本页内容
在可观测性数据库领域,存储架构设计直接影响着系统的性能表现、运营成本和数据可靠性。近期,GreptimeDB 在 ClickHouse 官方评测 JSONBench 里收获卓越表现:Cold Run 第一,Hot Run 第四!
本文将深度解析 GreptimeDB 如何通过突破性的存储架构设计实现读写性能的极致优化,并揭示其在存储效率、查询速度与资源消耗等多维度性能指标间取得的精妙平衡,最终为可观测性数据管理提供高效的解决方案。
存储经济学视角:为何选择对象存储
可观测领域的数据规模极为庞大,笔者与众多国内外的公司交流发现:具备数字化业务集群的中大型企业或物联网终端设备厂商,其单日产生的指标、日志及链路数据已普遍达到 TB-PB 量级,成为业务运营的新常态。
可观测性数据库面临的一项核心挑战是如何经济高效地存储海量数据,GreptimeDB 在设计伊始便充分考量了存储成本这一关键要素。
对象存储 vs. 块存储
对象存储系统(如 Amazon S3、Google Cloud Storage)在设计上主要优化吞吐量而非延迟,但它们提供了显著的成本优势:
- 相比块存储解决方案(如 Amazon EBS),对象存储通常便宜 3-5 倍;
- 对象存储提供几乎无限的扩展能力,非常契合监控和 IoT 数据持续增长的特性;
- 运维成本低,无需考虑复杂的容量规划。
然而,对象存储固有的高延迟特性与实时查询的毫秒级响应诉求形成了“天然屏障”。
GreptimeDB 没有在这两种存储方式之间做非此即彼的选择,而是通过巧妙的架构设计同时保留两者的优势。关于对象存储的性能特征评估,参见同事这篇精彩的论文解读:《论文分享:利用对象存储进行高性能数据分析》。
我们不考虑吞吐量、IOPS 和 API 调用次数等,仅查看存储成本:
- Amazon S3 标准存储(适合热数据):$0.023/GB/月
- Amazon S3 Glacier(针对冷数据):最低为 $0.004/GB/月
- EBS 普通 SSD(gp3):$0.08/GB/月
- EBS 吞吐优化 HDD(st1):$0.045/GB/月
价格倍数对比
- 热存储场景:即使与 EBS 的最便宜方案(吞吐优化型 HDD)相比,对象存储(S3 标准)的价格差异约为 2 倍 ($0.045 / $0.023);
- 对于高性能块存储(如通用型 SSD gp3),S3 标准存储便宜约 3-4 倍;
- 在冷存储场景中(如 S3 Glacier),价格差异更大,可达到 10 倍甚至更多。
多层次缓存架构:化解延迟挑战
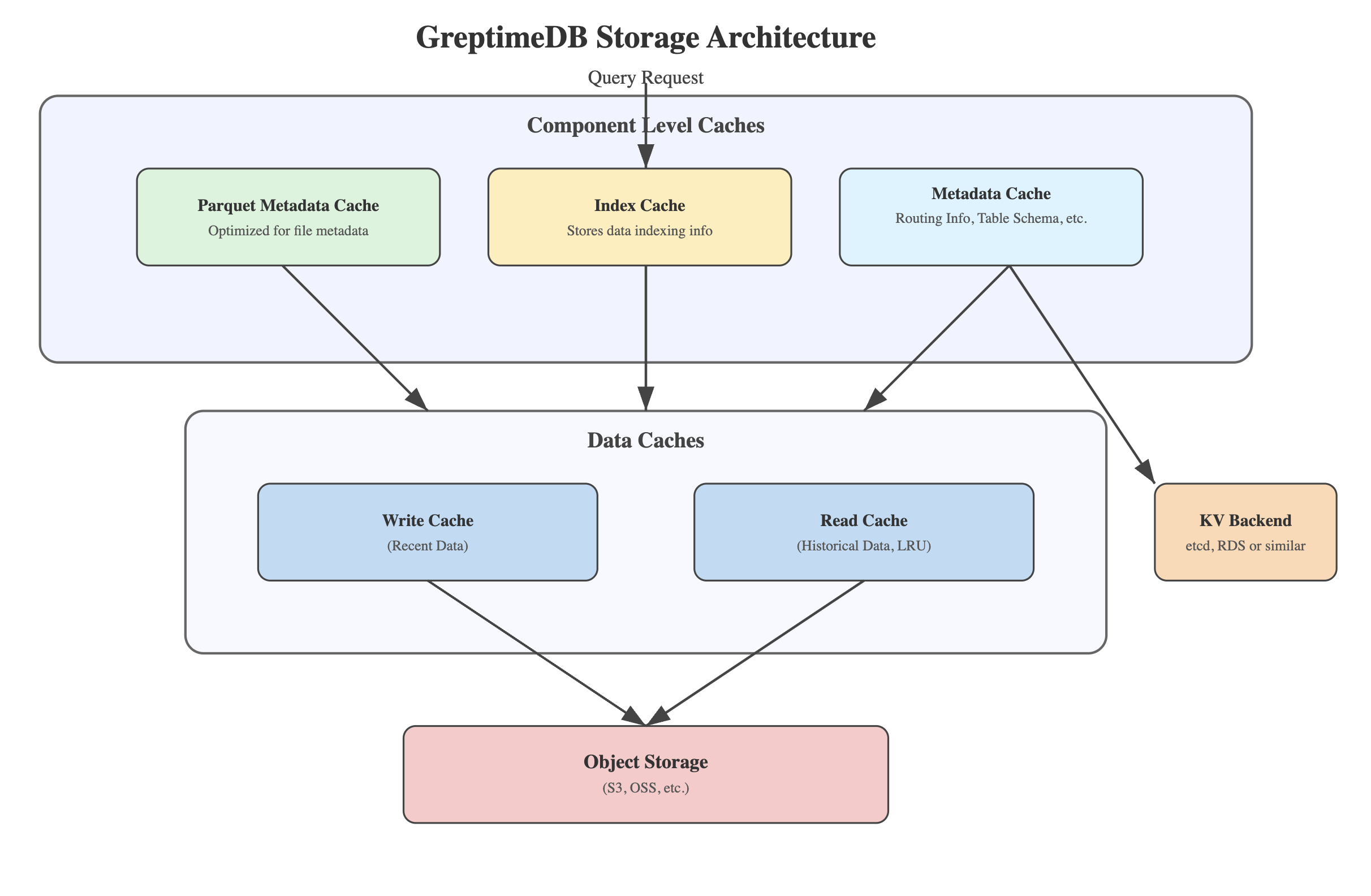
受到操作系统 Page Cache 的启发,GreptimeDB 实现了一个多层次缓存系统。这种架构使系统不仅能够利用对象存储的成本优势,还能克服其固有的延迟问题。
写入缓冲区(Write Cache)设计
写入缓冲区(Write Cache)是这一架构的关键组成部分,本质上是一个 write-through cache:
- 新近写入的数据首先进入本地磁盘支持的写缓冲区,我们称之为 Write Cache;
- 数据在写缓冲区中按时间组织,便于最近数据的快速查询;
- 写缓冲区大小可配置,通常足以容纳最近几小时或几天的数据。
这种设计确保了最常查询的最新数据能以低延迟的方式访问,无需依赖对象存储。
历史数据读取缓存(Read Cache)
针对查询较早历史数据的场景,GreptimeDB 设计了专门的读取缓存:
- 采用 LRU(最近/最少使用)算法管理缓存内容;
- 由本地磁盘支持,提供比对象存储快得多的访问速度;
- 缓存单元以 Parquet 的 page 为粒度,针对时序数据查询模式优化。
元数据与索引缓存
除了数据本身,系统还为关键元数据实现了专门的内存或者本地磁盘缓存:
- 表结构、分布式路由等元数据缓存;
- Parquet 文件元数据缓存;
- 索引数据缓存,索引数据通常较小,我们希望能将它们全量缓存来加速查询,内存结合磁盘缓存。
文件的元信息也同样是从对象存储获取,类似表的 schema、分片路由等信息都存储在 KV Backend 里,它是一层元信息存储的 KV 抽象,背后可以是 etcd 或者云数据库 RDS 等。这些缓存显著减少了查询执行过程中的元数据访问延迟,提升了整体查询性能。
LSM Tree 架构:为可观测性数据优化
在核心存储引擎设计上,GreptimeDB 采用了经过专门优化的 LSM(日志结构合并树)架构,这种架构适应了可观测性数据写入密集型的特性。
数据写入流程
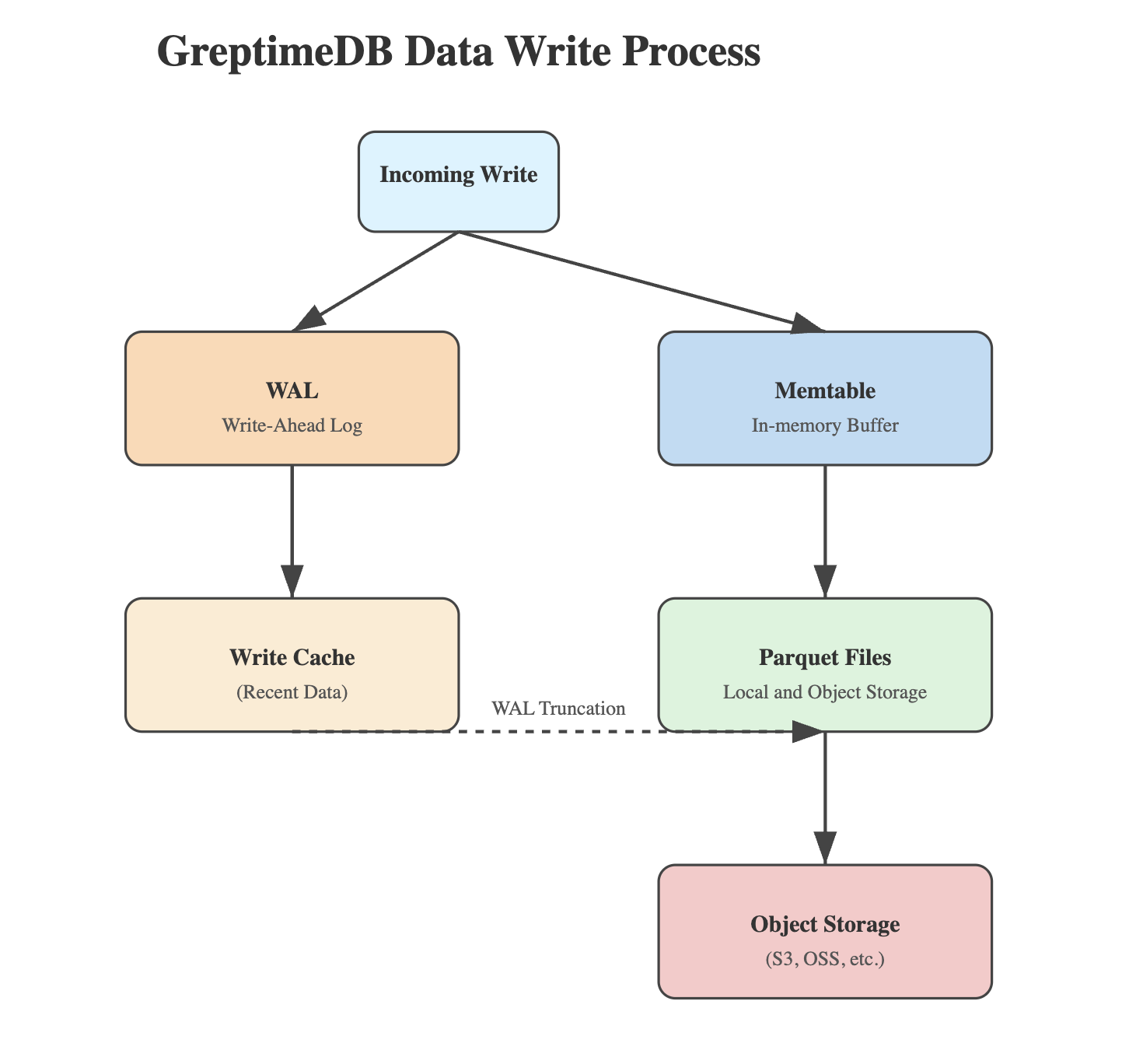
1. WAL 日志写入
- 所有写入首先记录到 WAL(Write-Ahead Logging,预写日志);
- 在分布式部署中,WAL 通过消息队列(如 Kafka)实现或者挂载 PVC(Persistent Volume Claim)的方式确保可靠性;
- 这种设计保证了数据持久性,即使在节点故障情况下也可适用;
- WAL 在特定情况下允许关闭(表级别),比如从 Kafka 等消息队列消费并处理数据,然后写入到 GreptimeDB时,随时可以通过重新消费消息队里的消息来恢复数据。
2. Memtable 处理
- 数据从 WAL 流入内存中的 Memtable 时,将按照时间来组织和管理(Memtable 的设计本身都非常值得解读,敬请期待后续文章);
- Memtable 提供内存级别的快速查询能力。
3. 数据持久化
- 当 Memtable 达到配置的大小阈值或时间限制时触发刷新;
- 数据被压缩并转换为列式存储格式(Parquet);
- Parquet 文件同步写入本地写缓冲区(Write Cache);
- 同时上传到对象存储(如 S3)。
4. WAL 管理
- 只有在确认数据成功上传到对象存储后,相应的 WAL 才会被截断;
- 确保了数据在任何故障情况下都不会丢失。
尽管像 VictoriaMetrics 这样的系统宣称在监控这个场景时 WAL 并非必需,但我们仍然觉得应当将这个选择的权利交给用户去决定,而非代替用户做出决策,承担丢失数据的风险。
压缩与合并策略
GreptimeDB 实现了针对时序数据特性的压缩与合并策略:
1. 时间分区
- 数据按时间窗口组织,便于高效查询特定时间范围的数据;
- 分区策略可根据数据模式和查询模式进行调整。
2. 分层压缩
- 采用分层压缩策略,较新的数据层保持较小的文件数;
- 较旧的数据经过多次压缩合并,减少文件碎片。
3. 列式存储优化
- 利用 Parquet 格式的列式存储特性,实现高效的数据压缩;
- 支持列裁剪和谓词下推,减少查询时的数据扫描量。
关于 GreptimeDB 的压缩策略,有兴趣可以阅读我们的文档获得进一步信息。
查询性能优化
GreptimeDB 的查询引擎充分利用了多层缓存架构,为不同时间范围的查询提供最优性能。
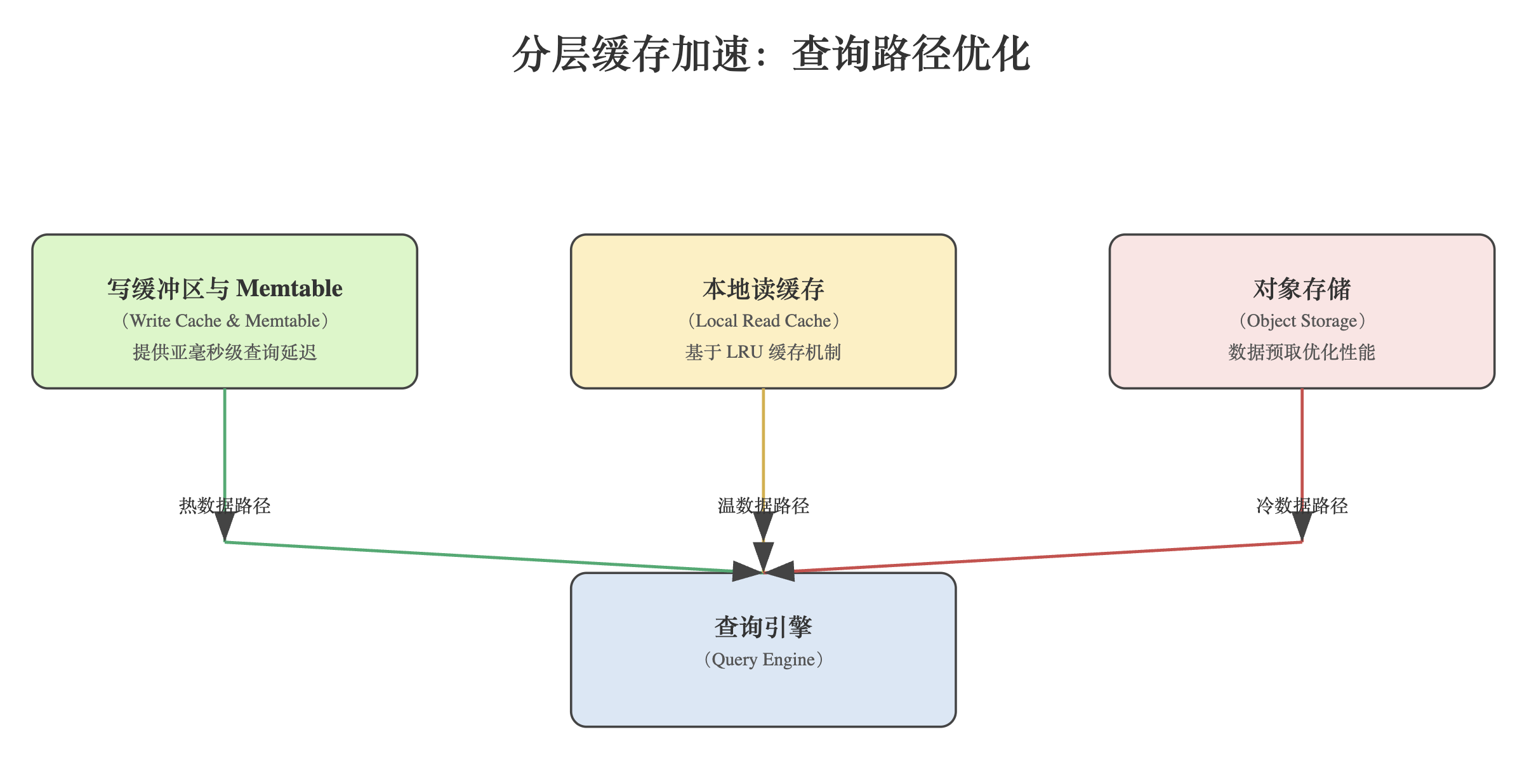
查询路径优化
1. 热数据查询
- 最近数据的查询直接从写缓冲区(Write cache)和 Memtable 中获取结果;
- 这种路径避开了对象存储,提供亚毫秒级的查询延迟。
2. 温数据查询
- 相对较近的历史数据从本地读缓存获取;
- LRU (Least Recently Used)机制确保频繁访问的数据保留在缓存中。
3. 冷数据查询
- 远期历史数据可能需要从对象存储读取;
- 系统会主动预取相关数据并填充读缓存,为后续查询优化性能。
向量化执行与并行处理
为进一步提升查询性能,GreptimeDB 基于 Rust 和 Apache DataFusion 和 Apache Arrow 实现了:
- 向量化查询执行,充分利用现代 CPU 的 SIMD 指令;
- 多核并行处理能力,自动拆分复杂查询为并行任务。
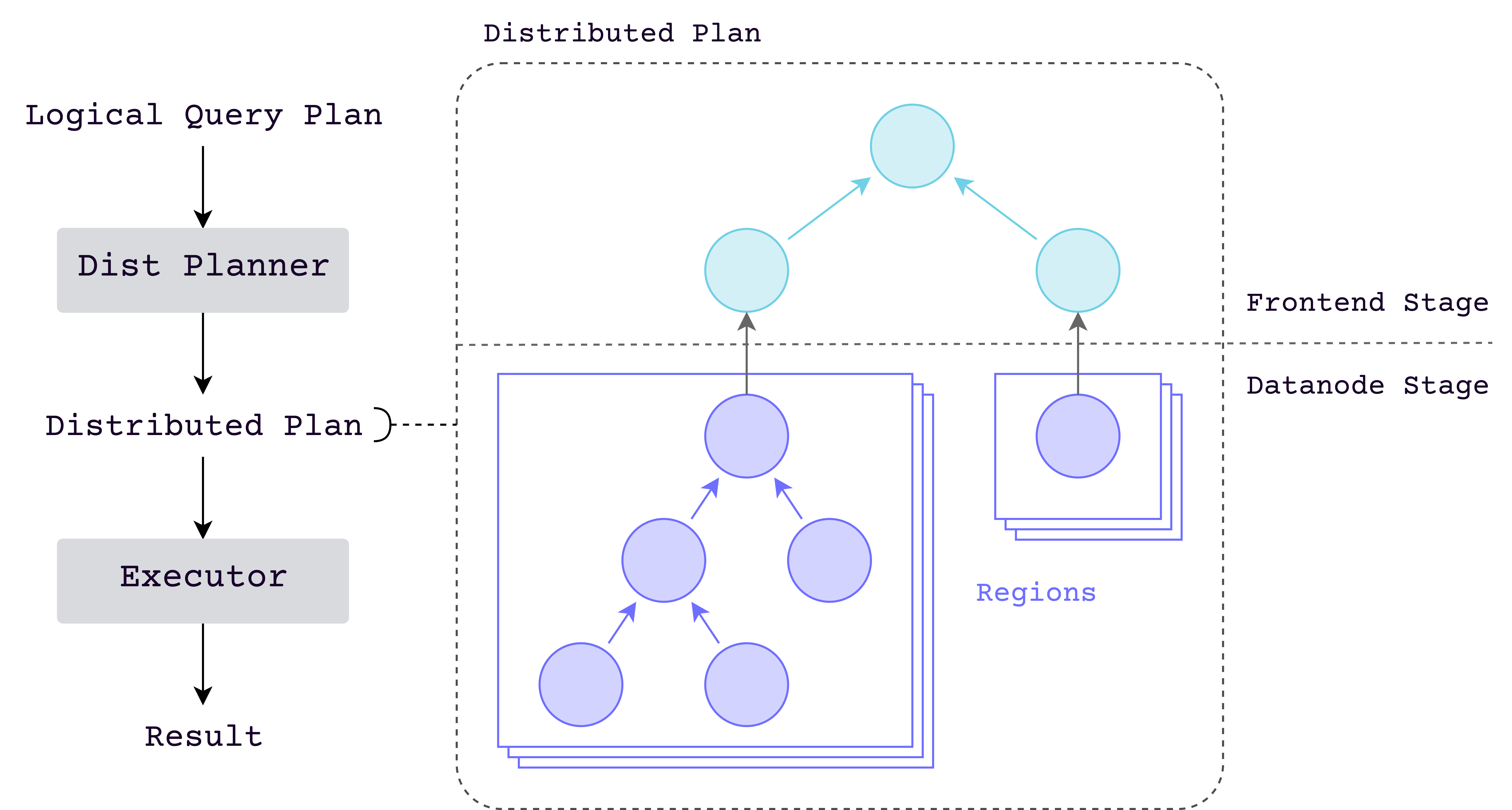
分布式查询引擎将查询拆分为子查询,每个子查询负责查询表数据的一个部分,然后将所有结果合并为最终结果。
未来我们将继续改进查询优化器,支持更智能的查询规划,根据数据分布和可用资源选择最优执行计划。
可靠性与灾备考量
除了性能和成本优化,GreptimeDB 的存储架构还特别注重数据可靠性:
1. 多副本策略
- 对象存储本身提供高可靠性(如 S3 的 99.999999999% 的持久性);
- 关键的元数据和索引信息通过分布式一致性协议或者云数据库如 RDS 在多节点间复制。
2. 故障恢复
- 节点故障后,可基于 WAL 和对象存储中的数据快速恢复;
- 支持跨区域复制,提供灾备能力。
3. 数据完整性验证
- 对写入对象存储的数据进行校验和验证;
- 定期后台验证数据完整性,主动发现并修复潜在问题。
架构的平衡艺术
GreptimeDB 的存储架构展示了在可观测数据管理中平衡多种需求的精妙设计:
- ✅ 成本效益:利用对象存储的经济性,显著降低存储成本;
- ✅ 查询性能:通过多层缓存架构克服对象存储的延迟问题;
- ✅ 写入性能:LSM 树设计提供高吞吐量写入能力;
- ✅ 数据可靠性:WAL 和多重验证机制确保数据安全;
- ✅ 扩展性:基于对象存储的设计提供几乎无限的容量扩展。
对于企业级可观测性数据的管理,这种平衡多种需求的架构设计提供了一个既经济高效又性能卓越的解决方案。
随着物联网、5G 和边缘计算的发展,可观测数据(如指标、日志和链路)的数据量将持续爆发增长,GreptimeDB 的创新架构将在未来数据管理领域发挥越来越重要的作用。
通过这种创新的多层架构设计,GreptimeDB 成功地将对象存储的经济性与块存储的性能优势相结合,为时序数据库带来了新的可能性。无论是成本敏感的企业应用,还是对性能有极高要求的实时监控系统,都能从这种架构中获益。
关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack

