
本页内容
我们很高兴地宣布:GreptimeDB v0.15 正式发布!本次 v0.15 版本更新重点关注系统灵活性、性能优化和可观测性提升,在数据处理、Pipeline 管理和运维能力方面都有显著提升。
版本开发概览
从 v0.14 到 v0.15,Greptime 团队和社区贡献者们共同取得了令人瞩目的进展:
开发数据统计:
- 253 个提交成功合并;
- 927 个文件被修改;
- 35 位独立贡献者参与;
- 6 位独立贡献者首次贡献代码。
主要改进分布:
- 50+ 项功能增强:包括进程管理系统、Pipeline 集成等核心特性;
- 30+ 项错误修复:持续提升系统稳定性;
- 10+ 项代码重构:优化代码架构和可维护性;
- 4 项 Breaking 变更:为未来发展奠定基础;
- 2 项性能优化:包括 SimpleBulkMemtable 和批量操作优化;
- 大量测试工作:确保功能的可靠性。
👏 特别感谢 26 位独立贡献者的辛勤付出,以及 6 位新加入的社区成员!我们欢迎更多对可观测性数据库技术感兴趣的朋友加入 Greptime 社区。
核心功能亮点
Pipeline 集成相关
本次更新大幅增强了 Pipeline 的数据处理能力👇
Pipeline 新增协议集成
- Prometheus Remote Write
- Loki 写入协议
这两个协议通过 HTTP header 的 x-greptime-pipeline-name 参数指定转换使用的 Pipeline,为用户带来了更丰富、灵活的数据处理能力,例如替换 Prometheus 指标 Label、日志结构化处理等。
引入 Vector Remap Language (VRL) 处理器
VRL 处理器为高级数据转换场景提供了强大的编程能力。与简单处理器相比,VRL 允许用户编写灵活的脚本来操作上下文变量,实现复杂的数据处理逻辑。
注意:
VRL是 Vector 引入的数据转换表达式语言,详细介绍请参考官方文档。VRL脚本执行会消耗更多资源,请根据实际场景权衡使用。关于VRL的介绍,也可以参考这篇文章:《可观测场景如何使用 Vector Remap 优化日志数据的解析与存储》。
VRL 处理器目前只有一个配置项,就是 source(源码)。示例如下:
yaml
processors:
- date:
field: time
formats:
- "%Y-%m-%d %H:%M:%S%.3f"
ignore_missing: true
- vrl:
source: |
.from_source = "channel_2"
cond, err = .id1 > .id2
if (cond) {
.from_source = "channel_1"
}
del(.id1)
del(.id2)
.该配置使用 | 在 YAML 中开启一个多行文本,随后即可编写整个脚本。
VRL 处理器使用要点:
- 脚本结尾:必须以单独的
.行结束,表示返回整个上下文; - 类型限制:返回值中不能包含
regex类型变量(可在过程中使用,但需在返回前删除del); - 类型转换:经过
VRL处理的数据类型会转换为最大容量类型(i64、u64和Timestamp::nanoseconds)。
更详细的使用教程,请关注近期的公众号文章更新。
Bulk Ingestion:支持高吞吐写入
针对高吞吐、延时容忍的场景,我们引入了 Bulk Ingestion 功能。这并非替代现有写入协议,而是在特定场景下的有效补充。
适用场景对比:
| 写入方法 | API | 吞吐 | 延迟 | 内存效率 | CPU利用率 | 适用场景 | 局限性 |
|---|---|---|---|---|---|---|---|
| Regular Write | Write(tables) | 高 | 低 | 中 | 高 | 简单应用,低延迟要求:如物联网传感器数据以及一些用户希望及时响应的场景 | 大批量时吞吐量较低 |
| Stream Write | StreamWriter() | 中 | 低 | 中 | 中 | 连续数据流,中等吞吐量,可以多个表的写入共享一个流 | 比普通写入使用上更复杂 |
| Bulk Write | BulkStreamWriter() | 最高 | 稍高 | 高效 | 中 | 最大吞吐量,大批量操作;如 ETL Pipelines,日志摄入,数据迁移等 | 更高的延迟,需要客户端批量攒数据,一个表绑定一个流,多个表无法共享一个写入流 |
客户端支持:
更多的使用教程,请关注近期公众号的文章更新。
运维能力增强
查询任务视图管理
新增查询任务视图管理功能,让用户能够实时监控和管理集群中的查询任务。包括查看 GreptimeDB 集群中所有正在运行的查询的视图,同时可以提前终止一个查询。
查询任务视图示例
sql
USE INFORMATION_SCHEMA;
DESC PROCESS_LIST;yaml
+-----------------+----------------------+------+------+---------+---------------+
| Column | Type | Key | Null | Default | Semantic Type |
+-----------------+----------------------+------+------+---------+---------------+
| id | String | | NO | | FIELD |
| catalog | String | | NO | | FIELD |
| schemas | String | | NO | | FIELD |
| query | String | | NO | | FIELD |
| client | String | | NO | | FIELD |
| frontend | String | | NO | | FIELD |
| start_timestamp | TimestampMillisecond | | NO | | FIELD |
| elapsed_time | DurationMillisecond | | NO | | FIELD |
+-----------------+----------------------+------+------+---------+---------------+终止查询操作
当 PROCESS_LIST 表识别到正在运行的查询时,用户可以使用 KILL <PROCESS_ID> 语句终止该查询,其中 <PROCESS_ID> 是 PROCESS_LIST 表中的 id 字段:
sql
mysql> select * from process_list;
+-----------------------+----------+--------------------+----------------------------+------------------------+---------------------+----------------------------+-----------------+
| id | catalog | schemas | query | client | frontend | start_timestamp | elapsed_time |
+-----------------------+----------+--------------------+----------------------------+------------------------+---------------------+----------------------------+-----------------+
| 112.40.36.208/7 | greptime | public | SELECT * FROM some_very_large_table | mysql[127.0.0.1:34692] | 112.40.36.208:4001 | 2025-06-30 07:04:11.118000 | 00:00:12.002000 |
+-----------------------+----------+--------------------+----------------------------+------------------------+---------------------+----------------------------+-----------------+
KILL '112.40.36.208/7';
Query OK, 1 row affected (0.00 sec)Dashboard 功能扩展
Dashboard 新增特性👇
- Traces 视图支持:增强可观测性体验。
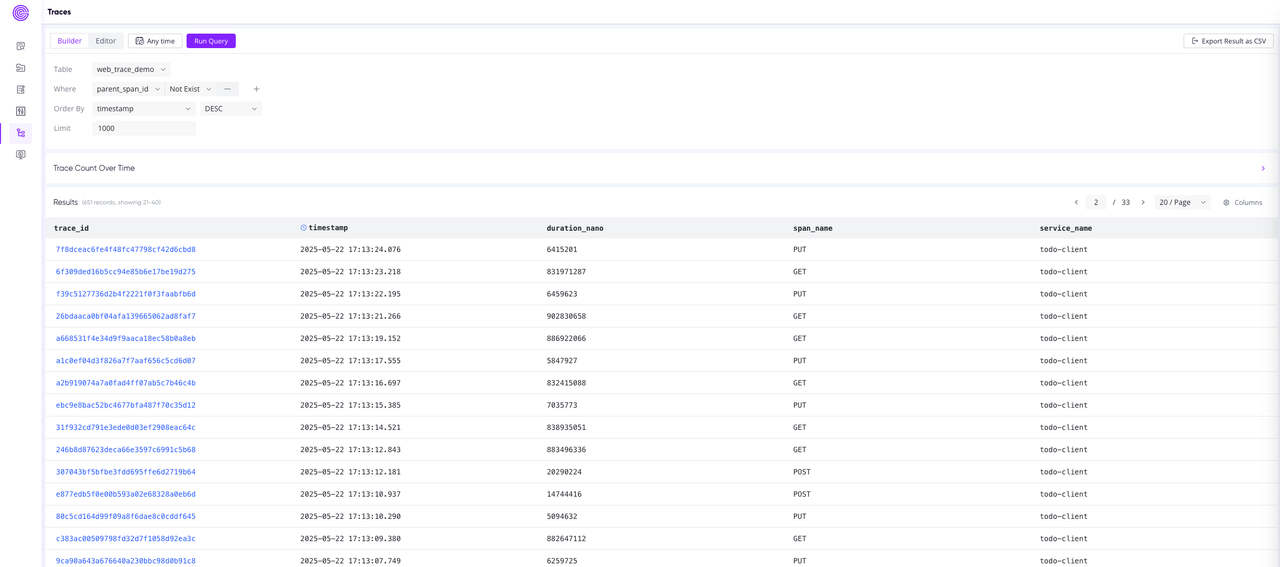
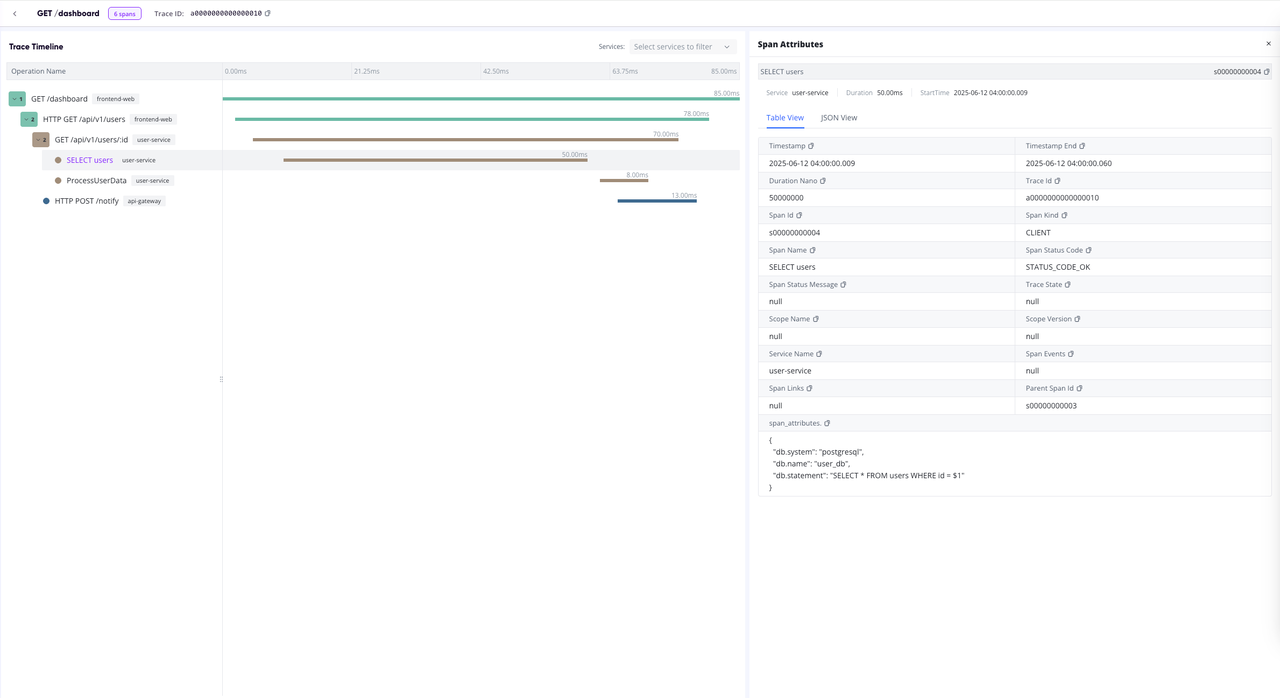
- 数据摄入面板新增日志写入能力:支持通过 Pipeline 写入日志,简化日志数据的接入与处理流程。
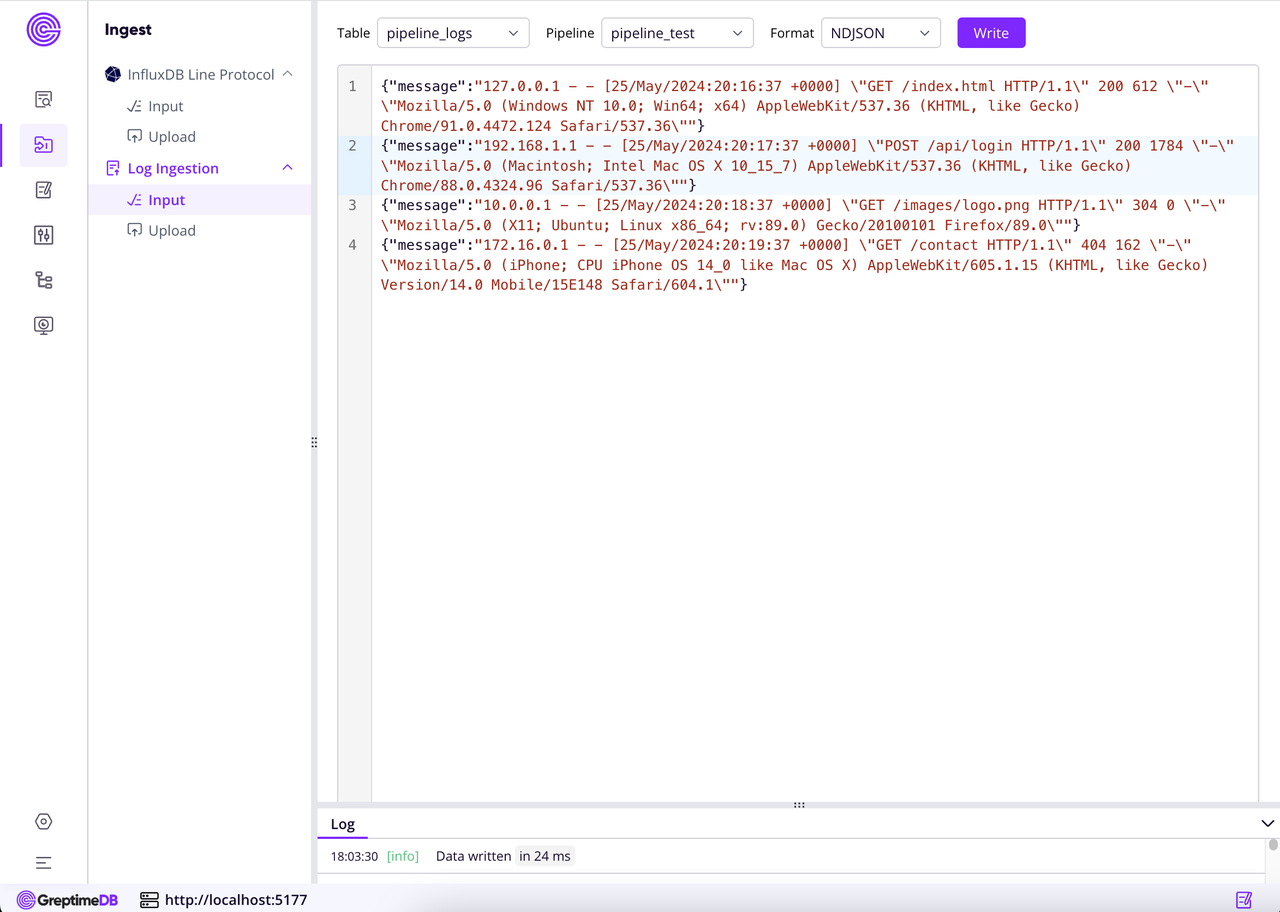
详细使用教程将于近期在 GreptimeDB 公众号上发布。
升级提示
兼容性说明
- v0.15 与 v0.14 数据和配置完全兼容
- 建议 v0.14 用户直接升级
升级操作
- 详细升级步骤请参考升级指南
- 更低版本升级请参考官方文档对应版本的升级文档。
未来规划与展望
v0.15 发布后,我们将专注于:
- 现有功能打磨:优化用户体验;
- 性能优化:提升系统效率;
- 可靠性和稳定性完善:构建企业级产品标准。
这些工作将为 GreptimeDB v1.0 的发布奠定坚实基础。再次感谢 Greptime 团队和所有社区贡献者的辛勤努力!我们期待更多开发者加入 GreptimeDB 社区,共同推动可观测性数据库技术的发展。

