
本页内容
日志(Log)在监控运维和数据分析的场景中发挥着关键作用。在线系统的问题诊断、用户的行为分析、广告的点击统计和边缘 IoT 设备的监控等都高度依赖日志数据,日志通常包括服务器日志、应用程序日志和安全记录等。然而,日志的数据量相对庞大,一个中大型客户每天的日志规模可达 TB 至 PB 级别。如何高效、实时地处理日志,已成为 IT 系统中一个亟需解决的问题。
ClickHouse 是国内外企业日志系统存储的主要选择之一,同时涵盖 Traces(即链路数据)这样“特殊”的日志。在海量日志场景中,其压缩率与高性能均可较好地取代 ELK(Elasticsearch)生态。GreptimeDB 自 2024 年起着手日志处理引擎的研发,近期于 ClickHouse 官方评测 JSONBench 中获得 Cold Run 第一、Hot Run 第四的卓越成绩。本文将对两个系统在日志场景下的功能/性能差异进行剖析,为用户的日志系统选型提供参考。
核心差异:通用 OLAP 和专为可观测设计
ClickHouse 是一款通用的 OLAP 数据库,能够高效地处理多种分析查询。在日志分析、金融处理以及物联网场景中,它凭借灵活的设计和成熟的 SQL 生态系统表现亮眼。
另一方面,GreptimeDB 是一款针对可观测性数据设计的云原生数据库,非常适用于可观测性数据、指标记录和实时监控工作负载,其架构针对高频率、时间戳数据(例如指标和事件)的摄入和查询进行了优化。
核心特性对比
| 产品 | ClickHouse | GreptimeDB |
|---|---|---|
| 数据模型 | 列存,表模型,通用 OLAP | 列存,表模型,统一 Metrics, Logs 和 Traces 模型 |
| 性能 | OLAP 性能优异,时间序列场景均衡 | 专为可观测场景优化,读写和压缩率优秀 |
| 可扩展性 | 水平扩展,需手动配置 | 云原生,通过 Kubernetes 实现自动弹性扩展 |
| 功能 | SQL | SQL,原生支持 PromQL |
| 成本效率 | 高效,依赖硬件资源 | 存算分离,基于对象存储提效 |
| 生态兼容 | 具备丰富的插件体系;成熟的 SQL 生态 | 支持众多写入协议;通过 MySQL/ PostgreSQL 协议接入成熟的 SQL 生态;存储格式为 Parquet,可直接接入大数据生态 |
| 社区支持 | 社区规模大,成熟稳定 | 社区逐渐壮大,专注可观测性场景 |

日志系统特性对比
以上是核心的特性对比,日志场景下我们还关注以下维度的对比:
| 产品 | ClickHouse | GreptimeDB |
|---|---|---|
| 可视化 | 可集成 Grafana、Kibana 等 | 内置日志视图,可集成 Grafana、Kibana 等 |
| Elasticsearch API 兼容性 | 不直接支持,可通过第三方实现 | 企业版直接支持 Elasticsearch 的读写 REST API |
| 日志 ETL | 无内置 ETL | 内置 Pipeline,将非结构化日志转化为结构化日志 |
| 日志转指标 | 物化视图;预聚合表 | Flow 流计算 |
| 结构化与非结构化日志 | 两者都支持,支持全文索引(实验功能); 开启后写入性能影响较大,存储空间占用较大 | 两者都支持,支持全文索引 |
| Traces 写入和查询 | 支持,需自行建模; SQL 查询 | 内置 Otel Traces 建模;支持 SQL 查询和 Jaeger 查询协议 |
性能分析
两者之间的性能差异可以参见下图,更详细的数据请参考:《写入性能跃升 67.5%,存储成本锐减 50%|GreptimeDB v0.12 日志场景性能测试发布》。
| 产品 | GreptimeDB | ClickHouse |
|---|---|---|
| 版本 | v0.12 | 24.9.1.219 |
| 数据模型 | 支持结构化和非结构化(启用全文索引) | 支持结构化和非结构化(实验性全文索引) |
| 写入性能(TPS) | 185,535(结构化);159,502(非结构化) | 166,667 (结构化);136,612 (非结构化) |
| 写入吞吐比例(HTTP 协议) | Elasticsearch 的 470% 范围 | 优于 Elasticsearch,略低于 GreptimeDB |
| 查询性能(结构化数据) | COUNT 查询时间:6ms;关键词匹配:22.8ms | COUNT 查询时间:46ms;关键词匹配:52ms |
| 查询性能(非结构化数据) | COUNT 查询时间:6ms;关键词匹配:~2547ms | COUNT 查询时间:8ms;关键词匹配:~2080ms |
| 存储压缩率 | 13%-33%(压缩比最优) | 26%-51% |
| 资源占用(CPU %) | 结构化: 13.2%;非结构化: 10.29% | 结构化: 9.56%;非结构化: 26.77% |
| 资源占用(内存 MB) | 结构化: 408MB;非结构化: 624MB | 结构化: 611MB;非结构化: 732MB |
| 对象存储支持(S3) | 性能损失仅 1%-2% | 默认支持 |
简而言之,GreptimeDB 的读写性能与 ClickHouse 表现相当,在压缩率和资源占用上略有优势。尤其值得强调的是在使用对象存储下,性能几乎不下降。
与其同时,GreptimeDB 在 ClickHouse 官方推出的 JSONBench 中的表现验证了其处理海量数据集的竞争力,性能与 ClickHouse 和 VictoriaLogs 处于同一梯队。10 亿级别的 Cold Run 斩获第一,Hot Run 前四:
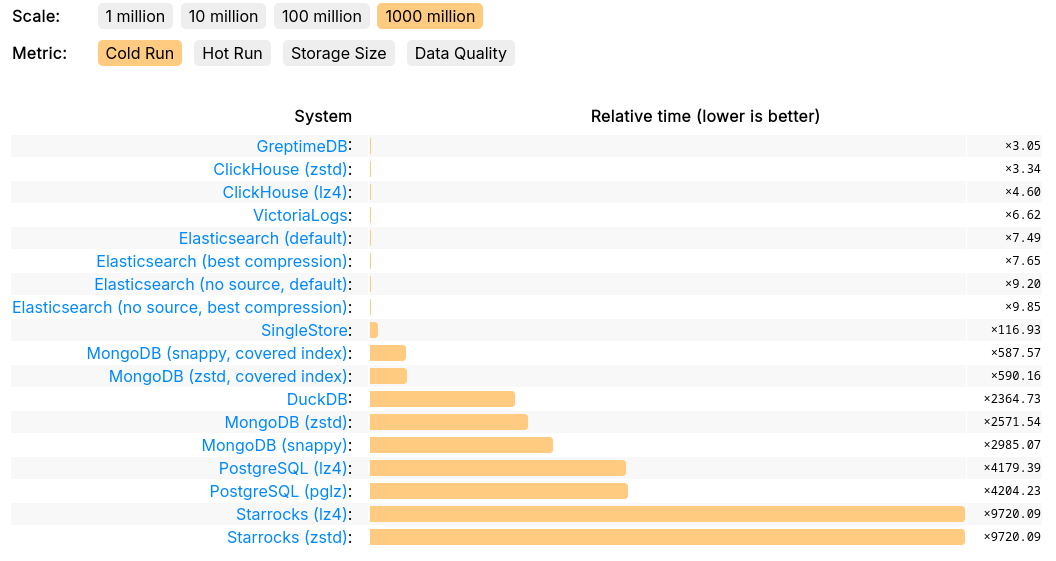
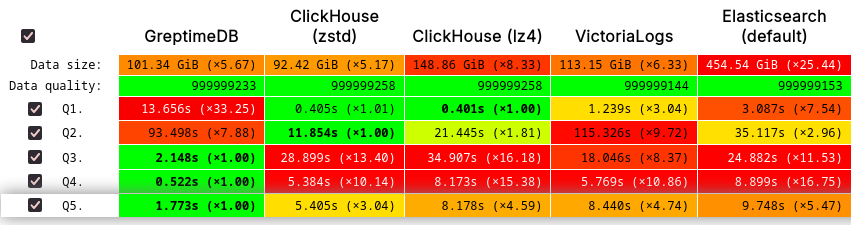
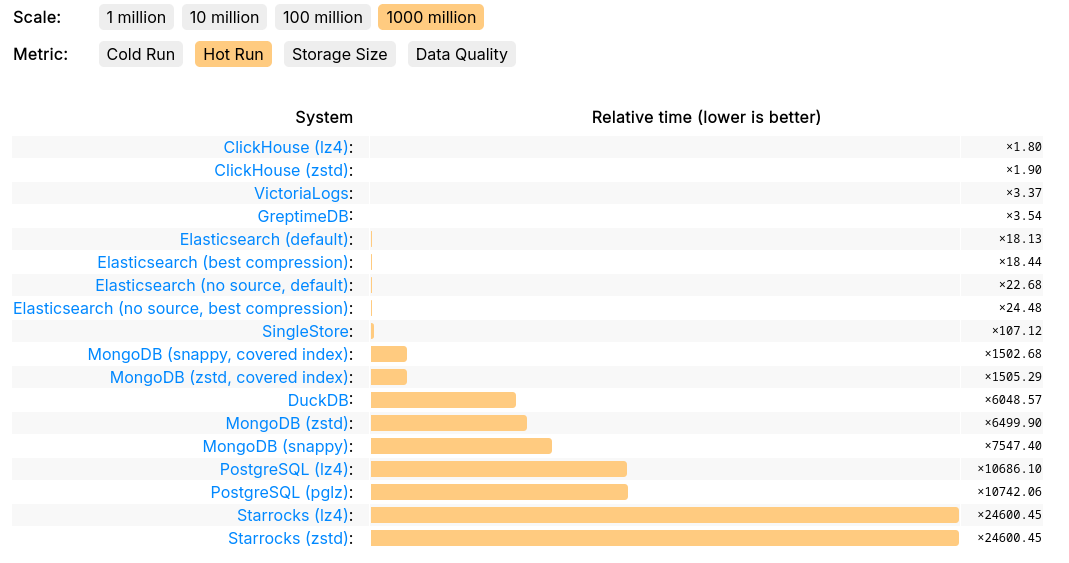
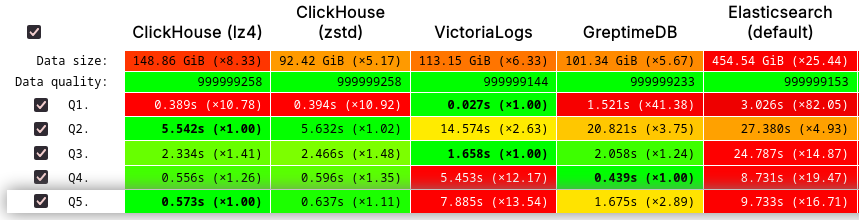
可扩展性对比
可扩展性往往是用户决定数据库选择的关键因素,而 ClickHouse 与 GreptimeDB 在这方面的处理方法大不相同。
配置复杂的扩展能力:ClickHouse
ClickHouse 支持通过分片和复制进行水平扩展,也支持垂直扩展。然而,水平扩展的实现需要手动配置,包括添加节点和重新平衡数据,这在集群规模扩大时可能变得复杂。尽管 ClickHouse Cloud 的自动扩展选项在一定程度上减少了维护成本,但与 GreptimeDB 已开源的弹性扩展相比仍显局限。
无缝弹性扩展:GreptimeDB
**作为云原生数据库,GreptimeDB 采用了计算与存储分离的架构。**它基于 Kubernetes 进行部署,可实现无缝的弹性扩展,非常适合云环境。资源独立扩展支持更高的成本效率和灵活性,确保高需求场景下性能稳定;无需手动干预的设计是 GreptimeDB 在观测性和物联网特定场景中的显著优势。
存算分离架构
针对存算分离架构,我们再做一些额外讨论(更多 GreptimeDB 存算分离相关,请阅读这篇文章:《GreptimeDB 存储架构深度剖析:JSONBench 榜单第一背后的秘密》)。
ClickHouse 尽管也可以将数据放在 S3 这样的对象存储上,但是这套架构存在一些问题:
首先,扩容仍然需要复制(数据既然已经放在 S3 上,复制完全是多此一举的行为)导致扩容较为繁琐和困难,也造成了存储资源浪费。尽管有 Zero-copy replication,但是当前仍然存在较多 Bug,不推荐使用。事实上 ClickHouse 官方推荐的是不开源的 SharedMergeTree。
其次,ClickHouse 仅仅是将数据放在了对象存储上,文件目录、表结构等元信息还是基于本地存储和 Zookeeper 做复制,这就导致元信息在对象存储和本地存储之间难以保持同步的问题,也存在较多的 Bug 和元信息存储的扩展性问题。相反, GreptimeDB 仅将表的元信息存储在 Metasrv,而数据文件的元信息则放在了对象存储上。
| 产品 | ClickHouse | GreptimeDB |
|---|---|---|
| 扩展方式 | 支持水平和垂直扩展,但水平扩展需手动配置(添加节点、数据重新平衡),规模扩大时较复杂 | 基于云原生架构,支持计算与存储分离,无缝实现弹性扩展,适合云环境 |
| 云端支持 | ClickHouse Cloud 提供自动扩展选项,但与开源 GreptimeDB 的弹性扩展相比仍有局限 | Kubernetes 部署,资源独立扩展,成本效率和灵活性高,性能稳定,无需手动干预 |
| 存算分离架构 | 数据可存储在 S3 等对象存储上,但扩容仍需复制,过程复杂且浪费存储资源。Zero-Copy复制依然存在较多问题和 Bug | 数据和元信息分离存储,元信息存储在 Metasrv,数据元信息存储在对象存储,架构设计更轻量且高可扩展性 |
| 元信息管理 | 文件目录和表结构元信息仍基于本地存储和 Zookeeper 复制,同步一致性差,扩展性问题较多 | 元信息集中在 Metasrv,对象存储中管理数据文件元数据,更具一致性和扩展性 |
| 适用场景 | 更广泛的 OLAP 查询分析,但受限于扩展性和云原生环境适配 | 可观测性和物联网场景中表现出色,适合高扩展性和弹性要求高的应用场景 |
决策指导
选择 ClickHouse 或 GreptimeDB 主要取决于具体的工作负载需求:
适合选择 ClickHouse 的场景
- 多领域的广泛分析查询;
- 需要成熟的社区支持和丰富文档;
- 通用 OLAP 工作负载与监控数据分析结合的场景。
适合选择 GreptimeDB 的场景
- 高频率、带时间戳的数据(例如指标、日志等可观测性数据);
- 云原生架构中需要弹性扩展及成本优先的场景;
- 工作负载需要 PromQL 集成及与 Prometheus 等监控工具配合使用。
选型结论
ClickHouse 是一款强大的通用 OLAP 数据库,具备多功能性、出色的性能以及庞大的社区生态。与此同时,GreptimeDB 在可观测性场景中更具优势,能够提供高效的数据存储、优化的摄取速度以及特别针对监控和 IoT 工作负载的可扩展解决方案。两者均为开源解决方案,为用户提供灵活性,但数据库选型需根据数据特性、扩展需求和预算约束来决定。
关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb 官网:https://greptime.cn/ 文档:https://docs.greptime.cn/ Twitter: https://twitter.com/Greptime Slack: https://greptime.com/slack LinkedIn: https://www.linkedin.com/company/greptime/
关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack

