
本页内容

时序数据库是为时序数据而设计的领域数据库,具有高效的并发写入、数据压缩和查询性能。随着物联网设备的普及,大量的时序数据被产生和收集,欢迎阅读时序数据库是什么了解更多。时序数据库在优化方面是针对时序场景特点权衡来的,比如写入多,更新和删除少,数据按照时间顺序写入等等。
理想情况下,我们认为数据都是实时顺序写入的,可是在真实的世界中,往往要复杂很多,并不能完全保证数据是顺序写入的,数据往往会因为传感器故障、网络延迟等原因出现乱序,给时序数据库带来一些挑战,比如:
数据插入与更新:乱序数据会导致数据插入与更新操作变得复杂,影响写入性能。
数据压缩:乱序数据可能影响数据压缩算法的效果,增加存储空间的需求。
查询性能:乱序数据可能导致查询性能下降,增加计算资源的消耗。
为了更好地说明,这里先解释一下什么是乱序数据。时序场景中,通常有数据生成端和接收端,数据从生成端到达接收端会有一定延迟,如果说接收的数据序列和生成的数据序列一致,则是顺序接收,若存在先生成的数据后接收,一般就认为出现了乱序数据,具体如下图:
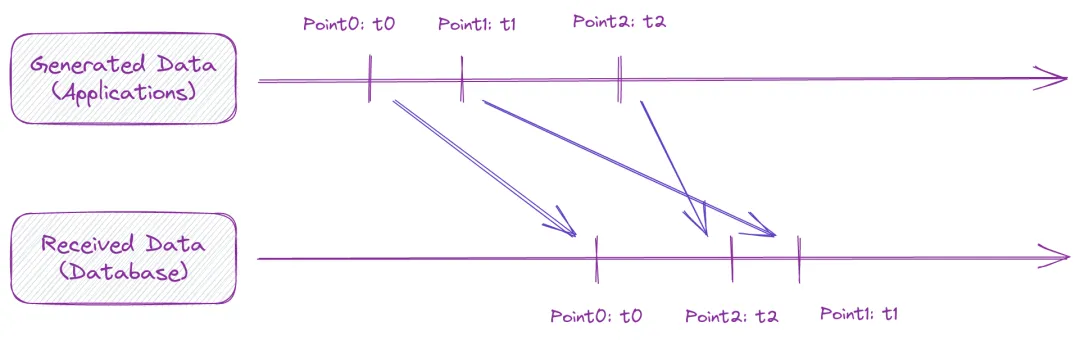
上图中 Point1 就是一个乱序数据。
很多的时序数据库在存储模型上会采用 LSMT(log-structured merge-tree),这是由 Patrick O'Neil 等人在 1996 年提出在持续不断高并发写入(和删除)的场景下,基于磁盘、满足实时低成本索引的 key-value 数据结构。这种数据结构和时序场景非常符合,持续高并发写入,时间维度有序。GreptimeDB 存储引擎也采用了 LSM Tree,一个简化的结构图如下:
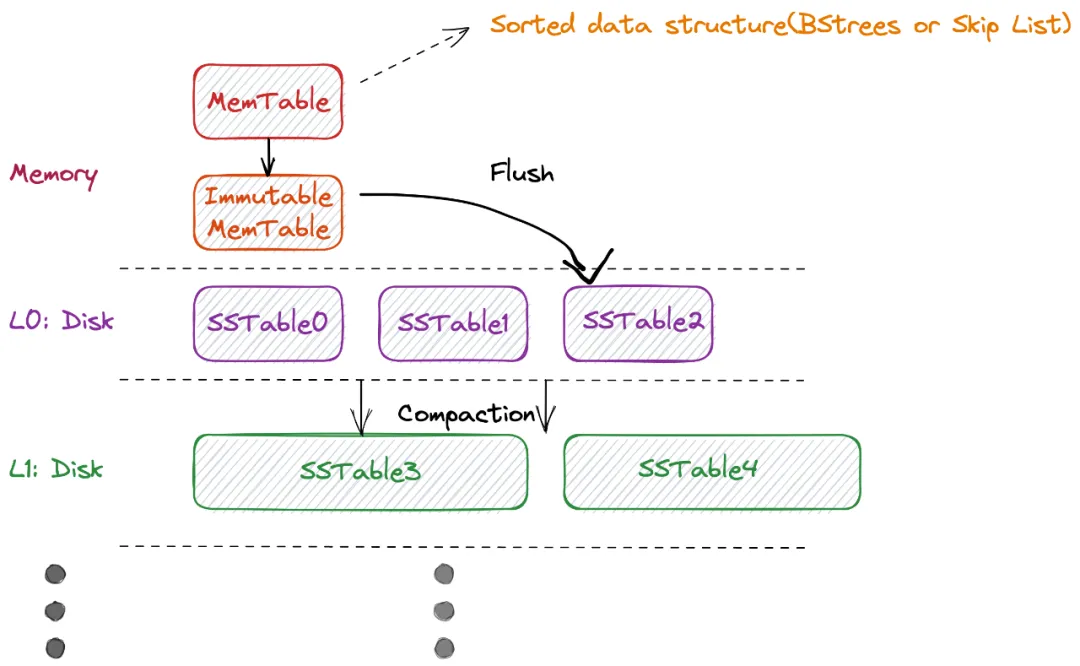
LSM Tree 的主要结构由:
MemTable: 一个有序的内存数据结构,工程上,通常会用 Skip List 实现,也有用 B-Tree 实现
Immutable MemTable: 和 MemTable 是一样的有序的内存数据结构,唯一不同是只读,当 MemTable 达到其大小限制时创建
SSTable(Sorted String Table): 与 Immutable MemTable 类似,只读有序的数据结构,但持久化在了磁盘,主流实现一般是将 Immutable MemTable 直接写入磁盘
为了查询和存储效率,往往还会对 SSTable 做 Compaction,Compaction 操作中通常会将同一层的 SSTable 块再归并,生成新的时间跨度的 SSTable 作为 L+1 层,可能还会做其他的优化,比如降精度以节省空间等。
为了更好地理解,这里我们不做证明的引用两个事实前提:
Skip List 的实现中,插入一条数据的平均时间复杂度是 O(logN);
Skip List 的实现中,查找一条数据的平均时间复杂度是 O(logN);
其中 N 是指一个 Memtable 中可以包含的最大 KV 对。
接下来,我们回到乱序数据的问题,在 LSM Tree 模型下,到底如何处理乱序数据呢?所谓处理乱序数据,最终要的效果是:查询的时候,可以将数据按照时间顺序返回,无论当时接收的时候是否是有序接收。
在理想情况下,假设时序数据都是按时间采集并且有序接收并写入到数据库内,那就不用做任何其他操作,直接写入即可,写入复杂度就是 O(logN),这时候每个 SSTable 都是文件内有序,文件之间也有序,不存在 overlap。
当查询的时候,比如查询某个时间范围内的数据,只需要将和查询时间范围有交集的 SSTable 取出来(可能包含 Immutable MemTable 和 MemTable),在第一个和最后一个 SSTable 文件查询,找到起点和终点,接下来就是将文件的内容串联拼接,时间复杂度可以控制在 O(2*logN + k), k 为常数。
关于如何更快的拷贝数据到内存中并返回了,就不在这里赘述。(当然在这种理想世界里面,完全可以用一个 append-only 的数据结构做到写入 O(1) 的时间复杂度)。
而真实世界是充满不确定性,乱序数据总会存在,从上面的情况就能看出来,SSTable 就无法保障文件间的绝对有序。特别是在 L0 层。那到底会产生什么影响呢?
当我们无法保障 SSTable 之间是有序的,那最糟糕的情况下,查询的时候,需要将所有和查询时间有交集的 SSTable 做多路归并,常规算法(最小堆多路归并)的时间复杂度就在 O(N *logM),其中 N 是 K-V所有待返回的数据点,而 M 是 SSTable 个数。所以相比理想情况下的 O(k *logN) 时间复杂度要高很多。
好在真实世界始终是善良的,并不总是出现最糟糕的情况。那不同情况下的乱序数据,对查询有什么影响呢?
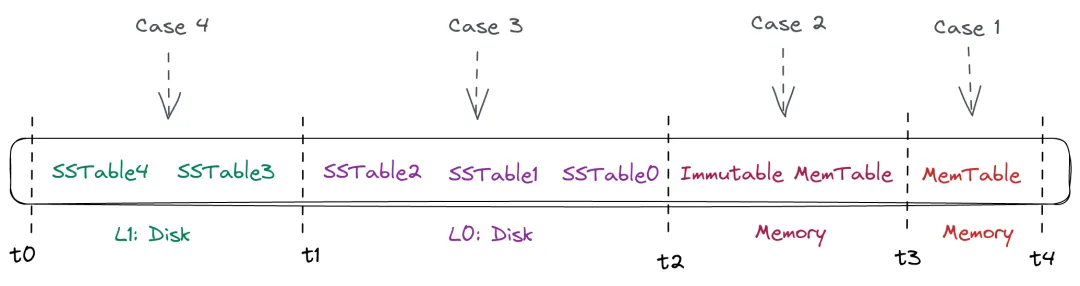
Case 1: 乱序数据的时间戳只在 t3 ~ t4 间,也就是 MemTable 层: 这种情况和理想情况是一样的,因为 MemTable 本身就是有序数据,当有乱序数据进来时,在写入时刻就会进行排序。
Case 2: 乱序数据的时间戳在 t2 ~ t3 间,也就是可能在 Immutable MemTable 层: 这种情况和 Case1 类似,在查询时只需要将 MemTable 和 Immutable MemTable 同时读取,做归并排序即可,都在内存中操作,而且数据块不多,所以影响也不大。
Case 3: 乱序数据的时间戳在 t1 ~ t2 间,这就比较麻烦了,因为涉及到了磁盘上的存储,一方面可能涉及到的要归并的数据文件比较多,另外也有磁盘 I/O 的操作。
Case 4: 乱序数据的时间戳在 t0 ~ t1 间,这种情况和 Case3 类似,但会更麻烦了,相当于在 L1 层 SSTable 也无法保证数据文件间有序,也就是需要处理的归并排序操作增多。
简单来讲,归并操作越多,磁盘操作越多,性能损耗和资源利用代价就越高。而乱序数据的不同情况,主要牵涉到的也是这两个维度。
知道了原因,也就可以做相应的优化,比如最简单是在产品上做设定,只允许短时间内的乱序数据写入,也就是让乱序数据发生在 Case 1 和 Case2 内,之外的数据就丢弃不处理,对于时序场景而言,可能已经可以满足大部分情况了。当然了,在非常严格的场景下,必须得满足到 Case4 层面的乱序数据处理,也可以在细节中优化,比如当新数据到达时,如果与最新数据的时间戳相差较大,可以考虑写入另外一个 MemTable 中,延迟写入到磁盘中,从而降低归并操作的频率,但还是会牺牲查询性能。这就是功能与性能的权衡。
在时序数据库中,也有不使用 LSM Tree 模型的,比如 TimescaleDB 是基于 PostgreSQL 的,在处理乱序数据的时候是利用自己的 hypertable 和 PG 自带的能力,相对会受限较多。GreptimeDB 是基于 LSM Tree 模型的时序数据库,原生就支持乱序数据的写入,同时为了保障用户的场景可以更丰富,我们也在不断优化不同情况下乱序数据的处理方式,会在之后的文章中分享,敬请关注。
关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack

