本页内容
本报告将初步给出 v0.9 首次引入的日志存储和检索的单机性能,包括写入和查询性能、资源占用和压缩率等。在可观测性领域中,常用的日志系统包括经典的 ELK 组合(ElasticSearch)以及在国内广泛使用的 ClickHouse。我们选择这两个系统进行横向对比,以供参考。GreptimeDB 面向云原生环境设计,因此我们也测试了基于 S3 对象存储的读写性能。
先来看结论:
- GreptimeDB 在写入性能、资源占用(CPU、内存和磁盘)方面都表现最优或次优,并且在本地磁盘和 S3 对象存储模式下,性能表现没有下降。单机在 8C16G 机器规格下达到 12 万行日志每秒写入,是 ES 的 3 倍,压缩率 13% 最优,内存占用仅为 ES 的 1/32;
- ElasticSearch 的资源消耗最大,写入最慢,但是换来的查询性能最优;
- GreptimeDB 大部分查询性能和 ClickHouse 接近,能满足日志使用场景。
以上结论跟三个产品面向的场景有关,我们在总结部分展开,下面是详细的测试报告。
测试场景
测试数据和流程
我们选用 nginx access log 作为写入数据,一行数据的样例如下:
129.37.245.88 - meln1ks [01/Aug/2024:14:22:47 +0800] "PATCH /observability/metrics/production HTTP/1.0" 501 33085我们使用 vector 这个开源可观测数据 pipeline 来生成并写入上面的数据。整体测试的流程如图:
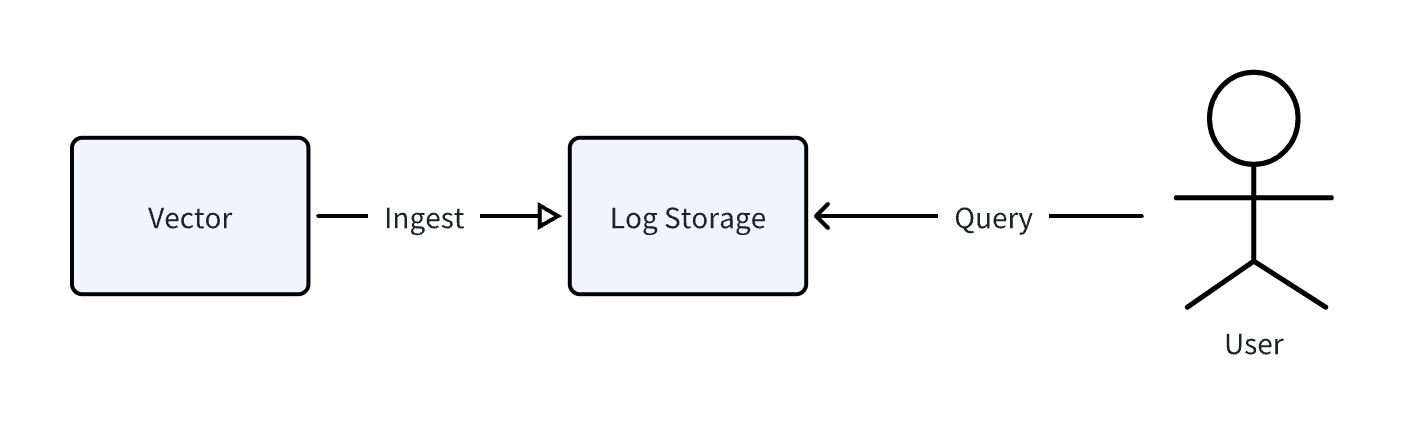
数据写入后,我们分别使用 SQL(GreptimeDB 和 ClickHouse)和 ElasticSearch HTTP 协议进行查询测试。
写入方式
写入方式我们也做了区分:
切分模式(Structured model):将每行日志,切分出多个字段,比如上面这行日志,可以切分出
http_version、ip、method、path、status等字段。我们同样使用 vector 进行日志的解析和切分;全文模式(Unstructured model):将该条日志,除了时间戳以外,完整存储为一个
message的文本字段,并启用全文索引。
我们也将比较两种模式带来的差异。
软硬件说明
硬件环境
| 机器规格 | 操作系统 |
|---|---|
| aws c5d.2xlarge, 8 CPU 16 Gib memory | ubuntu 24.04 LTS |
软件版本及设置
| GreptimeDB | v0.9.2 |
| ClickHouse(下文统称 CH) | 24.9.1.219 |
| ElasticSearch(下文统称 ES) | 8.15.0 |
如无特殊说明,三个存储都采用默认配置。
GreptimeDB S3 配置,开启了对象存储的读写 Buffer/Cache:
toml
[storage]
type = "S3"
bucket = "ap-southeast-1-test-bucket"
root = "logitem_data"
access_key_id = "xxx"
secret_access_key = "xxx"
endpoint = "endpoint"
region = "ap-southeast-1"
cache_path = "/home/ubuntu/s3cache"
cache_capacity = "20G"
[[region_engine]]
[region_engine.mito]
enable_experimental_write_cache = true
experimental_write_cache_size = "20G"切分模式设置
Vector 解析配置:
toml
[transforms.parse_logs]
type = "remap"
inputs = ["demo_logs"]
source = '''
. = parse_regex!(.message, r'^(?P<ip>\S+) - (?P<user>\S+) \[(?P<timestamp>[^\]]+)\] "(?P<method>\S+) (?P<path>\S+) (?P<http_version>\S+)" (?P<status>\d+) (?P<bytes>\d+)$')
# Convert timestamp to a standard format
.timestamp = parse_timestamp!(.timestamp, format: "%d/%b/%Y:%H:%M:%S %z")
# Convert status and bytes to integers
.status = to_int!(.status)
.bytes = to_int!(.bytes)
'''GreptimeDB 建表语句:
sql
--启用了 append 模式,并且将 user、path 和 status 设置为 Tag 类型(即主键)
CREATE TABLE IF NOT EXISTS `test_table` (
`bytes` Int64 NULL,
`http_version` STRING NULL,
`ip` STRING NULL,
`method` STRING NULL,
`path` STRING NULL,
`status` SMALLINT UNSIGNED NULL,
`user` STRING NULL,
`timestamp` TIMESTAMP(3) NOT NULL,
PRIMARY KEY (`user`, `path`, `status`),
TIME INDEX (`timestamp`)
)
ENGINE=mito
WITH(
append_mode = 'true'
);ClickHouse 建表语句:
sql
--使用默认 MergeTree 引擎,定义同样的 sorting key。
CREATE TABLE IF NOT EXISTS test_table
(
bytes UInt64 NOT NULL,
http_version String NOT NULL,
ip String NOT NULL,
method String NOT NULL,
path String NOT NULL,
status UInt8 NOT NULL,
user String NOT NULL,
timestamp String NOT NULL,
)
ENGINE = MergeTree()
ORDER BY (user, path, status);ElasticSearch 建表语句 (mapping):
json
{
"vector-2024.08.19": {
"mappings": {
"properties": {
"bytes": {
"type": "long"
},
"http_version": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"ip": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"method": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"path": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"status": {
"type": "long"
},
"timestamp": {
"type": "date"
},
"user": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}全文模式设置
GreptimeDB 建表语句:
sql
--message 列启用 FULLTEXT 选项,开启全文索引
CREATE TABLE IF NOT EXISTS `test_table` (
`message` STRING NULL FULLTEXT WITH(analyzer = 'English', case_sensitive = 'false'),
`timestamp` TIMESTAMP(3) NOT NULL,
TIME INDEX (`timestamp`)
)
ENGINE=mito
WITH(
append_mode = 'true'
);ClickHouse 建表语句:
sql
SET allow_experimental_full_text_index = true;
CREATE TABLE IF NOT EXISTS test_table
(
message String,
timestamp String,
INDEX inv_idx(message) TYPE full_text(0) GRANULARITY 1
)
ENGINE = MergeTree()
ORDER BY tuple();ElasticSearch:
json
{
"vector-2024.08.19": {
"mappings": {
"properties": {
"message": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"service": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"source_type": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"timestamp": {
"type": "date"
}
}
}
}
}写入性能
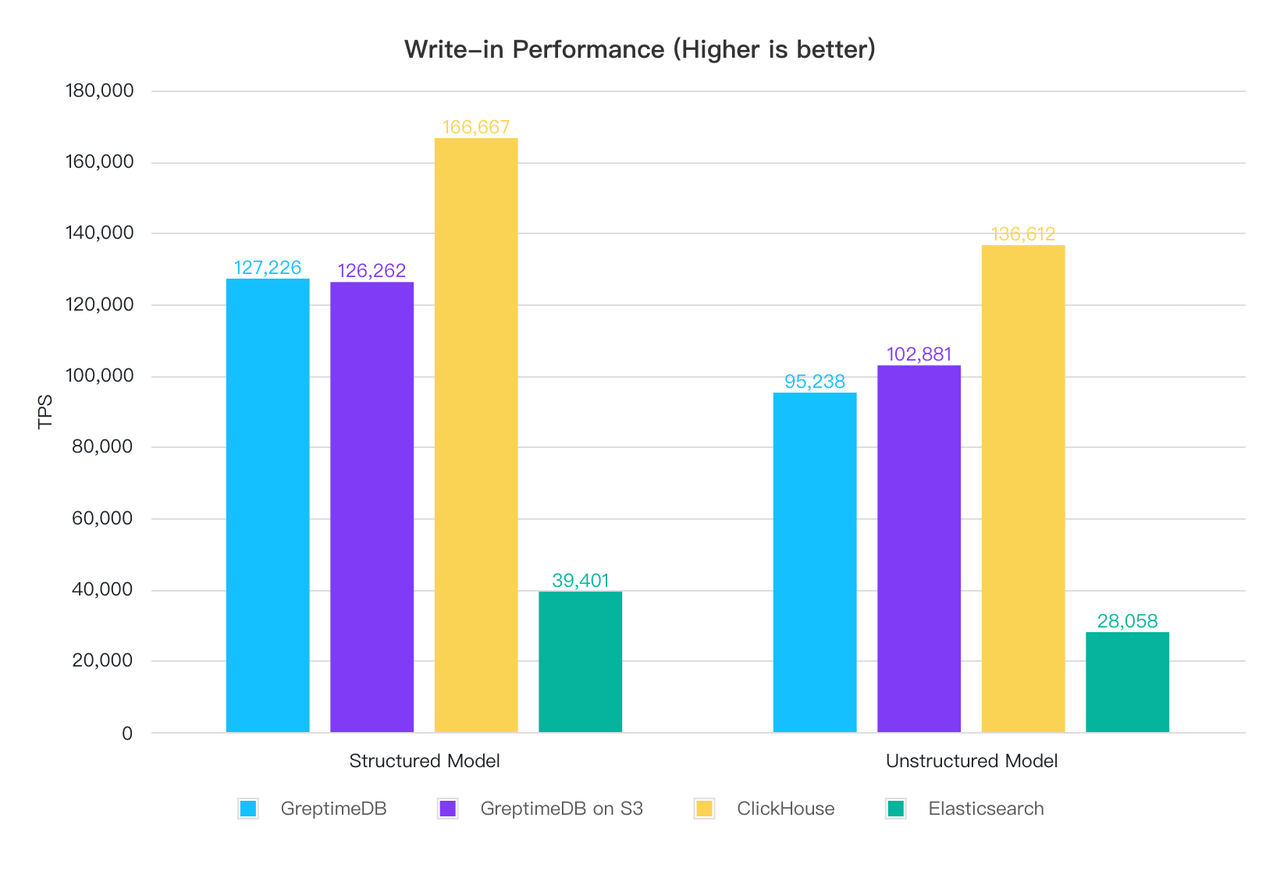
不限速写入 1 亿条数据:
| 切分模式 | 全文模式 | |||
|---|---|---|---|---|
| 写入耗时(单位:分钟) | 平均 TPS | 写入耗时(单位:分钟) | 平均 TPS | |
| GreptimeDB | 13.1 | 127,226 | 17.5 | 95,238 |
| GreptimeDB on S3 | 13.2 | 126,262 | 16.2 | 102,881 |
| ClickHouse | 10 | 166,667 | 12.2 | 136,612 |
| ElasticSearch | 42.3 | 39,401 | 59.4 | 28,058 |
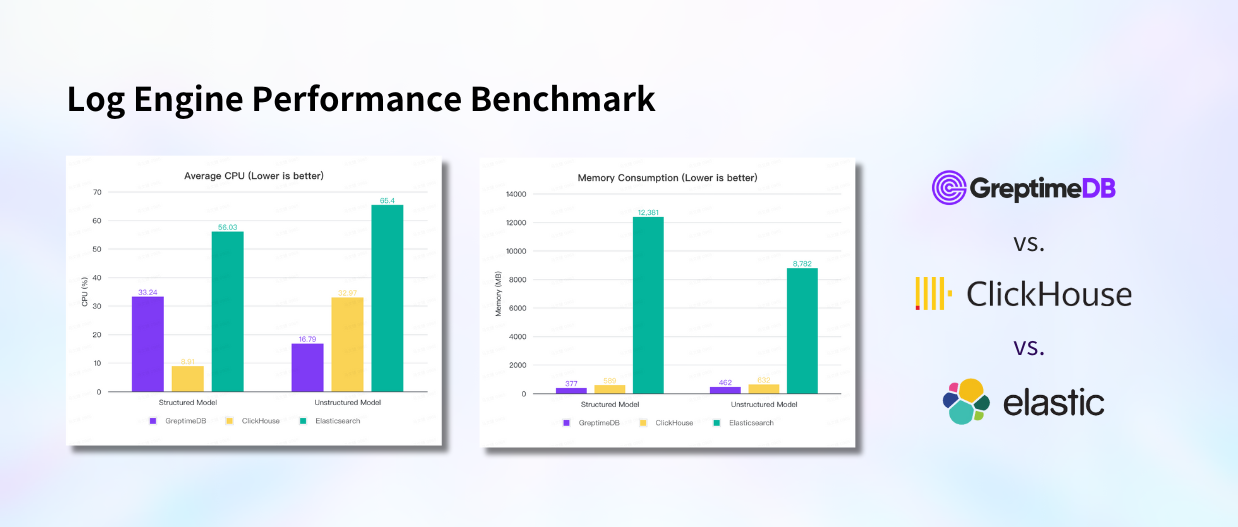
切分模式下,写入性能上 CH 最佳, GreptimeDB 本地磁盘模式和 S3 模式写入性能相当,都在 12~13 万行每秒左右, ES 最差,并且差距较大,仅为 GreptimeDB 的 1/3, ClickHouse 的 1/4;
全文模式下,整体横向对比结论不变,但是写入性能都有所下降,GreptimeDB 下降 25%,ClickHouse 下降 18%,ES 下降 29%,可见全文索引对写入的影响不小。
资源占用和压缩率
资源占用
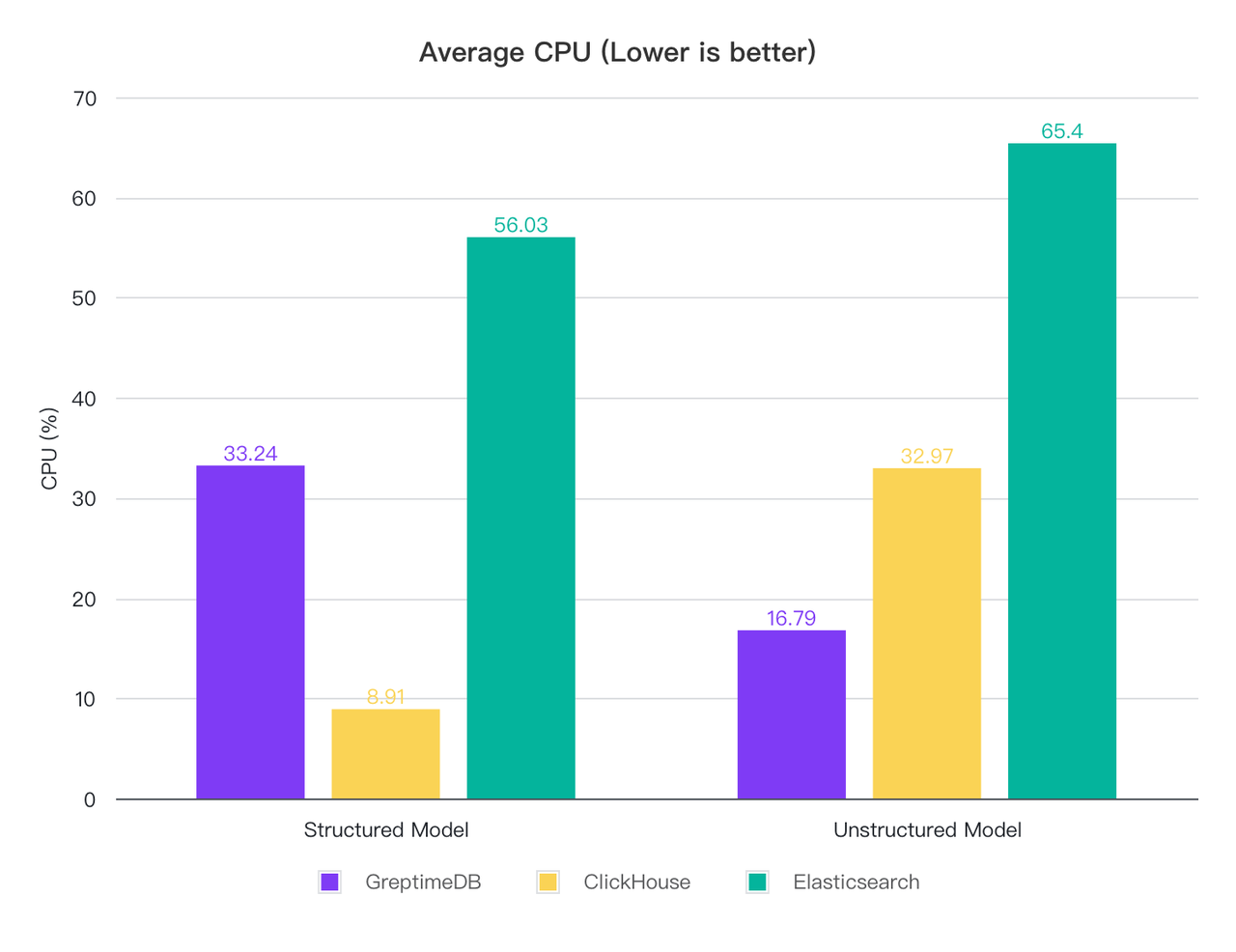
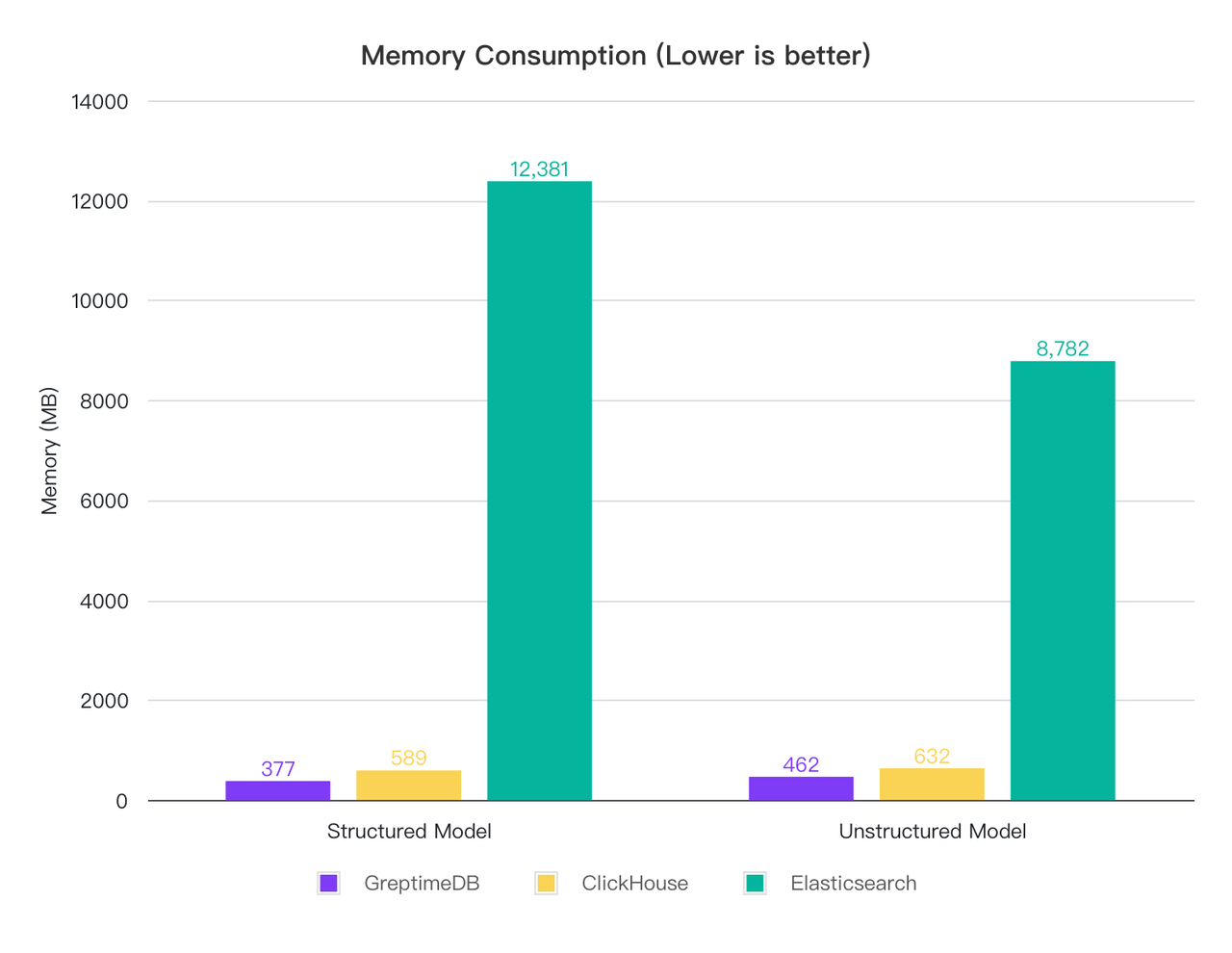
为了观察写入过程中的资源占用,我们将写入速度限速为 2 万行每秒,然后采集 CPU 和内存占用情况:
| 切分模式 | 全文模式 | |||
|---|---|---|---|---|
| CPU(%) | Memory(MB) | CPU(%) | Memory(MB) | |
| GreptimeDB | 33.24 | 377 | 16.79 | 462 |
| ClickHouse | 8.91 | 589 | 32.97 | 632 |
| ElasticSearch | 56.03 | 12,381 | 65.40 | 8,782 |
可以看到:
切分模式下,ClickHouse 的 CPU 消耗最低,GreptimeDB 其次, ES 消耗较高,是 CH 的 6 倍, GreptimeDB 的 1.7 倍,内存上 GreptimeDB 消耗最低, ClickHouse 其次,而 ES 的内存占用超过了 12 G,是 CH 的 21 倍, GrptimeDB 的 32 倍;
全文模式下,无论是 CPU 还是内存,都是 GreptimeDB 最优,其次 ClickHouse,ES 仍然是消耗最高的,尤其是内存;
测试过程中发现 ClickHouse 的 CPU 波动最大,最高可以到 139%。
这个结果其实跟三者的架构,以及针对优化的场景有关,我们最后再分析。
压缩率
原始 10 亿条数据在 10 GB 大小左右,我们再来看下三者的压缩率:
| 切分模式 | 全文模式 | ||||
|---|---|---|---|---|---|
| 磁盘占用(GB) | 压缩率 | 磁盘占用(GB) | 压缩率 | ||
| GreptimeDB | data | 1.3 | 13% | 3.3 | 33% |
| ClickHouse | 压缩前 | 7.6 | 15.5 | ||
| 压缩后 | 2.6 | 26% | 5.1 | 51% | |
| ElasticSearch | 压缩前 | 14.6 | 19.0 | ||
| 压缩后 | 10.2 | 102% | 17.2 | 172% | |
由于 ClickHouse 和 ES 在写入完成后会持续对数据进行压缩,我们这里同时记录刚写入完成和数据大小不再变化后的数据大小。可以看到:
**任何模式下, GreptimeDB 的压缩率都是最好的,切分模式下是原始数据的 13%,全文模式下是原始数据的 33%。**ClickHouse 其次,也都比原始数据更小,而 ES 最差,由于索引构建的开销,整体数据都比原始数据更大;
**切分模式下的压缩率都好于全文模式。**切分模式下,更多的列被提取出来,而 GreptimeDB 是列存结构,因此压缩率更优。
查询性能
查询场景
我们将查询场景区分为 6 个,覆盖比较典型的日志使用场景:
Count 统计查询:统计全表数据行数;
关键词匹配查询:匹配日志中的 user、method、endpoint、version、code 分别为特定值;
区间统计查询:使用时间范围统计约一半(5,000 万行)数据量的查询;
中间时间范围查询:取时间中间范围一分钟,并查询 1000 行数据;
最近时间范围查询:取最近时间范围一分钟,并查询 1000 行数据;
关键词匹配 + 区间查询:查询特定时间范围内的字段匹配结果。
GreptimeDB 和 ClickHouse 都使用 SQL 进行查询,前者使用 MySQL 客户端工具,后者使用 CH 自身提供的命令行客户端:https://Clickhouse.com/docs/en/interfaces/cli
ElasticSearch 我们使用 search 的 REST API:https://www.elastic.co/guide/en/elasticsearch/reference/current/search-search.html
切分模式查询性能
| 平均耗时 / 单位 ms | GreptimeDB | GreptimeDB on S3 | ClickHouse | ElasticSearch |
|---|---|---|---|---|
| Count 统计查询 | 7 | 7 | 46 | 10 |
| 关键词匹配查询 | 41 | 69 | 52 | 134 |
| 区间统计查询 | 994 | 1079 | 413 | 16 |
| 中间时间范围 | 49 | 56 | 56 | 32 |
| 最近时间范围 | 78 | 40 | 133 | 25 |
| 关键词匹配 + 区间查询 | 27 | 49 | 52 | 88 |
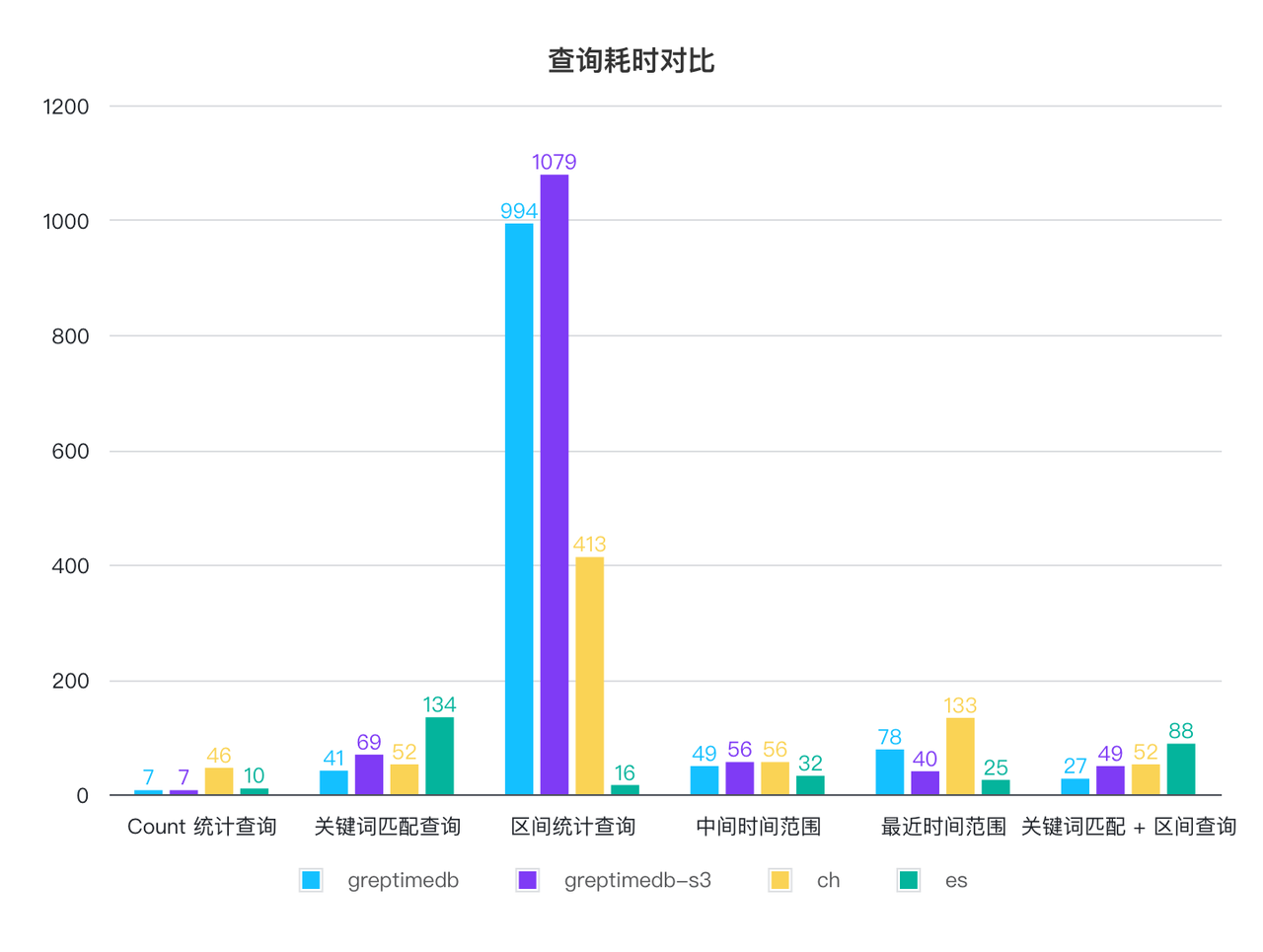
切分模式下,三者的查询性能大部分都很接近,都可以在 1 秒内完成查询,区间统计查询对于 GreptimeDB 和 ClickHouse 来说都需要扫表,比 ES 差的比较多,我们也在针对这一点做优化。GreptimeDB 在本地磁盘和 S3 模式下的查询性能基本一致。
全文模式查询性能
GreptimeDB 默认的全文索引配置是相对保守的,为了保持稳定的在线写入和查询性能,没有充分利用内存和 CPU。而 ClickHouse 和 ES 都会充分利用内存和索引,因此我们在这个模式下还提供了一个优化配置的结果,我们修改了 GreptimeDB 下列两个配置:
page_cache_size= "10GB",增大 SST 的 page cache 大小到 10GB;scan_parallelism= 8,扫描 SST 的并行数,默认为 CPU 数的四分之一,调整到 8 以使用所有的 CPU 核心;我们也提供了默认配置下的查询结果:
| 平均耗时 / 单位 ms | GreptimeDB | GreptimeDB on S3 | GreptimeDB 默认设置 | ClickHouse | ElasticSearch |
|---|---|---|---|---|---|
| Count 统计查询 | 8 | 7 | 8 | 43 | 9 |
| 关键词匹配查询 | 994 | 986 | 5596 | 2080 | 161 |
| 区间统计查询 | 1603 | 1101 | 1493 | 572 | 10 |
| 中间时间范围 | 1624 | 846 | 3694 | 51 | 26 |
| 最近时间范围 | 445 | 17 | 429 | 606 | 22 |
| 关键词匹配 + 区间查询 | 930 | 586 | 5373 | 1610 | 122 |
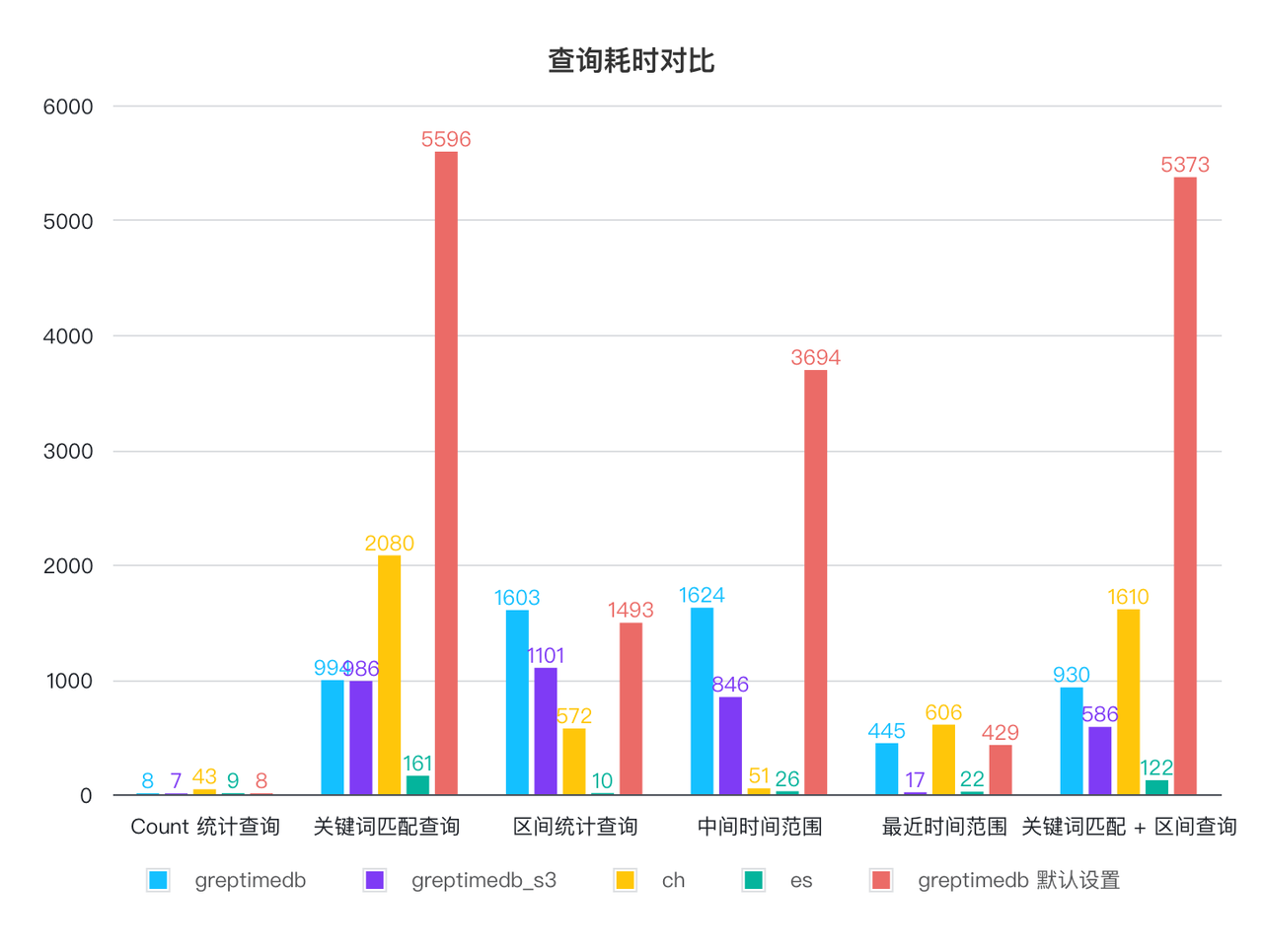
GreptimeDB 默认配置的查询性能除了最近时间范围查询以外都最差,在修改默认配置后,所有查询耗时都可以在 1.6 秒内完成,部分查询比 CH 更快,比如最常见的关键词匹配+时间区间范围查询。ES 的查询性能最优,较大的内存占用和更优化的索引实现带来来更好的查询性能, CH 表现较为均衡。
GreptimeDB 正在持续优化查询性能,未来预计默认配置将达到与 ClickHouse 相当的水平,敬请期待。
总结
通过测试,我们得出以下结论:
GreptimeDB 的日志引擎在写入性能、资源占用和压缩率方面表现出色,CH 较为平衡,而 ES 在这些方面表现最差且资源消耗高。
查询性能方面,切分模式下 GreptimeDB 与 CH 和 ES 相当。全文模式下,GreptimeDB 表现一般,但优化后可在 1.6 秒内完成大部分查询。ES 查询性能最佳,CH 较为均衡。
GreptimeDB 在本地磁盘和 S3 对象存储模式下性能基本一致。
切分模式(日志结构化)提升了读写性能和压缩率。GreptimeDB 和 ES 都具备 Ingestion Pipeline 功能,可将非结构化文本转换为结构化数据。
这个结果其实跟三者面向的场景紧密相关:
GreptimeDB 为面向在线的可观测应用而设计,比如智能运维和监控场景,尤其是海量数据,比如车联网或者大规模的监控系统,并且提供了数据直接保存在对象存储的能力。由于在线监控需要持续可用,因此 GreptimeDB 对于资源的使用会相对谨慎和控制,更希望提供稳定 7x24 读写服务,并具备良好的水平扩展能力。
ClickHouse 面向离线数仓服务设计,离线数仓很多是 ad hoc 查询或者长时间范围的数据分析,对查询耗时和失败率没有那么敏感,CH 更充分地利用 CPU 和内存等资源。
ElasticSearch 专为在线或离线检索业务而设计,具备良好的索引能力和完备的搜索功能(基于优秀的 Apache Lucence 项目),更加激进地使用资源,尤其是内存和磁盘占用,但是相对的,消耗的资源也是最大,写入性能也较差。
简而言之,在海量日志场景下, GreptimeDB 是一个性价比最高的选择,基于云原生架构,可以用更低的资源消耗(CPU、内存和磁盘)来承载大量日志的存储,并且具备优秀的水平扩展能力,但是作为首个版本实现,查询性能相对一般,还需要持续优化。ClickHouse 也是较为优秀的选择,只是 ClickHouse 仍然是传统的分布式架构设计,没有办法充分地利用云的基础设施,尤其是弹性和廉价对象存储。而 ES 则更适合面向在线的搜索业务,对于延时和结果排序更为敏感,日志场景不是合适的选择,资源消耗和写入性能都最差。最后,CH 和 ES 的分布式集群的运维部署都相当繁琐。
GreptimeDB 的日志引擎目前还是第一个版本,我们将持续优化,敬请关注!
附
详细的测试配置及步骤说明请参考 这里。
就在本周六下午,可观测专场技术沙龙来广州啦!广州的小伙伴千万不要错过哦~ 点击链接查看活动详情和报名,免费票数量有限,先到先得~ 其他地区的小伙伴也欢迎预约视频号(Greptime)直播,线下观看哦~
关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack

