
本页内容
p.s. 本篇文章来自 GreptimeDB 用户 xtang 的投稿,分享了如何利用 GreptimeDB 强大的 OpenTelemetry(OTLP)原生支持和 Dashboard as Code 能力,采集并可视化 Claude Code 的各项使用数据,实现数据驱动的自我编程效率提升和成本控制。
👏 欢迎各位开源用户积极分享自己的使用案例,一起分享,共同成长。
省流版:GreptimeDB 支持 OTLP 和 Perses。Claude Code 支持 OpenTelemetry 指标发送。那就用 GreptimeDB 来监控一下 Claude Code 的工作效率吧。
最近为了不被时代淘汰,高价订阅了 Claude Code Max 版本,不管是不是心理作用,效果的确比 $20 的 Cursor 好用。但毕竟一个月 100 刀,我还是想知道一下他到底提供了多少帮助?以及一个很现实的问题,如果按 API 计费,花费了多少钱,是不是比订阅更合适?
其实,有一个很棒的命令行工具 ccusage,可以快速提供使用情况的概览,非常适合进行快速检查,刚订阅那几天,Claude Code 牛马一会,我就去看看 ccusage,看看我用的效率怎么用,我特别喜欢 Cost 那列,因为我是订阅制,而如果按 API 计费,花费的钱已经远远超过了每个月的订阅费,一下子让我觉得自己反而赚到了,相信用过的朋友都能懂。 随后发现 Claude Code 居然支持 OTLP,这个好啊,就不用一直去敲指令了,弄个仪表盘多好,于是周末就花了点时间折腾。
数据库选择:为什么是 GreptimeDB?
首先,需要选择一个数据库来存储这些宝贵的遥测数据。脑子里第一个选择就是:GreptimeDB。利益相关,毕竟是之前的老东家,而且从第一性原来出发,它也完全符合这个项目的需求:
- 云端与本地随意选择:
GreptimeDB同时提供 Serverless 云版本和开源的本地版本。这是一个巨大的优势。我可以使用GreptimeDB Cloud快速开始进行初步测试和原型设计。如果未来我更关注数据隐私或需要更精细的控制,可以轻松迁移到自托管的实例上; - OpenTelemetry 完美支持:
GreptimeDB与OpenTelemetry的集成非常顺畅,填几个参数就完事了。可以看官方文档 OTLP 文档; - 通过 Perses 实现“仪表盘即代码”:
GreptimeDB使用Perses作为其仪表盘解决方案。无需在图形界面中繁琐地点击来构建和调整图表,而是可以在一个YAML文件中定义整个仪表盘。这使其易于进行版本控制、复用和分享。最主要的是,可以让 Claude Code 来写仪表盘; - 几乎免费:
GreptimeDB单机版开源的,可以自己部署;Cloud 版本的 Free 档对于收集 CC 这种个人项目来讲,也完全够用。
关注的指标
选定数据库后,初步定了几个指标来跟踪:
- 近期成本: 最近一天、一周或一个月的花费是多少?订阅制其实费用是固定的,从这能看出来实际“赚”了多少,也是我使劲用 CC 的动力之一;
- 近期 Token 使用量: 这是衡量我整体互动量的一个很好的指标。我特别想了解输入和输出 Token 之间的分布;
- 近期代码行数:
Claude帮助我生成或修改了多少行代码?这可以作为生产力的直接度量; - 活跃会话数: 一个简单的指标,用于观察我在一段时间内发起的独立编码会话数量;
- 指标细分: 我希望对数据进行多维度分析以获得更深入的洞察。Claude Code 官方监控文档列出了一些非常有价值的属性。我尤其对按
model(模型)、action(操作,如write、edit)和token_type进行的细分感兴趣。
部署流程:出乎意料的简单
收集数据的配置过程基本上没花时间,非常直白。
1. 数据收集器:GreptimeDB Cloud
如前所述,从 GreptimeDB Cloud 开始以接收数据流。整个设置过程非常轻松。只需创建一个新服务,系统便会提供 OTLP 端点和必要的凭据。
2. 配置 Claude Code
接下来,需要配置 Claude Code 将其遥测数据发送到指定位置。根据官方指南,这只需在 Claude Code 的配置文件(例如 ~/.claude/settings.json)中添加几个变量即可:
bash
"CLAUDE_CODE_ENABLE_TELEMETRY": "1",
"OTEL_METRICS_EXPORTER": "otlp",
"OTEL_LOGS_EXPORTER": "otlp",
"OTEL_EXPORTER_OTLP_PROTOCOL": "http/protobuf",
"OTEL_EXPORTER_OTLP_ENDPOINT": "<your-greptimedb-otlp-endpoint>",
"OTEL_EXPORTER_OTLP_HEADERS": "Authorization=Basic <your-base64-encoded-credentials>"
"OTEL_METRIC_EXPORT_INTERVAL": "10000",
"OTEL_LOGS_EXPORT_INTERVAL": "5000"仅此而已。Claude Code 随即开始向 GreptimeDB 实例发送指标。
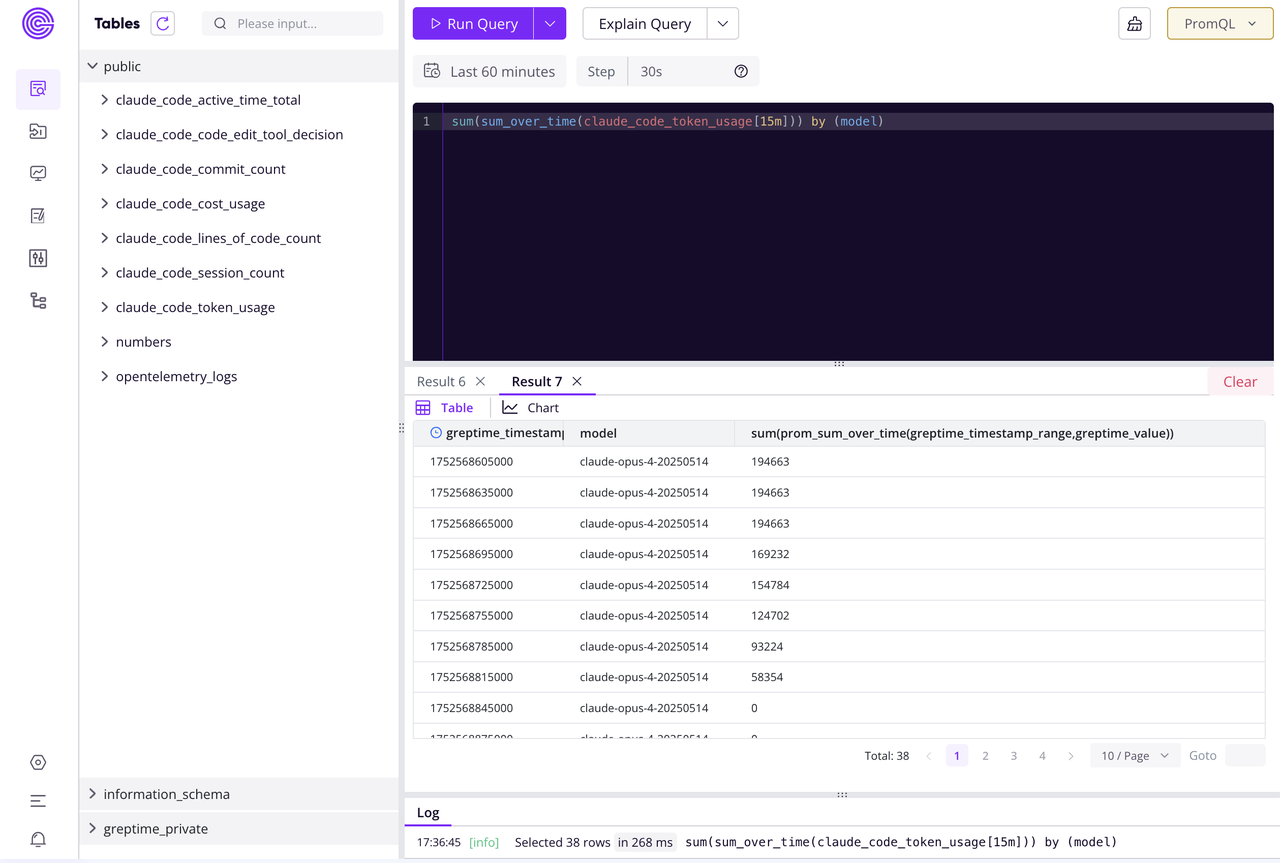
3. 构建仪表盘:一点小小的帮助
现在是有趣的部分:数据可视化。由于 GreptimeDB 使用 Perses,可以通过 JSON 文件进行配置。为了快速起步,我做了一件有点“元(meta)”的事情:我请求 Claude Code 为我想要追踪的指标生成一个基础的 Perses 仪表盘配置。生成的配置虽然不是 one-shot, 但基本提供了一个非常好用的起点,节省了大量时间。
不过,过程中也遇到了一个小问题。Claude Code 的指标名称中包含 "Count",例如 claude.code.lines_of_code.count。Claude Code 很自然地认为这些是 Counter(计数器)类型的指标。在 Prometheus 查询语言(PromQL)中,通常会使用 increase() 函数来计算计数器的增长率。
但关键在于:Claude Code 发送的指标实际上是增量(deltas),而非绝对递增的计数器。所以要用 sum_over_time() 这样的函数来正确地聚合这些增量值,而不是 increase()。
因此,一个最初可能错误的 Token 使用量查询:
promql
# 错误用法
increase(claude_code_lines_of_code_count[${__rate_interval}])需要被调整为:
promql
# 正确的增量求和方法
sum_over_time(claude_code_lines_of_code_count[${__rate_interval}])其实修改这个配置花了点时间,经过进一步的调整和优化 PromQL 查询后,得到了一个可用的仪表盘。
最终成果
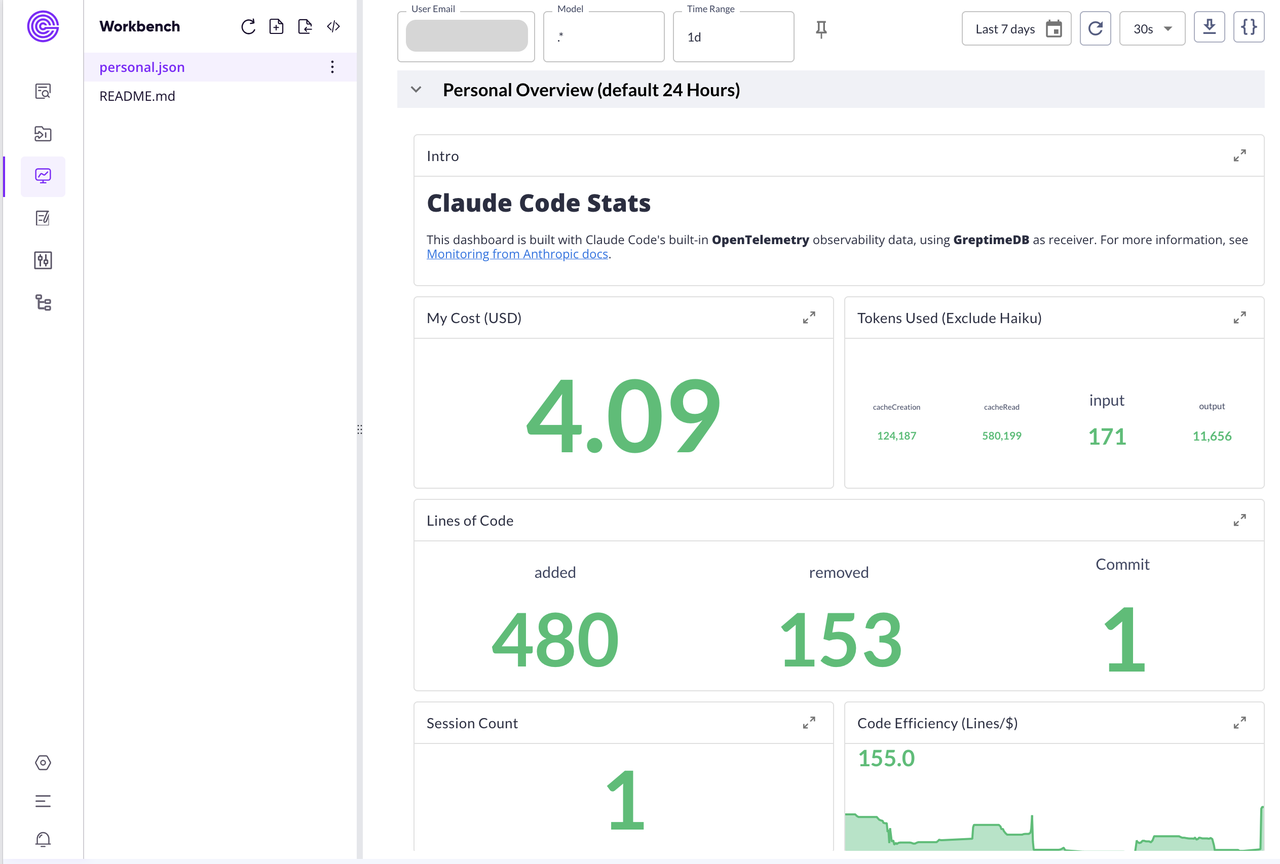
经过一番折腾,这就是我现在每天都要瞄几眼的仪表板。
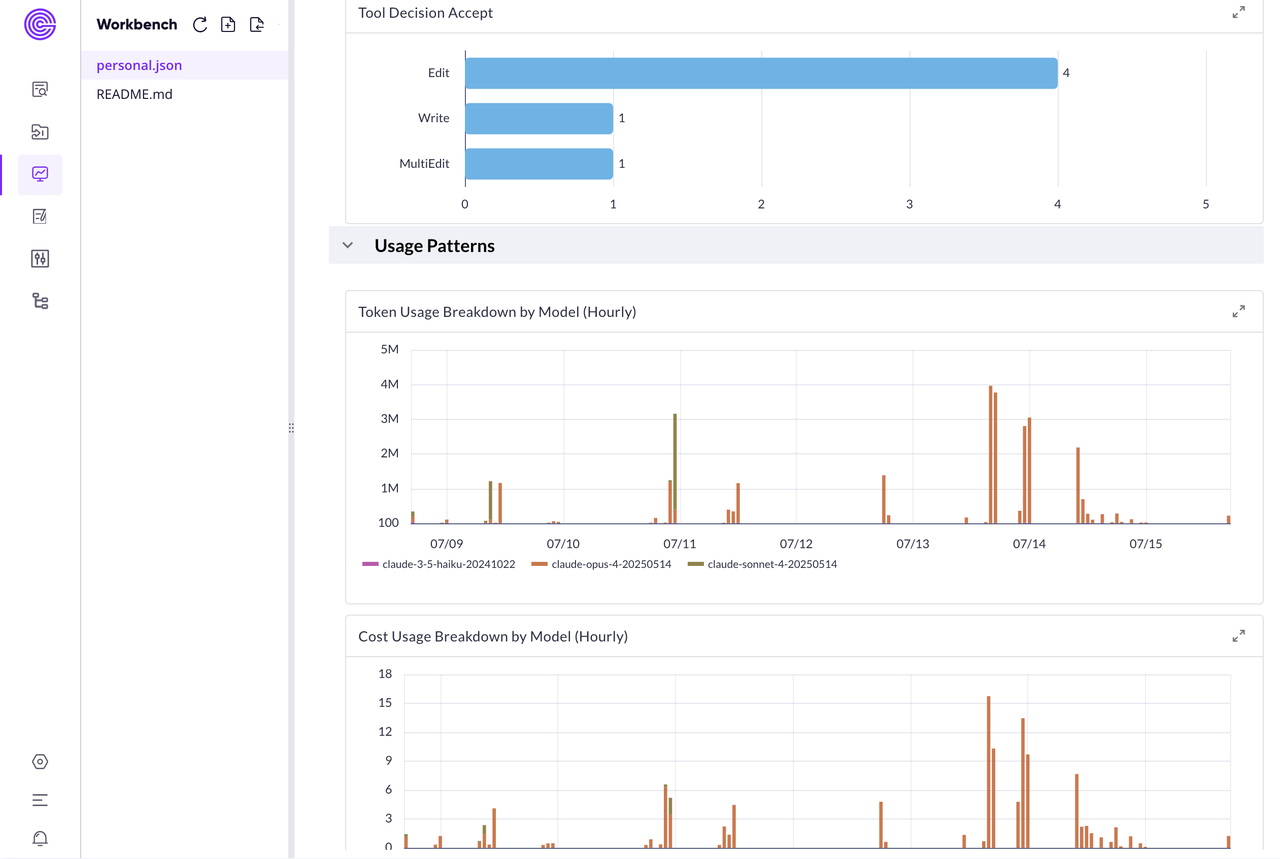
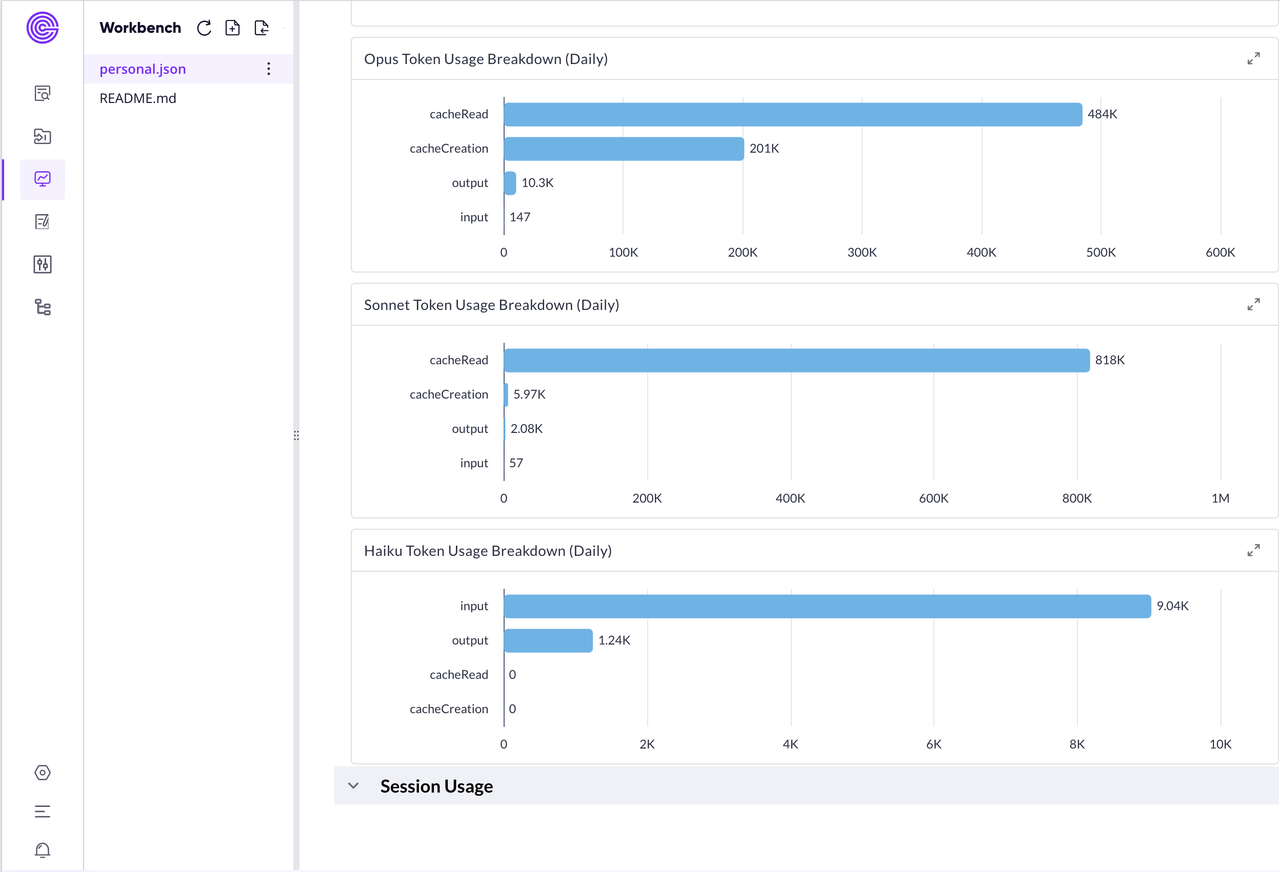
看着这个仪表板,一般看的最多的就是那个最大的绿色数字——今天又"烧"了多少钱。旁边的 Token 使用分布也挺有意思的,缓存读取居然有几十万个!说明 Claude Code 在疯狂复用之前的上下文,挺聪明的。而我真正的输入 Token 并不多,大部分工作都在"回忆"历史对话,想想也是,我基本上都是一句话描述任务。
代码行数统计主要是想了解 Claude Code 每天都实际产出了多少:从图上数据可以看出来,新增了几百行,删除相对较少,净产出不错!旁边那个"代码效率"指标表示每美元能搞定多少行代码,让我知道这钱花得值不值。
趋势图基本是 CC 编程节奏的完美写照。某些天的橙色山峰冲到了 1K+ 行,明显是"爆肝"的日子。蓝色删除部分相对平缓,说明主要在创造而不是重构。
模型使用分布让我发现一个有意思的点,Claude Code 会不时的用 Haiku 来做轻量任务,估计是 summary 之类的。
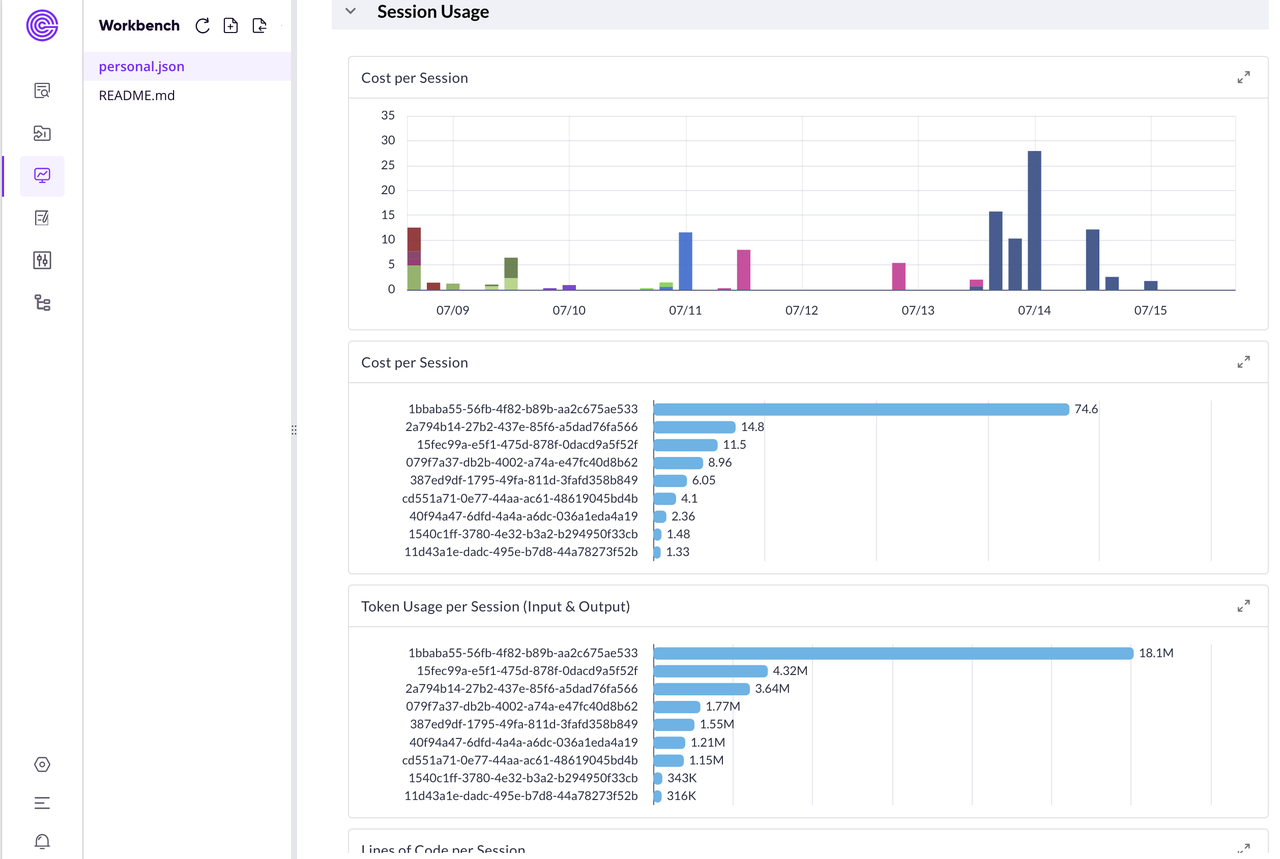
最后那个会话成本排行相当于是"烧钱排行榜"。最贵的会话花了我 78 刀,消耗了上千万 Token!由于只有 session_id,其实并不知道是什么项目,我只能到本地去反查才看出来这个 session 是对某个功能的优化需求。这也是我希望未来能在遥测数据中加上会话名称的原因——不然这些乱码一样的 ID 真的毫无意义。
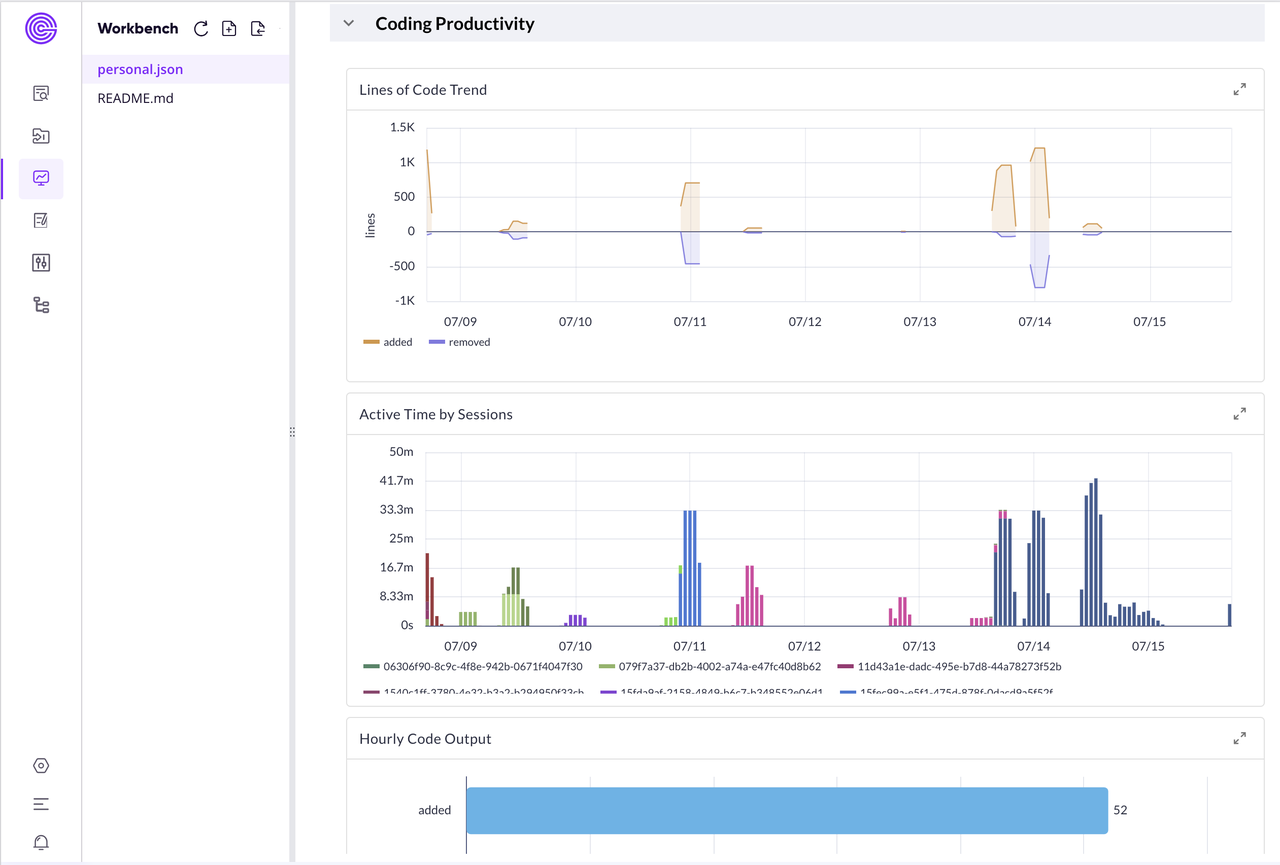
由于这完全是Dashboard as Code,所以分享也比较简单。具体代码如下所示,可以在这里找到这个仪表盘的完整 Perses 配置文件,有兴趣的朋友可以直接拿去用。
json
{
"env": {
"CLAUDE_CODE_ENABLE_TELEMETRY": "1",
"OTEL_METRICS_EXPORTER": "otlp",
"OTEL_LOGS_EXPORTER": "otlp",
"OTEL_EXPORTER_OTLP_PROTOCOL": "http/protobuf",
"OTEL_EXPORTER_OTLP_ENDPOINT": "https://fask21vvw8ri.us-west-2.aws.greptime.cloud/v1/otlp",
"OTEL_EXPORTER_OTLP_HEADERS": "Authorization=Basic aVV0U1lzM0l0bnQ3TzZrd3A4UGFSR3JSOkJIalBZR0o0Qll3dGgxNTZ1Q0lJWjM4cg==,X-Greptime-DB-Name=u28jduustrzqjolly_sleet-public",
"OTEL_METRIC_EXPORT_INTERVAL": "10000",
"OTEL_LOGS_EXPORT_INTERVAL": "5000"
}
}总结
过程中我也发现几个有趣的事情:
OpenTelemetry数据向我揭示了一个ccusage无法展示的细节:Claude Code在底层会使用Haiku模型。通过按模型分解 Token 使用量,发现它会智能地将较轻量、复杂度较低的任务分配给Haiku;现在会话指标提供了
session_id,这对于统计活跃会话非常有用。但是,在本地我可以看到会话名称(可以和项目对齐)。如果能将这个会话名称作为标签(label)添加到遥测数据中,看上去就更有意义了,现在就是一堆 Base64 码;Claude Code 官方其实没有说过 $100 的用量上限是多少,我其实挺好奇的。巧的是,有一次 Vibe Coding 了连续大概两个小时,突然被限流了,连
Sonnet 4的模型也用不了,赶紧看一眼 Dashboard,消耗了巨大的 600 万 Token,大约 500 个输入 Token,仅 5 万个输出 Token,其余全部来自缓存,基本都是Opus模型。估计这个就是 5 小时内的使用上限了。
就这样,谢谢阅读,祝大家 Happy Coding! Happy Hacking!

