
本页内容
什么是链路追踪
在日益复杂的微服务架构中,链路追踪(Traces) 作为可观测性的关键支柱之一,已逐渐成为开发者们排查故障和了解系统运行状况的第一入口。
最早系统阐述链路追踪工程实践可源于 Google 这篇讲述 Dapper 系统的论文,而这也给 Uber 的开发者们带来了灵感,进而诞生了 Jaeger 项目。发展至今,Jaeger 已是 CNCF 社区最重要的几个项目之一。
通过这些工程实践,我们可将链路追踪抽象总结为:
一条链路追踪代表的是一个横跨多个服务的分布式请求,请求中每一个操作步骤都被抽象描述为 Span,而 Span 是链路追踪中的原子单位,Span 中可添加各种元数据并用 Span ID 来进行唯一标识;
每条链路追踪都由多个具有因果关系的 Span 组成,形成一个完整的调用链路图,并用 Trace ID 进行唯一标识;
如下图所示(源于 Jaeger 官方文档):
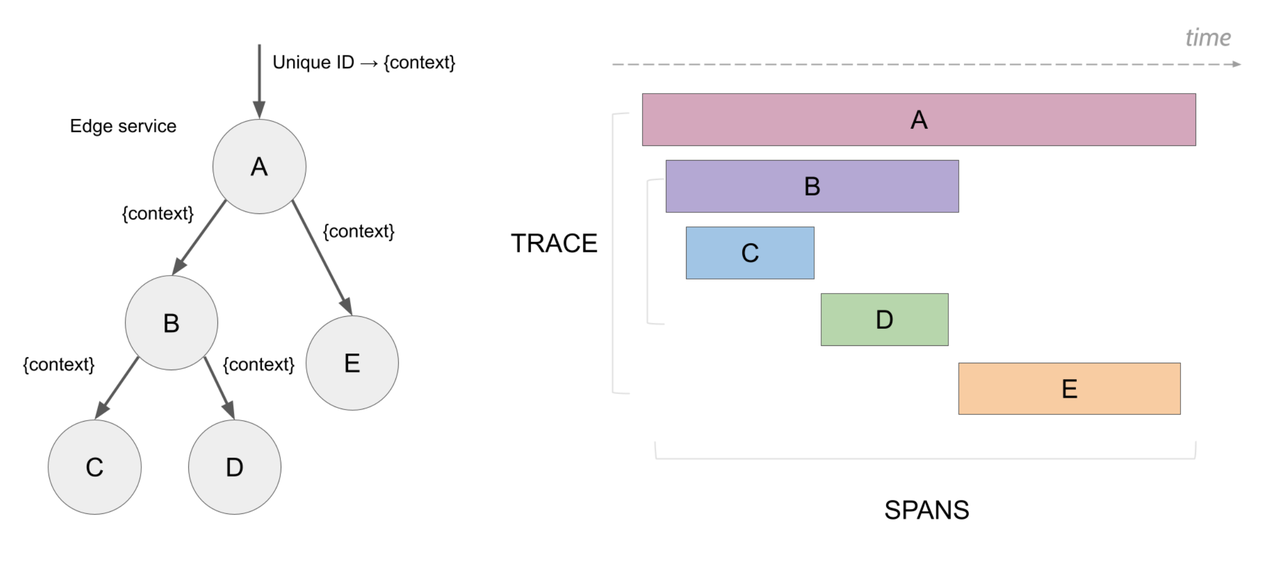
OpenTelemetry 社区最早聚焦于链路追踪构建出一套完整的数据模型,并逐渐成为当前社区的事实标准。OpenTelemetry Traces 的核心数据模型非常简单,比如我们可以基于其数据模型定义用 JSON 来描述一条完整的链路追踪:
json
{
"resourceSpans": [
{
"resource": {
"attributes": [
{
"key": "service.name",
"value": {
"stringValue": "my.service"
}
}
]
},
"scopeSpans": [
{
"scope": {
"name": "my.library",
"version": "1.0.0",
"attributes": [
{
"key": "my.scope.attribute",
"value": {
"stringValue": "some scope attribute"
}
}
]
},
"spans": [
{
"traceId": "5B8EFFF798038103D269B633813FC60C",
"spanId": "EEE19B7EC3C1B174",
"parentSpanId": "EEE19B7EC3C1B173",
"name": "I'm a server span",
"startTimeUnixNano": "1544712660000000000",
"endTimeUnixNano": "1544712661000000000",
"kind": 2,
"attributes": [
{
"key": "my.span.attr",
"value": {
"stringValue": "some value"
}
}
]
}
]
}
]
}
]
}通过上面的例子我们不难得出一个结论:链路追踪是特化后的结构化日志,而存储链路追踪本质上就是存储一系列 Span 数据。事实上,现在仍然有很多用户通过打印日志的方式来输出链路追踪。因此,一个支持日志存储的数据库基本也可以很容易支持链路追踪存储,二者并不存在明显的技术边界,不少用户也会使用 ClickHouse 和 Elasticsearch 同时存储链路追踪和日志数据。
GreptimeDB 在日志存储方面表现出色,在 JSONBench 基准测试中取得了优异成绩。如今,GreptimeDB 也在最新版中引入了实验性的存储 OpenTelemetry Traces 功能。本文将系统性地介绍 GreptimeDB 是如何实现这一能力的。
规模化存储和查询链路追踪面临的挑战
在与大量企业客户交流和沟通的过程中,我们发现规模化存储和查询链路追踪通常面临如下几大挑战:
海量数据写入:由于链路追踪记录的是每个服务的操作步骤,因此链路追踪的总数据量取决于其微服务的复杂度。在中大型规模公司内部,每天很有可能将生成数十亿到数百亿条甚至更多链路追踪数据,这也意味着后端数据库将面临每秒数百万甚至数千万 Span 数据实时写入;
实时查询:对于大多数场景而言,对链路追踪的查询时效性非常强,通常只会查询最近一段时间的数据,而更多的历史数据将被聚合转化成具有一定业务语义的指标。因此,后端数据库要支持很高的数据新鲜度,能让用户实时查询已写入的数据;
低成本长周期数据存储:由于链路追踪数据总量天然的大,因此存储这类数据就面临高昂的成本。为了降低写入压力和存储成本,大多数链路追踪系统通常会在 SDK 或采集端使用头采样或者尾采样的方式来降低链路追踪生成的总数据量。为了缩短存储周期,大多数链路追踪数据都有相对较短的 TTL,比如只保存 7 天甚至更短时间;
关联分析:大多数用户希望从一条链路追踪出发,看到一条请求完整的调用路径,并以 Trace ID 或其他关键语义属性作为关联键,跳转到相应的日志上下文,更进一步,能够将相关的指标也展示出来。这样一来我们可以很容易在多种不同类型的可观测数据间进行关联分析来定位问题;
高性能聚合计算:单条链路追踪数据只能反映某一条请求的上下文,而更多的链路追踪数据通常需要进行聚合计算才能生成更有价值的业务指标,这也是传统的 Traces To Metrics 的做法。比如,我们可以基于链路追踪数据生成常见的 RED 指标(Rate / Error / Duration)或者服务间拓扑关系,这样更能从海量数据中提取出更有价值的数据。
GreptimeDB 中如何存储和查询链路追踪
拥抱 OpenTelemetry
正如上文所提及,OpenTelemetry 已逐渐成为开放社区事实上的标准,而我们也积极地拥抱 OpenTelemetry,我们是一个 OpenTelemetry-Native 的可观测性数据库。
在链路追踪写入的场景中,GreptimeDB 支持原生的 OpenTelemetry HTTP 协议。事实上,GreptimeDB 可以很容易地作为 OpenTelemetry Traces Exporter 来直接写入链路追踪数据。例如,在一个使用 OpenTelemetry SDK 的业务容器时,你可以在服务启动时注入以下环境变量,就能很容易地将链路追踪数据直接写入到 GreptimeDB:
sql
OTEL_EXPORTER_OTLP_TRACES_ENDPOINT="http://cluster.greptime:4000/v1/otlp/v1/traces"
OTEL_EXPORTER_OTLP_TRACES_HEADERS="x-greptime-pipeline-name=greptime_trace_v1"对于所有写入的链路追踪数据,GreptimeDB 内部将生成一张基于 Trace ID 来分区的分布式表 opentelemetry_traces,这张表可作为链路追踪数据的明细表。默认地,我们会将这张表划分为 16 个 Region 进行存储,而每个 Region 将分摊不同的写入和查询压力。在企业版 GreptimeDB 中,系统可基于写入压力自动划分 Region,从而让链路追踪数据能更好地被多个节点(Frontend 和 Datanode)进行处理。
在原始的 OpenTelemetry Traces 模型中,有不少以 Map 形式存在的 Attributes 字段。对于这部分字段,GreptimeDB 会在写入的过程中自动将其拆分成单独的列来进行存储。这种处理方式不仅对数据压缩更友好,而且对数据查询也更友好(比如我们可以单独对某些关键的属性列增加索引)。更多存储细节可参考我们的开源文档。
对于链路追踪数据中的一些常用字段(比如 trace_id 和 service_name),GreptimeDB 将使用经典的跳数索引,这不仅可以满足绝大多数的链路追踪数据查询,也能降低索引代价。
存算分离下的弹性资源
GreptimeDB 采用存算分离架构,最终数据将存储于低成本的对象存储中,并利用 SSD 云盘作为 WAL 和 Cache 来保证数据写入可靠性和查询性能。整体架构可如下图所示:
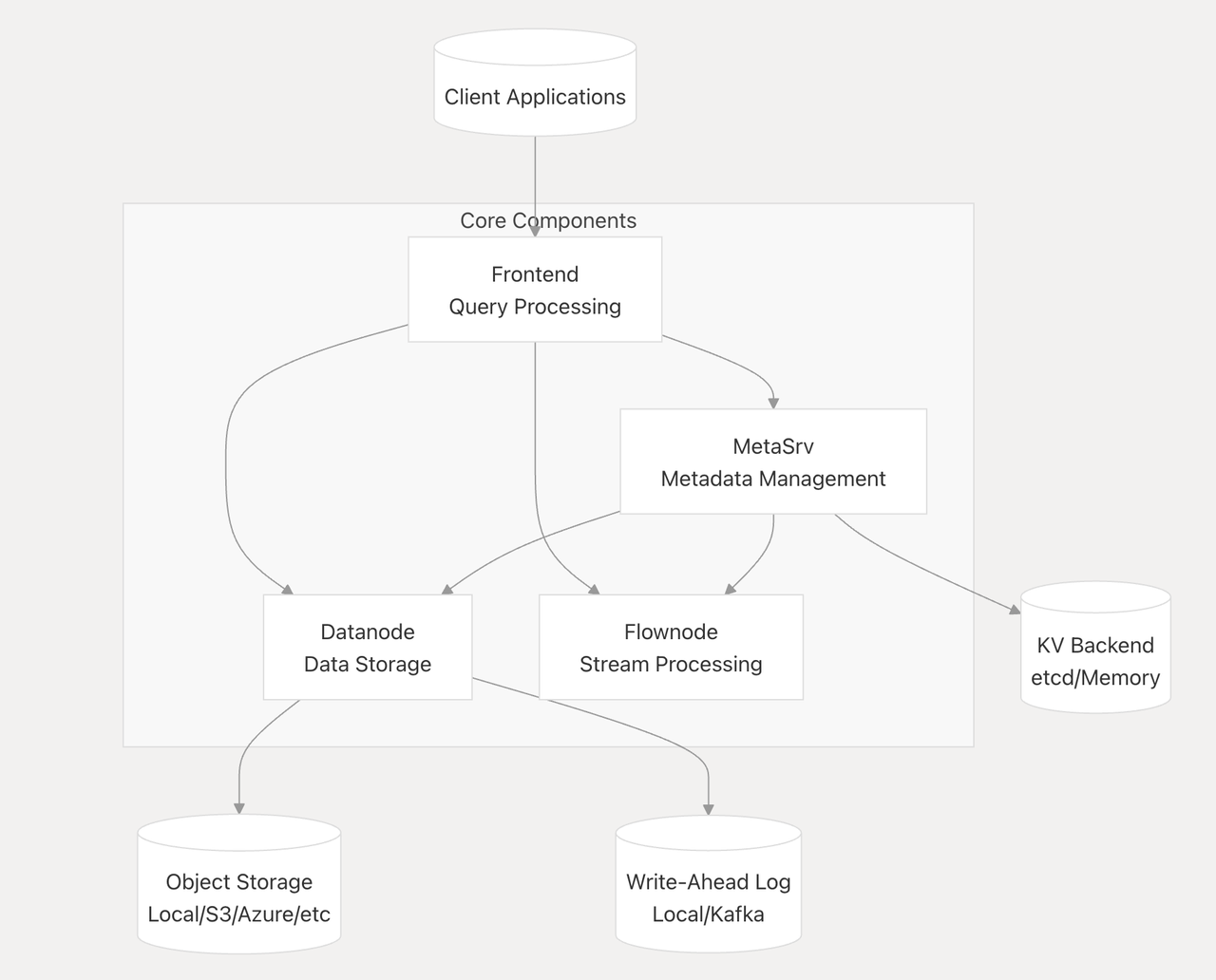
传统的存算一体的数据库(比如 Elasticsearch 和 ClickHouse)很难在保证读写性能的前提下具备较低的存储成本和较高的资源弹性。而 GreptimeDB 通过存算分离,实现了:
低成本的数据存储:所有链路追踪数据都将存储于廉价对象存储中,相较于传统云盘,这在大规模场景下可显著降低整体存储成本,成本优势可达数倍。我们可以 AWS S3 和 EBS 做一些粗略计算(具体金额以具体场景和区域为准):用户在 S3 存储 10 PB 数据每月约花费 21 万美金(使用标准存储),而同样的数据在 EBS(使用 gp3 类型)存储则需要高达 82 万美金。用户还可以进一步将历史的链路追踪数据随时间存入更冷的对象存储中,从而实现历史数据更长周期的保存,以备未来做数据审计或其他需求。
弹性的读写资源:通过解耦计算和存储,GreptimeDB 可根据链路追踪数据的读写规模实现计算资源的弹性扩展。考虑到链路追踪数据是典型的“写多读少”场景,企业版 GreptimeDB 还支持读写分离,用户可以按需扩展写入节点,并在确保高吞吐写入的同时实现资源隔离,即高吞吐的写入不影响查询性能。
内置轻量级流计算引擎进行聚合计算
在链路追踪数据计算场景中,聚合计算几乎是必不可少的环节,而基于流计算来从链路追踪数据进一步生成指标更是业界的主流做法。不同于用户需要去构建一套复杂的流计算系统,GreptimeDB 内置了一套轻量级流计算引擎来做数据的持续聚合。GreptimeDB 将流计算抽象出一个 Flownode 节点(可参考上文的架构图),与 Datanode 类似,Flownode 也可以基于负载来进行弹性伸缩。
用户只需要使用简单的 SQL 语句就可以基于上文的链路追踪数据表来创建实时的 Flow 任务,如下语句:
sql
CREATE FLOW IF NOT EXISTS `opentelemetry_traces_spans_red_metrics_1m_aggregation`
SINK TO `opentelemetry_traces_spans_red_metrics_1m`
COMMENT 'Calculate RED metrics for each span in 1 minute time window.'
AS
SELECT
`service_name`,
`span_name`,
`span_kind`,
count(*) as `total_count`,
sum(case when `span_status_code` = 'STATUS_CODE_ERROR' then 1 else 0 end) as `error_count`,
avg(`duration_nano`) as `avg_latency_nano`,
uddsketch_state(128, 0.01, "duration_nano") AS `latency_sketch`,
date_bin('1 minutes'::INTERVAL, `timestamp`, '2025-05-17 00:00:00') as `time_window`
FROM `opentelemetry_traces`
GROUP BY `service_name`, `span_name`, `span_kind`, `time_window`;我们创建了一个 opentelemetry_traces_spans_red_metrics_1m_aggregation 的 Flow 任务,并以 1 分钟作为时间窗口来持续计算 Span 的 RED 指标,并将这类指标统一写入另一张指标表 opentelemetry_traces_spans_red_metrics_1m。有趣的是,由于 GreptimeDB 支持 PromQL,用户其实也可以用 PromQL 的方式来查询这类表中的指标,进而与 Prometheus 生态进行融合。
除了 RED 指标,通过链路追踪数据来进行拓扑计算也是一个经典的需求。例如,在 Jaeger 生态中,有 spark-dependencies 项目运行 Spark Job 来计算链路追踪之间的调用关系。在 GreptimeDB 中,这一切将变得更加简单,我们只需创建一条简单的 Flow 任务:
sql
CREATE FLOW IF NOT EXISTS `opentelemetry_traces_dependencies_1h_aggregation`
SINK TO `opentelemetry_traces_dependencies_1h`
COMMENT 'Calculate dependencies between services in 1 hour time window.'
AS
SELECT
`parent`.`service_name` AS `parent_service`,
`child`.`service_name` AS `child_service`,
COUNT(*) AS `call_count`,
date_bin('1 hour'::INTERVAL, `parent`.`timestamp`, '2025-05-17 00:00:00') as `time_window`
FROM `opentelemetry_traces` AS `child`
JOIN `opentelemetry_traces` AS `parent` ON `child`.`parent_span_id` = `parent`.`span_id`
WHERE `parent`.`service_name` != `child`.`service_name`
GROUP BY `parent_service`, `child_service`, `time_window`;这样就能通过计算服务间的调用次数来绘制服务间的调用拓扑了。当然,我们未来也可以支持更复杂的拓扑计算。
可观测数据的统一存储
我们前文曾提及,链路追踪数据必须结合日志和指标进行关联分析才更有价值,而这样的需求在一个统一的可观测数据存储库中可通过 SQL 轻松实现。用户可以将日志和指标数据同时存储于 GreptimeDB,并在业务层通过各种关联属性进行绑定(比如 Trace ID 和 Service Name 等),这样一来:
- 更简单数据关联分析:上层用户或系统可通过一条以 Trace ID 等其他关联属性键作为查询条件的简单 SQL,便可获取完整的请求上下文,比如我们可以在这样一条 SQL 在同一个数据系统内部实现链路追踪、日志和指标的联合查询:
sql
SELECT
t.trace_id,
t.span_id,
t.span_name,
t.duration_nano,
t.status,
t.service_name,
l.timestamp,
l.level,
l.message,
m.cpu,
m.memory
FROM
traces t
JOIN
logs l ON t.trace_id = l.trace_id
JOIN
metrics m ON t.service_name = m.service_name
WHERE
t.trace_id = '4d6c62efe6be73c9c9f86e54b9b527e4'
ORDERBY
l.timestamp;我们可以很容易看出,当这条对应链路追踪发生的时候,对应组件的日志上下文是什么,当前的 CPU 和 Memory 负载位于什么状态。
- 更简洁且更高性能的数据查询:由于所有可观测数据统一存储在同一个数据库中,因此数据的查询性能变得更好,数据治理成本也变得更低,整体架构也会更加简洁。
支持 SQL 查询和 Jaeger API
由于 GreptimeDB 原生支持 SQL,因此用户无需太多的学习成本就可通过 SQL 对链路追踪数据进行常见的查询。
不仅如此,由于 Jaeger 是目前最为广泛使用的分布式链路追踪系统,为了能更好地兼容其生态,GreptimeDB 基本实现了 Jaeger 的大部分查询 API。事实上,由于 Jaeger 并没有独立的查询 DSL,因此兼容 Jaeger 查询接口对 GreptimeDB 来说其实并不是一件很复杂的事情,本质上是将 Jaeger 接口的查询映射成等价的 SQL 语句。
正因为我们支持 Jaeger API,用户还可以很容易地使用 Grafana 的 Jager 插件和原生的 Jaeger UI 来进行数据查询和渲染。
Grafana 插件支持
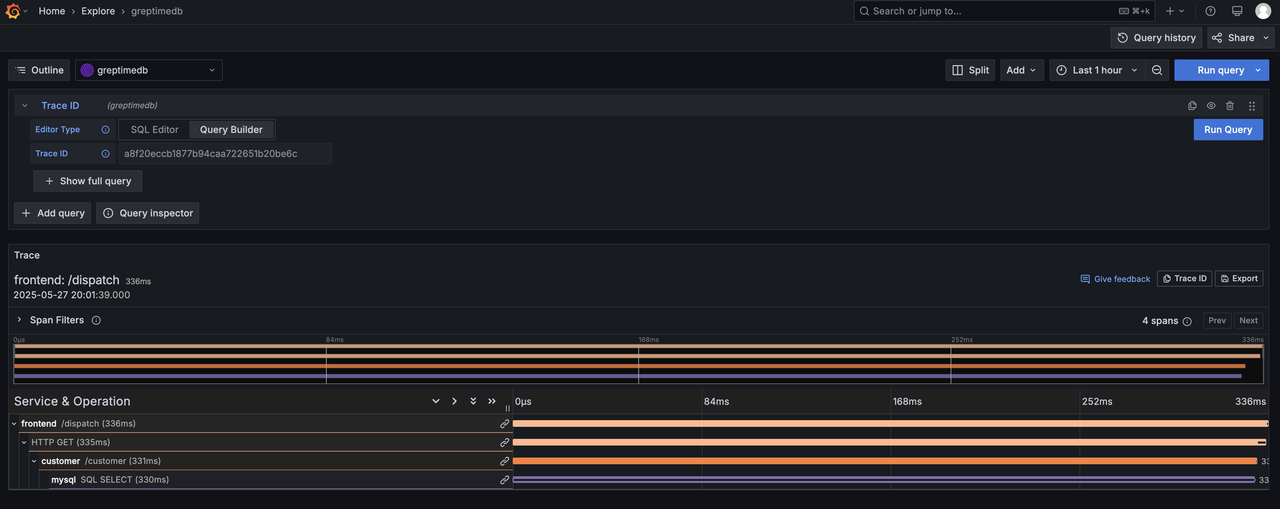
为了丰富 Grafana 生态,我们开源了 GreptimeDB Data Source 插件。用户在使用我们数据插件时(可参考使用文档),不仅可以实现渲染链路追踪数据,也可通过配置跳转规则从 Trace ID 跳转到相应的日志上下文,如下所示:
未来计划
GreptimeDB 对于链路追踪功能的支持目前仍在高速迭代中,我们的目标是:以极高的性能和易用性来满足不同规模的用户需求。未来我们将进一步迭代存储和查询链路追踪数据的功能:
更卓越的数据写入性能:我们正研发更高吞吐的实时写入功能,可进一步支持更大规模的链路追踪数据写入,满足更大规模公司对海量链路追踪数据实时写入的需求;
内置常用 Flow 任务以及在 SQL 生态中实现更多链路追踪查询相关函数:为了降低用户的使用成本,我们会在 OpenTelemetry Traces 的基础上内置一些常用的 Flow 任务(比如经典的 RED 指标计算),进而做到“开箱即用”。不仅如此,为了更好地满足用户使用 SQL 查询链路追踪数据的需求,我们未来也会推出一些 SQL 函数和简化语法,让用户更容易地进行链路追踪数据查询;
TraceBench 项目:不同于日志,链路追踪领域一直缺少相应的 Benchmark 标准和测试集。我们将在 JSONBench 的基础上,提炼出针对分布式链路追踪测试集并推出 TraceBench,来帮助社区用户更好地进行技术选型。

