
本页内容
在日常的数据库运维工作中,DBA 最头疼的问题之一就是遇到慢查询甚至死循环查询。这些异常查询不仅会消耗大量的系统资源,也会影响其他查询的正常执行。GreptimeDB v0.15 针对这一痛点,引入了完备的查询管理功能,尤其是慢查询的自动和手动终止机制,进一步提升了数据库的可用性和运维效率。
快速开始
在深入了解查询管理功能之前,我们假设你已经按照官方文档完成了 GreptimeDB 的安装。
最简单的方式是使用 Docker 快速启动:
bash
docker run -p 127.0.0.1:4000-4003:4000-4003 \
-v "$(pwd)/greptimedb:/greptimedb_data" \
--name greptime --rm \
greptime/greptimedb:v0.15.1 standalone start \
--http-addr 0.0.0.0:4000 \
--rpc-bind-addr 0.0.0.0:4001 \
--mysql-addr 0.0.0.0:4002 \
--postgres-addr 0.0.0.0:4003实时查询监控:正在运行的所有查询
GreptimeDB v0.15 新增的 INFORMATION_SCHEMA.PROCESS_LIST 表为运维人员提供了实时查询监控能力,能够全面展示当前所有正在执行的查询状态。
sql
USE INFORMATION_SCHEMA;
DESC PROCESS_LIST;系统表结构如下:
plaintext
+-----------------+----------------------+------+------+---------+---------------+
| Column | Type | Key | Null | Default | Semantic Type |
+-----------------+----------------------+------+------+---------+---------------+
| id | String | | NO | | FIELD |
| catalog | String | | NO | | FIELD |
| schemas | String | | NO | | FIELD |
| query | String | | NO | | FIELD |
| client | String | | NO | | FIELD |
| frontend | String | | NO | | FIELD |
| start_timestamp | TimestampMillisecond | | NO | | FIELD |
| elapsed_time | DurationMillisecond | | NO | | FIELD |
+-----------------+----------------------+------+------+---------+---------------+关键字段解析
这张表中我们需要关注下面几个字段:
id:查询的唯一标识符,可用于下文描述的KILL命令来终止查询;schemas:客户端发起查询时所在的数据库;query:具体的 SQL 语句,便于问题定位和后续的查询优化;client:客户端连接信息,包括地址和协议类型。通常情况下,用户不仅想知道执行的慢查询来自哪里,也希望知道使用的协议类型;start_timestamp和elapsed_time:分别表示查询开始的 unix 时间戳和耗时时长。
实例回顾:处理死循环查询
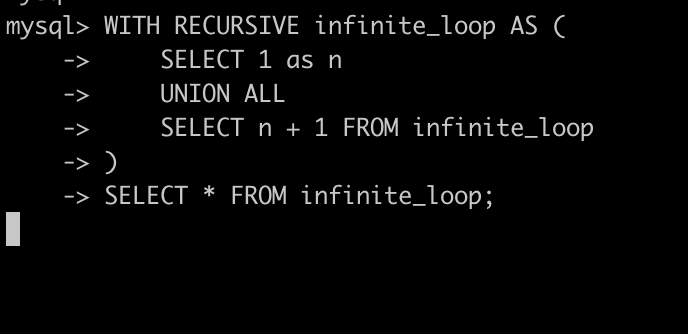
通过一个典型的 CTE 递归查询案例来演示查询管理功能:
sql
WITH RECURSIVE infinite_loop AS (
SELECT 1 as n
UNION ALL
SELECT n + 1 FROM infinite_loop -- 递归调用
)
SELECT * FROM infinite_loop;这样会陷入无限循环。
Step 1:执行问题查询
打开一个终端,通过 MySQL 命令连接到 GreptimeDB(如 mysql -h 127.0.0.1 -P 4002)并执行上面的 SQL,整个查询将 hang 住。
Step 2:监控查询状态
在第二个终端中,查看当前所有运行中的查询:
sql
SELECT * FROM INFORMATION_SCHEMA.PROCESS_LIST\G;输出示例:
yaml
*************************** 1. row ***************************
id: 172.17.0.2:4001/0
catalog: greptime
schemas: public
query: SELECT * FROM INFORMATION_SCHEMA.PROCESS_LIST
client: mysql[172.17.0.1:57814]
frontend: 172.17.0.2:4001
start_timestamp: 2025-07-07 10:58:15.673000
elapsed_time: 00:00:00.001000
*************************** 2. row ***************************
id: 172.17.0.2:4001/1
catalog: greptime
schemas: public
query: WITH RECURSIVE infinite_loop AS (SELECT 1 AS n UNION ALL SELECT n + 1 FROM infinite_loop) SELECT * FROM infinite_loop
client: mysql[172.17.0.1:63122]
frontend: 172.17.0.2:4001
start_timestamp: 2025-07-07 10:57:41.443000
elapsed_time: 00:00:34.231000
2 rows in set (0.00 sec)结果返回了两条查询记录,除了
SELECT * FROM INFORMATION_SCHEMA.PROCESS_LIST这条查询外,另一条是另一个终端执行 hang 起的查询。
从结果可以看出,ID 为 172.17.0.2:4001/1 的查询已经运行了 34 秒,正是我们的问题查询。
在实际生产环境中,开发者经常会遇到各种查询问题:未能有效利用索引的低效查询,逻辑错误的死循环查询,或者因数据库 Bug 导致的查询阻塞等问题。由于数据库资源有限,这些问题会严重影响系统的整体性能,及时终止异常查询的能力对于数据库来说至关重要。
GreptimeDB 0.15 正是针对这一需求,引入了多种慢查询终止机制。
多种慢查询终止机制
CTRL + C 查询终止
GreptimeDB v0.15 改进了对 MySQL 客户端的支持,现在可以通过 Ctrl+C 组合键直接终止当前执行的查询,对于开发和测试环境中的即时响应非常有用:
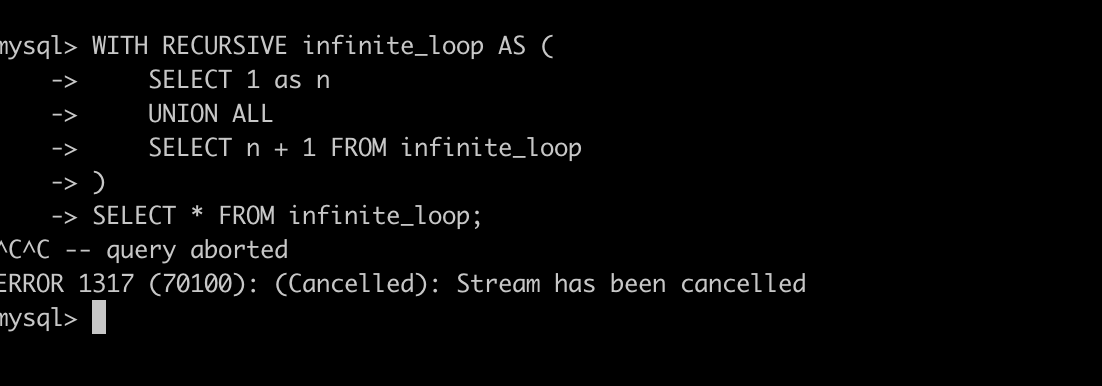
注:PostgreSQL psql 客户端的支持正在开发中。
查询超时控制
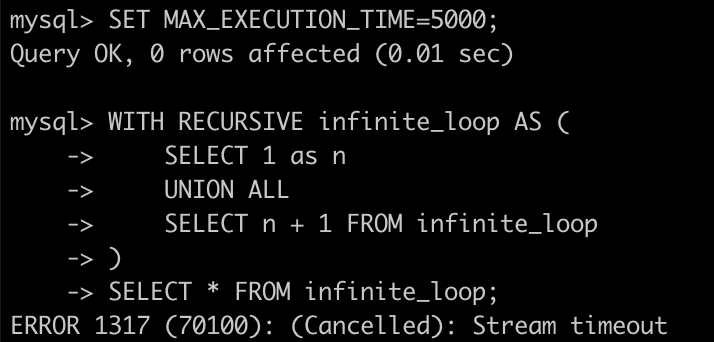
v0.15 通过设置 MAX_EXECUTION_TIME 变量,可以实现自动查询超时机制,在 MySQL 终端里执行:
sql
SET MAX_EXECUTION_TIME=5000;注:
MAX_EXECUTION_TIME的单位是毫秒,通过SET语句将当前 Session 的查询超时设置为 5 秒。
再次执行 CTE 查询时,系统会在 5 秒后自动终止查询并返回超时错误。
在应用程序中,可以通过连接字符串参数设置超时:如 Java JDBC 或者 Golang MySQL Driver 设置,只需要在数据库的连接字符串加上额外参数 MAX_EXECUTION_TIME=5000 即可,以 JDBC 为例:
sql
jdbc:mysql://127.0.0.1:4002?connectionTimeZone=Asia/Shanghai&forceConnectionTimeZoneToSession=true&MAX_EXECUTION_TIME=5000手动终止特定查询
通过 KILL {query id} 语句精确地终止特定查询。KILL 接受查询 PROCESS_LIST 返回的 ID,并终止对应查询。如下所示:
sql
*************************** 2. row ***************************
id: 172.17.0.2:4001/1
catalog: greptime
schemas: public
query: WITH RECURSIVE infinite_loop AS (SELECT 1 AS n UNION ALL SELECT n + 1 FROM infinite_loop) SELECT * FROM infinite_loop
client: mysql[172.17.0.1:63122]
frontend: 172.17.0.2:4001
start_timestamp: 2025-07-07 11:15:14.779000
elapsed_time: 00:00:03.075000执行 KILL 语句即可终止该查询:
sql
KILL '172.17.0.2:4001/1';这种方式特别适用于生产环境中需要立即终止特定慢查询的场景。
小结
GreptimeDB v0.15 通过引入 INFORMATION_SCHEMA.PROCESS_LIST 系统表,KILL 语句以及 MAX_EXECUTION_TIME 参数等新功能,实现了全面支持查询信息查看、自动终止和手动终止等关键能力。
作为专业的可观测性数据库,GreptimeDB 在查询管理方面的持续改进体现了我们对用户体验和系统稳定性的重视。我们期待您的试用体验,并欢迎通过官方渠道分享您的反馈和建议。

