踪数据,适合中小规模 IoT,个人项目与可观测性场景;
- GreptimeDB 企业版:面向关键业务,提供更高性能、高安全性、高可用性和智能化运维服务;
- GreptimeCloud 云服务:全托管云服务,零运维体验“企业级”可观测性数据库,弹性扩展,按需付费。
欢迎加入开源社区参与贡献与交流!推荐从带有 good first issue 标签的任务入手,一起共建可观测未来。
⭐ Star us on GitHub | 📚 官网 | 📖 文档

