本页内容
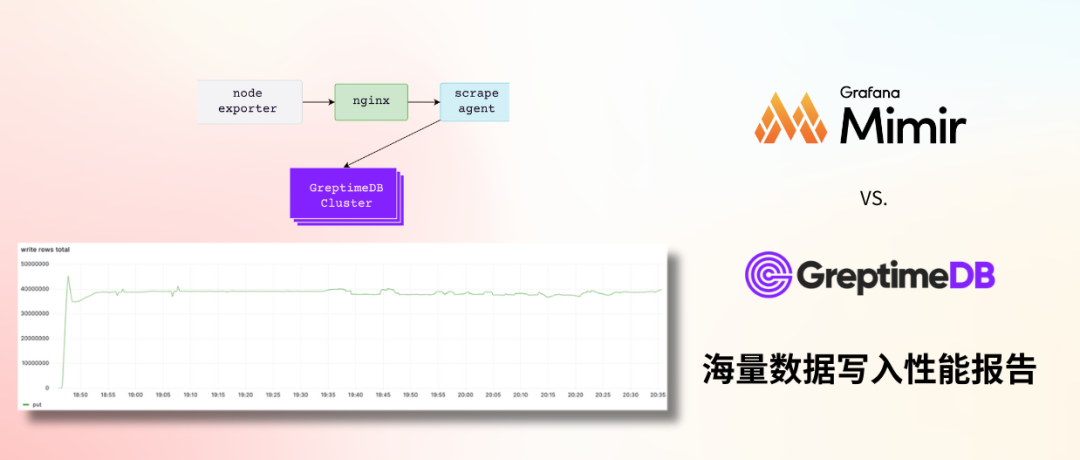
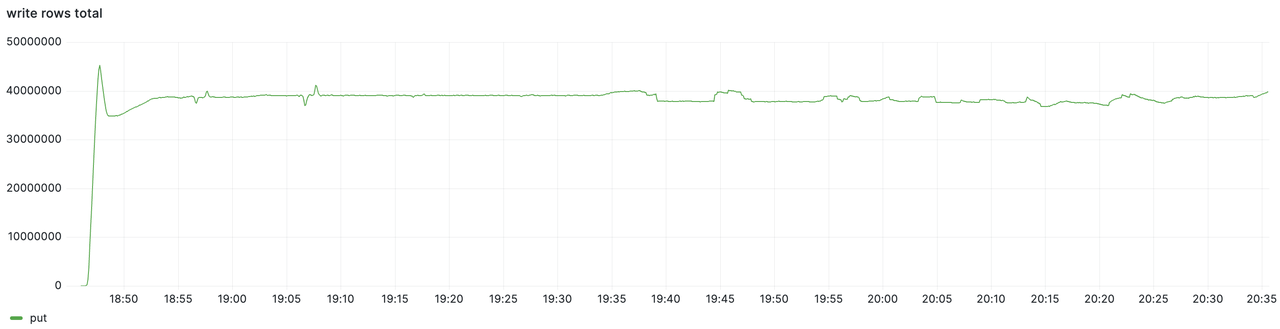
GreptimeDB 在行业标准测试 Prometheus-Benchmark 当中以 100 个 8c16g 规格节点的集群,在 datanode 峰值水位为 CPU 38%、内存 40% 的负载下,承接了每秒约 4000 万点的写入流量。总体活跃时间线 6.1 亿条,每十分钟更新 615 万条时间线,在测试的 1.5 小时内均能稳定写入。
测试结果说明 GreptimeDB 的架构设计能够支撑超大规模的数据集群,并且在同等规模集群下,GreptimeDB 的资源占用极低。对比同样适用对象存储的 Grafana Mimir,在处理同等规模的数据下,Mimir 需要消耗 5 倍以上的 CPU 和内存资源(基于 Mimir 测试报告折算)。
测试环境及工具
本轮测试中所使用的 Prometheus Benchmark 压测工具的相关关键参数及解释如下:
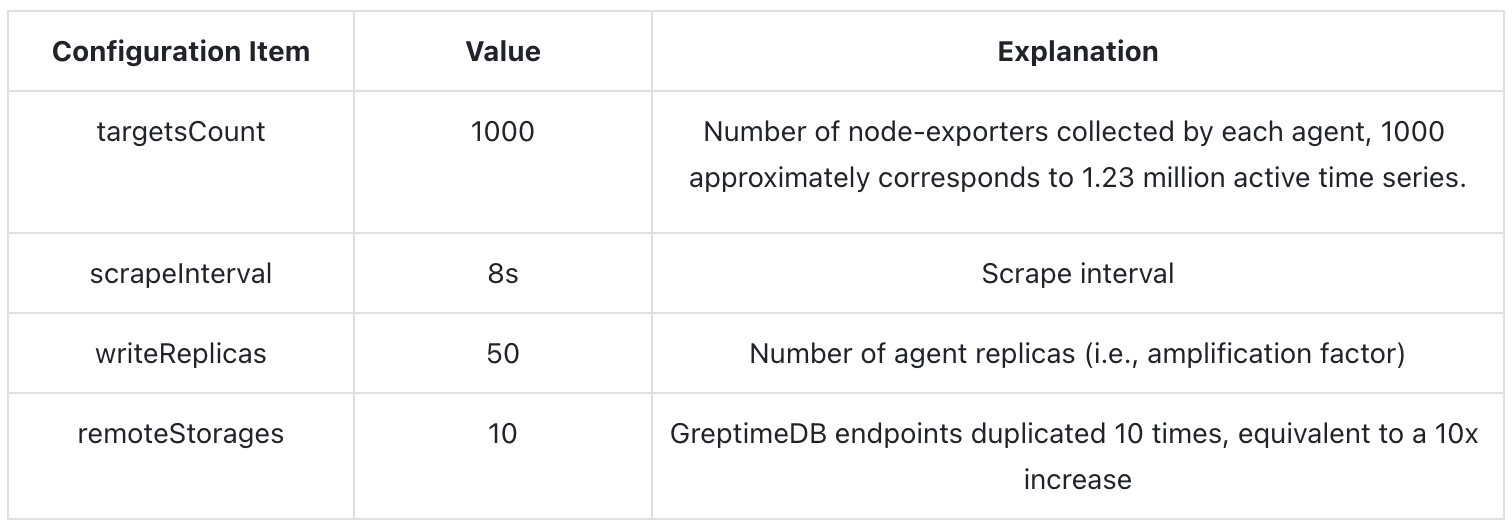
通过如上配置最终构建的理论数据产生速率约每秒 4160 万点。
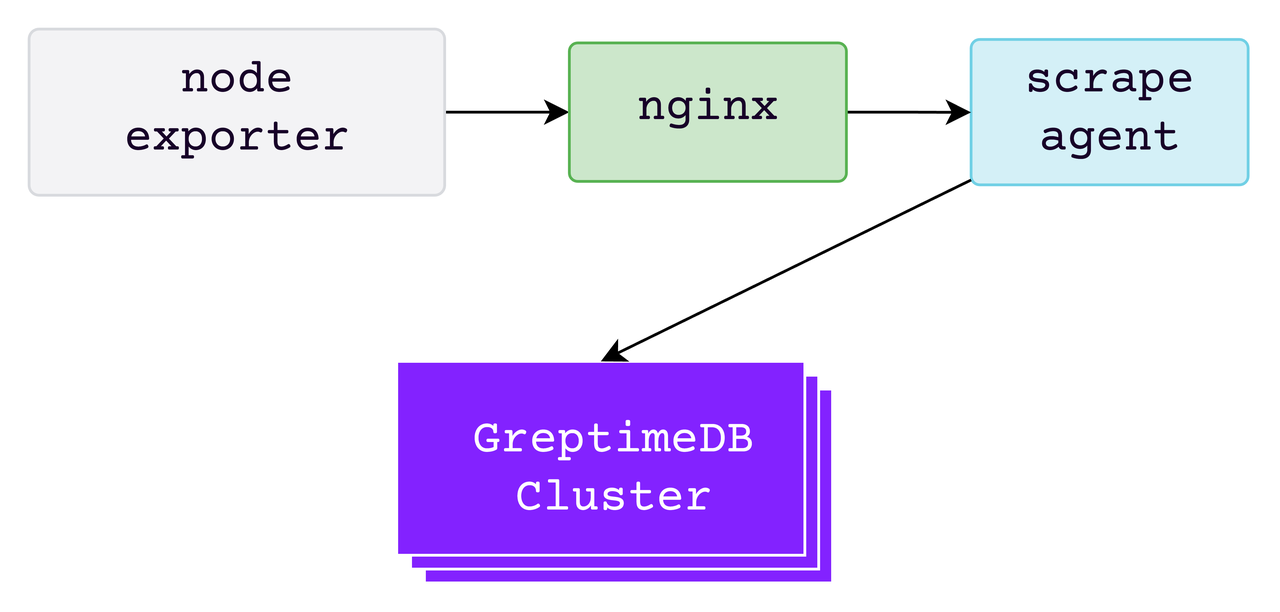
测试环境中一共有两个集群,分别是上述的 Prometheus Benchmark 的压力集群和 GreptimeDB 的数据库集群。两个集群均在 AWS EKS 部署。其中,GreptimeDB 集群所使用的镜像版本为 v0.8.2 所涉及到的各组件的部署规格及数量如下表所示:
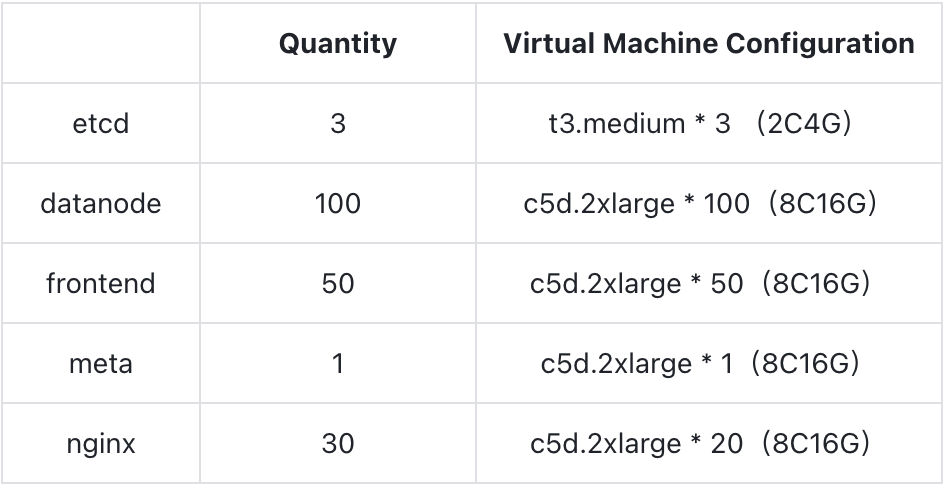
GreptimeDB 集群的 WAL 组件为 AWS EBS;SST flush 以及 compaction 均基于 S3 完成。本地盘规格为 GP3,S3 为相同 Region 的 Standard 类别。在本次测试中不包含节点调度迁移等的情况,各个节点之间使用 Round-Robin Selector 均匀分配数据分区,一共有 200 个 Regions。
详细测试数据
写入吞吐
本次测试一共持续约 1.5 小时,总和写入量以及分节点的写入量监控数据如下,可以看到在 1.5 个小时内集群写入流量能一直稳定保持在每秒约 4000 万点的速率:
资源占用
对 GreptimeDB 集群水位进行观察,可以看到如下数据:
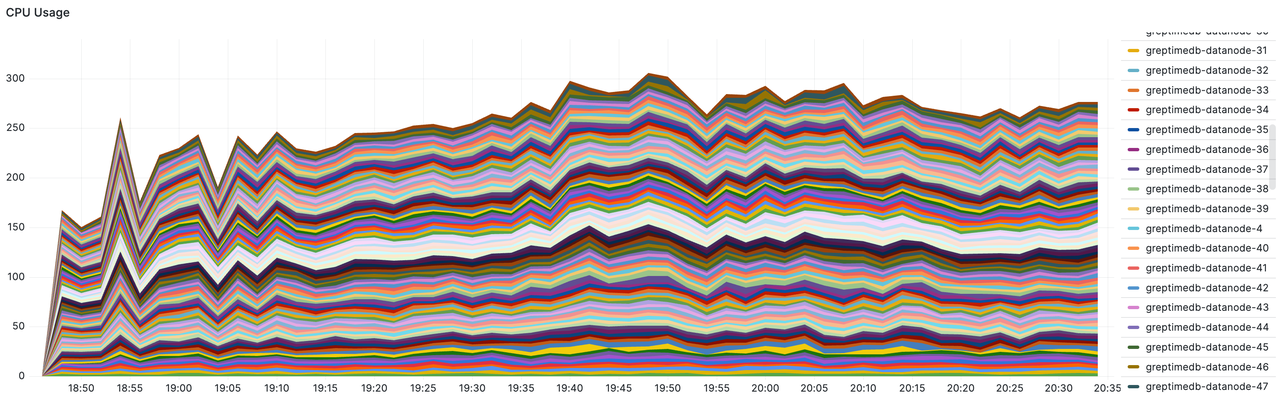
- Datanode 的总和 CPU 使用率。总核数为 100 * 8c = 800c,峰值为 305,约占 38%。
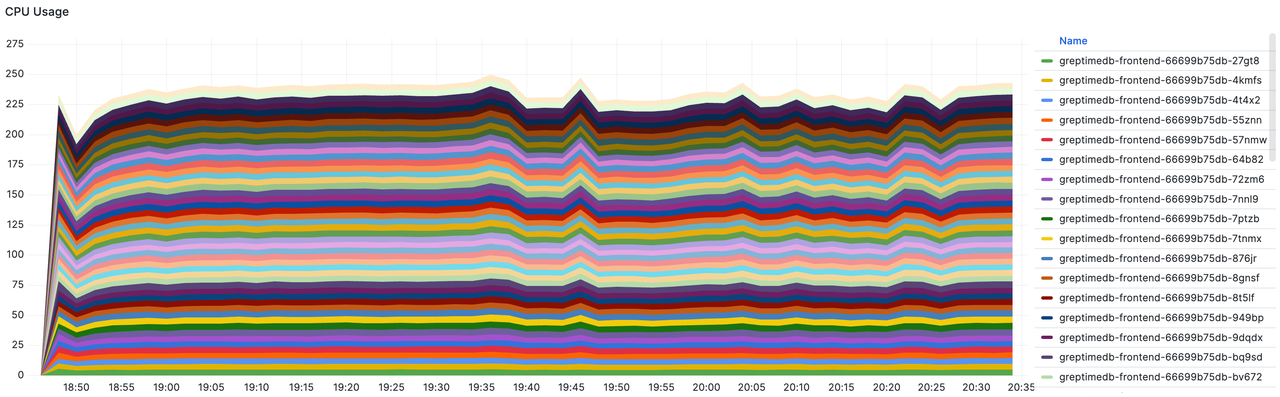
- Frontend 的总和 CPU 使用率。总核数为 50 * 8c = 400c,峰值为250,约占 63%。
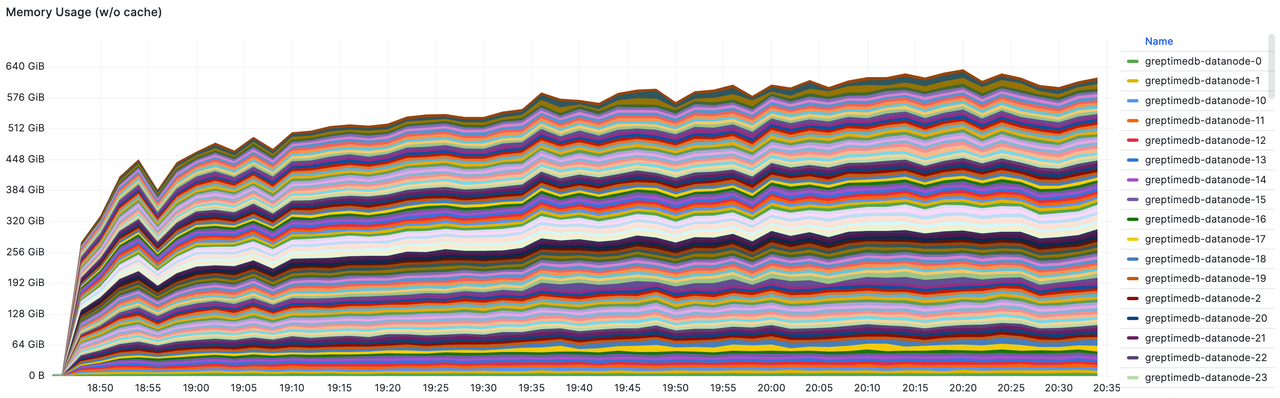
- Datanode 的总和内存占用。总内存为 100 * 16GiB = 1600 GiB。峰值为640GiB,约占 40%。
- Frontend 的总和内存占用。总内存为 50 * 16GiB = 800 GiB。峰值为 110 GiB,约占 14%。
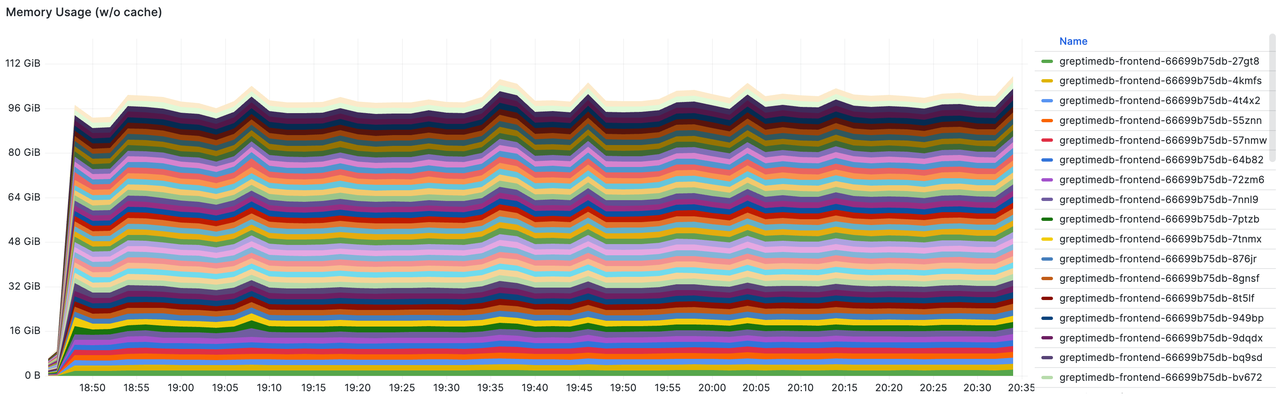
存储写入流量
下图是 S3 写入流量的统计,带宽占用基本在 512 MiB/s 以下,最终一个半小时内的总写入量为 2.8 TiB。
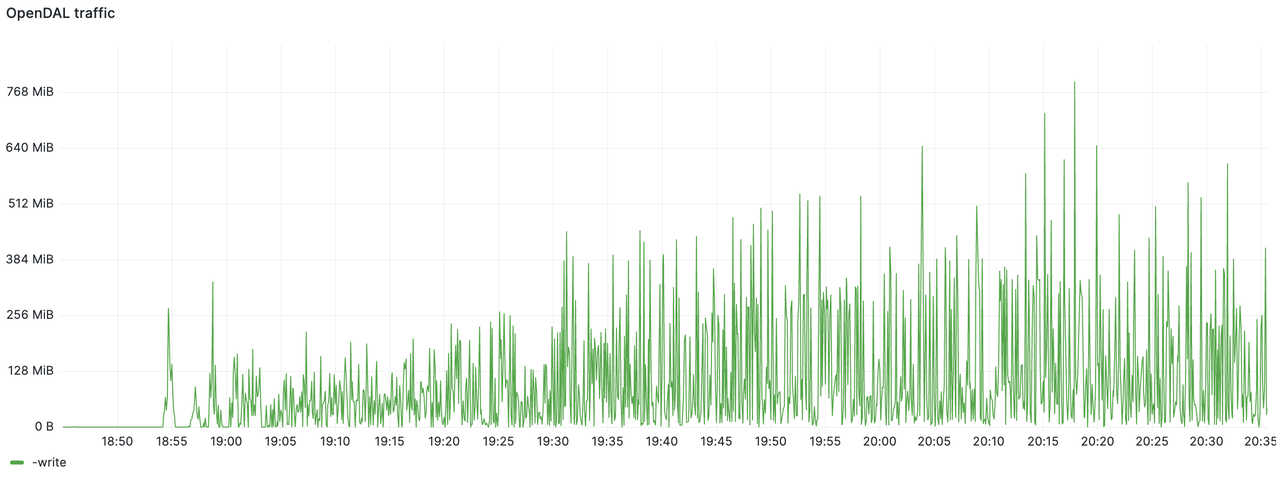
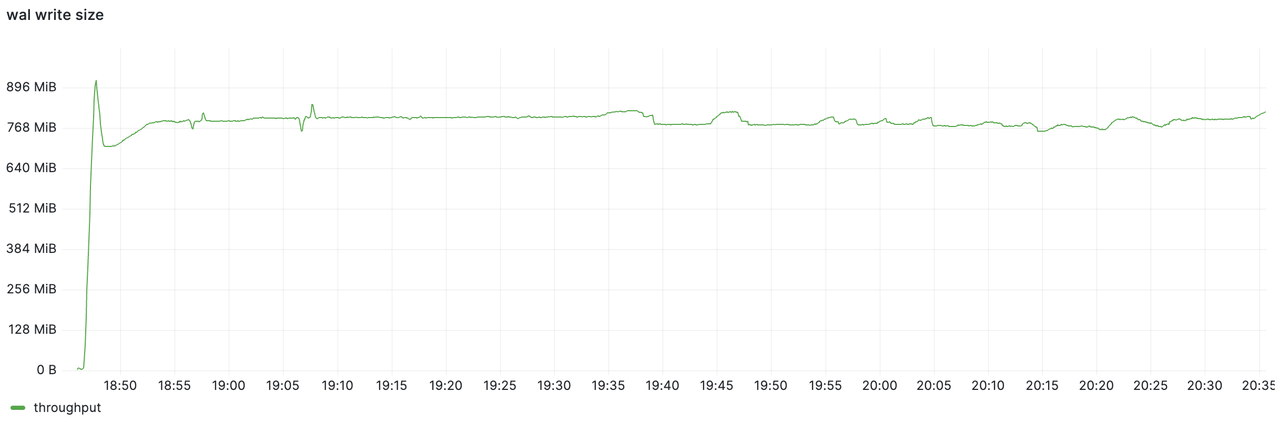
而 WAL 组件观测到的写入流量约为 800 MiB/s。通过两张图的对比能够看到 GreptimeDB 对数据进行了有效压缩,压缩比达到 75%,降低了数据刷写流量。最终压测结束时 S3 的目录大小远小于 1 TiB。
结语
100 个节点远远不是上限,本次测试验证了 GreptimeDB 架构无限扩展的能力,对比同样基于对象存储的 Grafana Mimir 有 5 倍的资源消耗降低。
下一步我们将进一步优化性能和测试,使 GreptimeDB 可承载海量时序指标数据的读写和分析。本次测试的版本是 v0.8.2, GreptimeDB 已发布 v0.9.0 版本,引入了日志引擎和全文检索能力,进一步优化了性能和稳定性,朝着成为一个融合 Metrics、Logs 和 Events 的统一时序数据库迈进了一大步,欢迎各位开发者测试使用。
关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~ Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack

