On this page

Introduction
Region 是 GreptimeDB 集群中数据读写最重要的基本单位,即集群中的分布式读写都是以 Region 为粒度拆分的,所以 Region 是否可用直接关系到整个集群的可用性。Region 分布在 Datanode 上,一旦 Datanode 因为硬件或网络故障导致无法响应请求,Region 也就不可用了。
关于 GreptimeDB 的集群架构,Datanode、Metasrv 和 Frontend 节点的意义,请参考我们的 “Architecture Overview”。
GreptimeDB 在 v0.3.2 版本中推出的集群的 Region Failover 实验功能,就是要解决 Datanode 故障导致 Region 不可用的问题。其核心思想是,令 Metasrv 充当集群的 “大脑”,确定性的设置 Region 在 Datanode 的分布,使整个集群能够在故障发生后恢复可用。
所以,Metasrv 需要解决以下三大问题:
如何检测 Datanode 出现故障;
出现故障后如何重新恢复 Region 在 Datanode 的分布;
以及如何确保 Region 分布的正确性。
下面我们将一一展开介绍。
Heartbeat & FailureDetector
“心跳” 是我们故障检测的起点。集群中每个 Datanode 节点都会与 Metasrv 维持一个 gRPC 双向流来作为心跳连接:
ProtoBuf
service Heartbeat {
rpc Heartbeat(stream HeartbeatRequest) returns (stream HeartbeatResponse) {}
}每隔一定的时间(默认 5 秒),Datanode 会将自己节点上打开的 Region 信息带在心跳请求中上报给 Metasrv。于是 Metasrv 就拥有了集群中所有 Region 在 Datanode 节点的实际分布情况。
对于每一个上报的 Region 信息,Metasrv 会启动一个 FailureDetector,它会每秒检查一次 Region 是否存活,存活的依据则是由 Region 心跳的历史频率计算而来。这里我们使用了应用广泛的 “The φ accrual failure detector” 算法,该算法可以很好地适应心跳的间隔规律。目前在默认配置下,如果 2 个心跳间隔时间之后,FailureDetector 仍然没有收到 Region 心跳,该 Region 就会被判定为不可用,进入 Failover 执行阶段。
Failover
执行 Failover 的关键是要保证执行过程的完整性。
Failover 不能并发执行,因此我们选择在 Metasrv 的 leader 节点上接收心跳和启动 FailureDetector;另外 Failover也不能因为 Metasrv 发生 leader 重选举而停止执行。因此我们使用了 “Procedure” 框架来执行 Region 的 Failover。分布式地执行 Procedure,只需要一个持久化保存和恢复整体状态的地方,我们选择了 etcd。
整个 Region Failover Procedure 执行的状态转换步骤如下:
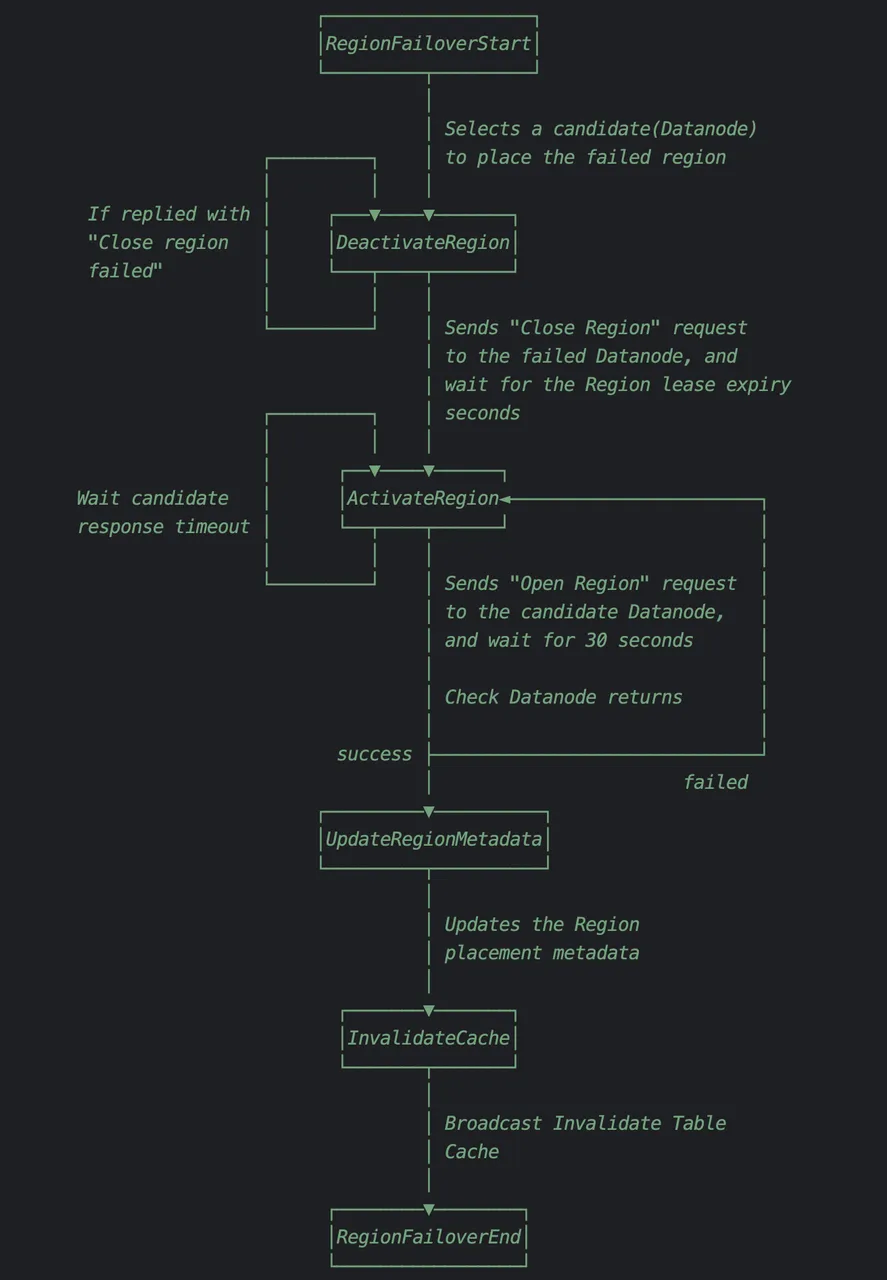
整体思路非常简单:
先将故障 Region 在原来的 Datanode 中关闭;
待 Region Lease 过期后(Region Lease 会在下一部分介绍),在预先选出的健康 Datanode 节点上将 Region 打开;
最后更新 Frontend 节点的 Region 缓存。
这样一个 procedure 完成后,Region 的可用性就恢复了。
Lease
Region 在 Datanode 分布的正确性,核心是确保 Region 至多只能在一个 Datanode 打开。为此我们引入了 Region 的 “租约(Lease)” 概念。每个 Region 都有一个租约,只有在租约时间内,Datanode 才能打开这个 Region。因此,Datanode 对每个Region都有一个 “Liveness Keeper”。在租约时间结束后,Liveness Keeper 会自动关闭过期的 Region。
Region 的续租需要 Metasrv 参与。我们对续租的实现方式是:Datanode 在心跳启动时,记下一个 Instant,作为 “epoch”。每当 Datanode 上报心跳时,会带上一个 duration_since_epoch = Instant::now() - epoch。Metasrv在做续租时,就是简单地将这个 duration_since_epoch 和一个固定的续租时间返回。Datanode 在收到心跳返回时,可简单地将返回值中的 duration_since_epoch 加上之前的 "epoch" 再加上固定的租约时间,即可得到新的 Region Liveness Keeper 的倒计时。
由于 Instant 一定是单调递增的(除非是罕见的硬件 bug),所以这个 duration_since_epoch 也一定是单调递增,倒计时一定不会回退。这样我们可以在一定程度上减少分布式环境中 Datanode 和 Metasrv 之间时钟不一致的影响。
Summary
本文总结了 GreptimeDB 在 v0.3.2 版本中 Region Failover的设计和实现。主要部分包括心跳,FailureDetector,执行 Region Failover 的 procedure 以及 Region Lease。可以看到,维护一个集群的高可用是比较复杂的。在后面的版本中我们还会对 Region 的 Failover 做进一步的优化。
关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack