
本页内容
我们在优化 GreptimeDB v0.7 的写入性能时,通过火焰图发现耗费在解析 Prometheus write request 上的 CPU 时间片占了 12% 左右。相比之下,Go 语言开发的 VictoriaMetrics 耗费在协议解析上的 CPU 仅 5% 左右。这让我们不得不开始考虑优化协议转换层的开销。
为了简化行文,所有的测试代码存放在 GitHub 仓库中:
https://github.com/v0y4g3r/prom-write-request-bench
bash
https://github.com/v0y4g3r/prom-write-request-bench
git clone https://github.com/v0y4g3r/prom-write-request-bench
cd prom-write-request-bench
export PROJECT_ROOT=$(pwd)优化步骤
Step1:复现
首先我们尝试使用一个最小可复现的 benchmark 来确认此问题。
对应分支:
bash
git checkout step1/reproduceRust 相关性能测试代码(benches/prom_decode.rs):
rust
fn bench_decode_prom_request(c: &mut Criterion) {
let mut d = std::path::PathBuf::from(env!("CARGO_MANIFEST_DIR"));
d.push("assets");
d.push("1709380533560664458.data");
let data = Bytes::from(std::fs::read(d).unwrap());
let mut request_pooled = WriteRequest::default();
c.benchmark_group("decode")
.bench_function("write_request", |b| {
b.iter(|| {
let mut request = WriteRequest::default();
let data = data.clone();
request.merge(data).unwrap();
});
});
}运行几次 bench 命令:
bash
cargo bench -- decode/write_request得到基线结果:
text
decode/write_request
time: [7.3174 ms 7.3274 ms 7.3380 ms]
change: [+128.55% +129.11% +129.65%] (p = 0.00 < 0.05)在当前目录下拉取 VictoriaMetrics 代码,构造 Go 性能测试环境:
bash
git clone https://github.com/VictoriaMetrics/VictoriaMetrics
cd VictoriaMetrics
cat <<EOF > ./lib/prompb/prom_decode_bench_test.go
package prompb
import (
"io/ioutil"
"testing"
)
func BenchmarkDecodeWriteRequest(b *testing.B) {
data, _ := ioutil.ReadFile("${PROJECT_ROOT}/assets/1709380533560664458.data")
wr := &WriteRequest{}
for n := 0; n < b.N; n++ {
b.StartTimer()
wr.Reset()
err := wr.UnmarshalProtobuf(data)
if err != nil {
panic("failed to unmarshall")
}
b.StopTimer()
}
}
EOF
go test github.com/VictoriaMetrics/VictoriaMetrics/lib/prompb --bench BenchmarkDecodeWriteRequest🌟 Go 版本中,数据文件路径指向 prom-write-request-bench 代码仓库的 assets 目录下的 1709380533560664458.data 文件。
输出为:
bash
goos: linux
goarch: amd64
pkg: github.com/VictoriaMetrics/VictoriaMetrics/lib/prompb
cpu: AMD Ryzen 7 7735HS with Radeon Graphics
BenchmarkDecodeWriteRequest-16 961 1196101 ns/op
PASS
ok github.com/VictoriaMetrics/VictoriaMetrics/lib/prompb 1.328s可以看到 Rust 解析一个 10000 条时间线的 Prometheus 写入请求耗费了 7.3ms 左右,而 VictoriaMetrics 的 Go 版本只花费了 1.2ms,仅为 Rust 版本的 1/6。
聪明的你可能一下子就看到问题所在了。在 Go 版本中,每次反序列化都是使用的相同的 WriteRequest 结构体,只是在反序列化之前执行 reset 避免数据污染而已,而 Rust 这边每次反序列化都会使用一个新的结构体。
这正是 VictoriaMetrics 为写入性能所做的优化之一。VictoriaMetrics 的写入路径上大量使用对象池化(sync.Pool)技术来降低垃圾回收的压力。假设 Go 版本也像 Rust 一样每次构建一个新的结构体用于反序列化,那么 Go 版本的耗时将会增加到 10ms 左右,比上面测出的 Rust 的结果要差。
那么在 Rust 版本中可以使用类似的池化技术吗?
我们可以做一个简单的实验——pooled_write_request 这个测试的逻辑和 Go 版本的类似:
rust
let mut request_pooled = WriteRequest::default();
c.bench_function("pooled_write_request", |b| {
b.iter(|| {
let data = data.clone();
request_pooled.clear();
request_pooled.merge(data).unwrap();
});
});然后执行:
bash
cargo bench -- decode/pooled_write_request得到结果:
text
decode/pooled_write_request
time: [7.1445 ms 7.1645 ms 7.1883 ms]可以看到性能并没有特别大的提升。那么这是为什么呢?
🌟 当前性能对比回顾
Rust 基线耗时:7.3ms
Go 解析耗时:1.2ms
Rust 当前耗时:7.1ms
Step2:RepeatedField
对应分支:
bash
git checkout step2/repeated_field要想回答上面的问题,还要从 Prometheus 的 WriteRequest 的数据结构说起:
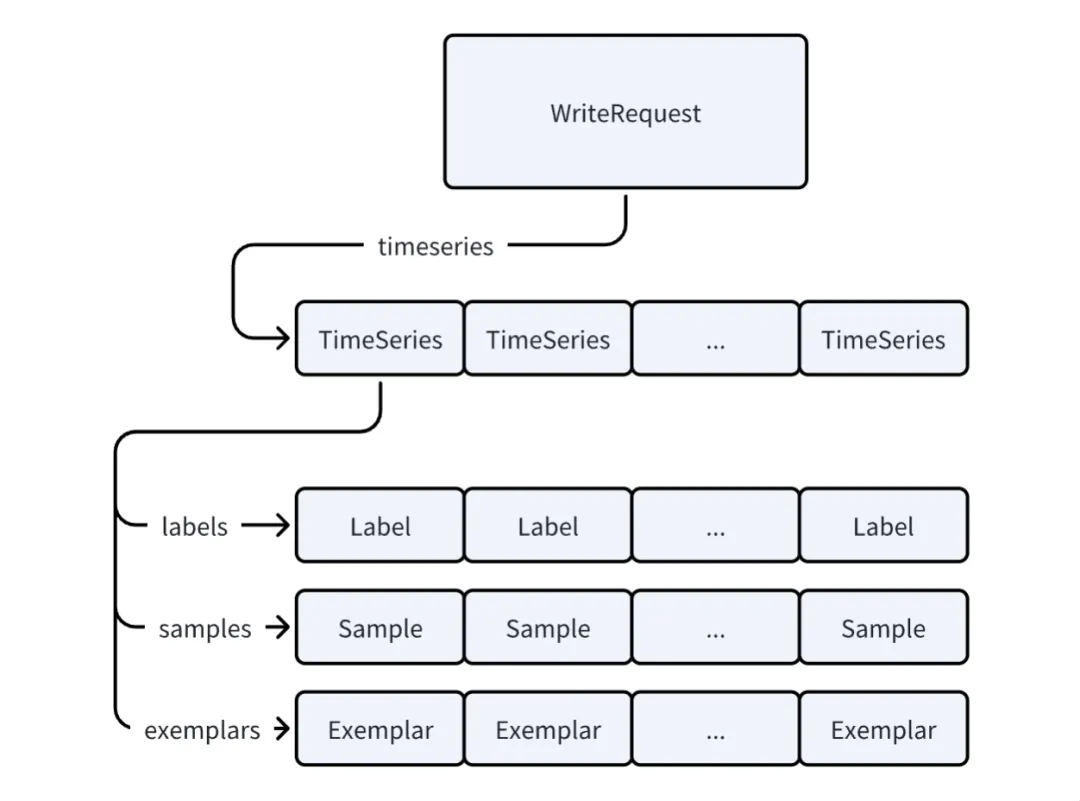
WriteRequest 持有一个 TimeSeries 的 vector,而每个 TimeSeries 又分别持有 Label ,Sample 和 Exemplar 的 vector。如果我们仅仅复用最外层的 WriteRequest,每次 clear 的时候,Labels,Samples 和 Exemplars 的 vector 都会被清除,根本达不到复用的目的。
而 Go 呢?我们可以看一看 WriteRequest 的 Reset 方法:
go
wr.Timeseries = tss[:0]并非是将 TimeSeries 字段设置为 nil,而是设置为一个空 slice,那么 slice 当中原有的元素仍然会被保留而不会被 GC(只是 len 字段设置为了 0 而已),因此 Go 的对象复用机制可以取得很好的避免反复分配内存的效果。
那么 Rust 有没有可能借鉴这个机制呢?
我们想到了 Rust 生态中另一个较为常用的 Protobuf 库 rust-protobuf v2.x 版本的一个机制:RepeatedField。其设计为了避免 Vec::clear 带来的 drop 开销,手动维护了 vec 和 len 字段,在 clear 时仅仅把 len 设为 0 而不调用 vec 的 clear,从而保证 vec 里面的元素以及这些元素内部的 vec 不被 drop。
那么问题来了,怎么把 RepeatedField 的机制集成到 PROST 里面呢?显然 PROST 是没有类似的配置项的,那么就需要我们把 PROST 的过程宏生成的代码手动展开了。
在这个过程中我们发现,有些字段是写入流程目前不需要的,我们也可以跳过他们。
bash
cargo bench -- decode/pooled_write_requesttext
decode/pooled_write_request
time: [2.6941 ms 2.7004 ms 2.7068 ms]
change: [-66.969% -66.417% -65.965%] (p = 0.00 < 0.05)
Performance has improved.Wow,我们通过 RepeatedField 机制成功将耗时降到了原先的 36% 左右。
那么这个耗时是否还能进一步降低呢?我们还能从 Go 的代码中学到什么?
值得一提的是,由于 RepeatedField 在使用上不如 Vec 方便,因此 rust-protobuf 的 3.x 版本已经去除了。不过 作者也提到过 可能会提供一个选项再把 RepeatedField 加回来。
🌟 当前性能对比回顾
Rust 基线耗时:7.3ms
Go 解析耗时:1.2ms
Rust 当前耗时:2.7ms
Step3:String or Bytes?
对应分支:
bash
git checkout step3/bytes众所周知,Go 中的 string 只是 bytes 的一个简单包装,反序列化 string 字段时只需要把原始 buffer 的指针和长度赋值给 string 字段即可。而 Rust 的 PROST 在反序列化 String 类型的字段时,需要将原始 buffer 中的数据复制到 String 中去,这样才能保证反序列化之后的结构体的生命周期和原始的 buffer 相互独立。但是这样就多了一次数据复制的开销。
我们是否也可以把 Label 的字段改为 Bytes 而不是 String 呢?我想起了 prost_build 中有个 Config::bytes 选项。在 PROST 的这个 PR 中支持将 bytes 类型的字段生成为 Bytes 而不是默认的 Vec<u8> 从而可以实现零拷贝的解析。我们同样可以将 Label 的 name 和 value 字段类型改为 Bytes。这样做的优点是无需复制,但是问题也很明显,在需要使用 Label 的地方还是需要把 Bytes 转换为 String 。在转换这个步骤中,我们可以选择 String::from_utf8_unchecked 来跳过字符串是否合法的检查从而进一步提高性能。当然如果 GreptimeDB 实例暴露在公网中这样的操作显然是不安全的,因此在 #3435 中我们提到了需要增加一个严格模式来校验字符串是否合法。
修改完 Label::name 和 Label::value 的类型之后我们再跑一次测试:
bash
cargo bench -- decode/pooled_write_request得到结果:
text
decode/pooled_write_request
time: [3.4295 ms 3.4315 ms 3.4336 ms]
change: [+26.763% +27.076% +27.383%] (p = 0.00 < 0.05)
Performance has regressed.怎么性能还变差了呢?不慌,我们采一个火焰图看看。

可以看到,绝大多数的 CPU 时间片都耗费在了 copy_to_bytes 上面。
从 prost 的解析 Bytes 字段的代码 中我们可以看到:
rust
pub fn merge<A, B>(
wire_type: WireType,
value: &mut A,
buf: &mut B,
_ctx: DecodeContext,
) -> Result<(), DecodeError>
where
A: BytesAdapter,
B: Buf,
{
check_wire_type(WireType::LengthDelimited, wire_type)?;
let len = decode_varint(buf)?;
if len > buf.remaining() as u64 {
return Err(DecodeError::new("buffer underflow"));
}
let len = len as usize;
//...
value.replace_with(buf.copy_to_bytes(len));
Ok(())
}而当 value 变量的类型为 Bytes 时,value.replace_with 又会调用一次 copy_to_bytes。
rust
impl sealed::BytesAdapter for Bytes {
...
fn replace_with<B>(&mut self, mut buf: B)
where
B: Buf,
{
*self = buf.copy_to_bytes(buf.remaining());
}
...
}那我们是否可以省略一次 copy 呢?虽然说 Bytes::copy_to_bytes 并不涉及到数据的复制,只是指针操作,但是其开销还是比较大的。
🌟 当前性能对比回顾
Rust 基线耗时:7.3ms
Go 解析耗时:1.2ms
Rust 当前耗时:3.4ms
Step4:消除一次复制
对应分支:
bash
git checkout step4/bytes-eliminate-one-copy由于我们解析 Prometheus 的 WriteRequest 都是从 Bytes 解析出来的,因此我们可以直接把泛型参数 B: Buf 去掉,特化成 Bytes。这样 prost::encoding::bytes::merge 就变成了下面的 merge_bytes 方法:
rust
#[inline(always)]
fn copy_to_bytes(data: &mut Bytes, len: usize) -> Bytes {
if len == data.remaining() {
std::mem::replace(data, Bytes::new())
} else {
let ret = data.slice(0..len);
data.advance(len);
ret
}
}
pub fn merge_bytes(value: &mut Bytes, buf: &mut Bytes) -> Result<(), DecodeError> {
let len = decode_varint(buf)?;
if len > buf.remaining() as u64 {
return Err(DecodeError::new(format!(
"buffer underflow, len: {}, remaining: {}",
len,
buf.remaining()
)));
}
*value = copy_to_bytes(buf, len as usize);
Ok(())
}替换完成之后再跑一遍 bench:
bash
cargo bench -- decode/pooled_write_request结果如下:
text
decode/pooled_write_request
time: [2.7597 ms 2.7630 ms 2.7670 ms]
change: [-19.582% -19.483% -19.360%] (p = 0.00 < 0.05)
Performance has improved.有进步,但不多,好像只是又回到刚刚的性能水平了。那么能不能再进一步呢?
🌟 当前性能对比回顾
Rust 基线耗时:7.3ms
Go 解析耗时:1.2ms
Rust 当前耗时:2.76ms
Step5:为什么 Bytes::slice 这么慢?
对应分支:
bash
git checkout step5/bench-bytes-slice首先我们看看,为什么 PROST 需要做两次 copy 呢?
主要是因为 PROST 的字段的 trait bound 是 BytesAdapter 而反序列化的 Bytes 的 trait bound 则是 Buf。虽然 Bytes 同时实现了两个 trait ,但是如果两个类型相互赋值,还是需要走 copy_to_bytes 转换两次。
merge 方法中,由于不知道 Buf 的具体类型,因此它需要先通过 Buf::copy_to_bytes 把 Buf 转换为 Bytes,然后把 Bytes 传给 BytesAdapter::replace_with,在其中再通过 <<Bytes as Buf>>::copy_to_bytes 将 Buf 转换为 Bytes。最终才能得到实现了 BytesAdapter 的具体类型 Bytes。

从 Prost 角度来看,Bytes::copy_to_bytes 并不涉及到数据的复制,因此可以看做是一个 zero copy 的操作。但是这个 zero copy 操作的开销并没有那么低。
我们做一个简单的测试 :
rust
c.benchmark_group("slice").bench_function("bytes", |b| {
let mut data = data.clone();
b.iter(|| {
let mut bytes = data.clone();
for _ in 0..10000 {
bytes = black_box(bytes.slice(0..1));
}
});
});go
func BenchmarkBytesSlice(b *testing.B) {
data, _ := ioutil.ReadFile("<any binary file>")
for n := 0; n < b.N; n++ {
b.StartTimer()
bytes := data
for i :=0; i < 10000; i++ {
bytes = bytes[:1]
}
b.StopTimer()
}
}其中 Go 的耗时是: 2.93us
text
goos: linux
goarch: amd64
pkg: github.com/VictoriaMetrics/VictoriaMetrics/lib/prompb
cpu: AMD Ryzen 7 7735HS with Radeon Graphics
BenchmarkBytesSlice-16 497607 2930 ns/op
PASS
ok github.com/VictoriaMetrics/VictoriaMetrics/lib/prompb 6.771s而 Rust 的耗时是:103.31us
text
slice/bytes
time: [103.23 µs 103.31 µs 103.40 µs]
change: [+7.6697% +7.8029% +7.9374%] (p = 0.00 < 0.05)可以看到 slice 这个操作 Rust 比 Go 慢了 2 个数量级。
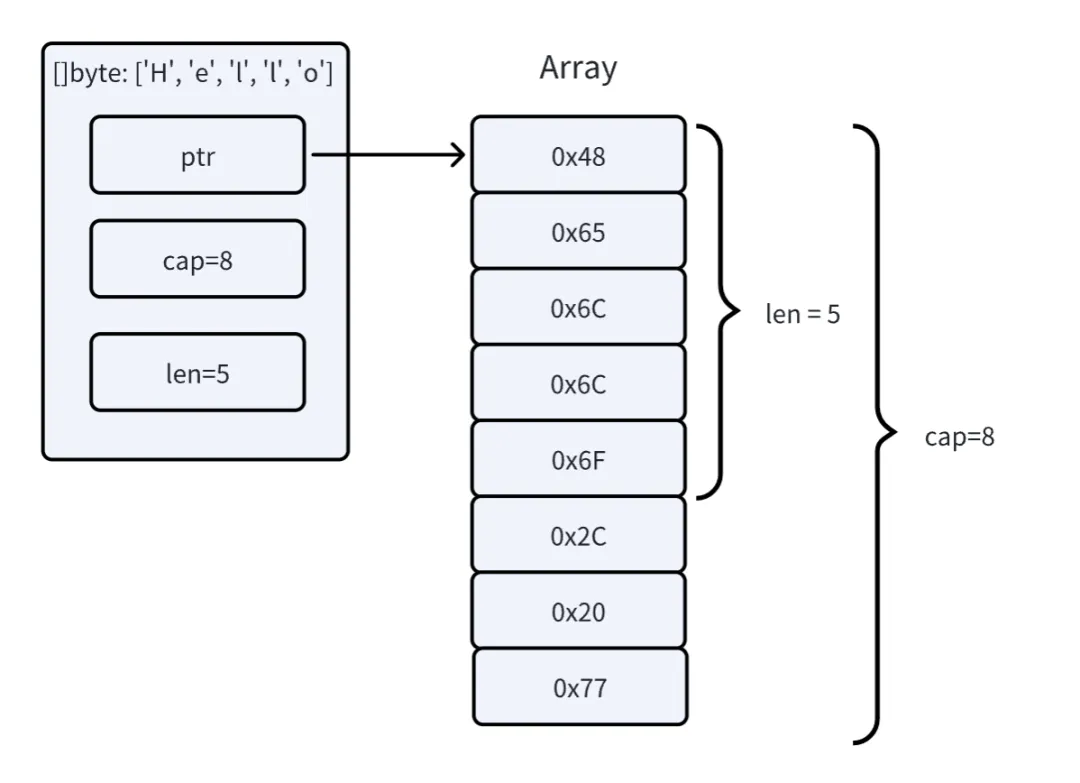
Go 的 slice 只包含 ptr、cap 和 len 三个字段,slice 操作也只涉及到三个变量的修改。
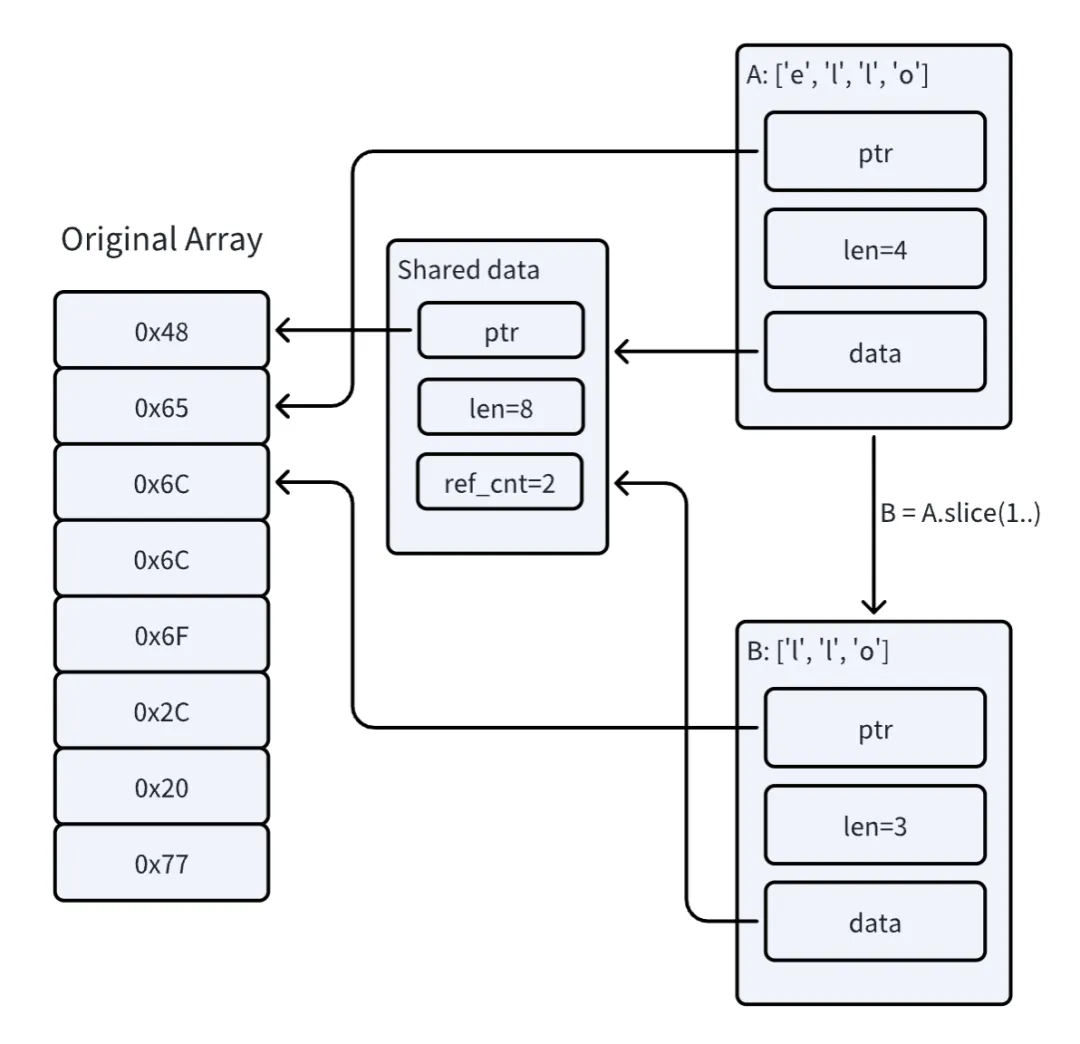
而在 Rust 中,为了保证内存安全,反序列化的输出(WriteRequest)必须和输入数据(Bytes)的生命周期相互独立,为了避免数据复制,Bytes 使用了引用计数的机制。如下图中,A 和 B 两个 Bytes 实例本质上指向的是同一块底层的内存区域,但是各自还有一个 data 指针指向保存了引用计数信息的结构体,只有当引用计数值为 0 的时候,原始的内存数组才会被 drop。这样虽然避免了复制,但是也带来了一些额外的开销。
通过
From<Vec<u8>>构造出来的的Bytes的 slice 操作基于引用计数,每次 slice 的时候需要复制原始 buffer 的指针、长度、引用计数、slice 返回值的指针和长度等等,和 Go 的基于可达性分析的垃圾回收机制比起来效率肯定是差很多的;由于 Bytes 支持多种实现,部分方法(如 clone)依赖 vtable 进行动态分发;
为了确保 slice 操作的安全性,Bytes 在很多地方手动插入了 bound check。
Step6:一点点 unsafe
对应分支:
bash
git checkout step6/optimize-slice那么这一块的开销有没有办法继续优化呢?在 GreptimeDB 的写入接口有个特点,即解析出了 WriteRequest 之后需要立刻转换为 GreptimeDB 自身的数据结构而不是直接使用 WriteRequest,也就是说,反序列化的输入 Bytes 的生命周期是一定长于解析出来的结构体的。因此我们可以对 slice 操作做一些 hack 的修改,直接根据原始数组的指针和长度组装返回的 Bytes。这样,只要原始的 A 实例存活,所有 slice 出来的 Bytes 实例所指向的内存一定是有效的。
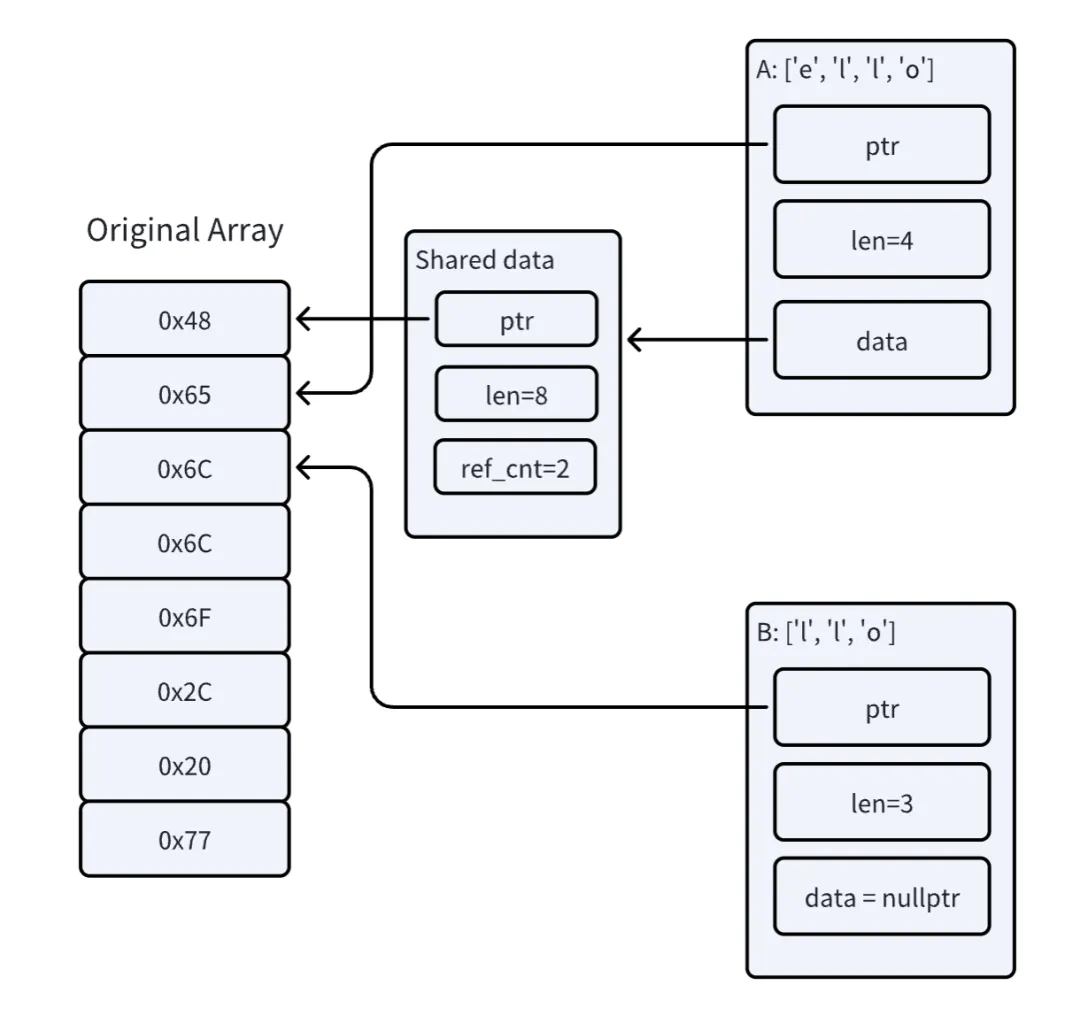
我们将 data.slice(..len) 操作替换为如下的 split_to 方法:
rust
pub fn split_to(buf: &mut Bytes, end: usize) -> Bytes {
let len = buf.len();
assert!(
end <= len,
"range end out of bounds: {:?} <= {:?}",
end,
len,
);
if end == 0 {
return Bytes::new();
}
let ptr = buf.as_ptr();
let x = unsafe { slice::from_raw_parts(ptr, end) };
// `Bytes::drop` does nothing when it's built via `from_static`.
Bytes::from_static(x)
}
//.benchmark
c.bench_function("split_to", |b| {
let data = data.clone();
b.iter(|| {
let mut bytes = data.clone();
for _ in 0..10000 {
bytes = black_box(unsafe { split_to(&bytes, 1) });
}
});
})再 Bench 一下看看效果:
text
slice/bytes
time: [103.23 µs 103.31 µs 103.40 µs]
change: [+7.6697% +7.8029% +7.9374%] (p = 0.00 < 0.05)
slice/split_to
time: [24.061 µs 24.089 µs 24.114 µs]
change: [+0.2058% +0.4198% +0.6371%] (p = 0.00 < 0.05)Wow 一下子从 103us 降低到了 24us,再看看反序列化整体的开销呢?
text
decode/pooled_write_request
time: [1.6169 ms 1.6181 ms 1.6193 ms]
change: [-37.960% -37.887% -37.815%] (p = 0.00 < 0.05)
Performance has improved.终于,我们可以把解析单个 WriteRequest 的耗时降低到了 1.6ms 左右,只比 Go 的 1.2ms 慢 33.3% !
当然这里还有优化空间,假如我们彻底摒弃掉 Bytes,而使用 Rust 中的 slice:&[u8] ,可以达到接近 Go 的性能(仅考虑 slice 的开销):
rust
c.bench_function("slice", |b| {
let data = data.clone();
let mut slice = data.as_ref();
b.iter(move || {
for _ in 0..10000 {
slice = black_box(&slice[..1]);
}
});
});对应结果:
text
slice/slice
time: [4.6192 µs 4.7333 µs 4.8739 µs]
change: [+6.1294% +9.8655% +13.739%] (p = 0.00 < 0.05)
Performance has regressed.但是由于这部分开销在整个写入链路中占比已经非常低,再继续优化对整体吞吐的影响并不会很大,感兴趣的小伙伴可以自行尝试一下使用 slice 重构反序列化的代码。
🌟 当前性能对比回顾
Rust 基线耗时:7.3ms
Go 解析耗时:1.2ms
Rust 当前耗时:1.62ms
总结
在本篇文章中,我们尝试了多种手段去优化反序列化 Protobuf 编码的 WriteRequest 数据的开销。首先我们使用了池化技术避免反复的内存分配和释放,从而直接将耗时降低到 baseline 的 36% 左右。接着为了使用零拷贝的特性,我们将 Label 的 String 字段替换为了 Bytes 类型,但是发现性能却下降了。通过火焰图我们发现 Prost 为了让 Bytes 在 BytesAdapter 和 Buf 两个 trait 之间转换引入了一些额外的开销。通过把类型特化我们得以去除这些开销。同时我们还在火焰图中发现了 Bytes:slice 自身为了确保内存安全引入的一些额外的开销。考虑到我们的用法,我们 hack 了 slice 的实现从而最终将耗时降低到 baseline 的 20% 左右。
总的来说,Rust 为了确保内存安全,在直接操作字节数组时限制比较多。如果使用 Bytes 可以通过引用计数绕过生命周期的问题,但是代价就是效率很低;要么使用slice &[u8] ,就不得不面对生命周期的传染。在本文中采取了一个折中的办法即通过 unsafe 方法绕过 Bytes 的引用计数机制,手动确保反序列化的输入 buffer 在输出的整个生命周期内有效。值得一提的是,这并不是一个普适的优化手段,但是当开销处于热点代码路径上时,还是值得尝试的。
此外,“零成本抽象” 是 Rust 语言重要的设计理念之一,但是不是所有的抽象都是没有成本的。在本篇文章中,我们看到了 Prost 的 BytesAdapter 和 Buf 这两个 trait 之间带来的相互转换的开销,以及 Bytes 为了兼容不同底层数据源引入的方法动态分派的开销等等。这也提醒我们在代码的关键路径上要更加关注底层的实现,通过持续 profiling 来确保性能不降级。
除了反序列化方面的优化,我们在为 GreptimeDB v0.7 的写入路径上还做了其他的努力。原本 WriteRequest 需要完整解析出来之后才会转换为 GreptimeDB 的 RowInsertRequest,我们去除了中间结构,直接在反序列化 WriteRequest 的过程中直接将 TimeSeries 结构转换为表维度的写入数据,从而减少了一次对所有时间线的遍历(#3425,#3478),也降低了中间结构的内存开销。此外在构建表维度的写入数据时,Rust 默认基于 SipHash 的 HashMap 性能不甚理想,我们通过替换为基于 aHash 的 HashMap 获得了接近 40% 的查表性能提升。性能的优化从来都是一个系统性的工作,点点滴滴细微处的积累才能厚积薄发,GreptimeDB 团队始终在努力的路上。
关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack

